Recognition: 2 theorem links
· Lean TheoremGeneralized Transferable Neural Networks for Steady-State Partial Differential Equations
Pith reviewed 2026-05-13 18:01 UTC · model grok-4.3
The pith
GTransNet extends single-hidden-layer TransNet by adding hidden layers with symmetry-constrained biases and variance-controlled weights to improve accuracy and stability for oscillatory steady-state PDE solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a generalized transferable neural network (GTransNet) for solving steady-state PDEs, which augments the original TransNet design with additional hidden layers while preserving its interpretable feature-generation mechanism. In particular, the first hidden layer of GTransNet retains TransNet's parameter sampling strategy but incorporates an additional symmetry constraint on the neuron biases, while the subsequent hidden layers omit bias terms and employ a variance-controlled sampling strategy for selecting neuron weights.
Load-bearing premise
That the symmetry constraint on the first-layer biases and the variance-controlled sampling in subsequent layers will simultaneously improve accuracy for oscillatory solutions and avoid introducing new saturation or conditioning problems that offset the gains.
Figures
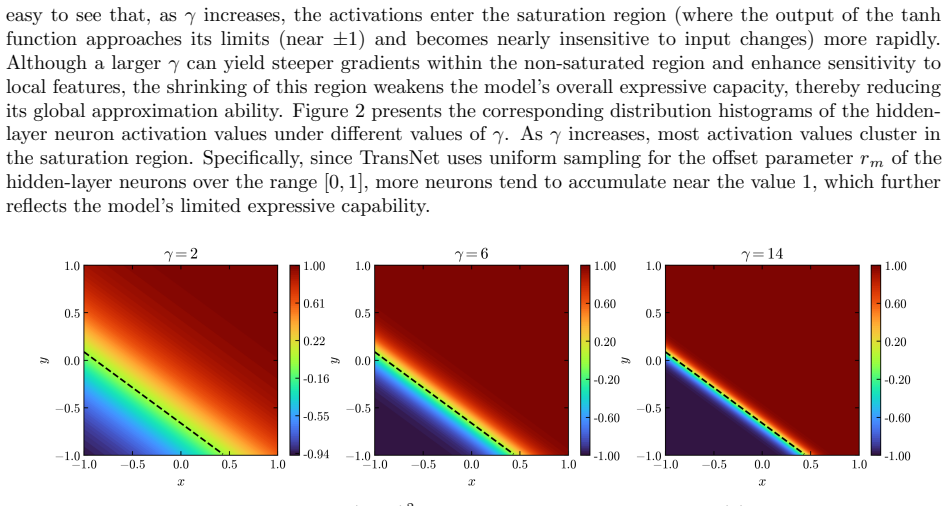



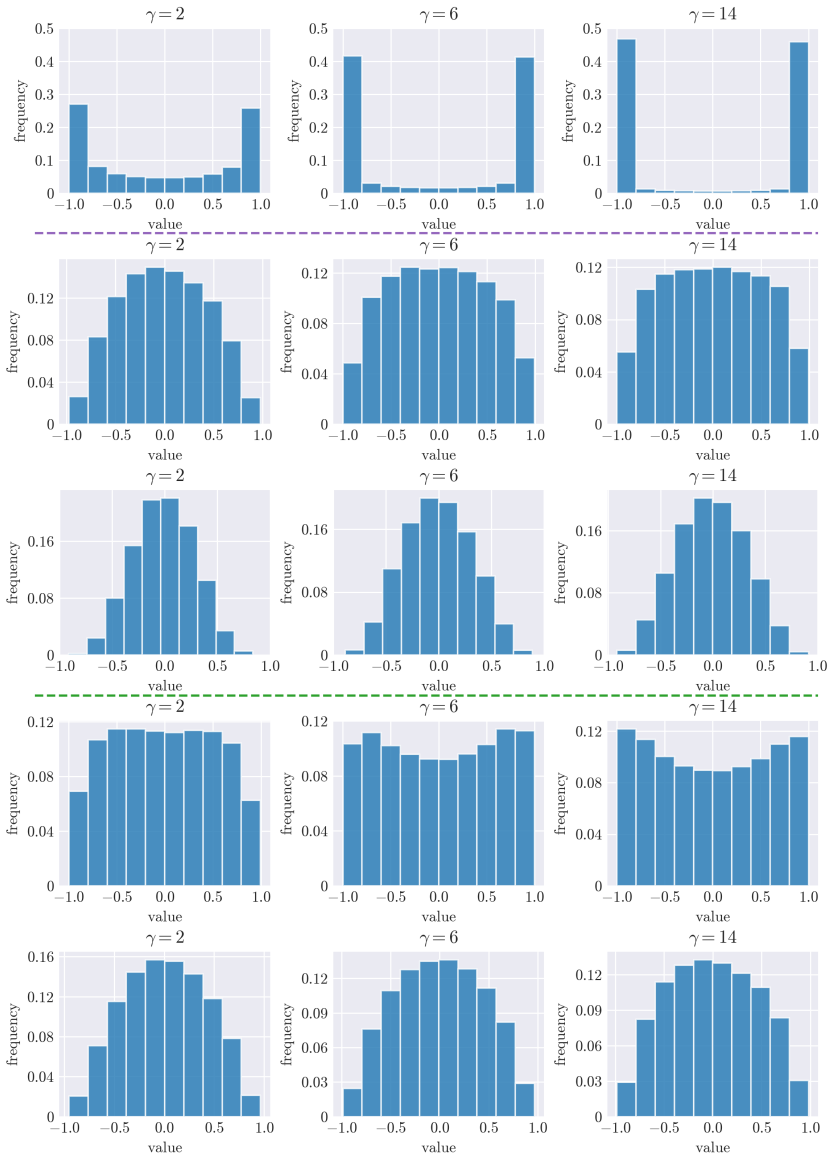


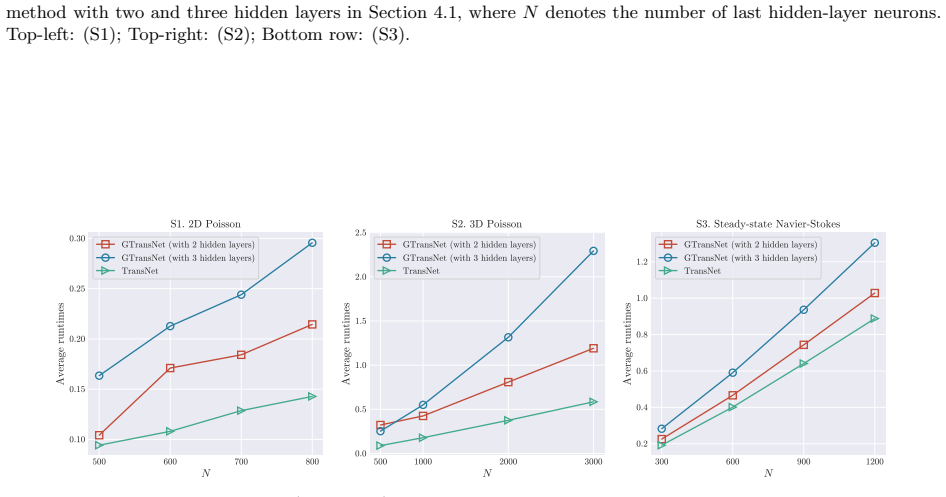








read the original abstract
Deep learning has emerged as a compelling framework for scientific and engineering computing, motivating growing interest in neural network-based solvers for partial differential equations (PDEs). Within this landscape, network architectures with deterministic feature construction have become an appealing approach, offering both high accuracy and computational efficiency