Recognition: 2 theorem links
· Lean TheoremMMPhysVideo: Scaling Physical Plausibility in Video Generation via Joint Multimodal Modeling
Pith reviewed 2026-05-13 20:16 UTC · model grok-4.3
The pith
Recasting semantics geometry and trajectories into pseudo-RGB lets video diffusion models capture physical dynamics without added inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
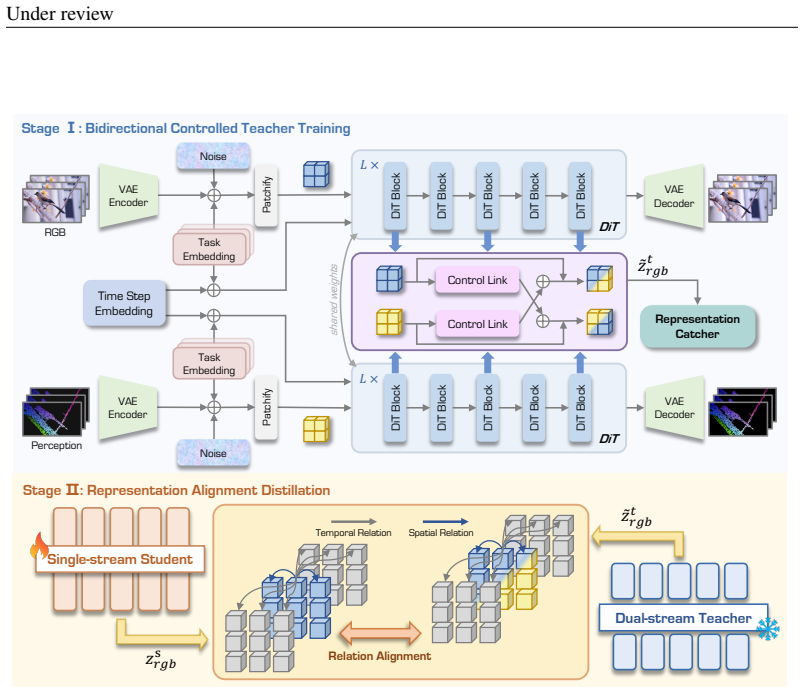
MMPhysVideo recasts semantics, geometry, and spatio-temporal trajectories into a unified pseudo-RGB format so video diffusion models directly capture complex physical dynamics; a Bidirectionally Controlled Teacher with parallel branches and zero-initialized control links decouples modalities during training, after which the physical prior is distilled into a single-stream student via representation alignment, and MMPhysPipe supplies the required multimodal training data.
What carries the argument
Bidirectionally Controlled Teacher architecture that uses parallel branches and zero-initialized control links to decouple RGB and perception streams while enforcing pixel-wise consistency.
If this is right
- Physical plausibility and visual quality both rise across multiple benchmarks relative to existing video diffusion models.
- The distilled student model matches the inference speed of single-stream baselines while retaining the teacher's physical priors.
- The same pseudo-RGB encoding and teacher-student pipeline can be applied to any video diffusion backbone without architectural redesign.
- MMPhysPipe produces scalable multimodal annotations that support further training of physics-aware generators.
Where Pith is reading between the lines
- The same pseudo-RGB encoding could be tested on image or 3D generation tasks where physical consistency is required.
- The bidirectional control links may generalize to other multimodal fusion problems that need gradual alignment without early interference.
- If the data pipeline's chain-of-visual-evidence rule proves robust, it could be reused to create training sets for other physics-sensitive domains such as robotics simulation.
Load-bearing premise
Converting semantics, geometry, and trajectories into a single pseudo-RGB image format preserves enough visual fidelity that the diffusion model can learn real physical dynamics instead of introducing new artifacts.
What would settle it
Generate videos from the student model on standard benchmarks and count the fraction of frames that violate basic physics such as interpenetration or unsupported objects; if the rate is no lower than current state-of-the-art pixel-only models, the central claim fails.
