Recognition: no theorem link
InstructTable: Improving Table Structure Recognition Through Instructions
Pith reviewed 2026-05-13 20:50 UTC · model grok-4.3
The pith
Instruction-guided pre-training with synthetic data generation sets new performance standards for recognizing complex table structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
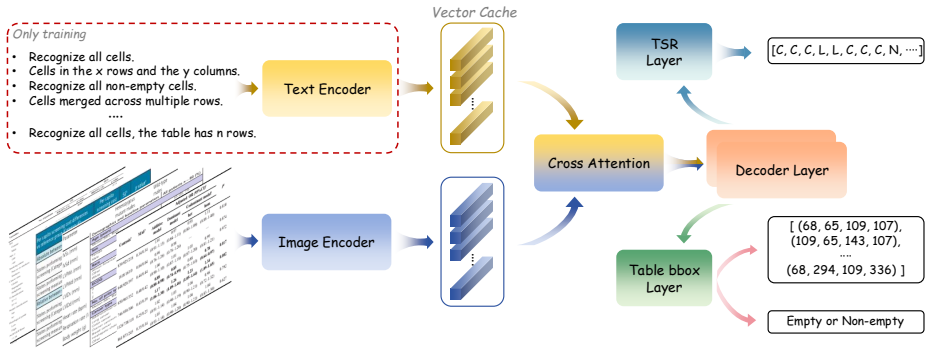
InstructTable is an instruction-guided multi-stage training TSR framework. Meticulously designed table instruction pre-training directs attention toward fine-grained structural patterns, enhancing comprehension of complex tables. Complementary TSR fine-tuning preserves robust visual information modeling, maintaining high-precision table parsing across diverse scenarios. The template-free Table Mix Expand method synthesizes large-scale authentic tabular data to build the BCDSTab benchmark of 900 complex table images, and the full pipeline achieves state-of-the-art results on FinTabNet, PubTabNet, MUSTARD, and BCDSTab.
What carries the argument
The InstructTable multi-stage training process that pairs table-specific instruction pre-training to emphasize structural patterns with subsequent visual fine-tuning, supported by the Table Mix Expand synthesis method for generating complex table images.
If this is right
- Higher accuracy on tables containing merged cells, empty cells, and other complex layouts that defeat purely visual models.
- A new public benchmark of 900 complex tables that can be used to measure progress on hard cases.
- Ablation evidence that both the instruction pre-training stage and the synthetic data contribute measurable gains.
- A training recipe that maintains visual precision while adding semantic guidance from instructions.
Where Pith is reading between the lines
- The same instruction-plus-fine-tuning pattern could be tested on other structured visual recognition tasks such as form parsing or chart understanding.
- Template-free synthesis may reduce reliance on expensive manual annotations for any document analysis domain that needs diverse layouts.
- If the designed instructions encode layout rules that hold across languages and document styles, the pre-training step could transfer with little additional labeled data.
Load-bearing premise
The hand-designed table instructions and TME-generated synthetic tables faithfully represent the distribution of real-world complex tables without introducing new biases or distribution shifts.
What would settle it
A controlled evaluation on a large set of previously unseen real-world photographed or scanned complex tables that shows InstructTable falling below the reported state-of-the-art accuracy.
