Recognition: 2 theorem links
· Lean TheoremSustainability Analysis of Prompt Strategies for SLM-based Automated Test Generation
Pith reviewed 2026-05-13 20:13 UTC · model grok-4.3
The pith
Prompt strategies impact sustainability more than model choice for SLM-based test generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
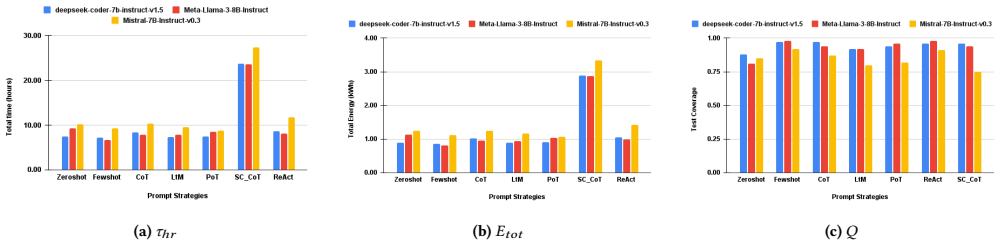
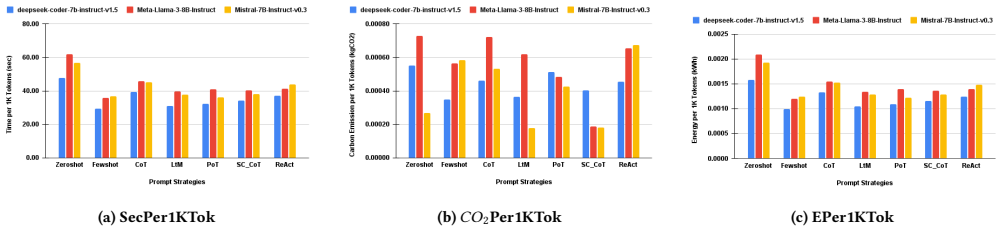
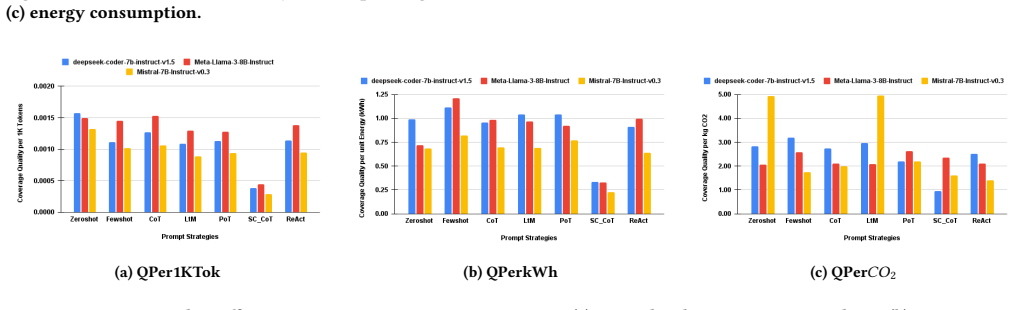
The paper's core discovery is that prompt strategies have a substantial and independent impact on sustainability outcomes, often outweighing the effect of model choice. Reasoning intensive strategies such as Chain of Thought and Self-Consistency achieve higher coverage but incur significantly higher execution time, energy consumption, and carbon emissions. In contrast, simpler strategies such as Zero-Shot and ReAct deliver competitive coverage test quality with markedly lower environmental cost, while Least-to-Most and Program of Thought offer balanced trade-offs.
What carries the argument
The joint evaluation of seven prompt strategies on three SLMs using metrics for execution time, token usage, energy consumption, carbon emissions, and test coverage quality.
Load-bearing premise
The experimental results obtained from three specific SLMs and seven prompt strategies under controlled conditions will generalize to other models, larger codebases, and practical testing environments.
What would settle it
Conducting the same analysis with additional SLMs or on significantly larger code repositories and observing that differences due to model choice exceed those from prompt strategies would disprove the claim of prompt strategies having the dominant impact.
