Recognition: no theorem link
CharTool: Tool-Integrated Visual Reasoning for Chart Understanding
Pith reviewed 2026-05-13 20:03 UTC · model grok-4.3
The pith
Equipping multimodal models with cropping and code tools improves chart reasoning via agentic reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
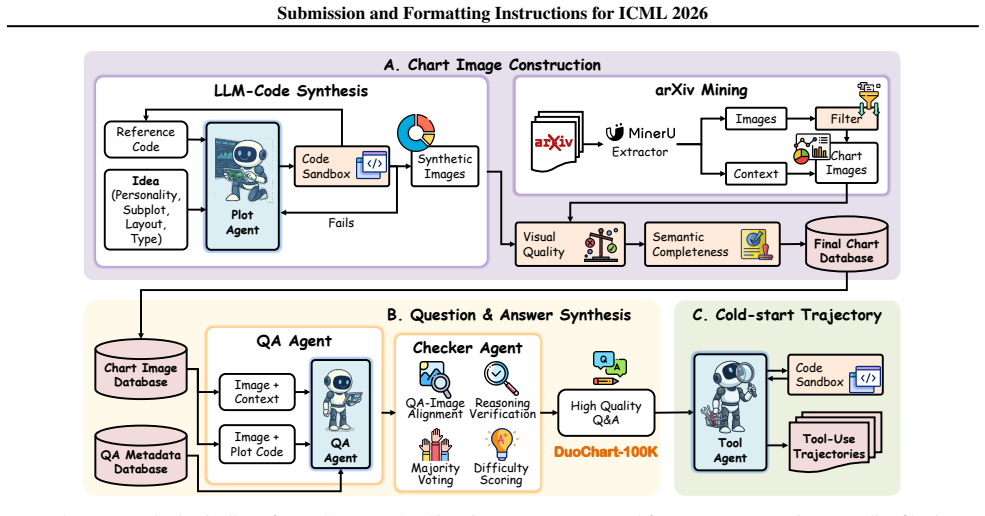
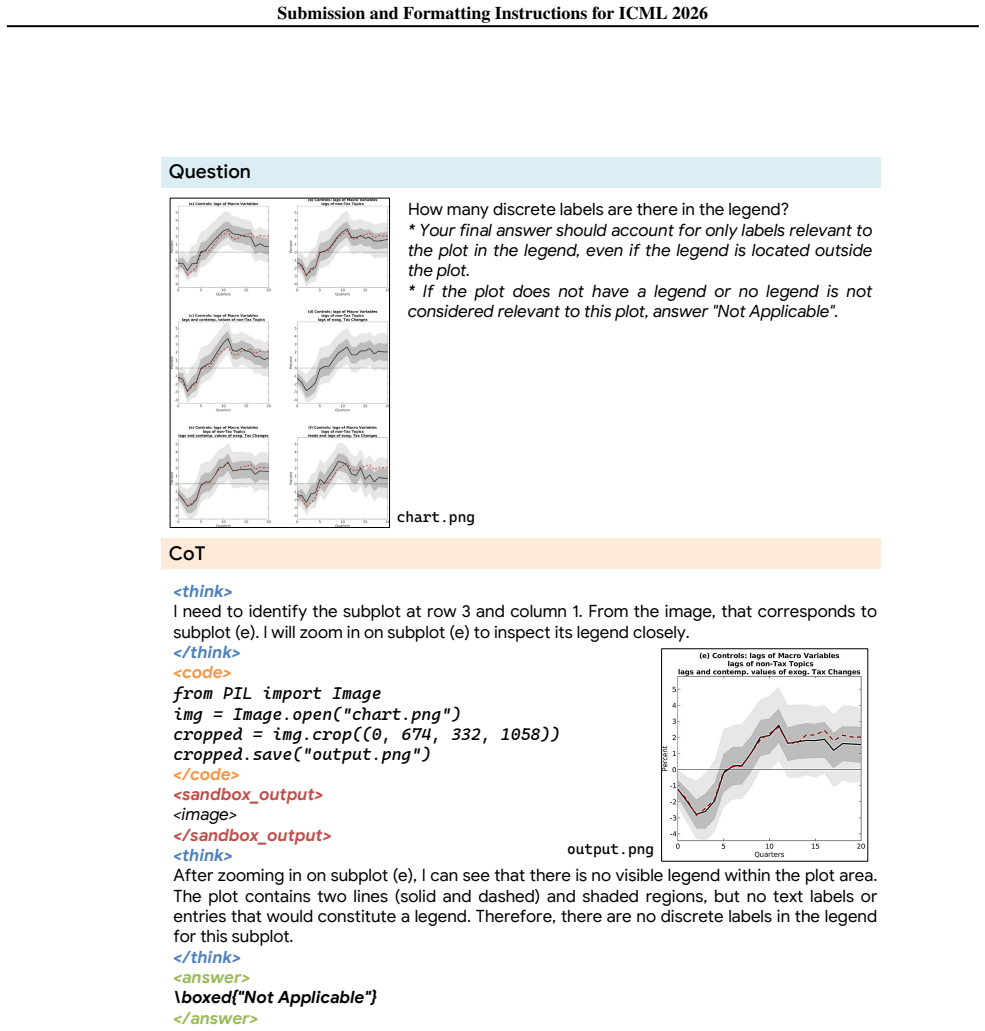
CharTool equips MLLMs with external tools for image cropping and code-based computation, then uses agentic reinforcement learning on the DuoChart dual-source dataset to learn tool-integrated reasoning that is grounded directly in chart content.
What carries the argument
Agentic reinforcement learning that trains the model to call image-cropping and code-execution tools during chart reasoning.
Load-bearing premise
The reported gains are produced by the tool integration and agentic reinforcement learning rather than by the specific data mixture or other training details.
What would settle it
An ablation that trains the identical base model on the same DuoChart data without the cropping or code tools and checks whether benchmark scores stay essentially unchanged.
Figures










read the original abstract
Charts are ubiquitous in scientific and financial literature for presenting structured data. However, chart reasoning remains challenging for multimodal large language models (MLLMs) due to the lack of high-quality training data, as well as the need for fine-grained visual grounding and precise numerical computation. To address these challenges, we first propose DuoChart, a scalable dual-source data pipeline that combines synthesized charts with real-world charts to construct diverse, high-quality chart training data. We then introduce CharTool, which equips MLLMs with external tools, including image cropping for localized visual perception and code-based computation for accurate numerical reasoning. Through agentic reinforcement learning on DuoChart, CharTool learns tool-integrated reasoning grounded in chart content. Extensive