Recognition: no theorem link
A Unified Perspective on Adversarial Membership Manipulation in Vision Models
Pith reviewed 2026-05-13 20:01 UTC · model grok-4.3
The pith
Adversarial perturbations can fabricate membership for non-training images in vision model attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
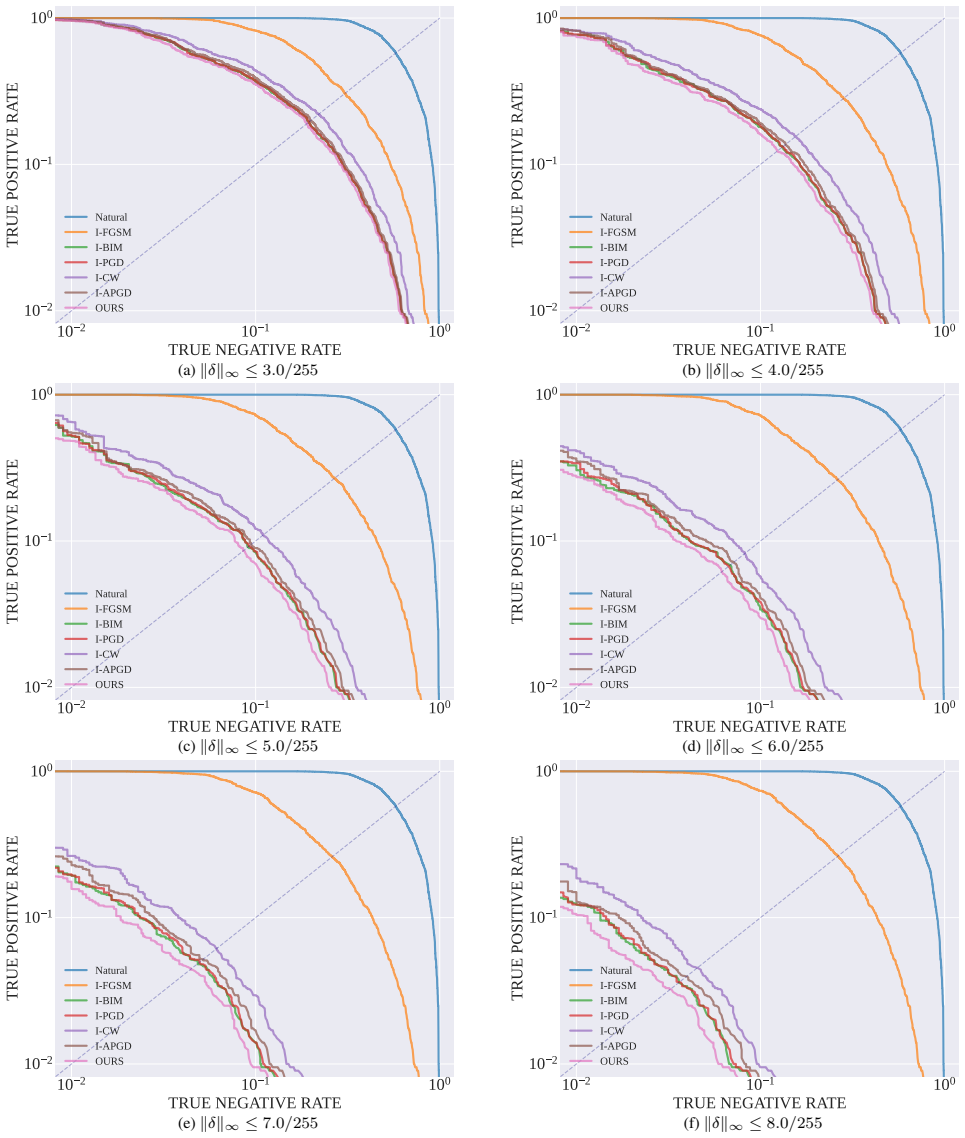
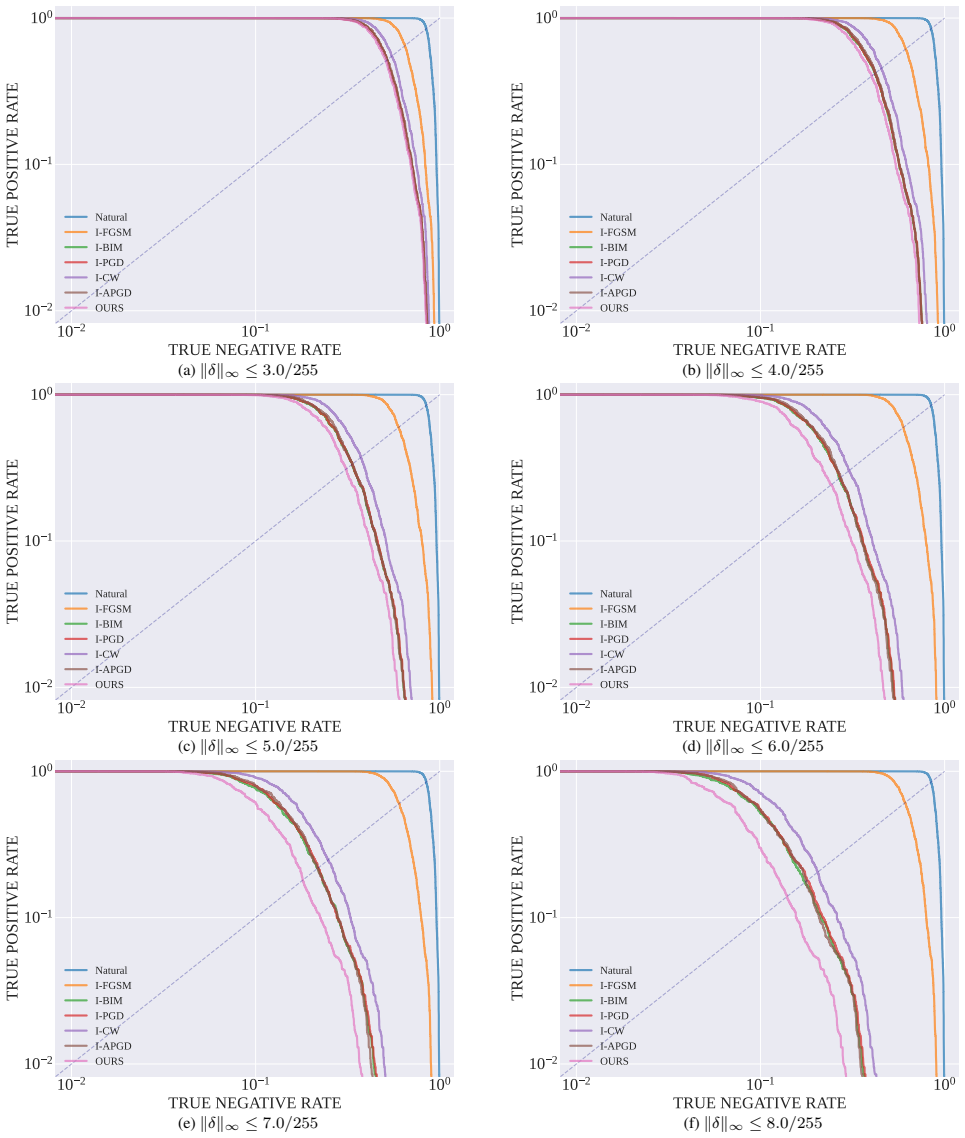
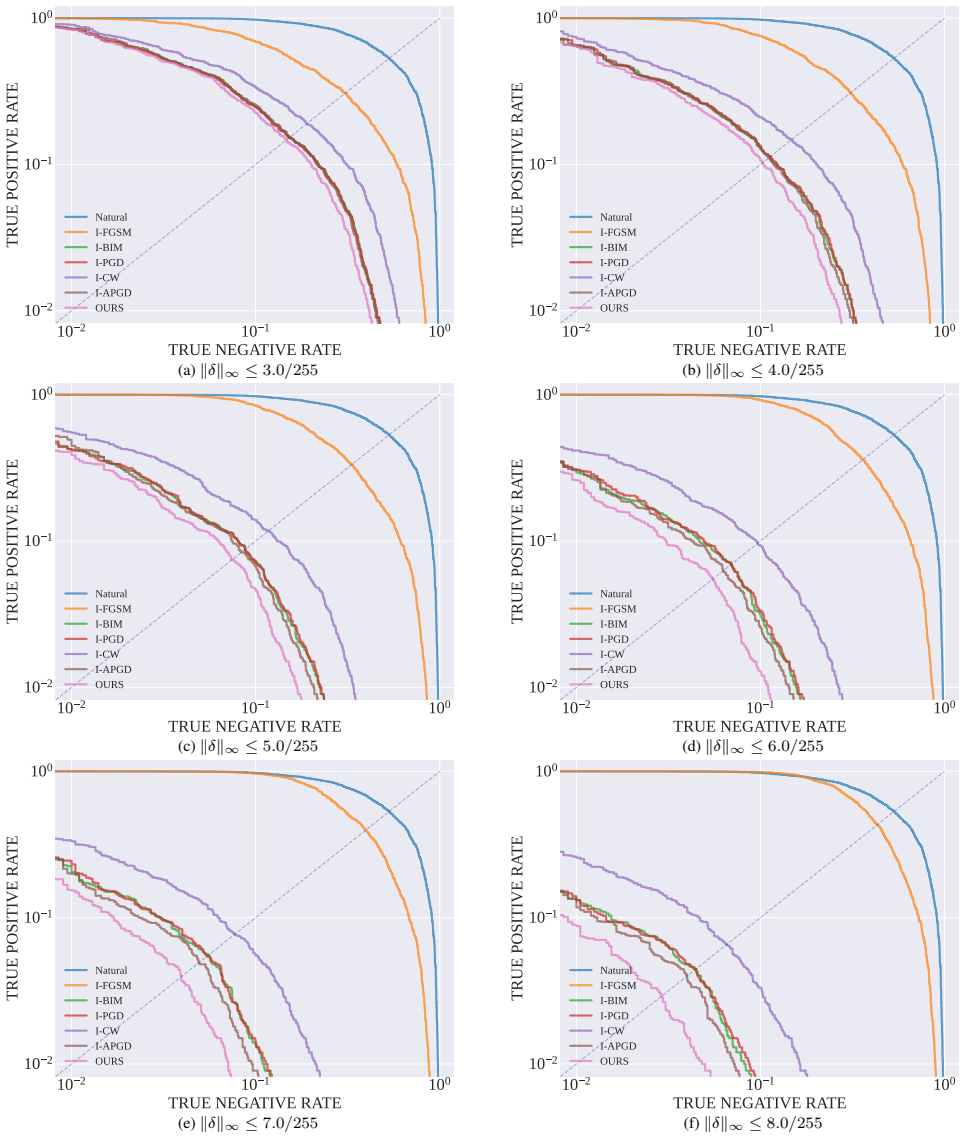
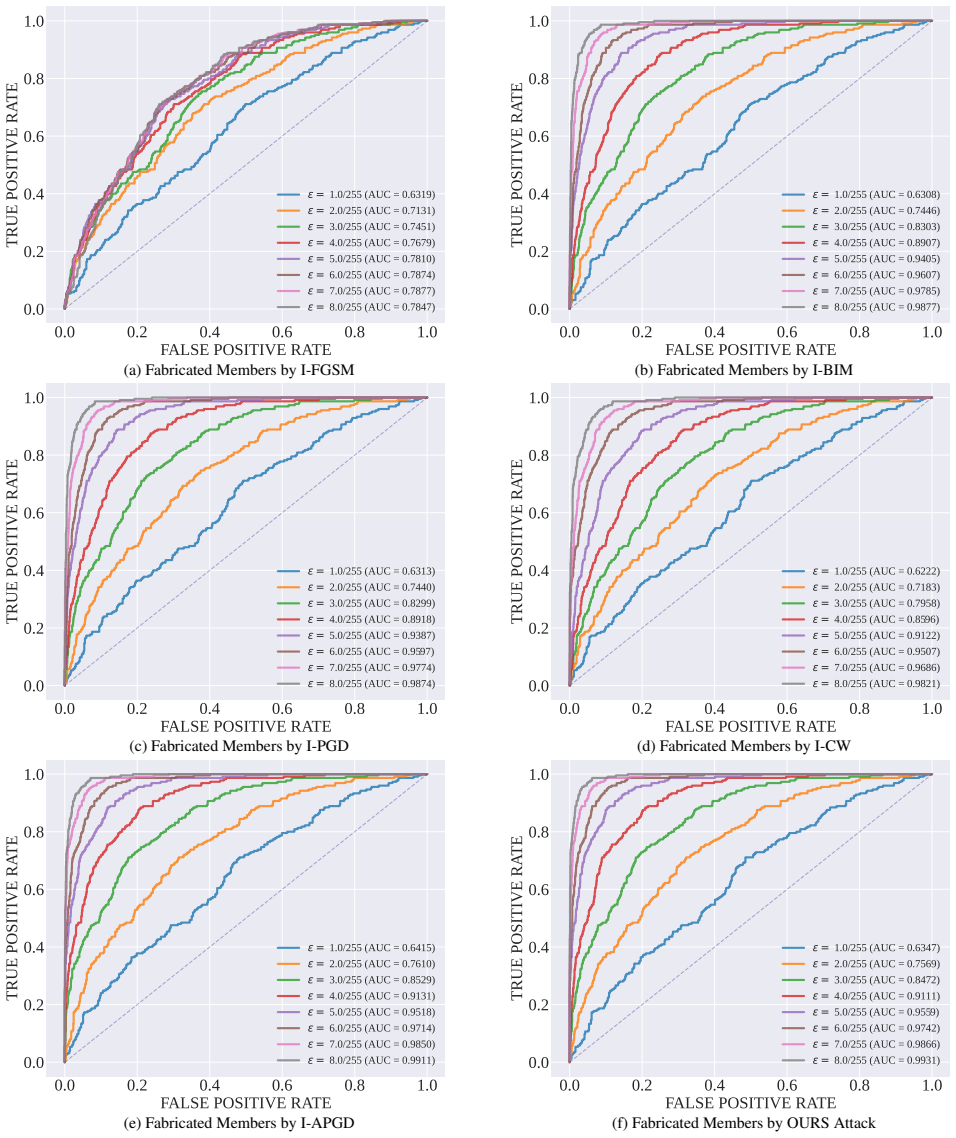
