Recognition: no theorem link
Importance Sampling Optimization with Laplace Principle
Pith reviewed 2026-05-13 18:53 UTC · model grok-4.3
The pith
Laplace-inspired importance sampling turns a set of random-search points into a weighted average whose error decays faster than n^{-1/d} for d>2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a general non-convex setting, after n evaluations the error of the proposed importance-sampled averaging methods is of smaller order than n^{-2/(d+2)}. This compares favorably to random search or grid search rates of n^{-1/d} as soon as d>2.
What carries the argument
Laplace-principle importance sampling weights that assign higher mass to better-performing evaluated points when forming their average.
If this is right
- The weighting step can be applied to any existing random-search output without new function evaluations.
- The iterative version generates fresh candidates from a distribution centered on the current weighted estimate.
- For all dimensions d greater than 2 the asymptotic error order beats that of standard grid or random search.
Where Pith is reading between the lines
- The same weighting idea could be inserted into other sampling-based black-box methods to improve their final estimate at negligible cost.
- If the evaluations are noisy, the Laplace weights would need adjustment for variance, potentially preserving part of the rate gain.
- Empirical tests on standard benchmark suites in dimensions 3-10 would reveal whether the theoretical rate improvement appears at practical sample sizes.
Load-bearing premise
The objective function satisfies regularity conditions that let the Laplace-based weights deliver the claimed faster error rate.