in practice. Among them, the transferable neural network (TransNet) is a special class of shallow neural networks (i.e., single-hidden-layer architectures), whose hidden-layer parameters are predetermined according to the principle of uniformly distributed partition hyperplanes. Although TransNet has demonstrated strong performance in solving PDEs with relatively smooth solutions, its accuracy and stability may deteriorate in the presence of highly oscillatory solution structures, where activation saturation and system conditioning issues become limiting factors. In this paper, we propose a generalized transferable neural network (GTransNet) for solving steady-state PDEs, which augments the original TransNet design with additional hidden layers while preserving its interpretable feature-generation mechanism. In particular, the first hidden layer of GTransNet retains TransNet's parameter sampling strategy but incorporates an additional symmetry constraint on the neuron biases, while the subsequent hidden layers omit bias terms and employ a variance-controlled sampling strategy for selecting neuron weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a generalized transferable neural network (GTransNet) for solving steady-state PDEs. It extends the single-hidden-layer TransNet architecture by adding multiple hidden layers while retaining the interpretable parameter-sampling mechanism: the first hidden layer uses TransNet's uniform partition hyperplane sampling but adds a symmetry constraint on neuron biases, and subsequent layers are bias-free with variance-controlled weight sampling. The central claim is that these modifications simultaneously improve accuracy and stability for highly oscillatory solutions without introducing new saturation or conditioning problems.