Figures


read the original abstract
The growing adoption of prompt-based automation in software testing raises important issues regarding its computational and environmental sustainability. Existing sustainability studies in AI-driven testing primarily focus on large language models, leaving the impact of prompt engineering strategies largely unexplored - particularly in the context of Small Language Models (SLMs). This gap is critical, as prompt design directly influences inference behavior, execution cost, and resource utilization, even when model size is fixed. To the best of our knowledge, this paper presents the first systematic sustainability evaluation of prompt engineering strategies for automated test generation using SLMs. We analyze seven prompt strategies across three open-source SLMs under a controlled experimental setup. Our evaluation jointly considers execution time, token usage, energy consumption, carbon emissions, and coverage test quality, the latter assessed through coverage analysis of the generated test scripts. The results show that prompt strategies have a substantial and independent impact on sustainability outcomes, often outweighing the effect of model choice. Reasoning intensive strategies such as Chain of Thought and Self-Consistency achieve higher coverage but incur significantly higher execution time, energy consumption, and carbon emissions. In contrast, simpler strategies such as Zero-Shot and ReAct deliver competitive coverage test quality with markedly lower environmental cost, while Least-to-Most and Program of Thought offer balanced trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic sustainability evaluation of seven prompt engineering strategies for automated test generation using three open-source SLMs. Under a controlled setup, it jointly measures execution time, token usage, energy consumption, carbon emissions, and test coverage quality. The central claim is that prompt strategies exert a substantial and independent effect on sustainability outcomes, often outweighing model choice: reasoning-intensive strategies (Chain of Thought, Self-Consistency) yield higher coverage at markedly higher environmental cost, while simpler strategies (Zero-Shot, ReAct) deliver competitive coverage with lower cost, and Least-to-Most and Program of Thought provide balanced trade-offs.
Significance. If the empirical comparison holds, the work is significant for filling the gap in sustainability analyses of AI-driven testing by shifting focus from large models to SLMs and by quantifying prompt-induced trade-offs across multiple environmental and quality metrics. It supplies concrete, actionable guidance on prompt selection for resource-constrained test generation and underscores that prompt design can be a higher-leverage lever than model selection for reducing carbon footprint.
major comments (2)
- [Abstract] Abstract and Results: the claim that prompt strategies 'often outweighing the effect of model choice' is load-bearing yet rests on only three SLMs. No parameter counts, architectural families, or performance-spread statistics are supplied; without these, it is impossible to determine whether the observed prompt dominance is an artifact of narrow model variance rather than a general phenomenon.
- [Experimental Setup] Experimental Setup (implied in Abstract): the manuscript reports no variance decomposition, prompt×model interaction statistics, or sensitivity checks that vary model diversity while holding prompts fixed. These omissions directly undermine the central comparison of relative effect sizes.
minor comments (1)
- [Abstract] The abstract states 'to the best of our knowledge' without citing prior SLM sustainability studies; a brief related-work paragraph would strengthen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our model selection and the need for stronger statistical support for our central claims. We address each major comment below and outline targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Results: the claim that prompt strategies 'often outweighing the effect of model choice' is load-bearing yet rests on only three SLMs. No parameter counts, architectural families, or performance-spread statistics are supplied; without these, it is impossible to determine whether the observed prompt dominance is an artifact of narrow model variance rather than a general phenomenon.
Authors: We acknowledge that the study is limited to three SLMs and that additional details are needed to contextualize the claim. In the revision we will add explicit parameter counts and architectural family information for each model, along with performance-spread statistics (means and standard deviations across repeated runs). We will also qualify the claim in the abstract and results to specify that it holds within the three studied models and provide a brief discussion of how the observed prompt effects compared to model effects in our data. While we cannot expand the model set without new experiments, these additions will allow readers to better assess the scope of the findings. revision: partial
-
Referee: [Experimental Setup] Experimental Setup (implied in Abstract): the manuscript reports no variance decomposition, prompt×model interaction statistics, or sensitivity checks that vary model diversity while holding prompts fixed. These omissions directly undermine the central comparison of relative effect sizes.
Authors: We agree that variance decomposition and interaction statistics would strengthen the comparison of effect sizes. Using the existing experimental data, the revised manuscript will include a new analysis subsection reporting variance decomposition (e.g., via ANOVA or similar methods) for key metrics such as energy consumption and coverage. We will also report prompt×model interaction effects and discuss sensitivity to model choice while holding prompts fixed. These additions will be based on the collected data and will directly support the relative-effect claim. revision: yes