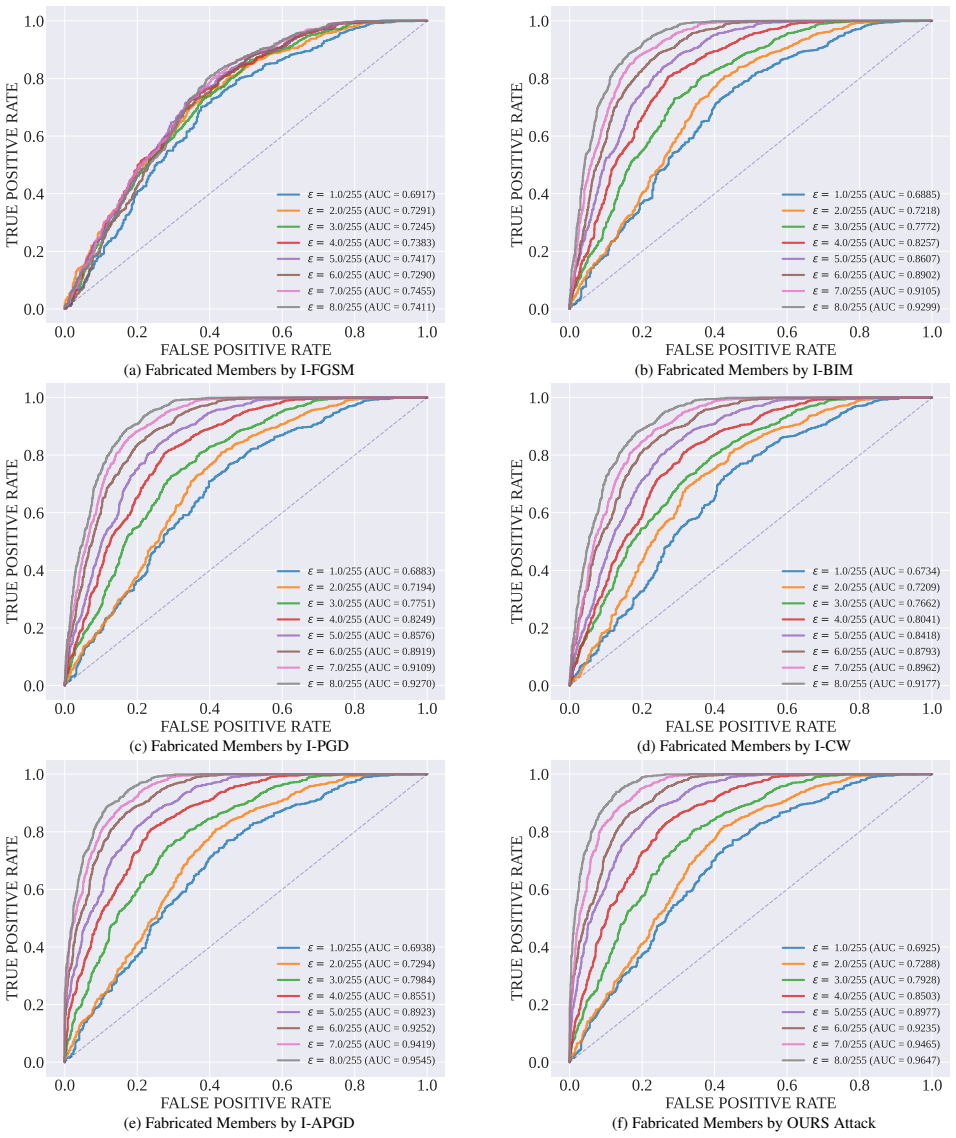
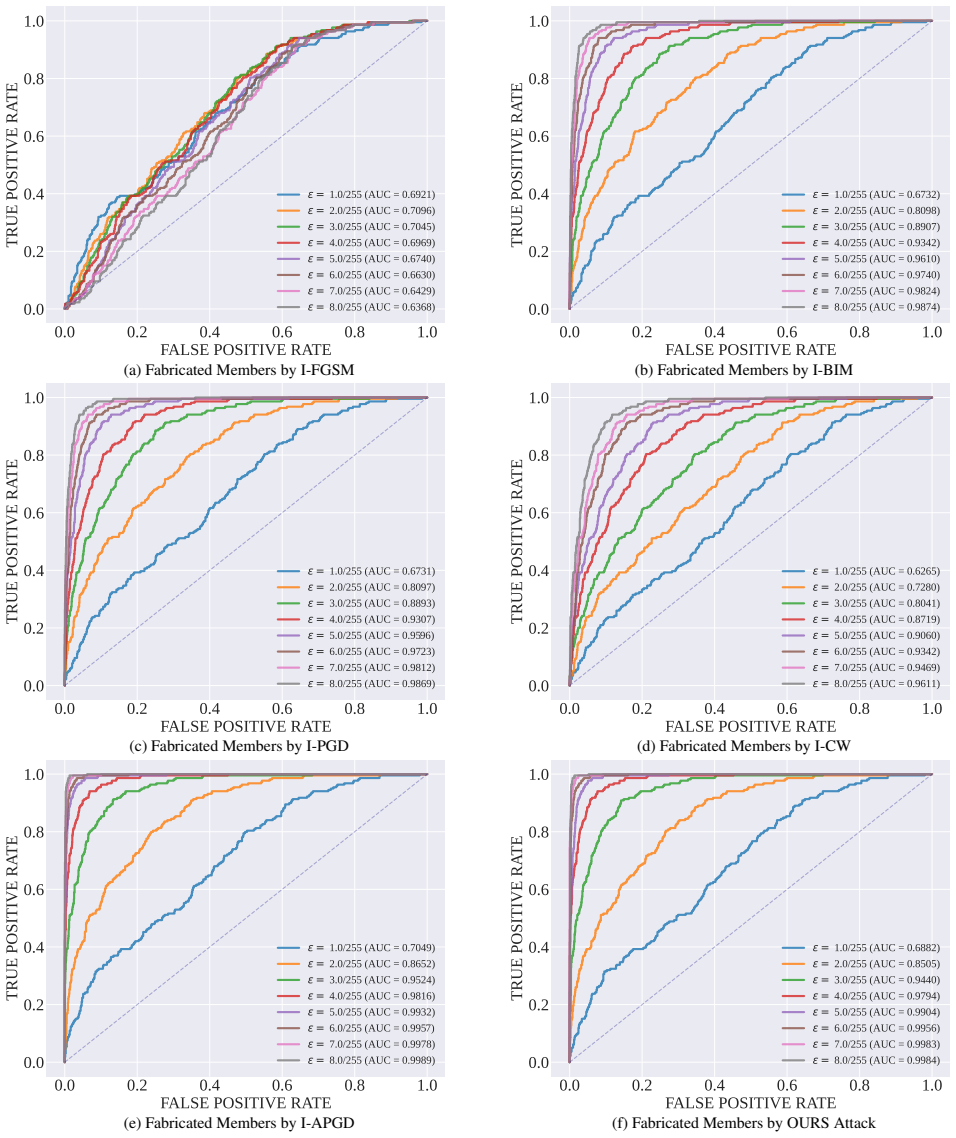
Adversarial membership fabrication pushes non-member images into the member region of MIAs across models and datasets, and a characteristic gradient-norm collapse trajectory separates these fabricated members from genuine ones despite nearly identical semantics, supporting detection and robust inference methods.
What carries the argument
The gradient-norm collapse trajectory that distinguishes fabricated from true members in the attack process.
If this is right
- Adversarial fabrication works reliably on various vision architectures and datasets.
- Gradient-geometry signals can detect the manipulation effectively.
- Robust inference frameworks can reduce the success of such adversarial attacks.
Where Pith is reading between the lines
- This vulnerability suggests that membership inference tools themselves require adversarial training or hardening.
- Similar manipulation might apply to other types of privacy attacks beyond membership inference.
- Defenses based on gradient norms could be integrated into standard model evaluation pipelines.
Load-bearing premise
The gradient-norm collapse trajectory reliably separates fabricated members from true members despite nearly identical semantic representations.
What would settle it
Finding a set of fabricated and true members where the gradient-norm trajectories are statistically indistinguishable would disprove the separation method.