Figures





read the original abstract
Table structure recognition (TSR) holds widespread practical importance by parsing tabular images into structured representations, yet encounters significant challenges when processing complex layouts involving merged or empty cells. Traditional visual-centric models rely exclusively on visual information while lacking crucial semantic support, thereby impeding accurate structural recognition in complex scenarios. Vision-language models leverage contextual semantics to enhance comprehension; however, these approaches underemphasize the modeling of visual structural information. To address these limitations, this paper introduces InstructTable, an instruction-guided multi-stage training TSR framework. Meticulously designed table instruction pre-training directs attention toward fine-grained structural patterns, enhancing comprehension of complex tables. Complementary TSR fine-tuning preserves robust visual information modeling, maintaining high-precision table parsing across diverse scenarios. Furthermore, we introduce Table Mix Expand (TME), an innovative template-free method for synthesizing large-scale authentic tabular data. Leveraging TME, we construct the Balanced Complex Dense Synthetic Tables (BCDSTab) benchmark, comprising 900 complex table images synthesized through our method to serve as a rigorous benchmark. Extensive experiments on multiple public datasets (FinTabNet, PubTabNet, MUSTARD) and BCDSTab demonstrate that InstructTable achieves state-of-the-art performance in TSR tasks. Ablation studies further confirm the positive impact of the proposed tabular-data-specific instructions and synthetic data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InstructTable, an instruction-guided multi-stage TSR framework that performs table-instruction pre-training to emphasize fine-grained structural patterns (merged/empty cells) followed by visual-preserving fine-tuning. It also presents the template-free Table Mix Expand (TME) synthesis method and the BCDSTab benchmark of 900 complex synthetic tables. Experiments report state-of-the-art results on FinTabNet, PubTabNet, MUSTARD and BCDSTab, supported by ablations on the instructions and synthetic data.
Significance. If the gains on complex layouts prove robust to distribution shift, the work offers a practical route to combine semantic instructions with visual modeling in TSR, addressing a known weakness of purely visual or under-constrained VLM approaches. TME and BCDSTab add reusable resources for data augmentation and evaluation; the multi-dataset empirical validation is a positive contribution if the new benchmark is shown to be independent.
major comments (2)
- [Section 3.3 and §4.2] BCDSTab construction (Section 3.3 and §4.2): the paper must explicitly confirm that the 900 BCDSTab images were strictly held out from the TME-augmented training corpus and must report distributional statistics (merge-pattern histograms, cell-density quantiles) comparing BCDSTab to FinTabNet/PubTabNet. Without this, the SOTA claim on BCDSTab is at risk of reflecting reduced domain gap rather than architectural improvement on genuinely complex real-world tables.
- [Table 2 and Table 3] Results tables (Table 2 and Table 3): the reported SOTA margins on complex subsets lack error bars, multiple random seeds, or full hyper-parameter protocols. Given that the central claim rests on reliable gains for merged/empty-cell cases, the absence of these details makes it impossible to judge whether the improvements are statistically stable or sensitive to post-hoc choices.
minor comments (2)
- [Section 3.1] The precise format and tokenization of the hand-designed table instructions should be shown with a concrete example in the main text (currently only referenced in the appendix).
- [Figure 4] Figure 4 (qualitative results) would benefit from side-by-side failure cases on public datasets to illustrate where InstructTable still errs on complex layouts.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Section 3.3 and §4.2] BCDSTab construction (Section 3.3 and §4.2): the paper must explicitly confirm that the 900 BCDSTab images were strictly held out from the TME-augmented training corpus and must report distributional statistics (merge-pattern histograms, cell-density quantiles) comparing BCDSTab to FinTabNet/PubTabNet. Without this, the SOTA claim on BCDSTab is at risk of reflecting reduced domain gap rather than architectural improvement on genuinely complex real-world tables.
Authors: We confirm that the 900 BCDSTab images were generated independently after the training corpus was finalized and were never included in any TME-augmented training data. In the revised manuscript we will add an explicit statement of this strict hold-out together with the requested distributional statistics, including merge-pattern histograms and cell-density quantiles, to demonstrate that BCDSTab occupies a distinct and more complex region of the data distribution relative to FinTabNet and PubTabNet. revision: yes
-
Referee: [Table 2 and Table 3] Results tables (Table 2 and Table 3): the reported SOTA margins on complex subsets lack error bars, multiple random seeds, or full hyper-parameter protocols. Given that the central claim rests on reliable gains for merged/empty-cell cases, the absence of these details makes it impossible to judge whether the improvements are statistically stable or sensitive to post-hoc choices.
