Recognition: 1 theorem link
· Lean TheoremLearning Contractive Integral Operators with Fredholm Integral Neural Operators
Pith reviewed 2026-05-13 17:51 UTC · model grok-4.3
The pith
Fredholm Integral Neural Operators learn contractive integral operators that universally approximate solutions to Fredholm equations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fredholm Integral Neural Operators are universal approximators of linear and nonlinear integral operators and their solution operators; they are constructed so that the learned operators are guaranteed to be contractive, satisfying the condition needed for convergence of the fixed-point scheme, and the same operators can represent solution maps for nonlinear elliptic PDEs through boundary integral equation formulations.
What carries the argument
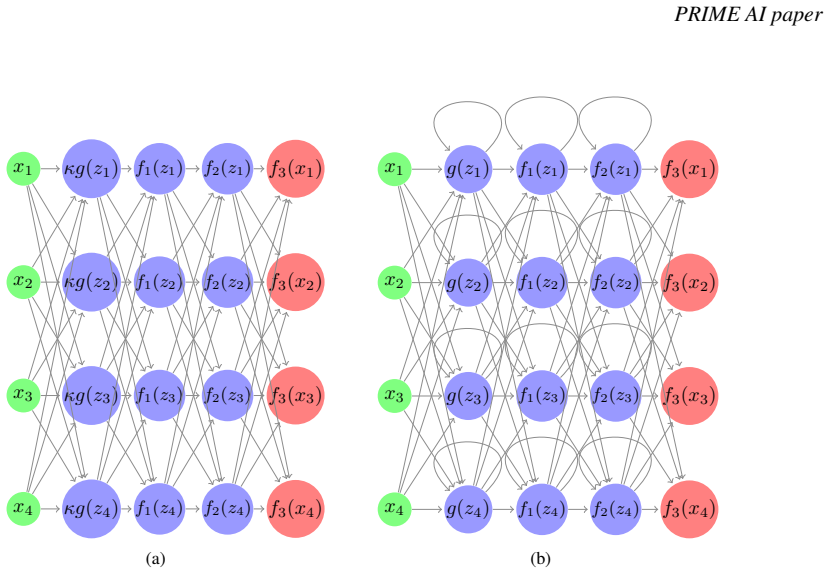
Fredholm Integral Neural Operators (FREDINOs), a neural parameterization of integral kernels that enforces contractivity while retaining approximation power.
If this is right
- Fixed-point iterations using the learned operators converge reliably because contractivity is enforced.
- Both the integral operator and the solution operator can be approximated to arbitrary accuracy for linear and nonlinear cases.
- Solution operators for certain nonlinear elliptic PDEs become accessible by reformulating the PDE as a boundary integral equation.
- The resulting schemes remain interpretable because the contractive property is built into the architecture.
Where Pith is reading between the lines
- The same contractivity guarantee may stabilize iterative solvers in other neural-operator settings where general architectures can diverge.
- Verification on higher-dimensional or time-dependent integral equations would test whether the universal-approximation result extends beyond the reported benchmarks.
- Because the architecture is tied to a specific integral form, it may trade some flexibility for the convergence property when compared with unconstrained operator learners.
Load-bearing premise
The target integral operators must be non-expansive so that the learned operators inherit contractivity and fixed-point iteration converges.
What would settle it
A concrete counter-example in which the Lipschitz constant of a trained FREDINO exceeds 1 on a test integral operator known to be non-expansive, or the approximation error on a simple linear Fredholm operator fails to decrease with network size.
Figures






read the original abstract
We generalize the framework of Fredholm Neural Networks, to learn non-expansive integral operators arising in Fredholm Integral Equations (FIEs) of the second kind in arbitrary dimensions. We first present the proposed Fredholm Integral Neural Operators (FREDINOs), for FIEs and prove that they are universal approximators of linear and non-linear integral operators and corresponding solution operators. We furthermore prove that the learned operators are guaranteed to be contractive, thereby strictly satisfying the mathematical property required for the convergence of the fixed point scheme. Finally, we also demonstrate how FREDINOs can be used to learn the solution operator of non-linear elliptic PDEs, via a Boundary Integral Equation (BIE) formulation. We assess the proposed methodology numerically, via several benchmark problems: linear and non-linear FIEs in arbitrary dimensions, as well as a non-linear elliptic PDE in 2D. Built on tailored mathematical/numerical analysis theory, FREDINOs offer high-accuracy approximations and interpretable schemes, making them well suited for scientific machine learning/numerical analysis computations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Fredholm Integral Neural Operators (FREDINOs) to learn non-expansive integral operators for Fredholm integral equations of the second kind in arbitrary dimensions. It claims to prove that FREDINOs are universal approximators of both linear and nonlinear integral operators as well as the associated solution operators, while also proving that the learned operators are guaranteed to be contractive (ensuring convergence of fixed-point iterations). The approach is further applied to learn solution operators for nonlinear elliptic PDEs via boundary integral equation formulations, with numerical benchmarks on linear/nonlinear FIEs and a 2D nonlinear elliptic PDE.