Figures



















read the original abstract
Membership inference attacks (MIAs) aim to determine whether a specific data point was part of a model's training set, serving as effective tools for evaluating privacy leakage of vision models. However, existing MIAs implicitly assume honest query inputs, and their adversarial robustness remains unexplored. We show that MIAs for vision models expose a previously overlooked adversarial surface: adversarial membership manipulation, where imperceptible perturbations can reliably push non-member images into the "member" region of state-of-the-art MIAs. In this paper, we provide the first unified perspective on this phenomenon by analyzing its mechanism and implications. We begin by demonstrating that adversarial membership fabrication is consistently effective across diverse architectures and datasets. We then reveal a distinctive geometric signature - a characteristic gradient-norm collapse trajectory - that reliably separates fabricated from true members despite their nearly identical semantic representations. Building on this insight, we introduce a principled detection strategy grounded in gradient-geometry signals and develop a robust inference framework that substantially mitigates adversarial manipulation. Extensive experiments show that fabrication is broadly effective, while our detection and robust inference strategies significantly enhance resilience. This work establishes the first comprehensive framework for adversarial membership manipulation in vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that membership inference attacks (MIAs) on vision models have an overlooked adversarial surface: imperceptible perturbations can fabricate membership for non-member images with high success across architectures and datasets. It identifies a characteristic gradient-norm collapse trajectory as a geometric signature that separates fabricated members from true members despite similar semantics. Building on this, the authors propose a gradient-geometry-based detection strategy and a robust inference framework that substantially mitigates fabrication success. Extensive experiments are reported to show consistent fabrication effectiveness and improved resilience under the proposed defenses.
Significance. If the gradient-norm separation and detection hold under realistic conditions, the work provides the first unified framework for adversarial membership manipulation in vision models. It highlights a new privacy leakage vector beyond standard MIAs and offers concrete detection and robust inference tools. Strengths include the broad experimental coverage across architectures/datasets and the insight that geometric signatures can distinguish fabricated from true members even when semantic representations are nearly identical.
major comments (2)
- [§5] §5 and abstract: The central claim that the robust inference framework 'substantially mitigates' adversarial fabrication rests on the gradient-norm collapse trajectory reliably separating classes under the paper's threat model. However, all reported experiments (§4) use standard PGD-style objectives without knowledge of the detector. No evaluation is provided for adaptive adversaries that explicitly optimize perturbations to match the gradient-norm trajectory of true members (e.g., by adding a matching term to the loss). This is load-bearing for the resilience conclusion.
- [§4] §4 (experimental setup): The soundness of the fabrication effectiveness and detection claims cannot be fully verified without reported data splits, exact MIA implementations, statistical significance tests (e.g., confidence intervals on success rates), or ablation on the gradient-norm threshold choice. The abstract notes consistent effectiveness, but missing details prevent independent reproduction of the separation results.
minor comments (2)
- [§3] Notation for the gradient-norm trajectory and detection threshold should be formalized with an equation in §3 to improve clarity and reproducibility.
- [Figures in §4] Figure captions and axis labels in the geometric signature plots could be expanded to explicitly state what 'collapse trajectory' quantifies (e.g., norm over perturbation steps).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate revisions to strengthen the reproducibility and robustness claims of the manuscript.
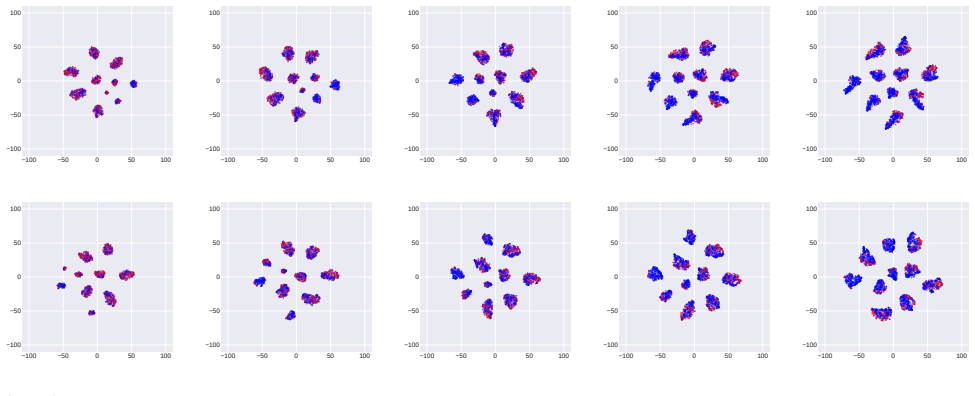
read point-by-point responses
-
Referee: [§5] §5 and abstract: The central claim that the robust inference framework 'substantially mitigates' adversarial fabrication rests on the gradient-norm collapse trajectory reliably separating classes under the paper's threat model. However, all reported experiments (§4) use standard PGD-style objectives without knowledge of the detector. No evaluation is provided for adaptive adversaries that explicitly optimize perturbations to match the gradient-norm trajectory of true members (e.g., by adding a matching term to the loss). This is load-bearing for the resilience conclusion.
Authors: We agree that evaluating resilience against adaptive adversaries who are aware of the detector is necessary to fully support the claim. In the revised manuscript, we will add experiments in which the adversary augments the PGD objective with an explicit term that penalizes deviation from the gradient-norm trajectory of true members. We will report fabrication success rates under this stronger threat model and discuss any degradation in the separation provided by the gradient-norm signal. revision: yes
-
Referee: [§4] §4 (experimental setup): The soundness of the fabrication effectiveness and detection claims cannot be fully verified without reported data splits, exact MIA implementations, statistical significance tests (e.g., confidence intervals on success rates), or ablation on the gradient-norm threshold choice. The abstract notes consistent effectiveness, but missing details prevent independent reproduction of the separation results.
Authors: We acknowledge the need for greater experimental transparency. In the revision we will (i) explicitly state the train/test splits and random seeds used for all datasets, (ii) provide precise pseudocode and hyper-parameter settings for each MIA implementation, (iii) report 95% confidence intervals on all success-rate figures, and (iv) include an ablation study varying the gradient-norm threshold to demonstrate the stability of the detection performance. revision: yes
Circularity Check
No circularity; empirical observations and strategies are independent of fitted inputs or self-citations
full rationale
The paper presents no mathematical derivations, equations, or parameter-fitting steps that reduce to self-definition or prior results by construction. Claims of fabrication effectiveness and the gradient-norm collapse trajectory as a separating signature are introduced as empirical findings from experiments across architectures and datasets. The detection strategy and robust inference framework are built directly on these observed geometric signals without invoking self-citations, uniqueness theorems, or ansatzes that loop back to the paper's own inputs. No load-bearing self-citation chains or renamed known results appear in the abstract or described content. The work is self-contained via external experimental validation, consistent with a score of 0.