Significance. If the architectural modifications can be shown to deliver the claimed gains, GTransNet would offer a deterministic, interpretable alternative to standard deep networks for oscillatory steady-state PDEs, potentially improving both accuracy and computational efficiency in scientific computing applications where feature construction must remain transparent.
major comments (2)
- [Abstract] Abstract: the assertion that accuracy and stability improve for highly oscillatory solutions rests on the design of the symmetry constraint and variance-controlled sampling, yet the manuscript contains no numerical experiments, error tables, condition-number measurements, or approximation bounds comparing GTransNet to TransNet on any test problem; this is load-bearing for the central claim.
- [Method] The description of the first-layer symmetry constraint and subsequent-layer variance sampling (detailed after the abstract) is presented as simultaneously raising accuracy and avoiding saturation/conditioning degradation, but no theoretical analysis or empirical verification is supplied to show that the added constraints produce a net benefit rather than offsetting trade-offs.
minor comments (1)
- [Method] Notation for the variance-controlled sampling strategy in deeper layers should be defined explicitly with a formula or pseudocode to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on our manuscript. The points raised correctly identify that the central claims require stronger supporting evidence. We will revise the manuscript to address these concerns by adding the requested numerical experiments, error tables, condition-number measurements, and theoretical analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that accuracy and stability improve for highly oscillatory solutions rests on the design of the symmetry constraint and variance-controlled sampling, yet the manuscript contains no numerical experiments, error tables, condition-number measurements, or approximation bounds comparing GTransNet to TransNet on any test problem; this is load-bearing for the central claim.
Authors: We agree that the current manuscript does not contain the comparative numerical experiments, error tables, condition-number measurements, or approximation bounds needed to substantiate the claims for highly oscillatory solutions. In the revised version we will add a dedicated numerical experiments section that includes test problems with highly oscillatory solutions, direct comparisons of GTransNet against TransNet, error tables, condition-number results, and any available approximation bounds. revision: yes
-
Referee: [Method] The description of the first-layer symmetry constraint and subsequent-layer variance sampling (detailed after the abstract) is presented as simultaneously raising accuracy and avoiding saturation/conditioning degradation, but no theoretical analysis or empirical verification is supplied to show that the added constraints produce a net benefit rather than offsetting trade-offs.
Authors: We acknowledge that the manuscript currently lacks both theoretical analysis and empirical verification demonstrating a net benefit from the symmetry constraint and variance-controlled sampling. We will expand the methods section with a theoretical discussion of how these modifications improve accuracy while avoiding saturation and conditioning degradation, and we will support this with the empirical results from the new numerical experiments section. revision: yes
Circularity Check
No circularity: GTransNet is an explicit architectural construction from TransNet rules
full rationale
The paper defines GTransNet directly via construction rules: first hidden layer keeps TransNet's uniform partition hyperplane sampling but adds a symmetry constraint on biases; subsequent layers drop biases and use variance-controlled weight sampling. These choices are presented as design decisions to address oscillatory solutions, not as predictions or derivations that reduce to fitted parameters or prior results by construction. No equations equate a claimed improvement to an input quantity, no self-citation is invoked as a uniqueness theorem or load-bearing ansatz, and the feature-generation mechanism is preserved by explicit rule rather than tautology. The derivation chain consists of independent architectural specifications.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The uniformly distributed partition hyperplanes principle from TransNet remains a sound basis for feature construction even after adding layers and symmetry constraints.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