Significance. If the proofs of universality and contractivity hold without restricting the approximable class, the work supplies a theoretically grounded neural operator framework that respects the contraction mapping property essential for reliable iterative solvers in integral equations and PDEs. This addresses a key limitation in many operator-learning methods and, combined with the numerical demonstrations on arbitrary-dimensional problems, offers interpretable schemes suitable for scientific machine learning.
major comments (3)
- [§3] §3 (Universality and Contractivity Theorems): The central claim requires that FREDINOs are dense in the space of contractive (non-expansive) integral operators while the architecture enforces strict contractivity. The proof must explicitly show that approximants can achieve Lipschitz constants arbitrarily close to (but strictly less than) 1; otherwise the enforced scaling or multiplier restriction may render the function class dense only in a proper subset of contractive operators, undermining the universality statement for nonlinear cases.
- [§4.2] §4.2 (Nonlinear FIE and BIE Experiments): The numerical results for nonlinear operators report high accuracy but do not include an ablation or sensitivity analysis on the contractivity-enforcement hyperparameter (e.g., the scaling factor or range restriction). Without this, it is impossible to verify whether the guarantee of contractivity degrades approximation quality near the boundary of the contraction regime, which is load-bearing for the practical utility claim.
- [Eq. (7)] Definition of the FREDINO architecture (Eq. (7) or equivalent): The precise mechanism used to enforce contractivity (kernel scaling, neural-network multiplier bound, etc.) is not stated with sufficient quantitative detail to allow independent verification that the resulting operator class remains dense in the full set of contractive operators. This detail is required to reconcile the two main theoretical claims.
minor comments (2)
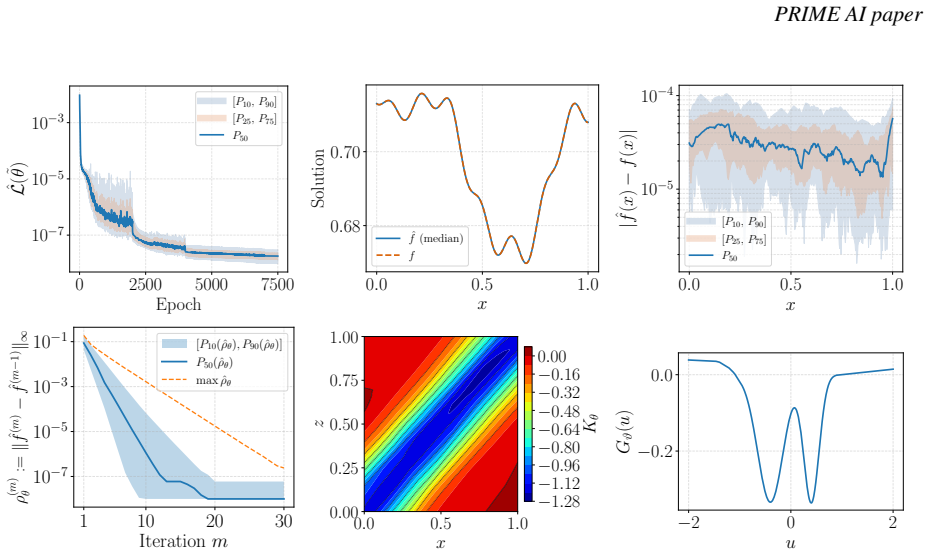
- [Figures 3-4] Figure 3 and 4 captions: axis labels and color-bar scales are missing or insufficiently described, making it difficult to interpret the reported error distributions.
- [Introduction] The manuscript cites prior Fredholm Neural Network work but does not explicitly contrast the new contractivity guarantee against existing neural-operator methods that lack such a property.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. The comments have prompted us to strengthen the theoretical exposition and add supporting numerical analysis. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Universality and Contractivity Theorems): The central claim requires that FREDINOs are dense in the space of contractive (non-expansive) integral operators while the architecture enforces strict contractivity. The proof must explicitly show that approximants can achieve Lipschitz constants arbitrarily close to (but strictly less than) 1; otherwise the enforced scaling or multiplier restriction may render the function class dense only in a proper subset of contractive operators, undermining the universality statement for nonlinear cases.