experiments on six chart benchmarks show that our method consistently improves over strong MLLM baselines across model scales. Notably, CharTool-7B outperforms the base model by **+8.0%** on CharXiv (Reasoning) and **+9.78%** on ChartQAPro, while achieving competitive performance with substantially larger or proprietary models. Moreover, CharTool demonstrates positive generalization to out-of-domain visual math reasoning benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DuoChart, a dual-source data pipeline that synthesizes charts and augments them with real-world examples to create high-quality training data, and CharTool, an MLLM equipped with image-cropping and code-execution tools. The model is trained via agentic reinforcement learning on DuoChart to perform tool-integrated visual reasoning. Experiments across six chart benchmarks report consistent gains over base MLLMs, with CharTool-7B achieving +8.0% on CharXiv (Reasoning) and +9.78% on ChartQAPro while remaining competitive with larger or proprietary models and showing positive transfer to out-of-domain visual math tasks.
Significance. If the performance gains can be robustly attributed to tool integration and agentic RL rather than the DuoChart data mixture alone, the work would meaningfully advance tool-augmented multimodal reasoning for structured visual data. It offers a practical recipe combining scalable data synthesis with external perception and computation tools, which could influence future MLLM designs for scientific, financial, and analytical chart tasks. The reported generalization beyond the training distribution is a positive signal for broader applicability.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and associated tables: No ablation is reported that fine-tunes the base MLLM on identical DuoChart data without tool calling or agentic RL. This control is required to substantiate the central attribution that the +8.0% CharXiv and +9.78% ChartQAPro gains arise specifically from tool-integrated reasoning rather than data quality.