Authors: We agree that reporting variability is important for claims on complex subsets. We will expand the experimental section with a complete hyper-parameter protocol and will add error bars derived from three independent random seeds for the key tables. These additional runs have already been performed and show consistent gains; the revised tables will report mean and standard deviation to allow readers to assess stability. revision: yes
Circularity Check
No circularity: empirical training and evaluation with independent public benchmarks
full rationale
The paper contains no equations, derivations, or parameter-fitting steps that could reduce predictions to inputs by construction. It describes an instruction-guided training framework plus a template-free synthesis method (TME) used to create both augmentation data and the BCDSTab test benchmark. Results on public datasets (FinTabNet, PubTabNet, MUSTARD) supply external validation independent of the synthetic distribution. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude 3.7 sonnet and claude code.https: / / www
Anthropic. Claude 3.7 sonnet and claude code.https: / / www . anthropic . com / news / claude - 3 - 7 - sonnet, 2025. 7
work page 2025
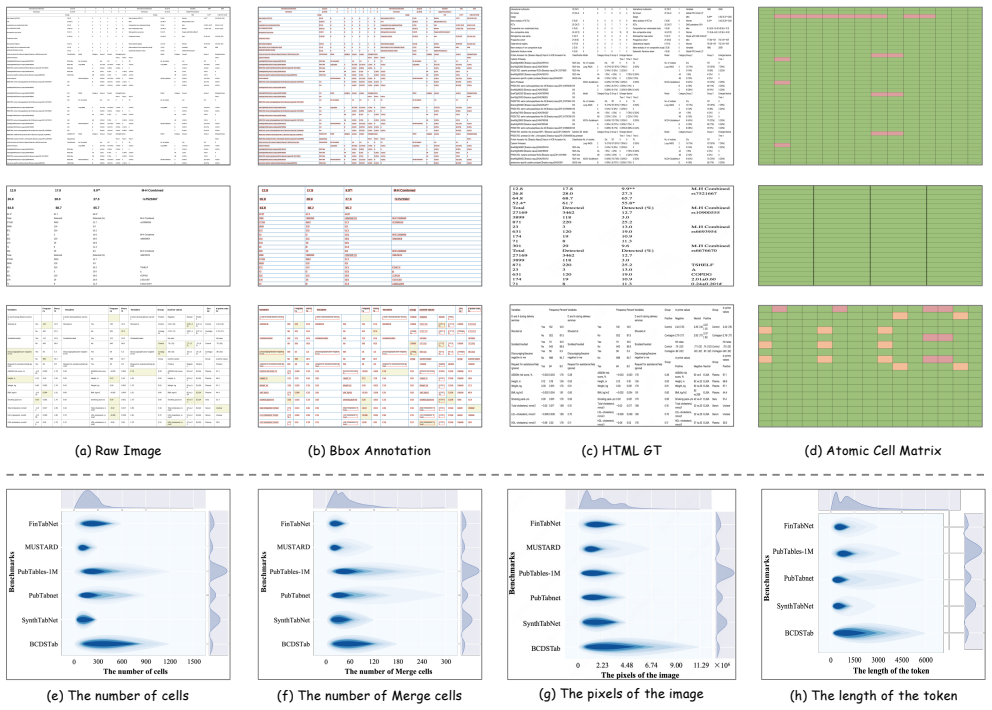
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Seed1.6 tech introduction.https://seed
ByteDance. Seed1.6 tech introduction.https://seed. bytedance.com/en/seed1_6, 2025. 2, 7
work page 2025
-
[4]
Comparing machine learning approaches for table recognition in historical reg- ister books
St ´ephane Clinchant, Herv ´e D ´ejean, Jean-Luc Meunier, Eva Maria Lang, and Florian Kleber. Comparing machine learning approaches for table recognition in historical reg- ister books. In2018 13th IAPR International Workshop on Document Analysis Systems (DAS), pages 133–138. IEEE,
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2, 4, 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9 B Ultra-Compact Vision-Language Model
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, et al. Paddleocr-vl: Boosting multilingual document parsing via a 0.9 b ultra-compact vision-language model.arXiv preprint arXiv:2510.14528, 2025. 3, 7
-
[7]
Micha ¨el Defferrard, Xavier Bresson, et al. Convolutional neural networks on graphs with fast localized spectral filter- ing.Advances in neural information processing systems, 29,
-
[8]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 5, 12
work page 2019
-
[9]
Instructocr: In- struction boosting scene text spotting
Chen Duan, Qianyi Jiang, Pei Fu, Jiamin Chen, Shengxi Li, Zining Wang, Shan Guo, and Junfeng Luo. Instructocr: In- struction boosting scene text spotting. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2807– 2815, 2025. 4
work page 2025
-
[10]
Max Gobel, Tamir Hassan, Ermelinda Oro, and Giorgio Orsi. ICDAR 2013 Table Competition . In2013 12th Interna- tional Conference on Document Analysis and Recognition (ICDAR), pages 1449–1453, Los Alamitos, CA, USA, 2013. IEEE Computer Society. 1
work page 2013
-
[11]
Tongkun Guan, Wei Shen, and Xiaokang Yang. Ccdplus: Towards accurate character to character distillation for text recognition.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 47(5):3546–3562, 2025. 3
work page 2025
-
[12]
A token-level text image foundation model for document understanding
Tongkun Guan, Zining Wang, Pei Fu, Zhengtao Guo, Wei Shen, Kai Zhou, Tiezhu Yue, Chen Duan, Hao Sun, Qianyi Jiang, Junfeng Luo, and Xiaokang Yang. A token-level text image foundation model for document understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 23210–23220, 2025. 3