Axiom & Free-Parameter Ledger
free parameters (1)
- gradient-norm threshold
axioms (1)
- domain assumption MIAs can be evaluated via output or gradient signals from the target model
Reference graph
Works this paper leans on
-
[1]
Jason W Bentley, Daniel Gibney, Gary Hoppenworth, and Sumit Kumar Jha. Quantifying membership inference vulner- ability via generalization gap and other model metrics.arXiv preprint arXiv:2009.05669, 2020. 13
-
[2]
A survey of black-box adversarial attacks on computer vision models.arXiv preprint arXiv:1912.01667,
Siddhant Bhambri, Sumanyu Muku, Avinash Tulasi, and Arun Balaji Buduru. A survey of black-box adversarial attacks on computer vision models.arXiv preprint arXiv:1912.01667,
-
[3]
Pattern recognition.Machine learning, 128(9), 2006
Christopher M Bishop. Pattern recognition.Machine learning, 128(9), 2006. 13
work page 2006
-
[4]
Adversarial examples are not easily detected: Bypassing ten detection methods
Nicholas Carlini and David Wagner. Adversarial examples are not easily detected: Bypassing ten detection methods. In ACM Workshop on Artificial Intelligence and Security, 2017. 13
work page 2017
-
[5]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. InCVPR, 2017. 3, 14, 19, 20
work page 2017
-
[6]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Nicholas Carlini, Chang Liu, ´Ulfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. InUSENIX Security, 2019. 13
work page 2019
-
[7]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. InIEEE Symposium on Security and Privacy, 2022. 1, 2, 3, 4, 8, 12, 13, 18, 19, 20
work page 2022
-
[8]
Deepdriving: Learning affordance for direct perception in autonomous driving
Chenyi Chen, Ari Seff, Alain Kornhauser, and Jianxiong Xiao. Deepdriving: Learning affordance for direct perception in autonomous driving. InICCV, 2015. 13
work page 2015
-
[9]
Gan- leaks: A taxonomy of membership inference attacks against generative models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan- leaks: A taxonomy of membership inference attacks against generative models. InACM SIGSAC Conference on Computer and Communications Security, 2020. 13
work page 2020
-
[10]
When machine unlearn- ing jeopardizes privacy
Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. When machine unlearn- ing jeopardizes privacy. InACM SIGSAC Conference on Computer and Communications Security, 2021. 12
work page 2021
-
[11]
Adversarial robustness: From self-supervised pre-training to fine-tuning
Tianlong Chen, Sijia Liu, Shiyu Chang, Yu Cheng, Lisa Amini, and Zhangyang Wang. Adversarial robustness: From self-supervised pre-training to fine-tuning. InCVPR, 2020. 14
work page 2020
-
[12]
Label-only membership infer- ence attacks
Christopher A Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot. Label-only membership infer- ence attacks. InICML, 2021. 12
work page 2021
-
[13]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter- free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter- free attacks. InICML, 2020. 3, 4, 8, 14, 19, 20
work page 2020
-
[14]
Cinic-10 is not imagenet or cifar-10.arXiv preprint arXiv:1810.03505, 2018
Luke N Darlow, Elliot J Crowley, Antreas Antoniou, and Amos J Storkey. Cinic-10 is not imagenet or cifar-10.arXiv preprint arXiv:1810.03505, 2018. 8, 19, 20
-
[15]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009. 8, 19, 20
work page 2009
-
[16]
Model inversion attacks that exploit confidence information and basic countermeasures
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. InACM SIGSAC Conference on Computer and Communications Security, 2015. 12
work page 2015
-
[17]
Karan Ganju, Qi Wang, Wei Yang, Carl A Gunter, and Nikita Borisov. Property inference attacks on fully connected neural networks using permutation invariant representations. In ACM SIGSAC Conference on Computer and Communications Security, 2018. 12
work page 2018
-
[18]
Maximum mean discrepancy test is aware of adversarial attacks
Ruize Gao, Feng Liu, Jingfeng Zhang, Bo Han, Tongliang Liu, Gang Niu, and Masashi Sugiyama. Maximum mean discrepancy test is aware of adversarial attacks. InICML,
-
[19]
Fast and reliable evaluation of adversarial robustness with minimum- margin attack
Ruize Gao, Jiongxiao Wang, Kaiwen Zhou, Feng Liu, Binghui Xie, Gang Niu, Bo Han, and James Cheng. Fast and reliable evaluation of adversarial robustness with minimum- margin attack. InICML, 2022. 3, 14, 19
work page 2022
-
[20]
Explaining and harnessing adversarial examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InICLR,
-
[21]
On the ( Statistical ) Detection of Adversarial Examples
Kathrin Grosse, Praveen Manoharan, Nicolas Papernot, Michael Backes, and Patrick McDaniel. On the (statistical) detection of adversarial examples.arXiv:1702.06280, 2017. 14
-
[22]
Simple black-box adversarial attacks
Chuan Guo, Jacob Gardner, Yurong You, Andrew Gordon Wilson, and Kilian Weinberger. Simple black-box adversarial attacks. InICML, 2019. 4
work page 2019
-
[23]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, 2016. 8, 12, 19
work page 2016
-
[24]
Sorami Hisamoto, Matt Post, and Kevin Duh. Membership inference attacks on sequence-to-sequence models: Is my data in your machine translation system?Transactions of the Association for Computational Linguistics, 8:49–63, 2020. 12
work page 2020
-
[25]
Nils Homer, Szabolcs Szelinger, Margot Redman, David Dug- gan, Waibhav Tembe, Jill Muehling, John V Pearson, Di- etrich A Stephan, Stanley F Nelson, and David W Craig. Resolving individuals contributing trace amounts of dna to highly complex mixtures using high-density snp genotyping microarrays.PLOS Genetics, 4:1–9, 2008. 1, 3
work page 2008
-
[26]