- [Tables 1–3] Tables 1–3 (benchmark results): All reported scores are single point estimates with no error bars, standard deviations, or details on the number of random seeds or runs. Given the stochasticity of RL training, this omission prevents assessment of whether the headline improvements are statistically reliable.
minor comments (2)
- [§3.2] §3.2 (Agentic RL): The reward formulation and tool-calling loop would benefit from pseudocode or a concise algorithm box to clarify the interaction between perception, code execution, and policy updates.
- [Abstract] Abstract and §1: The six evaluation benchmarks are referenced but not enumerated; listing their names would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the attribution of gains in our work. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated tables: No ablation is reported that fine-tunes the base MLLM on identical DuoChart data without tool calling or agentic RL. This control is required to substantiate the central attribution that the +8.0% CharXiv and +9.78% ChartQAPro gains arise specifically from tool-integrated reasoning rather than data quality.
Authors: We agree that the requested ablation—fine-tuning the base MLLM on the identical DuoChart mixture without tools or agentic RL—would provide a cleaner isolation of the tool-integration and RL components. The current manuscript compares CharTool against the unmodified base MLLM (which has not seen DuoChart) and against other chart-specialized models, but does not include this exact control. In the revised version we will add this ablation for the 7B scale on the primary benchmarks (CharXiv Reasoning and ChartQAPro) and report the resulting deltas. This will allow readers to quantify how much of the observed improvement is attributable to the data mixture versus the tool-augmented agentic training. revision: yes
-
Referee: [Tables 1–3] Tables 1–3 (benchmark results): All reported scores are single point estimates with no error bars, standard deviations, or details on the number of random seeds or runs. Given the stochasticity of RL training, this omission prevents assessment of whether the headline improvements are statistically reliable.
Authors: We acknowledge that single-run point estimates limit statistical assessment, particularly for RL-trained models. All numbers in Tables 1–3 were obtained from single training and evaluation runs due to the substantial compute required for agentic RL at the 7B and 13B scales. In the revision we will rerun the main CharTool-7B experiments with three random seeds, report mean and standard deviation for the headline metrics on CharXiv and ChartQAPro, and add a brief note on seed count and variance in the experimental setup section. revision: yes
Circularity Check
No circularity; empirical benchmark results with no derivations or self-referential fits
full rationale
The paper describes an empirical pipeline (DuoChart data synthesis + tool-equipped MLLM trained via agentic RL) and reports performance lifts on external benchmarks (CharXiv, ChartQAPro, etc.). No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. All claims rest on direct comparisons to baselines and larger models on held-out datasets, which are independent of the training mixture. No self-citations are used to justify core premises. This is a standard empirical ML contribution whose central attribution (tool integration + RL) is tested via ablation-style experiments rather than being definitionally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abaskohi, A., Gella, S., Carenini, G., and Laradji, I. H. FM2DS: few-shot multimodal multihop data synthesis with knowledge distillation for question answering. CoRR, abs/2412.07030, 2024. doi:10.48550/ARXIV.2412.07030
-
[2]
Claude 3.5 sonnet model card addendum, 2024
Anthropic . Claude 3.5 sonnet model card addendum, 2024
work page 2024
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X.-H., Cheng, Z., Deng, L., Ding, W., Fang, R., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, Q., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L. Y., Ren, X., yi Ren, X., Song, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report. CoRR, abs/2502.13923, 2025 b . doi:10.48550/ARXIV.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[5]
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., and Shou, M. Z. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Bytedance-Seed-Foundation-Code-Team, :, Cheng, Y., Chen, J., Chen, J., Chen, L., Chen, L., Chen, W., Chen, Z., Geng, S., Li, A., Li, B., Li, B., Li, L., Liu, B., Liu, J., Liu, K., Liu, Q., Liu, S., Liu, S., Liu, T., Liu, T., Liu, Y., Long, R., Mai, J., Ning, G., Peng, Z. Y., Shen, K., Su, J., Su, J., Sun, T., Sun, Y., Tao, Y., Wang, G., Wang, S., Wang, X....