work page 2025
-
[13]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Qiyu Hou and Jun Wang. Tablet: Table structure recog- nition using encoder-only transformers.arXiv preprint arXiv:2506.07015, 2025. 2, 7
-
[15]
Improving table structure recognition with visual-alignment sequential coordinate modeling
Yongshuai Huang, Ning Lu, Dapeng Chen, Yibo Li, Zecheng Xie, Shenggao Zhu, Liangcai Gao, and Wei Peng. Improving table structure recognition with visual-alignment sequential coordinate modeling. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11134–11143, 2023. 3, 6, 7
work page 2023
-
[16]
sprint: Script-agnostic structure recognition in tables
Dhruv Kudale, Badri Vishal Kasuba, Venkatapathy Sub- ramanian, Parag Chaudhuri, and Ganesh Ramakrishnan. sprint: Script-agnostic structure recognition in tables. InIn- ternational Conference on Document Analysis and Recogni- tion, pages 350–367. Springer, 2024. 3, 5, 7, 12
work page 2024
-
[17]
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Zidun Guo, Jiarui Zhang, Xinyu Wang, and Xiang Bai. Monkeyocr: Document parsing with a structure-recognition-relation triplet paradigm.arXiv preprint arXiv:2506.05218, 2025. 3, 7
-
[18]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, et al. Fully convolutional networks for semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 3431–3440, 2015. 2
work page 2015
-
[19]
Parsing table structures in the wild
Rujiao Long, Wen Wang, Nan Xue, Feiyu Gao, Zhibo Yang, Yongpan Wang, and Gui-Song Xia. Parsing table structures in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 944–952, 2021. 2
work page 2021
-
[20]
Rujiao Long, Hangdi Xing, Zhibo Yang, Qi Zheng, Zhi Yu, Fei Huang, and Cong Yao. Lore++: Logical location re- gression network for table structure recognition with pre- training.Pattern Recognition, 157:110816, 2025. 2
work page 2025
-
[21]
Nam Tuan Ly and Atsuhiro Takasu. An end-to-end multi- task learning model for image-based table recognition.arXiv preprint arXiv:2303.08648, 2023. 1, 7
-
[22]
Optimized table tokeniza- tion for table structure recognition
Maksym Lysak, Ahmed Nassar, Nikolaos Livathinos, Christoph Auer, and Peter Staar. Optimized table tokeniza- tion for table structure recognition. InInternational Confer- ence on Document Analysis and Recognition, pages 37–50. Springer, 2023. 3, 7
work page 2023
-
[23]
Gridformer: Towards accurate table structure recognition via grid prediction
Pengyuan Lyu, Weihong Ma, Hongyi Wang, Yuechen Yu, Chengquan Zhang, Kun Yao, Yang Xue, and Jingdong Wang. Gridformer: Towards accurate table structure recognition via grid prediction. InProceedings of the 31st ACM Interna- tional Conference on Multimedia, pages 7747–7757, 2023. 7
work page 2023
-
[24]
Chixiang Ma, Weihong Lin, Lei Sun, and Qiang Huo. Robust table detection and structure recognition from heterogeneous document images.Pattern Recognition, 133:109006, 2023. 2
work page 2023
-
[25]
Tableformer: Table structure understanding with transformers
Ahmed Nassar, Nikolaos Livathinos, Maksym Lysak, and Peter Staar. Tableformer: Table structure understanding with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4614– 4623, 2022. 1, 2, 3, 7, 12
work page 2022
- [26]
-
[27]
Hello gpt-4o.https : / / openai
OpenAI. Hello gpt-4o.https : / / openai . com / index/hello-gpt-4o, 2024. 3, 4, 7, 12
work page 2024
-
[28]
Introducing gpt-4.1 in the api.https : / / openai.com/index/gpt-4-1/, 2025
OpenAI. Introducing gpt-4.1 in the api.https : / / openai.com/index/gpt-4-1/, 2025. 7
work page 2025
-
[29]