first hidden layer ... symmetry constraint on the neuron biases ... subsequent hidden layers omit bias terms and employ a variance-controlled sampling strategy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3 (Controlled Variance Propagation ... Var[ψ(l)_i] ≤ δ^{l-1} σ_0²
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jingrun Chen, Xurong Chi, Weinan E, and Zhouwang Yang. Bridging traditional and machine learning- based algorithms for solving PDEs: The random feature method.Journal of Machine Learning, 1:268– 298, 06 2022
work page 2022
-
[2]
Jingrun Chen, Zheng Ma, and Keke Wu. A micro-macro decomposition-based asymptotic-preserving random feature method for multiscale radiative transfer equations.Journal of Computational Physics, 537:114103, 2025
work page 2025
-
[3]
Xurong Chi, Jingrun Chen, and Zhouwang Yang. The random feature method for solving interface problems.Computer Methods in Applied Mechanics and Engineering, 420:116719, 2024
work page 2024
-
[4]
Suchuan Dong and Zongwei Li. Local extreme learning machines and domain decomposition for solv- ing linear and nonlinear partial differential equations.Computer Methods in Applied Mechanics and Engineering, 387:Paper No. 114129, 63, 2021
work page 2021
-
[5]
Suchuan Dong and Zongwei Li. A modified batch intrinsic plasticity method for pre-training the random coefficients of extreme learning machines.Journal of Computational Physics, 445:110585, 2021
work page 2021
-
[6]
Weinan E and Bing Yu. The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6(1):1–12, 2018
work page 2018
-
[7]
Davide Elia De Falco, Enrico Schiassi, and Francesco Calabr` o. Least squares with equality constraints extreme learning machines for the resolution of PDEs.Journal of Computational Physics, 547:114553, 2026
work page 2026
-
[8]
Xavier Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. Journal of Machine Learning Research - Proceedings Track, 9:249–256, 01 2010
work page 2010
-
[9]
Ehsan Haghighat, Maziar Raissi, Adrian Moure, Hector Gomez, and Ruben Juanes. A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics.Computer Methods in Applied Mechanics and Engineering, 379:Paper No. 113741, 22, 2021
work page 2021
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
work page 2016
- [11]
-
[12]
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. Densely connected con- volutional networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2261–2269, 2017
work page 2017
-
[13]
Jagtap, Ehsan Kharazmi, and George Em Karniadakis
Ameya D. Jagtap, Ehsan Kharazmi, and George Em Karniadakis. Conservative physics-informed neural networks on discrete domains for conservation laws: applications to forward and inverse problems. Computer Methods in Applied Mechanics and Engineering, 365:113028, 27, 2020
work page 2020
-
[14]
The principles of diffusion models, 2025
Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, and Stefano Ermon. The principles of diffusion models, 2025. 22
work page 2025
-
[15]
Xi-An Li, Zhi-Qin John Xu, and Lei Zhang. Subspace decomposition based dnn algorithm for elliptic type multi-scale PDEs.Journal of Computational Physics, 488:112242, 2023
work page 2023
-
[16]
Xi’an Li, Jinran Wu, Xin Tai, Jianhua Xu, and You-Gan Wang. Solving a class of multi-scale elliptic PDEs by fourier-based mixed physics informed neural networks.Journal of Computational Physics, 508:113012, 2024
work page 2024
-
[17]
Fourier Neural Operator for Parametric Partial Differential Equations
Zong-Yi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, An- drew M. Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.ArXiv, abs/2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [18]
-
[19]
Yulei Liao and Pingbing Ming. Deep Nitsche method: deep Ritz method with essential boundary conditions.Communications in Computational Physics, 29(5):1365–1384, 2021
work page 2021
-
[20]
Ziqi Liu, Wei Cai, and Zhiqin Xu. Multi-scale deep neural network (MscaleDNN) for solving Poisson- Boltzmann equation in complex domains.Journal of Computational Physics, 28:1970–2001, 2020
work page 1970
-
[21]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218–229, 2021
work page 2021
-
[22]
Tianzheng Lu, Lili Ju, and Liyong Zhu. A multiple transferable neural network method with domain decomposition for elliptic interface problems.Journal of Computational Physics, 530:113902, 2025
work page 2025
-
[23]