-
[7]
Chart-based reasoning: Transferring capabilities from llms to vlms
Carbune, V., Mansoor, H., Liu, F., Aralikatte, R., Baechler, G., Chen, J., and Sharma, A. Chart-based reasoning: Transferring capabilities from llms to vlms. In Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024 , volume NAACL 2024 of Findings of ACL , pp.\ 989--1004. Association for Computational ...
-
[8]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
Chan, X., Wang, X., Yu, D., Mi, H., and Yu, D. Scaling synthetic data creation with 1,000,000,000 personas. arXiv, abs/2406.20094, 2024
-
[9]
Onechart: Purify the chart structural extraction via one auxiliary token
Chen, J., Kong, L., Wei, H., Liu, C., Ge, Z., Zhao, L., Sun, J., Han, C., and Zhang, X. Onechart: Purify the chart structural extraction via one auxiliary token. In Proceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 2024 , pp.\ 147--155. ACM , 2024. doi:10.1145/3664647.3681167
-
[10]
Chart-r1: Chain-of-thought supervision and reinforcement for advanced chart reasoner
Chen, L., Zhao, X., Zeng, Z., Huang, J., Zhong, Y., and Ma, L. Chart-r1: Chain-of-thought supervision and reinforcement for advanced chart reasoner. arXiv preprint arXiv:2507.15509, 2025
-
[11]
X., Luan, Z., Dai, B., and Zhang, Z
Cheng, D., Huang, S., Zhu, Z., Zhang, X., Zhao, W. X., Luan, Z., Dai, B., and Zhang, Z. On domain-adaptive post-training for multimodal large language models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 274--296, Suzhou, China, November 2025. Association for Computational Linguistics. doi:10.18653/v1/2025.findings-emnlp.17
-
[12]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
GRIT: Teaching MLLMs to Think with Images
Fan, Y., He, X., Yang, D., Zheng, K., Kuo, C.-C., Zheng, Y., Narayanaraju, S. J., Guan, X., and Wang, X. E. Grit: Teaching mllms to think with images. ArXiv, abs/2505.15879, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., et al. A survey on llm-as-a-judge. The Innovation, 2024
work page 2024
-
[15]
Chartllama: A multimodal llm for chart understanding and generation
Han, Y., Zhang, C., Chen, X., Yang, X., Wang, Z., Yu, G., Fu, B., and Zhang, H. Chartllama: A multimodal llm for chart understanding and generation. arXiv preprint arXiv:2311.16483, 2023
-
[16]
Distill visual chart reasoning ability from LLM s to MLLM s
He, W., Xi, Z., Zhao, W., Fan, X., Ding, Y., Shan, Z., Gui, T., Zhang, Q., and Huang, X. Distill visual chart reasoning ability from LLM s to MLLM s. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 3224--3250, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-89176-335-7. doi:10.18653/v1/202...