What would settle it
On a non-convex test function in dimension 4, run the method for n=1000 evaluations and check whether the observed error stays at or above the n^{-1/4} rate of plain random search.
Figures
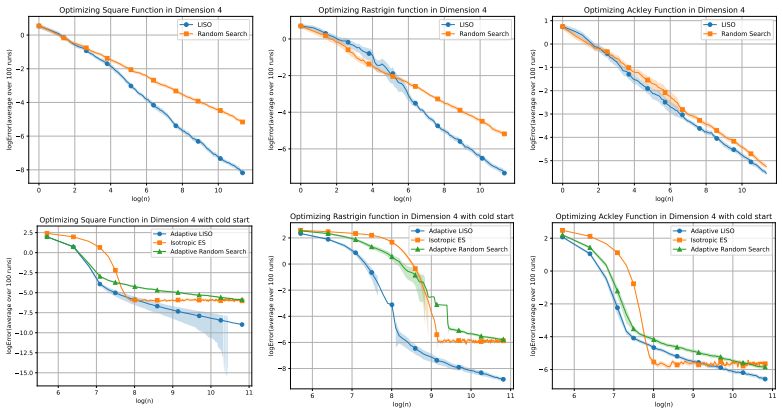

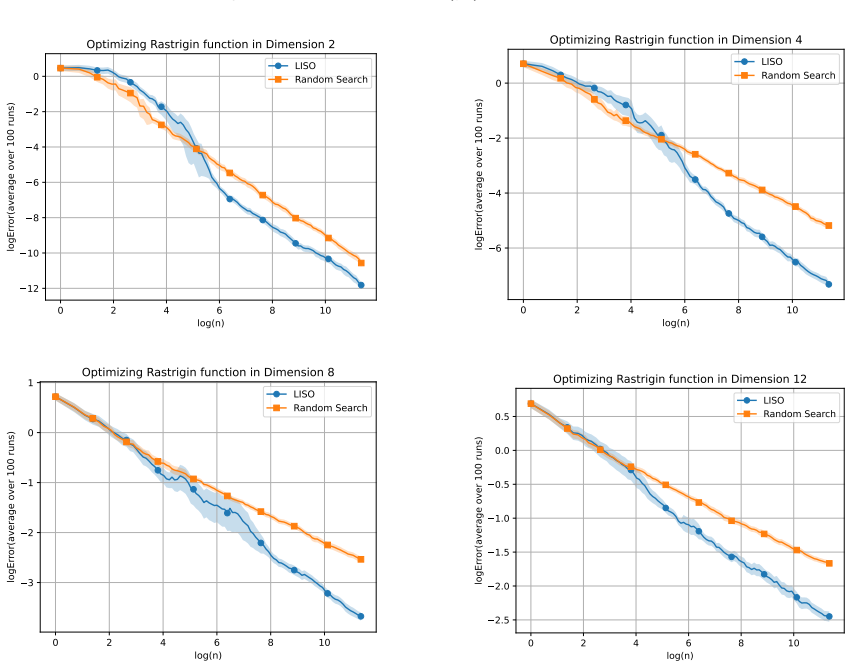
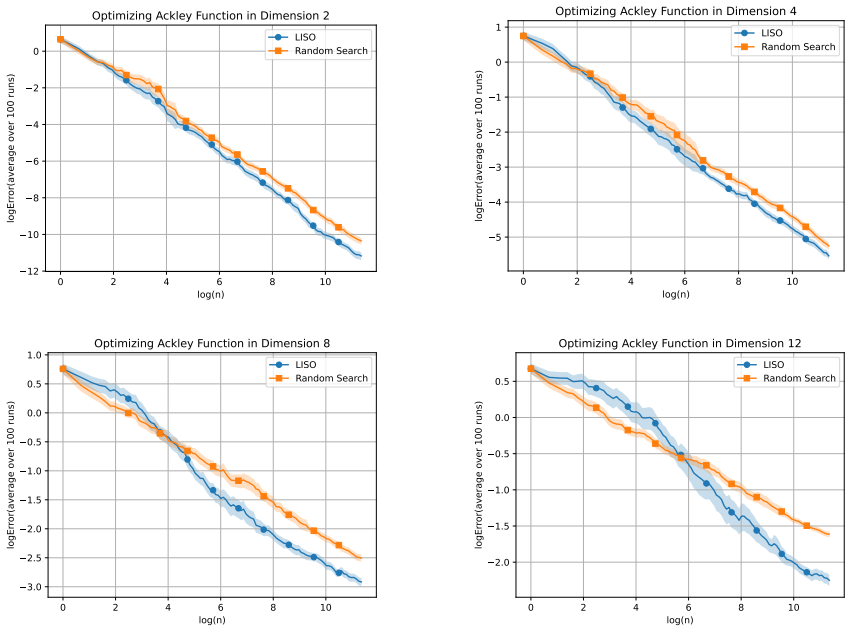
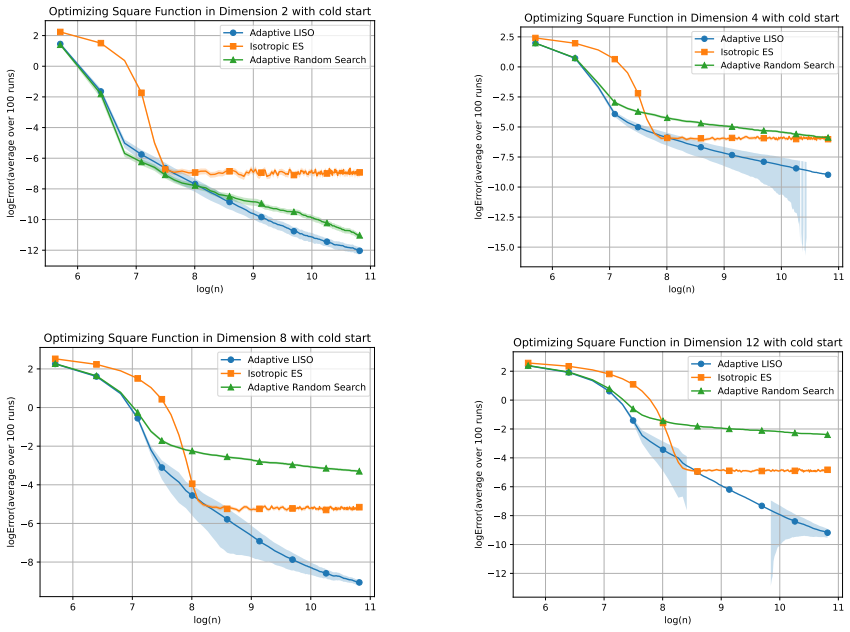
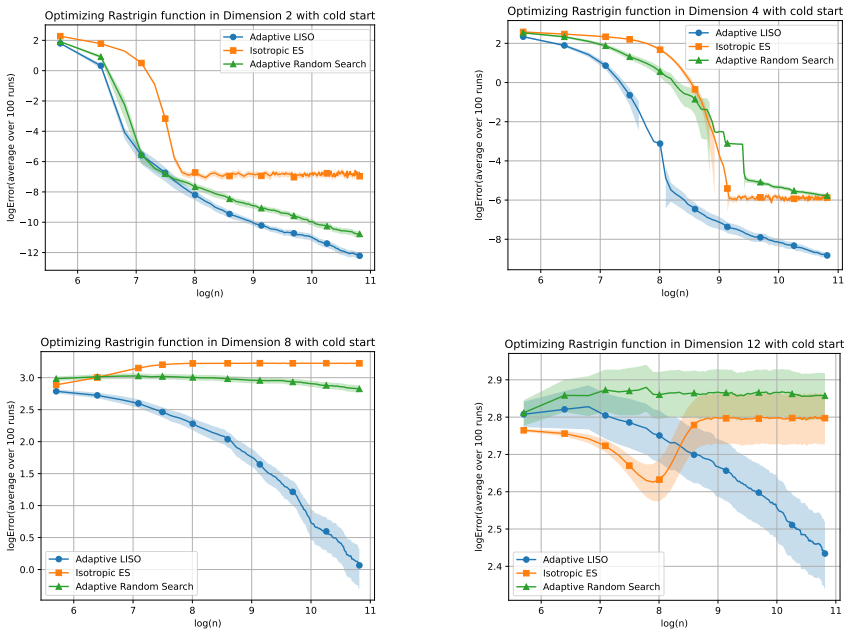

read the original abstract
Grid search and random search are widely used techniques for hyperparameter tuning in machine learning, especially when gradient information is unavailable. In these methods, a finite set of candidate configurations is evaluated, and the best-performing one is selected. We propose a simple and computationally inexpensive refinement of this paradigm: instead of selecting a single best point, we form a weighted average of the evaluated configurations, where the weights are chosen using an importance sampling scheme inspired by the Laplace principle. This scheme can be implemented as a post-processing step on top of a random search, with no additional function evaluations. We also propose an iterative variant, where the sampling distributions are chosen adaptively to generate new candidate points around the previous estimate, in the spirit of Evolution Strategy (ES) methods. In a general non-convex setting, we show that, after n evaluations, the error of the proposed methods is of smaller order than n -2/(d+2) . This compares favorably to random search or grid search rates of n -1/d as soon as d > 2. We illustrate the practical benefits of this averaging strategy on several examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-processing importance-sampling scheme based on the Laplace principle to form a weighted average of points obtained from random search, together with an adaptive iterative variant in the spirit of evolution strategies. The central claim is that, after n evaluations in a general non-convex setting, the error of the resulting estimator is of smaller order than n^{-2/(d+2)}, which improves upon the n^{-1/d} rate of uniform random or grid search once d>2. The method requires no extra function evaluations beyond the initial sample.
Significance. If the stated rate can be established under clearly articulated conditions, the contribution is a simple, computationally inexpensive refinement that yields a strictly better asymptotic rate than standard random search in moderate dimensions. The post-processing nature and the adaptive variant are practical strengths; the comparison to n^{-1/d} is a concrete, falsifiable prediction that could be tested numerically.
major comments (2)
- [Abstract] Abstract: the claim that the n^{-2/(d+2)} rate holds in a 'general non-convex setting' is load-bearing for the comparison with random search, yet the abstract lists no regularity conditions (unique isolated minimizer, C^2 smoothness, positive-definite Hessian at the minimum, suitable growth at infinity). The Laplace-principle weighting w_i ∝ exp(-n f(x_i)) concentrates at the stated rate only when the integral is dominated by a single quadratic minimum; multiple minima or vanishing Hessian eigenvalues reduce the rate to the uniform-search order n^{-1/d}. The precise assumptions must be stated explicitly before the rate comparison can be accepted.
