Recognition: 2 theorem links
· Lean TheoremCan Nano Banana 2 Replace Traditional Image Restoration Models? An Evaluation of Its Performance on Image Restoration Tasks
Pith reviewed 2026-05-13 20:07 UTC · model grok-4.3
The pith
Nano Banana 2 achieves competitive image restoration scores and user preference through prompt design yet produces over-enhanced details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
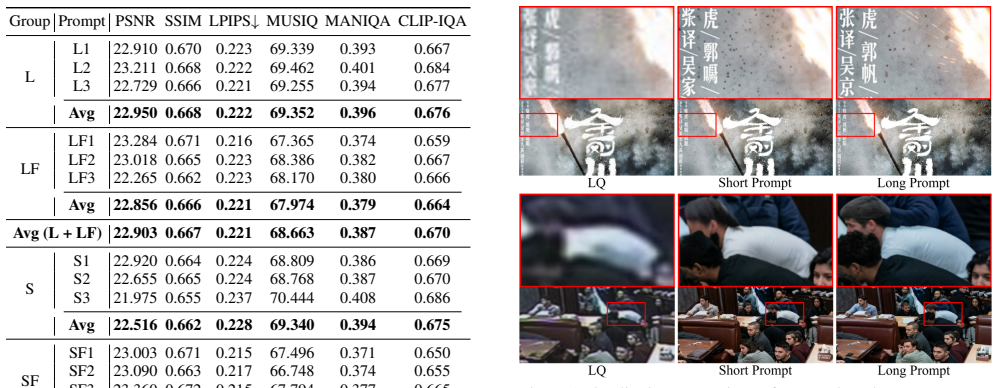
Nano Banana 2, when guided by concise prompts with explicit fidelity constraints, achieves competitive full-reference performance on diverse image restoration tasks and is consistently preferred in user studies while showing strong generalization in challenging scenarios. The model tends to produce visually rich results with over-enhanced details and inconsistencies, an issue not well captured by existing IQA metrics or standard user studies, indicating that general-purpose models show promise as unified IR solvers from a perceptual perspective but require improved controllability and fidelity-aware evaluation.
What carries the argument
Prompt engineering with concise instructions and fidelity constraints applied to Nano Banana 2 outputs, evaluated via full-reference metrics and user preference studies against traditional restorers.
If this is right
- Concise prompts with fidelity constraints produce a better balance between accurate reconstruction and perceptual quality.
- The model generalizes effectively to challenging degradation scenarios.
- Standard IQA metrics and user studies overlook inconsistencies in generated details.
- General-purpose generative models offer promise as unified image restoration solvers from a perceptual standpoint.
- Improved controllability is needed to close the observed fidelity gap.
Where Pith is reading between the lines
- New metrics focused on invented structures and consistency would give a clearer picture of generative restorers.
- Hybrid systems that combine Nano Banana 2 outputs with traditional priors could reduce over-enhancement.
- The same evaluation approach could test other general-purpose editing models on restoration benchmarks.
- Future model development should embed explicit fidelity constraints rather than relying on post-hoc prompts.
Load-bearing premise
Existing IQA metrics and standard user studies are sufficient to detect gaps between perceptual quality and restoration fidelity when the model produces over-enhanced details and inconsistencies.
What would settle it
A targeted user study or new metric that specifically rates content accuracy and detail consistency would show whether the over-enhancements count as flaws that reverse the reported user preference.
Figures






read the original abstract
Recent advances in generative AI raise the question of whether general-purpose image editing models can serve as unified solutions for image restoration. We conduct a systematic evaluation of Nano Banana 2 across diverse scenes and degradations. Our results show that prompt design is critical, with concise prompts and explicit fidelity constraints achieving a better balance between reconstruction and perceptual quality. Nano Banana 2 achieves competitive full-reference performance and is consistently preferred in user studies, while showing strong generalization in challenging scenarios. However, we observe a gap between perceptual quality and restoration fidelity, as the model tends to produce visually rich results with over-enhanced details and inconsistencies. This issue is not well captured by existing IQA metrics or user studies. Overall, general-purpose models show promise as unified IR solvers from a perceptual perspective, but require improved controllability and fidelity-aware evaluation. Further comparisons and detailed analyses are available in our project repository: https://github.com/yxyuanxiao/NanoBanana2TestOnIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates Nano Banana 2, a general-purpose generative model, on image restoration tasks across diverse scenes and degradations. It claims that concise prompts with explicit fidelity constraints yield competitive full-reference performance and consistent user preference over traditional models, with strong generalization in challenging cases, while acknowledging a gap between perceptual quality and restoration fidelity manifested as over-enhanced details and inconsistencies that existing IQA metrics and user studies fail to capture. The authors conclude that such models show promise as unified IR solvers from a perceptual perspective but require improved controllability and fidelity-aware evaluation.