-
[17]
Deepeyesv2: Toward agentic multimodal model
Hong, J., Zhao, C., Zhu, C., Lu, W., Xu, G., and Yu, X. Deepeyesv2: Toward agentic multimodal model. ArXiv, abs/2511.05271, 2025
-
[18]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Hu, Y., and Lin, S. Vision-r1: Incentivizing reasoning capability in multimodal large language models. CoRR, abs/2503.06749, 2025. doi:10.48550/ARXIV.2503.06749
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.06749 2025
-
[19]
Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought
Jiang, C., Heng, Y., Ye, W., Yang, H., Xu, H., Yan, M., Zhang, J., Huang, F., and Zhang, S. Vlm-r3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought. ArXiv, abs/2505.16192, 2025
-
[20]
O., Wang, D., Zamani, H., and Han, J
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S. O., Wang, D., Zamani, H., and Han, J. Search-r1: Training LLM s to reason and leverage search engines with reinforcement learning. In Second Conference on Language Modeling, 2025
work page 2025
-
[21]
Kantharaj, S., Do, X. L., Leong, R. T., Tan, J. Q., Hoque, E., and Joty, S. Opencqa: Open-ended question answering with charts. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 11817--11837, 2022
work page 2022
-
[22]
Lai, X., Li, J., Li, W., Liu, T., Li, T., and Zhao, H. Mini-o3: Scaling up reasoning patterns and interaction turns for visual search. ArXiv, abs/2509.07969, 2025
-
[23]
R., Hu, H., Liu, F., Eisenschlos, J
Lee, K., Joshi, M., Turc, I. R., Hu, H., Liu, F., Eisenschlos, J. M., Khandelwal, U., Shaw, P., Chang, M., and Toutanova, K. Pix2struct: Screenshot parsing as pretraining for visual language understanding. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , volume 202 of Proceedings of Machine Learning Rese...
work page 2023
-
[24]
From generation to judgment: Opportunities and challenges of LLM -as-a-judge
Li, D., Jiang, B., Huang, L., Beigi, A., Zhao, C., Tan, Z., Bhattacharjee, A., Jiang, Y., Chen, C., Wu, T., Shu, K., Cheng, L., and Liu, H. From generation to judgment: Opportunities and challenges of LLM -as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 2757--2791, Suzhou, China, 2025 a . Associa...
work page 2025
-
[25]
Torl: Scaling tool-integrated rl, 2025 b
Li, X., Zou, H., and Liu, P. Torl: Scaling tool-integrated rl, 2025 b . URL https://arxiv.org/abs/2503.23383
-
[26]
Li, Z., Jasani, B. A., Tang, P., and Ghadar, S. Synthesize step-by-step: Tools, templates and llms as data generators for reasoning-based chart vqa. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 13613--13623, 2024
work page 2024
-
[27]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
M., Piccinno, F., Krichene, S., Pang, C., Lee, K., Joshi, M., Chen, W., Collier, N., and Altun, Y
Liu, F., Eisenschlos, J. M., Piccinno, F., Krichene, S., Pang, C., Lee, K., Joshi, M., Chen, W., Collier, N., and Altun, Y. Deplot: One-shot visual language reasoning by plot-to-table translation. In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023 , volume ACL 2023 of Findings of ACL , pp.\ 10381--1039...
-
[29]
M at C ha: Enhancing visual language pretraining with math reasoning and chart derendering
Liu, F., Piccinno, F., Krichene, S., Pang, C., Lee, K., Joshi, M., Altun, Y., Collier, N., and Eisenschlos, J. M at C ha: Enhancing visual language pretraining with math reasoning and chart derendering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 12756--12770, Toronto, Canada, Ju...
-
[30]
MMC : Advancing multimodal chart understanding with large-scale instruction tuning
Liu, F., Wang, X., Yao, W., Chen, J., Song, K., Cho, S., Yacoob, Y., and Yu, D. MMC : Advancing multimodal chart understanding with large-scale instruction tuning. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 1287--1310, Mexic...
-
[31]
Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual instruction tuning. arXiv, abs/2304.08485, 2023 c
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Chartthinker: A contextual chain-of-thought approach to optimized chart summarization
Liu, M., Chen, D., Li, Y., Fang, G., and Shen, Y. Chartthinker: A contextual chain-of-thought approach to optimized chart summarization. ArXiv, abs/2403.11236, 2024 c
-
[33]
Liu, S., Liu, H., Liu, J., Xiao, L., Gao, S., Lyu, C., Gu, Y., Zhang, W., Wong, D. F., Zhang, S., and Chen, K. C ompass V erifier: A unified and robust verifier for LLM s evaluation and outcome reward. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 33466--33494, Suzhou, China, November 2025 a . Association ...