- [Main theoretical result] The derivation of the improved rate (presumably in the main theorem) relies on the Laplace approximation for the normalizing constant and the weighted average. Without the full statement of the function-class assumptions and the supporting lemmas, it is impossible to verify whether the o(n^{-2/(d+2)}) bound survives when the objective is merely continuous or possesses flat regions. This gap directly affects the central theoretical claim.
minor comments (1)
- [Abstract] Abstract: the rates are written as 'n -2/(d+2)' and 'n -1/d'; these should be formatted consistently as superscripts n^{-2/(d+2)} and n^{-1/d}.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We agree that the regularity conditions supporting the n^{-2/(d+2)} rate must be stated explicitly to justify the comparison with standard random search. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the n^{-2/(d+2)} rate holds in a 'general non-convex setting' is load-bearing for the comparison with random search, yet the abstract lists no regularity conditions (unique isolated minimizer, C^2 smoothness, positive-definite Hessian at the minimum, suitable growth at infinity). The Laplace-principle weighting w_i ∝ exp(-n f(x_i)) concentrates at the stated rate only when the integral is dominated by a single quadratic minimum; multiple minima or vanishing Hessian eigenvalues reduce the rate to the uniform-search order n^{-1/d}. The precise assumptions must be stated explicitly before the rate comparison can be accepted.
Authors: We acknowledge that the abstract's use of 'general non-convex setting' without listing conditions risks overstatement. The main text (Section 2) defines the function class as having a unique isolated minimizer, C^2 smoothness in a neighborhood, positive-definite Hessian, and quadratic growth at infinity to ensure the Laplace principle yields the improved rate. We will revise the abstract to state these assumptions explicitly, so the rate comparison to n^{-1/d} (valid for d>2 under these conditions) is clearly scoped. revision: yes
-
Referee: [Main theoretical result] The derivation of the improved rate (presumably in the main theorem) relies on the Laplace approximation for the normalizing constant and the weighted average. Without the full statement of the function-class assumptions and the supporting lemmas, it is impossible to verify whether the o(n^{-2/(d+2)}) bound survives when the objective is merely continuous or possesses flat regions. This gap directly affects the central theoretical claim.
Authors: Theorem 3.1 and its proof (Section 3) are derived under the precise assumptions of Section 2 (unique minimizer with non-degenerate Hessian). The Laplace approximation is applied only to the local quadratic contribution; contributions from flat regions or multiple minima are exponentially negligible only under these conditions, otherwise reverting to n^{-1/d}. We will add an explicit statement of the function class at the start of Section 3, include a supporting lemma reference for the approximation error, and add a remark in the discussion noting that the improved rate fails for merely continuous or degenerate cases. revision: yes
Circularity Check
No circularity: rate derived from standard Laplace asymptotics under external regularity assumptions
full rationale
The paper's central claim is a theoretical convergence rate n^{-2/(d+2)} for the weighted estimator formed by Laplace-principle importance weights w_i ∝ exp(-n f(x_i)). This rate is obtained by asymptotic analysis of the weighted average, relying on the classical Laplace method for integrals dominated by a quadratic minimum. No equation reduces the claimed rate to a fitted parameter, a self-referential definition, or a self-citation chain. The derivation treats the regularity conditions (C^2 smoothness, positive-definite Hessian at the isolated minimum, suitable growth) as external inputs rather than deriving them from the result itself. The iterative variant is presented as an adaptive extension but does not alter the non-circular character of the rate analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function belongs to a class of non-convex functions possessing sufficient regularity for the Laplace-based importance weights to yield the stated convergence rate.