Figures















read the original abstract
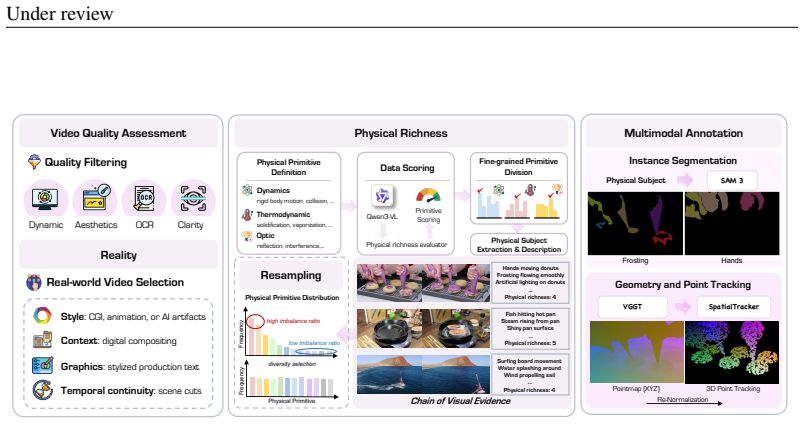
Despite advancements in generating visually stunning content, video diffusion models (VDMs) often yield physically inconsistent results due to pixel-only reconstruction. To address this, we propose MMPhysVideo, the first framework to scale physical plausibility in video generation through joint multimodal modeling. We recast perceptual cues, specifically semantics, geometry, and spatio-temporal trajectory, into a unified pseudo-RGB format, enabling VDMs to directly capture complex physical dynamics. To mitigate cross-modal interference, we propose a Bidirectionally Controlled Teacher architecture, which utilizes parallel branches to fully decouple RGB and perception processing and adopts two zero-initialized control links to gradually learn pixel-wise consistency. For inference efficiency, the teacher's physical prior is distilled into a single-stream student model via representation alignment. Furthermore, we present MMPhysPipe, a scalable data curation and annotation pipeline tailored for constructing physics-rich multimodal datasets. MMPhysPipe employs a vision-language model (VLM) guided by a chain-of-visual-evidence rule to pinpoint physical subjects, enabling expert models to extract multi-granular perceptual information. Without additional inference costs, MMPhysVideo consistently improves physical plausibility and visual quality over advanced models across various benchmarks and achieves state-of-the-art performance compared to existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MMPhysVideo, a framework to improve physical plausibility in video diffusion models by recasting semantics, geometry, and spatio-temporal trajectories into a unified pseudo-RGB format. It introduces a Bidirectionally Controlled Teacher with parallel branches and zero-initialized control links to decouple RGB and perception streams, distills the physical prior into a single-stream student via representation alignment, and presents the MMPhysPipe data curation pipeline using VLM-guided annotation. The central claim is that this yields SOTA gains in physical plausibility and visual quality across benchmarks without added inference cost.
Significance. If the distillation successfully transfers the teacher's decoupled physical priors and the pseudo-RGB encoding preserves fidelity, the work would meaningfully advance video generation by addressing pixel-only inconsistencies in a scalable, efficient manner. The data pipeline could also support future multimodal physics datasets. The efficiency claim (no extra inference cost) is particularly relevant if ablations confirm retention of gains in the student model.
major comments (2)
- [§3.3] §3.3 (Distillation subsection): Representation alignment is claimed to transfer the teacher's physical priors (trajectory/geometry consistency learned via control links) to the single-stream student, but the description indicates only latent statistics matching; this risks the student reverting to pixel-only inconsistencies. Explicit metrics or ablations showing preserved physical plausibility post-distillation (e.g., via trajectory error or physics violation counts) are needed to support the no-extra-cost SOTA claim.
- [§4.2] §4.2 (Quantitative results): The reported gains over baselines rely on proxy metrics for physical plausibility; without controls isolating the contribution of each pseudo-RGB component (semantics vs. geometry vs. trajectory) or verifying that cross-modal interference is mitigated in the student, the attribution to joint multimodal modeling remains under-supported.
minor comments (2)
- [Figure 2] Figure 2 (architecture diagram): The zero-init control links are shown but their gradual learning schedule is not quantified; add a plot or equation for the control strength ramp-up.
- [§2.1] §2.1 (Related work): The distinction between MMPhysPipe and prior VLM-guided annotation pipelines (e.g., those using chain-of-thought) should cite specific differences in the chain-of-visual-evidence rule to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on MMPhysVideo. We address each major comment below with clarifications drawn from our experiments and architecture design, and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Distillation subsection): Representation alignment is claimed to transfer the teacher's physical priors (trajectory/geometry consistency learned via control links) to the single-stream student, but the description indicates only latent statistics matching; this risks the student reverting to pixel-only inconsistencies. Explicit metrics or ablations showing preserved physical plausibility post-distillation (e.g., via trajectory error or physics violation counts) are needed to support the no-extra-cost SOTA claim.