-
[34]
Visual agentic reinforcement fine-tuning
Liu, Z., Zang, Y., Zou, Y., Liang, Z., wen Dong, X., Cao, Y., Duan, H., Lin, D., and Wang, J. Visual agentic reinforcement fine-tuning. ArXiv, abs/2505.14246, 2025 b
-
[35]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.-W., Galley, M., and Gao, J. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[36]
doi: 10.18653/v1/2022.findings-acl.177
Masry, A., Long, D. X., Tan, J. Q., Joty, S., and Hoque, E. C hart QA : A benchmark for question answering about charts with visual and logical reasoning. In Findings of the Association for Computational Linguistics: ACL 2022, pp.\ 2263--2279, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi:10.18653/v1/2022.findings-acl.177
-
[37]
S., Ahmed, M., Bajaj, A., Kabir, F., Kartha, A., Laskar, M
Masry, A., Islam, M. S., Ahmed, M., Bajaj, A., Kabir, F., Kartha, A., Laskar, M. T. R., Rahman, M., Rahman, S., Shahmohammadi, M., Thakkar, M., Parvez, M. R., Hoque, E., and Joty, S. C hart QAP ro: A more diverse and challenging benchmark for chart question answering. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 19123--1915...
-
[38]
A., Thakkar, M., Mahajan, K., Yadav, V., Madhusudhan, S
Masry, A., Puri, A., Hashemi, M., Rodriguez, J. A., Thakkar, M., Mahajan, K., Yadav, V., Madhusudhan, S. T., Pich \'e , A., Bahdanau, D., Pal, C., Vazquez, D., Hoque, E., Taslakian, P., Rajeswar, S., and Gella, S. Bigcharts-r1: Enhanced chart reasoning with visual reinforcement finetuning. In Second Conference on Language Modeling, 2025 b
work page 2025
-
[39]
Chartgemma: Visual instruction-tuning for chart reasoning in the wild
Masry, A., Thakkar, M., Bajaj, A., Kartha, A., Hoque, E., and Joty, S. Chartgemma: Visual instruction-tuning for chart reasoning in the wild. In Proceedings of the 31st International Conference on Computational Linguistics: Industry Track, pp.\ 625--643, 2025 c
work page 2025
-
[40]
Meng, F., Shao, W., Lu, Q., Gao, P., Zhang, K., Qiao, Y., and Luo, P. C hart A ssistant: A universal chart multimodal language model via chart-to-table pre-training and multitask instruction tuning. In Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 7775--7803, Bangkok, Thailand, August 2024. Association for Computational Linguis...
-
[41]
Niu, J., Liu, Z., Gu, Z., Wang, B., Ouyang, L., Zhao, Z., Chu, T., He, T., Wu, F., Zhang, Q., et al. Mineru2.5: A decoupled vision-language model for efficient high-resolution document parsing. arXiv preprint arXiv:2509.22186, 2025
-
[42]
OpenAI . Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
OpenAI . Hello gpt-4o, 2024. URL https://openai.com/index/hello-gpt-4o/
work page 2024
-
[44]
C., He, Q., WANG, H., Chen, X., Hakkani-T \"u r, D., Tur, G., and Ji, H
Qian, C., Acikgoz, E. C., He, Q., WANG, H., Chen, X., Hakkani-T \"u r, D., Tur, G., and Ji, H. Tool RL : Reward is all tool learning needs. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[45]
Qiao, R., Tan, Q., Dong, G., MinhuiWu, M., Sun, C., Song, X., Wang, J., GongQue, Z., Lei, S., Zhang, Y., Wei, Z., Zhang, M., Qiao, R., Zong, X., Xu, Y., Yang, P., Bao, Z., Diao, M., Li, C., and Zhang, H. We-math: Does your large multimodal model achieve human-like mathematical reasoning? In Proceedings of the 63rd Annual Meeting of the Association for Com...