Significance. If the empirical results and user studies hold under scrutiny, the work would demonstrate that general-purpose generative models can function as unified solutions for image restoration, potentially simplifying pipelines that currently rely on specialized traditional models. The explicit identification of metric limitations and the call for better controllability add constructive value by highlighting open problems in evaluation.
major comments (2)
- Abstract: The claim of 'competitive full-reference performance' is load-bearing for the replacement thesis yet is presented without any numerical scores, baseline comparisons, tables, or error analysis in the abstract; this absence directly weakens the central assertion given the paper's own statement that the observed over-enhancement and inconsistencies are not captured by the metrics used to support competitiveness.
- Abstract: The explicit admission that 'this issue is not well captured by existing IQA metrics or user studies' creates an internal tension with the use of precisely those tools to assert competitiveness and user preference; the evaluation framework therefore cannot securely underwrite the conclusion that Nano Banana 2 can replace traditional models.
minor comments (1)
- Abstract: The GitHub repository link is useful but the manuscript should embed at least one summary table of quantitative results and one representative visual comparison to allow readers to assess the claims without external access.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major comment below and have revised the abstract to improve clarity and support for our claims.
read point-by-point responses
-
Referee: Abstract: The claim of 'competitive full-reference performance' is load-bearing for the replacement thesis yet is presented without any numerical scores, baseline comparisons, tables, or error analysis in the abstract; this absence directly weakens the central assertion given the paper's own statement that the observed over-enhancement and inconsistencies are not captured by the metrics used to support competitiveness.
Authors: We agree that the abstract would be strengthened by including concrete numerical support. In the revised manuscript we have added a concise statement of key full-reference results (average PSNR and LPIPS across the evaluated datasets relative to the strongest traditional baselines) while preserving brevity. The complete tables, per-degradation breakdowns, and error analysis remain in Section 4 and the supplementary material. revision: yes
-
Referee: Abstract: The explicit admission that 'this issue is not well captured by existing IQA metrics or user studies' creates an internal tension with the use of precisely those tools to assert competitiveness and user preference; the evaluation framework therefore cannot securely underwrite the conclusion that Nano Banana 2 can replace traditional models.
Authors: The referee correctly notes a presentational tension. We have partially revised the abstract to explicitly distinguish the two layers of evidence: standard IQA metrics and user studies are reported because they are the established benchmarks for competitiveness, yet the text now states that these same tools do not fully capture the observed fidelity gap. This framing preserves the empirical findings while making the limitations and the call for improved controllability and fidelity-aware evaluation the central takeaway, rather than an unqualified replacement claim. revision: partial
Circularity Check
No circularity: empirical evaluation without derivations or self-referential modeling
full rationale
The paper is a systematic empirical evaluation of Nano Banana 2 on image restoration tasks. It reports performance via full-reference metrics, user studies, and observations of over-enhancement without any equations, parameter fitting, derivations, or modeling steps. Claims rest on independent test results and studies; no load-bearing step reduces to its own inputs by construction. The noted gap between perceptual quality and fidelity is presented as an observation, not a fitted or self-defined result.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
prompt design plays a critical role... concise prompts with explicit fidelity constraints... competitive full-reference performance... gap between perceptual quality and restoration fidelity... not well captured by existing IQA metrics