Stefano Markidis. The old and the new: Can physics-informed deep-learning replace traditional linear solvers?Frontiers in Big Data, 4, 2021
work page 2021
-
[24]
Levi D. McClenny and Ulisses M. Braga-Neto. Self-adaptive physics-informed neural networks.Journal of Computational Physics, 474:Paper No. 111722, 23, 2023
work page 2023
-
[25]
fPINNs: fractional physics-informed neural networks
Guofei Pang, Lu Lu, and George Em Karniadakis. fPINNs: fractional physics-informed neural networks. SIAM Journal on Scientific Computing, 41(4):A2603–A2626, 2019
work page 2019
-
[26]
Hamprecht, Yoshua Bengio, and Aaron C
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Dr¨ axler, Min Lin, Fred A. Hamprecht, Yoshua Bengio, and Aaron C. Courville. On the spectral bias of neural networks. InInternational Conference on Machine Learning, 2018
work page 2018
- [27]
-
[28]
Zhequan Shen, Lili Ju, and Liyong Zhu. Matched asymptotic expansions-based transferable neural networks for singular perturbation problems, 2025
work page 2025
-
[29]
Hailong Sheng and Chao Yang. Pfnn: A penalty-free neural network method for solving a class of second- order boundary-value problems on complex geometries.Journal of Computational Physics, 428:110085, 2021
work page 2021
-
[30]
Justin Sirignano and Konstantinos Spiliopoulos. Dgm: a deep learning algorithm for solving partial differential equations.Journal of Computational Physics, 375:1339–1364, 2018
work page 2018
-
[31]
Jingbo Sun, Suchuan Dong, and Fei Wang. Local randomized neural networks with discontinuous galerkin methods for partial differential equations.Journal of Computational and Applied Mathematics, 445:115830, 2024
work page 2024
-
[32]
Yifei Sun and Jingrun Chen. Two-level random feature methods for elliptic partial differential equa- tions over complex domains.Computer Methods in Applied Mechanics and Engineering, 441:Paper No. 117961, 15, 2025. 23
work page 2025
-
[33]
Timemixer++: A general time series pattern machine for universal predictive analysis
Shiyu Wang, Jiawei LI, Xiaoming Shi, Zhou Ye, Baichuan Mo, Wenze Lin, Ju Shengtong, Zhixuan Chu, and Ming Jin. Timemixer++: A general time series pattern machine for universal predictive analysis. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[34]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why PINNs fail to train: a neural tangent kernel perspective.Journal of Computational Physics, 449:Paper No. 110768, 28, 2022
work page 2022
-
[35]
Yiran Wang and Suchuan Dong. An extreme learning machine-based method for computational PDEs in higher dimensions.Journal of Computational Physics, 418:Paper No. 116578, 31, 2024
work page 2024
-
[36]
Yong Wang, Yanzhong Yao, Jiawei Guo, and Zhiming Gao. A practical pinn framework for multi-scale problems with multi-magnitude loss terms.Journal of Computational Physics, 510:113112, 2024
work page 2024
-
[37]
Zhiwen Wang, Minxin Chen, and Jingrun Chen. Solving multiscale elliptic problems by sparse radial basis function neural networks.Journal of Computational Physics, 492:Paper No. 112452, 16, 2023
work page 2023
-
[38]
Kexiang Xiong, Zhen Zhang, Jingrun Chen, and Yixin Luo. The random feature method for elliptic eigenvalue problems.Advances in Applied Mathematics and Mechanics, 17(4):1133–1170, 2025
work page 2025
-
[39]
Weak transnet: A petrov-galerkin based neural network method for solving elliptic PDEs, 2025
Zhihang Xu, Min Wang, and Zhu Wang. Weak transnet: A petrov-galerkin based neural network method for solving elliptic PDEs, 2025
work page 2025
-
[40]
Zhiqin Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, and Zheng Ma. Frequency principle: Fourier analysis sheds light on deep neural networks.Journal of Computational Physics, 28:1746–1767, 2020
work page 2020
-
[41]
Liu Yang, Xuhui Meng, and George Em Karniadakis. B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data.Journal of Computational Physics, 425:Paper No. 109913, 23, 2021
work page 2021
-
[42]
Yaohua Zang, Gang Bao, Xiaojing Ye, and Haomin Zhou. Weak adversarial networks for high- dimensional partial differential equations.Journal of Computational Physics, 411:109409, 14, 2020
work page 2020
-
[43]
Huajian Zhang, Chao Li, Rui Xia, Xinhai Chen, Tiaojie Xiao, Xiao-Wei Guo, and Jie Liu. Fe-pirbn: Feature-enhanced physics-informed radial basis neural networks for solving high-frequency electromag- netic scattering problems.Journal of Computational Physics, 527:113798, 2025
work page 2025
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.