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y. K., Wu, Y., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. CoRR, abs/2402.03300, 2024. doi:10.48550/ARXIV.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[47]
Hybridflow: A flexible and efficient rlhf framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., and Wu, C. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys '25, pp.\ 1279–1297, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 9798400711961. doi:10.1145/3689031.3696075
-
[48]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Song, H., Jiang, J., Min, Y., Chen, J., Chen, Z., Zhao, W. X., Fang, L., and Wen, J.-R. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Domino: A dual-system for multi-step visual language reasoning
Wang, P., Golovneva, O., Aghajanyan, A., Ren, X., Chen, M., Celikyilmaz, A., and Fazel-Zarandi, M. Domino: A dual-system for multi-step visual language reasoning. ArXiv, abs/2310.02804, 2023
-
[50]
Charxiv: Charting gaps in realistic chart understanding in multimodal llms
Wang, Z., Xia, M., He, L., Chen, H., Liu, Y., Zhu, R., Liang, K., Wu, X., Liu, H., Malladi, S., Chevalier, A., Arora, S., and Chen, D. Charxiv: Charting gaps in realistic chart understanding in multimodal llms. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver,...
work page 2024
- [51]
-
[52]
Wu, M., Yang, J., Jiang, J., Li, M., Yan, K., Yu, H., Zhang, M., Zhai, C., and Nahrstedt, K. Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use. ArXiv, abs/2505.19255, 2025
-
[53]
Chartx and chartvlm: A versatile benchmark and foundation model for complicated chart reasoning
Xia, R., Ye, H., Yan, X., Liu, Q., Zhou, H., Chen, Z., Shi, B., Yan, J., and Zhang, B. Chartx and chartvlm: A versatile benchmark and foundation model for complicated chart reasoning. IEEE Trans. Image Process. , 34: 0 7436--7447, 2025. doi:10.1109/TIP.2025.3607618
-
[54]
Chartadapter: Large vision-language model for chart summarization
Xu, P., Ding, Y., and Fan, W. Chartadapter: Large vision-language model for chart summarization. CoRR, abs/2412.20715, 2024. doi:10.48550/ARXIV.2412.20715
-
[55]
Chartbench: A benchmark for complex visual reasoning in charts
Xu, Z., Du, S., Qi, Y., Xu, C., Yuan, C., and Guo, J. Chartbench: A benchmark for complex visual reasoning in charts. CoRR, abs/2312.15915, 2023. doi:10.48550/ARXIV.2312.15915
-
[56]
Chartmoe: Mixture of diversely aligned expert connector for chart understanding
Xu, Z., Qu, B., Qi, Y., Du, S., Xu, C., Yuan, C., and Guo, J. Chartmoe: Mixture of diversely aligned expert connector for chart understanding. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025
work page 2025
-
[57]
Chartmimic: Evaluating lmm's cross-modal reasoning capability via chart-to-code generation
Yang, C., Shi, C., Liu, Y., Shui, B., Wang, J., Jing, M., Xu, L., Zhu, X., Li, S., Zhang, Y., Liu, G., Nie, X., Cai, D., and Yang, Y. Chartmimic: Evaluating lmm's cross-modal reasoning capability via chart-to-code generation. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025 a
work page 2025
-
[58]
Effective training data synthesis for improving MLLM chart understanding
Yang, Y., Zhang, Z., Hou, Y., Li, Z., Liu, G., Payani, A., Ting, Y.-S., and Zheng, L. Effective training data synthesis for improving MLLM chart understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 2653--2663, 2025 b
work page 2025
-
[59]
Matplotagent: Method and evaluation for llm-based agentic scientific data visualization
Yang, Z., Zhou, Z., Wang, S., Cong, X., Han, X., Yan, Y., Liu, Z., Tan, Z., Liu, P., Yu, D., Liu, Z., Shi, X., and Sun, M. Matplotagent: Method and evaluation for llm-based agentic scientific data visualization. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 , volume ACL 20...