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Nano Banana 2 achieves superior performance in full-reference metrics... user studies... strong generalization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 1, 2
work page 2022
-
[2]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.NeurIPS, 35:36479–36494, 2022
work page 2022
-
[3]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InCVPR, pages 18392–18402, 2023
work page 2023
-
[4]
Grok imagine image.https : / / docs
xAI. Grok imagine image.https : / / docs . x . ai/developers/models/grok-imagine-image,
-
[5]
Accessed: 2026-03-22
work page 2026
-
[6]
Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
-
[7]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next- generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Improving image generation with better captions.Computer Science, 2(3):8, 2023
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science, 2(3):8, 2023
work page 2023
-
[9]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising.TIP, 26(7):3142–3155, 2017. 1
work page 2017
-
[11]
Deblurgan: Blind motion deblurring using conditional adversarial networks
Orest Kupyn, V olodymyr Budzan, Mykola Mykhailych, Dmytro Mishkin, and Ji ˇr´ı Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. InCVPR, pages 8183–8192, 2018. 1
work page 2018
-
[12]
Image super-resolution using deep convolutional net- works.PAMI, 38(2):295–307, 2015
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional net- works.PAMI, 38(2):295–307, 2015. 1, 2
work page 2015
-
[13]
Esrgan: En- hanced super-resolution generative adversarial networks
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: En- hanced super-resolution generative adversarial networks. In ECCVW, pages 63–79, 2018. 1, 2
work page 2018
-
[14]
Compression artifacts reduction by a deep convolu- tional network
Chao Dong, Yubin Deng, Chen Change Loy, and Xiaoou Tang. Compression artifacts reduction by a deep convolu- tional network. InICCV, pages 576–584, 2015. 1
work page 2015
-
[15]
Sinsr: diffusion-based image super- resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super- resolution in a single step. InCVPR, pages 25796–25805,
-
[16]
Generative dif- fusion prior for unified image restoration and enhancement
Ben Fei, Zhaoyang Lyu, Liang Pan, Junzhe Zhang, Weidong Yang, Tianyue Luo, Bo Zhang, and Bo Dai. Generative dif- fusion prior for unified image restoration and enhancement. InCVPR, pages 9935–9946, 2023
work page 2023
-
[17]
Exploiting diffusion prior for real-world image super-resolution.IJCV, 132(12):5929– 5949, 2024
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.IJCV, 132(12):5929– 5949, 2024. 1, 2
work page 2024
-
[18]
Unires: Universal im- age restoration for complex degradations
Mo Zhou, Keren Ye, Mauricio Delbracio, Peyman Milanfar, Vishal M Patel, and Hossein Talebi. Unires: Universal im- age restoration for complex degradations. InICCV, pages 13237–13247, 2025. 1, 2
work page 2025
-
[19]
Diffusion models in low-level vision: A survey.PAMI, 2025
Chunming He, Yuqi Shen, Chengyu Fang, Fengyang Xiao, Longxiang Tang, Yulun Zhang, Wangmeng Zuo, Zhenhua Guo, and Xiu Li. Diffusion models in low-level vision: A survey.PAMI, 2025
work page 2025
-
[20]
A survey on all-in-one image restoration: Tax- onomy, evaluation and future trends.PAMI, 2025
Junjun Jiang, Zengyuan Zuo, Gang Wu, Kui Jiang, and Xi- anming Liu. A survey on all-in-one image restoration: Tax- onomy, evaluation and future trends.PAMI, 2025. 1, 2
work page 2025
-
[21]
Generative modeling by esti- mating gradients of the data distribution.NeurIPS, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by esti- mating gradients of the data distribution.NeurIPS, 32, 2019. 1
work page 2019
-
[22]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InCVPR, pages 6228–6237, 2018. 1
work page 2018
-
[28]
Xiang Yin, Jinfan Hu, Zhiyuan You, Kainan Yan, Yu Tang, Chao Dong, and Jinjin Gu. How far have we gone in gener- ative image restoration? a study on its capability, limitations and evaluation practices.arXiv preprint arXiv:2603.05010,
-
[29]