Spatial as deep: Spatial cnn for traffic scene understanding
Xingang Pan, Jianping Shi, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Spatial as deep: Spatial cnn for traffic scene understanding. InProceedings of the AAAI conference on artificial intelligence, 2018. 2
work page 2018
-
[30]
ShengYun Peng, Aishwarya Chakravarthy, Seongmin Lee, Xiaojing Wang, Rajarajeswari Balasubramaniyan, and Duen Horng Chau. Unitable: Towards a unified framework for table recognition via self-supervised pretraining.arXiv preprint arXiv:2403.04822, 2024. 3, 7
-
[31]
Devashish Prasad, Ayan Gadpal, Kshitij Kapadni, Manish Visave, and Kavita Sultanpure. Cascadetabnet: An ap- proach for end to end table detection and structure recog- nition from image-based documents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 572–573, 2020. 2
work page 2020
-
[32]
Rethinking ta- ble recognition using graph neural networks
Shah Rukh Qasim, Hassan Mahmood, et al. Rethinking ta- ble recognition using graph neural networks. In2019 Inter- national Conference on Document Analysis and Recognition (ICDAR), pages 142–147. IEEE, 2019. 2
work page 2019
-
[33]
Lgpma: Complicated table structure recognition with local and global pyramid mask alignment
Liang Qiao, Zaisheng Li, Zhanzhan Cheng, Peng Zhang, Shiliang Pu, Yi Niu, Wenqi Ren, Wenming Tan, and Fei Wu. Lgpma: Complicated table structure recognition with local and global pyramid mask alignment. InInternational confer- ence on document analysis and recognition, pages 99–114. Springer, 2021. 2
work page 2021
-
[34]
Semv3: A fast and robust ap- proach to table separation line detection
Chunxia Qin, Zhenrong Zhang, Pengfei Hu, Chenyu Liu, Jiefeng Ma, and Jun Du. Semv3: A fast and robust ap- proach to table separation line detection. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 1191–1199. International Joint Conferences on Artificial Intelligence Organization, 2024. Main Track. 2
work page 2024
-
[35]
Qwen3-vl: Sharper vision, deeper thought, broader action.https : / / qwen
Qwen. Qwen3-vl: Sharper vision, deeper thought, broader action.https : / / qwen . ai / blog ? id = 99f0335c4ad9ff6153e517418d48535ab6d8afef& from = research . latest - advancements - list,
-
[36]
rednote. dots.ocr: Multilingual document layout parsing in a single vision-language model.https://github.com/ rednote-hilab/dots.ocr, 2025. 2, 3, 7
work page 2025
-
[37]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information process- ing systems, 28, 2015. 2
work page 2015
-
[38]
Deepdesrt: Deep learning for de- tection and structure recognition of tables in document im- ages
Sebastian Schreiber, Stefan Agne, Ivo Wolf, Andreas Den- gel, and Sheraz Ahmed. Deepdesrt: Deep learning for de- tection and structure recognition of tables in document im- ages. In2017 14th IAPR international conference on docu- ment analysis and recognition (ICDAR), pages 1162–1167. IEEE, 2017. 2
work page 2017
-
[39]
Pubtables-1m: To- wards comprehensive table extraction from unstructured documents
Brandon Smock, Rohith Pesala, et al. Pubtables-1m: To- wards comprehensive table extraction from unstructured documents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4634– 4642, 2022. 3, 12
work page 2022
-
[40]
Deep splitting and merging for table structure decomposition
Chris Tensmeyer, Vlad I Morariu, Brian Price, Scott Co- hen, and Tony Martinez. Deep splitting and merging for table structure decomposition. In2019 International Confer- ence on Document Analysis and Recognition (ICDAR), pages 114–121. IEEE, 2019. 2
work page 2019
-
[41]
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 3