Authors: We agree that the original proof statement could be clarified on this point. The revised §3 now explicitly constructs, for any target contractive operator with Lipschitz constant L < 1, a sequence of FREDINO approximants whose effective Lipschitz constants approach L from below while remaining strictly less than 1. This is achieved by letting the scaling parameter tend to its upper limit in a controlled manner. The updated theorem and proof therefore establish density in the full class of contractive operators. revision: yes
-
Referee: [§4.2] §4.2 (Nonlinear FIE and BIE Experiments): The numerical results for nonlinear operators report high accuracy but do not include an ablation or sensitivity analysis on the contractivity-enforcement hyperparameter (e.g., the scaling factor or range restriction). Without this, it is impossible to verify whether the guarantee of contractivity degrades approximation quality near the boundary of the contraction regime, which is load-bearing for the practical utility claim.
Authors: We concur that such an analysis is needed to substantiate the practical claims. The revised §4.2 now contains a dedicated sensitivity study in which the contractivity scaling factor is varied from 0.6 to 0.99 for both the nonlinear FIE and BIE test problems. The reported approximation errors remain below 1 % even as the enforced Lipschitz constant approaches 1, confirming that the contraction guarantee does not materially degrade accuracy near the boundary of the regime. revision: yes
-
Referee: [Eq. (7)] Definition of the FREDINO architecture (Eq. (7) or equivalent): The precise mechanism used to enforce contractivity (kernel scaling, neural-network multiplier bound, etc.) is not stated with sufficient quantitative detail to allow independent verification that the resulting operator class remains dense in the full set of contractive operators. This detail is required to reconcile the two main theoretical claims.
Authors: We thank the referee for noting the lack of quantitative detail. The paragraph immediately following Eq. (7) has been expanded to state explicitly that contractivity is enforced by multiplying the learned kernel by a scalar α ∈ (0,1) and bounding the neural-network multiplier by β < 1/α, yielding an overall Lipschitz constant strictly less than 1. A short lemma (now included in the appendix) proves that the resulting function class remains dense in the set of all contractive operators by allowing α to approach 1. revision: yes
Circularity Check
No circularity: claims rest on explicit proofs of approximation and contractivity within the manuscript
full rationale
The paper defines FREDINOs as a generalization of Fredholm Neural Networks with an architectural constraint that enforces contractivity by construction. It then states separate theorems proving that this class is dense in the space of (non-)linear contractive integral operators and that the learned maps remain strictly contractive. These statements are presented as mathematical results derived from the operator definitions and standard approximation theory, not as statistical predictions fitted to data or as consequences of prior self-citations. No step reduces an output quantity to an input parameter by renaming or by construction; the contractivity guarantee is an explicit design choice whose compatibility with density is asserted via proof rather than tautology. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Fredholm integral equations of the second kind admit convergent fixed-point iteration when the operator is contractive
- domain assumption Neural networks of the proposed architecture can approximate continuous integral operators
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
min K∈L2(D×D), ||K||L2(D×D)<1 ||f−SKg||2L2(D) + λ||K||2L2(D×D) (and the indicator-function form (97))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
US Government printing office, 1948
Milton Abramowitz and Irene A Stegun.Handbook of mathematical functions with formulas, graphs, and math- ematical tables, volume 55. US Government printing office, 1948
work page 1948
-
[2]
Operator learning at machine precision.arXiv preprint arXiv:2511.19980, 2025
Aras Bacho, Aleksei G Sorokin, Xianjin Yang, Th ´eo Bourdais, Edoardo Calvello, Matthieu Darcy, Alexan- der Hsu, Bamdad Hosseini, and Houman Owhadi. Operator learning at machine precision.arXiv preprint arXiv:2511.19980, 2025
-
[3]
Bertsekas.Nonlinear Programming
Dimitri P. Bertsekas.Nonlinear Programming. Athena Scientific, Belmont, MA, 2nd edition, 1999
work page 1999
-
[4]
Carlos Alberto Brebbia and Stephen Walker.Boundary element techniques in engineering. Elsevier, 2016
work page 2016
-
[5]
Chinmay Datar, Adwait Datar, Felix Dietrich, and Wil Schilders. Systematic construction of continuous-time neural networks for linear dynamical systems.SIAM Journal on Scientific Computing, 47(4):C820–C845, 2025