Jialong Zuo, Haoyou Deng, Hanyu Zhou, Jiaxin Zhu, Yicheng Zhang, Yiwei Zhang, Yongxin Yan, Kaixing Huang, Weisen Chen, Yongtai Deng, et al. Is nano banana pro a low-level vision all-rounder? a comprehensive evaluation on 14 tasks and 40 datasets.arXiv preprint arXiv:2512.15110,
-
[30]
Pipal: a large-scale image quality assessment dataset for perceptual image restoration
Gu Jinjin, Cai Haoming, Chen Haoyu, Ye Xiaoxing, Jimmy S Ren, and Dong Chao. Pipal: a large-scale image quality assessment dataset for perceptual image restoration. InECCV, pages 633–651, 2020. 2, 7
work page 2020
-
[31]
Jiale Zhang, Yulun Zhang, Jinjin Gu, Yongbing Zhang, Linghe Kong, and Xin Yuan. Accurate image restora- tion with attention retractable transformer.arXiv preprint arXiv:2210.01427, 2022. 2
-
[32]
Image denoising by sparse 3-d transform- domain collaborative filtering.TIP, 16(8):2080–2095, 2007
Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform- domain collaborative filtering.TIP, 16(8):2080–2095, 2007. 2
work page 2080
-
[33]
Bilateral filtering for gray and color images
Carlo Tomasi and Roberto Manduchi. Bilateral filtering for gray and color images. InICCV, pages 839–846. IEEE,
-
[34]
Acceler- ating the super-resolution convolutional neural network
Chao Dong, Chen Change Loy, and Xiaoou Tang. Acceler- ating the super-resolution convolutional neural network. In ECCV, pages 391–407, 2016. 2
work page 2016
-
[35]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InCVPR, pages 5728–5739, 2022. 2
work page 2022
-
[36]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InICCV, pages 1833–1844, 2021. 2
work page 2021
-
[37]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InCVPR, pages 25669–25680, 2024. 2, 7
work page 2024
-
[38]
Fanghua Yu, Jinjin Gu, Jinfan Hu, Zheyuan Li, and Chao Dong. Unicon: Unidirectional information flow for effec- tive control of large-scale diffusion models.arXiv preprint arXiv:2503.17221, 2025. 2
-
[39]
Ultraedit: Instruction-based fine-grained im- age editing at scale.NeurIPS, 37:3058–3093, 2024
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Ru- jie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained im- age editing at scale.NeurIPS, 37:3058–3093, 2024. 3
work page 2024
-
[40]
Regev Cohen, Idan Kligvasser, Ehud Rivlin, and Daniel Freedman. Looks too good to be true: An information- theoretic analysis of hallucinations in generative restoration models.NeurIPS, 37:22596–22623, 2024. 3
work page 2024
-
[41]
Harnessing diffusion-yielded score priors for image restoration.TOG, 44(6):1–21, 2025
Xinqi Lin, Fanghua Yu, Jinfan Hu, Zhiyuan You, Wu Shi, Jimmy S Ren, Jinjin Gu, and Chao Dong. Harnessing diffusion-yielded score priors for image restoration.TOG, 44(6):1–21, 2025. 4
work page 2025
-
[42]
Ziyi Tong, Xinding Jiang, Jiemin Hu, Lu Xu, Long Wu, Xu Yang, and Bo Zou. Tsdsr: temporal–spatial domain de- noise super-resolution photon-efficient 3d reconstruction by deep learning. InPhotonics, volume 10, page 744. MDPI,
-
[43]
Pixel-level and semantic-level adjustable super-resolution: A dual-lora approach
Lingchen Sun, Rongyuan Wu, Zhiyuan Ma, Shuaizheng Liu, Qiaosi Yi, and Lei Zhang. Pixel-level and semantic-level adjustable super-resolution: A dual-lora approach. InCVPR, pages 2333–2343, 2025. 4
work page 2025
-
[44]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InECCV, pages 430–448, 2024. 4
work page 2024
-
[45]
Image quality assessment: from error visibility to structural similarity.TIP, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.TIP, 13(4):600–612, 2004. 4
work page 2004
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595,
-
[47]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InCVPR, pages 5148–5157, 2021. 4
work page 2021
-
[48]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InCVPR, pages 1191–1200,
-
[49]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In AAAI, volume 37, pages 2555–2563, 2023. 4
work page 2023
-
[50]
Milton Friedman. The use of ranks to avoid the assumption of normality implicit in the analysis of variance.Journal of the american statistical association, 32(200):675–701, 1937. 5
work page 1937
-
[51]
Jinfan Hu, Fanghua Yu, Zhiyuan You, Xiang Yin, Hongyu An, Xinqi Lin, Chao Dong, and Jinjin Gu. Position: Eval- uation of visual processing should be human-centered, not metric-centered.arXiv preprint arXiv:2603.00643, 2026. 7 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.