work page 2017
-
[42]
Omniparser: A unified framework for text spotting key information extraction and table recognition
Jianqiang Wan, Sibo Song, Wenwen Yu, Yuliang Liu, Wen- qing Cheng, Fei Huang, Xiang Bai, Cong Yao, and Zhibo Yang. Omniparser: A unified framework for text spotting key information extraction and table recognition. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15641–15653, 2024. 3, 7
work page 2024
-
[43]
Marten: Visual question answering with mask generation for multi-modal document understanding
Zining Wang, Tongkun Guan, Pei Fu, Chen Duan, Qianyi Jiang, Zhentao Guo, Shan Guo, Junfeng Luo, Wei Shen, and Xiaokang Yang. Marten: Visual question answering with mask generation for multi-modal document understanding. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 14460–14471, 2025. 3
work page 2025
-
[44]
Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, et al. General ocr theory: Towards ocr-2.0 via a unified end-to-end model.arXiv preprint arXiv:2409.01704,
-
[45]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek- ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Anyi Xiao and Cihui Yang. Tablecenternet: A one-stage network for table structure recognition.arXiv preprint arXiv:2504.17522, 2025. 1
-
[47]
Lore: logical location regression network for table structure recognition
Hangdi Xing, Feiyu Gao, Rujiao Long, Jiajun Bu, Qi Zheng, Liangcheng Li, Cong Yao, and Zhi Yu. Lore: logical location regression network for table structure recognition. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 2992–3000, 2023. 2, 7
work page 2023
-
[48]
Res2tim: Reconstruct syntactic structures from table images
Wenyuan Xue, Qingyong Li, et al. Res2tim: Reconstruct syntactic structures from table images. In2019 international conference on document analysis and recognition (ICDAR), pages 749–755. IEEE, 2019. 2
work page 2019
-
[49]
Tgrnet: A table graph reconstruction net- work for table structure recognition
Wenyuan Xue, Baosheng Yu, Wen Wang, Dacheng Tao, and Qingyong Li. Tgrnet: A table graph reconstruction net- work for table structure recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1295–1304, 2021. 2
work page 2021
-
[50]
Jiaquan Ye, Xianbiao Qi, Yelin He, Yihao Chen, Dengyi Gu, Peng Gao, and Rong Xiao. Pingan-vcgroup’s solution for icdar 2021 competition on scientific literature parsing task b: table recognition to html.arXiv preprint arXiv:2105.01848,
-
[51]
Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chenliang Li, Jun- feng Tian, et al. mplug-docowl: Modularized multimodal large language model for document understanding.arXiv preprint arXiv:2307.02499, 2023. 4
-
[52]
Wenwen Yu, Zhibo Yang, Jianqiang Wan, Sibo Song, Jun Tang, Wenqing Cheng, Yuliang Liu, and Xiang Bai. Om- niparser v2: Structured-points-of-thought for unified visual text parsing and its generality to multimodal large language models.arXiv preprint arXiv:2502.16161, 2025. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Split, embed and merge: An accurate table structure recognizer.Pattern Recognition, 126:108565, 2022
Zhenrong Zhang, Jianshu Zhang, Jun Du, and Fengren Wang. Split, embed and merge: An accurate table structure recognizer.Pattern Recognition, 126:108565, 2022. 2
work page 2022
-
[54]
Weichao Zhao, Hao Feng, Qi Liu, Jingqun Tang, Binghong Wu, Lei Liao, Shu Wei, Yongjie Ye, Hao Liu, Wengang Zhou, et al. Tabpedia: Towards comprehensive visual ta- ble understanding with concept synergy.Advances in Neural Information Processing Systems, 37:7185–7212, 2024. 3, 7
work page 2024
-