Circularity Check
No circularity: direct empirical measurements only
full rationale
The paper reports controlled experiments that measure execution time, token usage, energy, emissions, and coverage for seven prompt strategies run on three fixed SLMs. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the abstract or described methodology. All reported outcomes are observed quantities from the experimental runs rather than quantities defined by or reduced to prior results within the paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We analyze seven prompt strategies across three open-source SLMs... execution time, token usage, energy consumption, carbon emissions, and coverage test quality
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
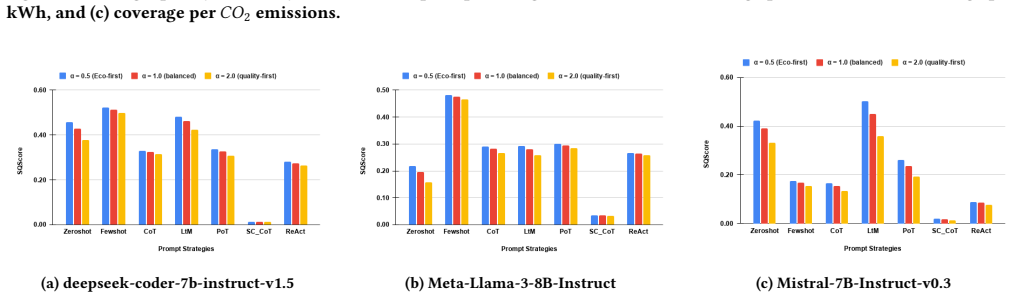
SQScore = α · Q / (CO2 · Etot · τhr)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Shaiful Alam Chowdhury and Abram Hindle. 2016. GreenOracle: Estimating Software Energy Consumption with Energy Measurement Corpora. InProceed- ings of the 13th International Conference on Mining Software Repositories (MSR). 49–60. doi:10.1145/2901739.2901763
-
[3]
Vincenzo De Martino, Mohammad Amin Zadenoori, Xavier Franch, and Alessio Ferrari. 2026. Green Prompt Engineering: Investigating the Energy Impact of Prompt Design in Software Engineering. InProceedings of the ACM Conference on Software Engineering. Pre-print
work page 2026
-
[4]
Antonio Della Porta, Stefano Lambiase, and Fabio Palomba. 2025. Do Prompt Pat- terns Affect Code Quality? A First Empirical Assessment of ChatGPT-Generated Code. InProceedings of the 29th International Conference on Evaluation and As- sessment in Software Engineering. ACM, Istanbul, Turkiye. doi:10.1145/3756681. 3756938
- [5]
- [6]
-
[7]
Peng Jiang, Christian Sonne, Wangliang Li, Fengqi You, and Siming You. 2024. Preventing the Immense Increase in the Life-Cycle Energy and Carbon Footprints of LLM-Powered Intelligent Chatbots.Engineering40 (2024), 202–210. doi:10. 1016/j.eng.2024.04.002
work page 2024
-
[8]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K. Lahiri, and Saurabh Sen
-
[9]
Automated program repair in the era of large pre-trained language models
CodaMOSA: Escaping Coverage Plateaus in Test Generation with Pre- trained Large Language Models. InProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE). doi:10.1109/ICSE48619.2023.00085
-
[10]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: 10 A Machine Learning Benchmark Dataset for Code Unders...
work page internal anchor Pith review arXiv 2021
- [11]
- [12]
-
[13]
Patomporn Payoungkhamdee, Pume Tuchinda, Jinheon Baek, Samuel Cahyaw- ijaya, Can Udomcharoenchaikit, Potsawee Manakul, Peerat Limkonchotiwat, Ekapol Chuangsuwanich, and Sarana Nutanong. 2025. Towards Better Under- standing of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments.arXiv preprintarXiv:2502.17956 (2025). https://arxiv.or...
-
[14]
Riccardo Rubei, Aicha Moussaid, Claudio Di Sipio, and Davide Di Ruscio. 2025. Prompt Engineering and Its Implications on the Energy Consumption of Large Language Models. InProceedings of the IEEE/ACM 9th International Workshop on Green and Sustainable Software (GREENS). 1–6. doi:10.1109/GREENS66463.2025. 00014
-
[15]
Asif Hassan Russel, Md Sanaul Haque, Hatef Shamshiri, and Jari Porras. 2024. Impact of Incorporating AI Tools on Software Sustainability among Software Developers.SSRN Electronic Journal(2024). https://ssrn.com/abstract=5519476 Preprint
work page 2024
-
[16]
Max Schaefer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2024. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation. IEEE Transactions on Software Engineering(2024). doi:10.1109/TSE.2023.3334955
-
[17]
Jieke Shi, Zhou Yang, and David Lo. 2025. Efficient and Green Large Language Models for Software Engineering: Vision and the Road Ahead.ACM Transactions on Software Engineering and Methodology(2025). doi:10.1145/3708525
- [18]
-
[19]
Roberto Verdecchia, Emilio Cruciani, Antonia Bertolino, and Breno Miranda. 2021. Energy-Aware Software Testing. InProceedings of the IEEE/ACM International Conference on Software Engineering Workshops. 1–5
work page 2021
-
[20]
Roberto Verdecchia, Patricia Lago, Christof Ebert, and Carol De Vries. 2021. Green IT and Green Software.IEEE Software38, 6 (2021), 7–15. doi:10.1109/MS.2021. 3102254
-
[21]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software Testing with Large Language Models: Survey, Landscape, and Vision.IEEE Transactions on Software Engineering(2024). doi:10.1109/TSE. 2024.3368208
work page doi:10.1109/tse 2024
-
[22]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InProceedings of the International Conference on Learning Representations. https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems. https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of the International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Andy Zaidman. 2024. An Inconvenient Truth in Software Engineering? The Environmental Impact of Testing Open Source Java Projects. InProceedings of the 5th ACM/IEEE International Conference on Automation of Software Test (AST). 1–5. doi:10.1145/3644032.3644461
-
[26]
Denny Zhou, Nathanael Scharli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. 2023. Least- to-Most Prompting Enables Complex Reasoning in Large Language Models. In Proceedings of the International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2205.10625 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.