Scalable continuous-time diffusion framework for network inference and influence estimation
Keke Huang, Ruize Gao, Bogdan Cautis, and Xiaokui Xiao. Scalable continuous-time diffusion framework for network inference and influence estimation. InWWW, 2024. 12
work page 2024
-
[27]
Black-box adversarial attacks with limited queries and information
Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. InICML, 2018. 4
work page 2018
-
[28]
Memguard: Defending against black- box membership inference attacks via adversarial examples
Jinyuan Jia, Ahmed Salem, Michael Backes, Yang Zhang, and Neil Zhenqiang Gong. Memguard: Defending against black- box membership inference attacks via adversarial examples. InProceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2019. 1
work page 2019
-
[29]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 8, 18, 19, 20
work page 2009
-
[30]
Adver- sarial examples in the physical world
Alexey Kurakin, Ian Goodfellow, Samy Bengio, et al. Adver- sarial examples in the physical world. InICLR, 2017. 13, 19, 20
work page 2017
-
[31]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InNeurIPS, 2018. 5, 14
work page 2018
-
[32]
Stolen memories: Leverag- ing model memorization for calibrated white-box membership inference
Klas Leino and Matt Fredrikson. Stolen memories: Leverag- ing model memorization for calibrated white-box membership inference. InUSENIX Security, 2020. 12, 13, 18
work page 2020
-
[33]
Membership in- ference attacks and defenses in classification models
Jiacheng Li, Ninghui Li, and Bruno Ribeiro. Membership in- ference attacks and defenses in classification models. InACM Conference on Data and Application Security and Privacy,
-
[34]
Adversarial examples detection in deep networks with convolutional filter statistics
Xin Li and Fuxin Li. Adversarial examples detection in deep networks with convolutional filter statistics. InICCV, 2017. 14
work page 2017
-
[35]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Characterizing adversarial sub- spaces using local intrinsic dimensionality
Xingjun Ma, Bo Li, Yisen Wang, Sarah M Erfani, Sudanthi Wijewickrema, Grant Schoenebeck, Dawn Song, Michael E Houle, and James Bailey. Characterizing adversarial sub- spaces using local intrinsic dimensionality. InICLR, 2018. 5, 14
work page 2018
-
[37]
Understanding adversarial at- tacks on deep learning based medical image analysis systems
Xingjun Ma, Yuhao Niu, Lin Gu, Yisen Wang, Yitian Zhao, James Bailey, and Feng Lu. Understanding adversarial at- tacks on deep learning based medical image analysis systems. Pattern Recognition, 2021. 13
work page 2021
-
[38]
Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008. 5, 17, 19
work page 2008
-
[39]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InICLR, 2018. 3, 4, 8, 13, 19, 20
work page 2018
-
[40]
Exploiting unintended feature leakage in collaborative learning
Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. Exploiting unintended feature leakage in collaborative learning. InIEEE Symposium on Security and Privacy, 2019. 18
work page 2019
-
[41]
On detecting adversarial perturbations
Jan Hendrik Metzen, Tim Genewein, V olker Fischer, and Bastian Bischoff. On detecting adversarial perturbations. arXiv:1702.04267, 2017. 14
-
[42]
Riccardo Miotto, Fei Wang, Shuang Wang, Xiaoqian Jiang, and Joel T Dudley. Deep learning for healthcare: review, opportunities and challenges.Briefings in bioinformatics, 19 (6):1236–1246, 2018. 12
work page 2018
-
[43]
Sasi Kumar Murakonda and Reza Shokri. Ml privacy meter: Aiding regulatory compliance by quantifying the privacy risks of machine learning.arXiv preprint arXiv:2007.09339, 2020. 13, 14, 18
-
[44]
Machine learning with membership privacy using adversarial regu- larization
Milad Nasr, Reza Shokri, and Amir Houmansadr. Machine learning with membership privacy using adversarial regu- larization. InACM SIGSAC Conference on Computer and Communications Security, 2018. 12
work page 2018
-
[45]
Milad Nasr, Reza Shokri, and Amir Houmansadr. Compre- hensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. InIEEE symposium on security and privacy, 2019. 7, 12
work page 2019
-
[46]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNeurIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011. 19
work page 2011
-
[47]
Jerzy Neyman and Egon Sharpe Pearson. Ix. on the problem of the most efficient tests of statistical hypotheses.Philosoph- ical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, 231(694-706):289–337, 1933. 12
work page 1933
-
[48]
Deep neural networks are easily fooled: High confidence predictions for unrecognizable images
Anh Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. InCVPR, 2015. 13
work page 2015
-
[49]
Curtail: Characterizing and thwarting adversarial deep learning.arXiv:1709.02538, 2017
Bita Darvish Rouhani, Mohammad Samragh, Tara Javidi, and Farinaz Koushanfar. Curtail: Characterizing and thwarting adversarial deep learning.arXiv:1709.02538, 2017. 14
-
[50]
White-box vs black- box: Bayes optimal strategies for membership inference
Alexandre Sablayrolles, Matthijs Douze, Yann Ollivier, Cordelia Schmid, and Herv ´e J ´egou. White-box vs black- box: Bayes optimal strategies for membership inference. In ICML, 2019. 12
work page 2019
-
[51]
Ahmed Salem, Yang Zhang, Mathias Humbert, Mario Fritz, and Michael Backes. Ml-leaks: Model and data indepen- dent membership inference attacks and defenses on machine learning models. InAnnual Network and Distributed System Security Symposium, 2019. 12, 13, 18
work page 2019
-
[52]
Hats: Hardness- aware trajectory synthesis for gui agents