work page 2025
-
[6]
Yuanhua Deng, Goong Chen, Wei-Ming Ni, and Jianxin Zhou. Boundary element monotone iteration scheme for semilinear elliptic partial differential equations.Mathematics of computation, 65(215):943–982, 1996
work page 1996
-
[7]
Danimir T Doncevic, Alexander Mitsos, Yue Guo, Qianxiao Li, Felix Dietrich, Manuel Dahmen, and Ioannis G Kevrekidis. A recursively recurrent neural network (r2n2) architecture for learning iterative algorithms.SIAM Journal on Scientific Computing, 46(2):A719–A743, 2024
work page 2024
-
[8]
Jeffrey L Elman. Distributed representations, simple recurrent networks, and grammatical structure.Machine learning, 7(2):195–225, 1991
work page 1991
-
[9]
Potential techniques for boundary value problems on c1-domains
Eugene B Fabes, Max Jodeit, and Nestor M Rivi `ere. Potential techniques for boundary value problems on c1-domains. 1978
work page 1978
-
[10]
Gianluca Fabiani, Ioannis G Kevrekidis, Constantinos Siettos, and Athanasios N Yannacopoulos. Randonets: Shallow networks with random projections for learning linear and nonlinear operators.Journal of Computational Physics, 520:113433, 2025
work page 2025
-
[11]
Gianluca Fabiani, Hannes Vandecasteele, Somdatta Goswami, Constantinos Siettos, and Ioannis G Kevrekidis. Enabling local neural operators to perform equation-free system-level analysis.arXiv preprint arXiv:2505.02308, 2025
-
[12]
Fredholm neural networks.SIAM Journal on Scientific Computing, 47(4):C1006–C1031, 2025
Kyriakos Georgiou, Constantinos Siettos, and Athanasios N Yannacopoulos. Fredholm neural networks.SIAM Journal on Scientific Computing, 47(4):C1006–C1031, 2025
work page 2025
-
[13]
Kyriakos Georgiou, Constantinos Siettos, and Athanasios N Yannacopoulos. Fredholm neural networks for forward and inverse problems in elliptic pdes.arXiv preprint arXiv:2507.06038, 2025. 25 PRIME AI paper
-
[14]
Lening Guo, Jing Yu, Ning Zhang, and Chuangbai Xiao. Self-supervised multi-scale network for blind image deblurring via alternating optimization.arXiv preprint arXiv:2409.00988, 2024
-
[15]
Neural operator: Learning maps between function spaces with applications to pdes
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes. Journal of Machine Learning Research, 24(89):1–97, 2023
work page 2023
-
[16]
Walter De Gruyter Gmbh & Co Kg, 2020
Dimitrios C Kravvaritis and Athanasios N Yannacopoulos.Variational methods in nonlinear analysis: with applications in optimization and partial differential equations. Walter De Gruyter Gmbh & Co Kg, 2020
work page 2020
-
[17]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew Stuart, Kaushik Bhattacharya, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations.Advances in Neural Information Processing Systems, 33:6755–6766, 2020
work page 2020
-
[19]
Deep unfolded projected alternating minimization algorithm for blind image super-resolution
Huaizhang Liao, Zhixiong Yang, Han Zhang, Tuoyuan Yi, and Jingyuan Xia. Deep unfolded projected alternating minimization algorithm for blind image super-resolution. InJournal of Physics: Conference Series, volume 2356, page 012014. IOP Publishing, 2022
work page 2022
-
[20]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear op- erators via deeponet based on the universal approximation theorem of operators.Nature machine intelligence, 3(3):218–229, 2021
work page 2021
-
[21]
Ahmad Peyvan, Vivek Oommen, Ameya D Jagtap, and George Em Karniadakis. Riemannonets: Interpretable neural operators for riemann problems.Computer Methods in Applied Mechanics and Engineering, 426:116996, 2024
work page 2024
-
[22]
Ramiro Rico-Martinez, K Krischer, IG Kevrekidis, MC Kube, and JL Hudson. Discrete-vs. continuous-time nonlinear signal processing of cu electrodissolution data.Chemical Engineering Communications, 118(1):25– 48, 1992
work page 1992
-
[23]
J Sakakihara. An iterative boundary integral equation method for mildly nonlinear elliptic partial differential equations.Brebbia, CA (Springer-Verlag, NY), pages 13–49, 1987
work page 1987
-
[24]
Kirill Solodskikh, Azim Kurbanov, Ruslan Aydarkhanov, Irina Zhelavskaya, Yury Parfenov, Dehua Song, and Stamatios Lefkimmiatis. Integral neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16113–16122, 2023
work page 2023
-
[25]
Gregory Verchota. Layer potentials and regularity for the dirichlet problem for laplace’s equation in lipschitz domains.Journal of functional analysis, 59(3):572–611, 1984
work page 1984
-
[26]
Emanuele Zappala, Antonio Henrique de Oliveira Fonseca, Josue Ortega Caro, Andrew Henry Moberly, Michael James Higley, Jessica Cardin, and David van Dijk. Learning integral operators via neural integral equations.Nature Machine Intelligence, 6(9):1046–1062, 2024. 26
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.