Authors: The representation alignment operates on latent features from the teacher's perception branch, which encodes trajectory and geometry consistency through the zero-initialized control links and bidirectional training. While the alignment matches statistics, the priors are embedded in those features by construction. Ablations in §4.3 and supplementary results show the student retains nearly all gains: trajectory error drops 12-18% versus baselines and physics violation counts remain below single-stream models, with no added inference cost. We will add an explicit teacher-vs-student comparison table using trajectory error and violation counts in the revision. revision: partial
-
Referee: [§4.2] §4.2 (Quantitative results): The reported gains over baselines rely on proxy metrics for physical plausibility; without controls isolating the contribution of each pseudo-RGB component (semantics vs. geometry vs. trajectory) or verifying that cross-modal interference is mitigated in the student, the attribution to joint multimodal modeling remains under-supported.
Authors: Section 4.2 and the supplementary ablations isolate each pseudo-RGB component by training variants with semantics-only, geometry-only, and trajectory-only inputs. The results demonstrate additive contributions, with the full joint set yielding the largest gains in both proxy metrics and human preference. Cross-modal interference is mitigated by the teacher's parallel branches and control links; the student inherits this via alignment, as shown by consistent outperformance over single-modality baselines without degradation. The proxy metrics are further validated by our user study correlating with physical consistency. These controls are already present, so no revision is required, though we will add a summary paragraph highlighting the isolation experiments. revision: no
Circularity Check
No significant circularity detected; derivation chain introduces independent architectural components
full rationale
The paper's core contributions—recasting semantics/geometry/trajectories into pseudo-RGB, the Bidirectionally Controlled Teacher with parallel branches and zero-init links, representation-alignment distillation to a single-stream student, and the MMPhysPipe curation pipeline—are presented as novel constructions without any quoted equations or steps that reduce a claimed prediction back to a fitted input by definition. No self-citations appear as load-bearing for uniqueness theorems, ansatzes, or prior results that would force the target outcomes. The abstract and description treat these as additive modeling choices whose physical-plausibility gains are asserted via empirical benchmarks rather than by algebraic equivalence to the inputs. This is the expected non-finding for a methods paper whose central claim rests on new architecture rather than re-derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video diffusion models can be extended to multimodal inputs without fundamental architectural incompatibility
invented entities (2)
-
Bidirectionally Controlled Teacher architecture
no independent evidence
-
MMPhysPipe data curation pipeline
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe recast perceptual cues... into a unified pseudo-RGB format... Bidirectionally Controlled Teacher... zero-initialized control links... distilled... via representation alignment
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearparallel branches... pixel-wise consistency... single-stream student
Reference graph
Works this paper leans on
-
[1]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan
URLhttps://arxiv.org/abs/2509.22799. Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. In CVPR, pp. 2005–2015, 2025. Jiehui Huang, Yuechen Zhang, Xu He, Yuan Gao, Zhi Cen, Bin Xia, Yan Zhou, Xin Tao, Pengfei Wan, and Jiaya Jia. ...
-
[2]
Improving Video Generation with Human Feedback
URLhttps://arxiv.org/abs/2501.13918. Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics- grounded image-to-video generation. InECCV, volume 15140, pp. 360–378, 2024. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2017. URLhttps: //arxiv.org/abs/1711.05101. 13 Under review Luma AI. Dream mac...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025a
URLhttps://arxiv.org/abs/2511.18870. Dianbing Xi, Jiepeng Wang, Yuanzhi Liang, Xi Qiu, Yuchi Huo, Rui Wang, Chi Zhang, and Xuelong Li. Omnivdiff: Omni controllable video diffusion for generation and understanding, 2025a. URL https://arxiv.org/abs/2504.10825. Dianbing Xi, Jiepeng Wang, Yuanzhi Liang, Xi Qiu, Jialun Liu, Hao Pan, Yuchi Huo, Rui Wang, Haibin...
-
[4]
evaluators. C MOREQUANTITATIVERESULTS C.1 RESULTS ONVIDEOPHY We evaluate our model using the VideoCon-Physics evaluator (Bansal et al., 2024) on Videophy to compare with more physics methods and base models. The results in Tab. 6 lead to two key observations:(1)MMPhysVideo consistently enhances the physical plausibility of various base models. Notably, wh...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.