Rui Shao, Ruize Gao, Bin Xie, Yixing Li, Kaiwen Zhou, Shuai Wang, Weili Guan, and Gongwei Chen. Hats: Hardness- aware trajectory synthesis for gui agents. InCVPR, 2026. 12
work page 2026
-
[53]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. InIEEE Symposium on Security and Privacy,
-
[54]
Machine learning models that remember too much
Congzheng Song, Thomas Ristenpart, and Vitaly Shmatikov. Machine learning models that remember too much. InACM SIGSAC Conference on Computer and Communications Se- curity, 2017. 13
work page 2017
-
[55]
Systematic evaluation of pri- vacy risks of machine learning models
Liwei Song and Prateek Mittal. Systematic evaluation of pri- vacy risks of machine learning models. InUSENIX Security,
-
[56]
Introducing a new privacy testing library in tensorflow, 2020
Shuang Song and David Marn. Introducing a new privacy testing library in tensorflow, 2020. 14
work page 2020
-
[57]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. InICLR, 2014. 3, 13
work page 2014
-
[58]
Stealing machine learning models via prediction apis
Florian Tram`er, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning models via prediction apis. InUSENIX Security, 2016. 12
work page 2016
-
[59]
Haonan Wang, Qianli Shen, Yao Tong, Yang Zhang, and Kenji Kawaguchi. The stronger the diffusion model, the easier the backdoor: Data poisoning to induce copyright breaches without adjusting finetuning pipeline. InICML, 2024. 14
work page 2024
-
[60]
On the convergence and robustness of adversarial training
Yisen Wang, Xingjun Ma, James Bailey, Jinfeng Yi, Bowen Zhou, and Quanquan Gu. On the convergence and robustness of adversarial training. InICML, 2019. 13, 14
work page 2019
-
[61]
Lauren Watson, Chuan Guo, Graham Cormode, and Alex Sablayrolles. On the importance of difficulty calibra- tion in membership inference attacks.arXiv preprint arXiv:2111.08440, 2021. 1, 3, 12, 18
-
[62]
Adversarial weight perturbation helps robust generalization
Dongxian Wu, Shu-Tao Xia, and Yisen Wang. Adversarial weight perturbation helps robust generalization. InNeurIPS,
-
[63]
Hui Y Xiong, Babak Alipanahi, Leo J Lee, Hannes Bretschneider, Daniele Merico, Ryan KC Yuen, Yimin Hua, Serge Gueroussov, Hamed S Najafabadi, Timothy R Hughes, et al. The human splicing code reveals new insights into the genetic determinants of disease.Science, 347(6218), 2015. 12
work page 2015
-
[64]
Enhanced membership in- ference attacks against machine learning models
Jiayuan Ye, Aadyaa Maddi, Sasi Kumar Murakonda, Vincent Bindschaedler, and Reza Shokri. Enhanced membership in- ference attacks against machine learning models. InACM SIGSAC Conference on Computer and Communications Se- curity, 2022. 1, 2, 3, 4, 8, 12, 18, 19
work page 2022
-
[65]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. InIEEE computer security foundations symposium, 2018. 1, 3, 4, 8, 12, 13, 19
work page 2018
-
[66]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. InBMVC, 2016. 8, 19
work page 2016
-
[67]
Low-cost high-power membership inference attacks
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. Low-cost high-power membership inference attacks. InICML, 2024. 1, 3, 4, 8, 12, 19, 20
work page 2024
-
[68]
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning (still) re- quires rethinking generalization.Communications of the ACM, 64:107–115, 2021. 13
work page 2021
-
[69]
Geometry-aware instance-reweighted adversarial training
Jingfeng Zhang, Jianing Zhu, Gang Niu, Bo Han, Masashi Sugiyama, and Mohan Kankanhalli. Geometry-aware instance-reweighted adversarial training. InICLR, 2021. 14
work page 2021
-
[70]
Dual-path distillation: A unified framework to improve black- box attacks
Yonggang Zhang, Ya Li, Tongliang Liu, and Xinmei Tian. Dual-path distillation: A unified framework to improve black- box attacks. InICML, 2020. 13 A. Related Works A.1. Privacy Risks in Machine Learning Machine learning(ML) models, particularly deep neural networks, have become integral to advancements in vari- ous high-stakes domains such as healthcare, ...
work page 2020
-
[71]
introduced a simple refinement of FGSM, which is the projected gradient descent (PGD) attack. Instead of taking a single step of size ϵ in the direction of the gradient sign, multiple smaller steps are taken in PGD (the result is clipped by the same ϵ). Specifically, we start with setting x0 =x , and then in each iteration: x′ (t+1) = ΠBϵ[x(0)](x′ (t) +αs...
-
[72]
Motivated by this, [5] replaced the CE loss with several possible choices
observed the phenomenon of gradient vanishing in the widely used CE loss for potential failure. Motivated by this, [5] replaced the CE loss with several possible choices. Among these choices, the widely used one for the untargeted attack is CW(x, y) =−z y(x′) + max i̸=y zi(x′).(21) wherezis the logits of the model outputs. AutoAttack and Minimum Margin at...
-
[73]
argued that the high computational cost ofAutoAttack is unnecessary for identifyingthe most adversarial example: Definition 6(The most adversarial example).Given a natu- ral example x with its true label y and, the most adversarial examplex ∗ withinB ϵ[x]is defined as: ∀x′ ∈ B ϵ[x], x∗ = arg max x′ −(zy(x′)−max i̸=y zi(x′)), (22) where Bϵ[x] ={x ′ |d ∞(x,...
-
[74]
Shadow Models.ForAttack R[ 64], we train 100 reference models (OUT-Models)
The learning rate is initialized to τ= 0.1 and follows a cosine annealing schedule, gradually decaying to zero over 100 epochs. Shadow Models.ForAttack R[ 64], we train 100 reference models (OUT-Models). ForLiRA[ 7] andRMIA[ 67], we train 100 IN-Models and 100 OUT-Models for modeling ˜Qin/out, and ensure that the same shadow models are used across differe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.