-
[60]
Ye, J., Hu, A., Xu, H., Ye, Q., Yan, M., Xu, G., Li, C., Tian, J., Qian, Q., Zhang, J., Jin, Q., He, L., Lin, X., and Huang, F. Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model. In Conference on Empirical Methods in Natural Language Processing, 2023 a
work page 2023
-
[61]
mplug-owi2: Revolutionizing multi-modal large language model with modality collaboration
Ye, Q., Xu, H., Ye, J., Yan, M., Hu, A., Liu, H., Qian, Q., Zhang, J., Huang, F., and Zhou, J. mplug-owi2: Revolutionizing multi-modal large language model with modality collaboration. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 13040--13051, 2023 b
work page 2024
-
[62]
LAMM: language-assisted multi-modal instruction-tuning dataset, framework, and benchmark
Yin, Z., Wang, J., Cao, J., Shi, Z., Liu, D., Li, M., Huang, X., Wang, Z., Sheng, L., Bai, L., Shao, J., and Ouyang, W. LAMM: language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans...
work page 2023
-
[63]
C., Savarese, S., Xiong, C., Chen, Z., Krishna, R., and Xu, R
Zhang, J., Xue, L., Song, L., Wang, J., Huang, W., Shu, M., Yan, A., Ma, Z., Niebles, J. C., Savarese, S., Xiong, C., Chen, Z., Krishna, R., and Xu, R. Provision: Programmatically scaling vision-centric instruction data for multimodal language models. ArXiv, abs/2412.07012, 2024 a
-
[64]
Zhang, L., Hu, A., Xu, H., Yan, M., Xu, Y., Jin, Q., Zhang, J., and Huang, F. T iny C hart: Efficient chart understanding with program-of-thoughts learning and visual token merging. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 1882--1898, Miami, Florida, USA, November 2024 b . Association for Computationa...
-
[65]
Zhang, R., Jiang, D., Zhang, Y., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K., Qiao, Y., Gao, P., and Li, H. MATHVERSE: does your multi-modal LLM truly see the diagrams in visual math problems? In Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part VIII , volume 15066 of Lecture N...
-
[66]
Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms
Zhang, X., Gao, Z., Zhang, B., Li, P., Zhang, X., Liu, Y., Yuan, T., Wu, Y., Jia, Y., Zhu, S.-C., and Li, Q. Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms. 2025 a
work page 2025
-
[67]
Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
Zhang, Y., Lu, X., Yin, S., Fu, C., Chen, W., Hu, X., Wen, B., Jiang, K., Liu, C., Zhang, T., Fan, H., Chen, K., Chen, J., Ding, H., Tang, K., Zhang, Z., Wang, L., Yang, F., Gao, T., and Zhou, G. Thyme: Think beyond images. CoRR, abs/2508.11630, 2025 b . doi:10.48550/ARXIV.2508.11630
-
[68]
SWIFT: A scalable lightweight infrastructure for fine-tuning
Zhao, Y., Huang, J., Hu, J., Wang, X., Mao, Y., Zhang, D., Jiang, Z., Wu, Z., Ai, B., Wang, A., Zhou, W., and Chen, Y. Swift: A scalable lightweight infrastructure for fine-tuning. Proceedings of the AAAI Conference on Artificial Intelligence, 39 0 (28): 0 29733--29735, Apr. 2025. doi:10.1609/aaai.v39i28.35383
-
[69]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., and Yu, X. Deepeyes: Incentivizing "thinking with images" via reinforcement learning. CoRR, abs/2505.14362, 2025. doi:10.48550/ARXIV.2505.14362
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.14362 2025
-
[70]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E., Wang, X., Cao, Y., Liu, Y., Wei, X., Zhang, H., Wang, H., Xu, W., Li, H., Wang, J., Deng, N., Li, S., He, Y., Jiang, T., Luo, J., Wang, Y., He, C., Shi, B., Zhang, X., Shao, W., He, J., Xiong, Y., Qu, W., Sun, P., Jiao, P., Lv, H., Wu, L., Zhang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.10479 2025
-
[71]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.