Reference graph
Works this paper leans on
-
[1]
S. Agapiou, O. Papaspiliopoulos, D. Sanz-Alonso, and A. M Stuart. Importance sampling: Intrinsic dimension and computational cost. Statistical Science , pages 405--431, 2017
work page 2017
-
[2]
D. V. Arnold. Weighted multirecombination evolution strategies. Theoretical Computer Science , 361(1):18--37, 2006. Foundations of Genetic Algorithms
work page 2006
-
[3]
P. Bianchi, R.-A. Dragomir, and V. Priser. Consensus-based optimization beyond finite-time analysis. arXiv preprint arXiv:2509.12907 , 2025
-
[4]
M. F Bugallo, V. Elvira, L. Martino, D. Luengo, J. Miguez, and P. M Djuric. Adaptive importance sampling: The past, the present, and the future. IEEE Signal Processing Magazine , 34(4):60--79, 2017
work page 2017
-
[5]
H.-G. Beyer and H.-P. Schwefel. Evolution strategies – a comprehensive introduction. Natural Computing , 1(1):3–52, March 2002
work page 2002
-
[6]
T.-S. Chiang, C.-R. Hwang, and S. J. Sheu. Diffusion for global optimization in R ^n . SIAM Journal on Control and Optimization , 25(3):737--753, 1987
work page 1987
-
[7]
P.-T. De Boer, D. P Kroese, S. Mannor, and R. Y Rubinstein. A tutorial on the cross-entropy method. Annals of operations research , 134(1):19--67, 2005
work page 2005
-
[8]
M. Feurer and F. Hutter. Hyperparameter optimization. In Automated machine learning: Methods, systems, challenges , pages 3--33. Springer International Publishing Cham, 2019
work page 2019
-
[9]
M. Fornasier, T. Klock, and K. Riedl. Consensus-based optimization methods converge globally. SIAM Journal on Optimization , 34(3):2973–3004, September 2024
work page 2024
-
[10]
N. Hansen. The cma evolution strategy: a comparing review. Towards a new evolutionary computation: Advances in the estimation of distribution algorithms , pages 75--102, 2006
work page 2006
-
[11]
C.-R. Hwang. Laplace's method revisited: weak convergence of probability measures. The Annals of Probability , pages 1177--1182, 1980
work page 1980
-
[12]
P. Koch, O. Golovidov, S. Gardner, B. Wujek, J. Griffin, and Y. Xu. Autotune: A derivative-free optimization framework for hyperparameter tuning. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages 443--452, 2018
work page 2018
-
[13]
S. Kirkpatrick, C D. Gelatt Jr, and M. P Vecchi. Optimization by simulated annealing. science , 220(4598):671--680, 1983
work page 1983
- [14]
-
[15]
H. Karimi, J. Nutini, and M. Schmidt. Linear convergence of gradient and proximal-gradient methods under the polyak- ojasiewicz condition. In Paolo Frasconi, Niels Landwehr, Giuseppe Manco, and Jilles Vreeken, editors, Machine Learning and Knowledge Discovery in Databases , pages 795--811, Cham, 2016. Springer International Publishing
work page 2016
-
[16]
I. Loshchilov and F. Hutter. Cma-es for hyperparameter optimization of deep neural networks. arXiv preprint arXiv:1604.07269 , 2016
- [17]
-
[18]
F. Portier and B. Delyon. Asymptotic optimality of adaptive importance sampling. In Advances in Neural Information Processing Systems , 2018
work page 2018
- [19]
-
[20]
C. P Robert, G. Casella, and G. Casella. Monte Carlo statistical methods , volume 2. Springer, 1999
work page 1999
-
[21]
T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever. Evolution strategies as a scalable alternative to reinforcement learning. arXiv preprint arXiv:1703.03864 , 2017
-
[22]
F. Stulp and O. Sigaud. Path integral policy improvement with covariance matrix adaptation. In Proceedings of the 29th International Conference on Machine Learning (ICML) , 2012
work page 2012
-
[23]
A. F Villaverde, D. Fr \"o hlich, D. Weindl, J. Hasenauer, and J. R Banga. Benchmarking optimization methods for parameter estimation in large kinetic models. Bioinformatics , 35(5):830--838, 2019
work page 2019
-
[24]
P. Xu, J. Chen, D. Zou, and Q. Gu. Global convergence of langevin dynamics based algorithms for nonconvex optimization. Advances in Neural Information Processing Systems , 31, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.