[55]
Xinyi Zheng, Douglas Burdick, Lucian Popa, Xu Zhong, and Nancy Xin Ru Wang. Global table extractor (gte): A frame- work for joint table identification and cell structure recogni- tion using visual context. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 697–706, 2021. 5, 12
work page 2021
-
[56]
Image-based table recognition: data, model, and evaluation
Xu Zhong et al. Image-based table recognition: data, model, and evaluation. InEuropean conference on computer vision, pages 564–580. Springer, 2020. 1, 3, 5, 6, 7, 12
work page 2020
-
[57]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
BCDSTab Benchmark Detailed Specifica- tions The Balanced Complex Dense Synthetic Tables (BCD- STab) benchmark comprises 900 dense table images syn- thesized through our TableMixExpand (TME) framework, with source data derived from FinTabNet [55] and Pub- TabNet [56]. During synthesis, we first sample the total cell countCfrom a normal distributionNbounded...
-
[59]
Convert cell sub-image to binary format
-
[60]
Detect text contours using OpenCV’sboundingRect
-
[61]
Map local coordinates to global image
-
[62]
Output cell content bounding boxes in [xmin, ymin, xmax, ymax]format matching FinTab- Net/PubTabNet specifications The controlled color differentiation ensures reliable bi- narization. This process yields the complete BCDSTab benchmark, comprising 1,000 dense table images, HTML ground-truth representations, atomic cell matrix structures, cell-level boundi...
-
[63]
with their test sets. As quantified in Figure Fig. 6, BCDSTab demonstrates superior distribution balance and broader value ranges in both cell counts and merged cell quantities, fulfilling our objective to evaluate TSR mod- els under dense, long-table scenarios. BCDSTab provides images with significantly higher pixel counts than existing datasets, deliver...
-
[64]
Vision-Language Model Experimental Setup In our experimental evaluation, we conduct extensive test- ing across multiple vision-language models while maintain- ing fixed configurations for each model to ensure fairness, with detailed settings specified as follows:
-
[65]
We fix the prompt to “This is an image containing only one table, please convert the table in the image to HTML (begin with⟨table⟩and end with⟨/table⟩) format. Only the content in the image needs to be output without ex- panding other content.” uniformly across all general (a) Raw Image(b) BboxAnnotation(c) HTML GT(d) Atomic Cell Matrix (e) The number of ...
-
[66]
We set the maximum output length to 8192 tokens, which is sufficient for generating complete HTML table outputs across all datasets
-
[67]
We systematically employ regular expressions to ex- tract clean table content enclosed within “⟨table⟩” and “⟨/table⟩” tags from model outputs, ensuring effective isolation from extraneous textual elements
-
[68]
For reasoning-capable models (e.g., Gemini 2.5 Pro), we consistently enable their think mode during inference
-
[69]
For the multi-stage Table-aware VLMs (e.g., MinerU2.5 [26]), we isolate their table structure recognition module separately and employ official parameters and prompts to perform table structure recognition
-
[70]
Case Study (a) Input image(b) MinerU2.5(c) Gemini 2.5 Pro(d) InstructTable Figure 7. Visual comparison of different methods on BCDSTab, including: (a) input image, (b) MinerU2.5 results, (c) Gemini 2.5 Pro results, and (d) our InstructTable results. Red regions highlight erroneous positions in the predictions, with corresponding areas marked by green zone...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.