Recognition: 2 theorem links
· Lean TheoremFlash-Mono: Feed-Forward Accelerated Gaussian Splatting Monocular SLAM
Pith reviewed 2026-05-13 19:03 UTC · model grok-4.3
The pith
A recurrent feed-forward network directly predicts Gaussian surfels and poses to replace per-frame optimization in monocular SLAM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
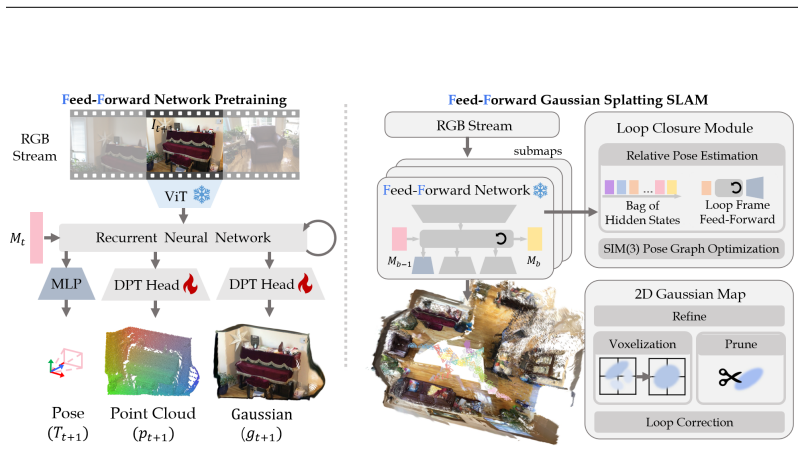
Flash-Mono shows that a recurrent feed-forward model can progressively aggregate multi-frame context via cross attention to predict both camera poses and per-pixel 2D Gaussian surfel properties in a single pass. By bypassing per-frame optimization entirely, the approach achieves an order-of-magnitude speedup while maintaining high-quality mapping and tracking. The hidden states additionally function as submap descriptors that support fast loop closure and global scale-consistent optimization.
What carries the argument
Recurrent feed-forward frontend that aggregates visual features across frames via cross attention into a hidden state and jointly predicts poses plus per-pixel Gaussian surfel attributes.
If this is right
- Runtime drops by a factor of ten because Gaussian attributes are predicted rather than optimized per frame.
- 2D Gaussian surfels supply sufficient geometric detail for accurate tracking and mapping without 3D ellipsoids.
- Hidden states act as compact descriptors that enable efficient loop closure and global Sim(3) bundle adjustment.
- The system reaches state-of-the-art tracking accuracy and mapping quality on standard monocular SLAM benchmarks.
- Real-time reconstruction becomes feasible for embodied perception tasks that previously required offline processing.
Where Pith is reading between the lines
- The same recurrent hidden-state mechanism could be adapted to fuse additional sensor streams such as depth or IMU data without changing the core architecture.
- Because prediction replaces optimization, the method may scale more readily to longer sequences or higher-resolution imagery than optimization-heavy GS-SLAM variants.
- Training on more diverse multi-environment datasets would directly test and likely improve the observed generalization to new scenes.
- The 2D surfel choice may trade off some volumetric representation power for speed, suggesting a hybrid 2D-3D extension as a natural next step.
Load-bearing premise
The recurrent model, trained on particular datasets, generalizes to unseen scenes while preserving inter-frame scale consistency.
What would settle it
A long trajectory in an environment absent from training data that exhibits accumulating scale drift or inconsistent loop closures would show the generalization assumption fails.
Figures






read the original abstract
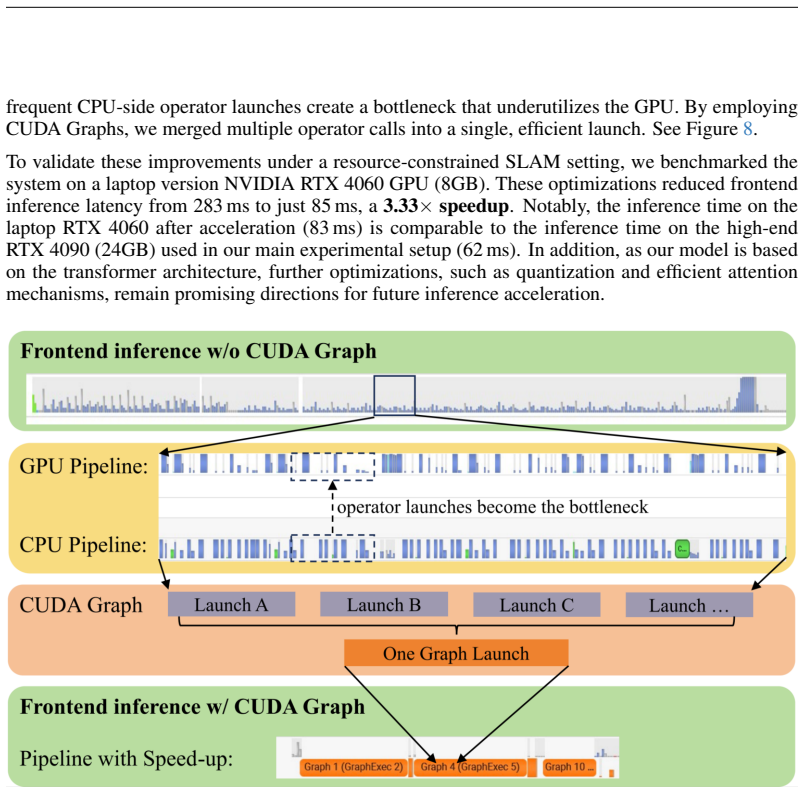
Monocular 3D Gaussian Splatting SLAM suffers from critical limitations in time efficiency, geometric accuracy, and multi-view consistency. These issues stem from the time-consuming $\textit{Train-from-Scratch}$ optimization and the lack of inter-frame scale consistency from single-frame geometry priors. We contend that a feed-forward paradigm, leveraging multi-frame context to predict Gaussian attributes directly, is crucial for addressing these challenges. We present Flash-Mono, a system composed of three core modules: a feed-forward prediction frontend, a 2D Gaussian Splatting mapping backend, and an efficient hidden-state-based loop closure module. We trained a recurrent feed-forward frontend model that progressively aggregates multi-frame visual features into a hidden state via cross attention and jointly predicts camera poses and per-pixel Gaussian properties. By directly predicting Gaussian attributes, our method bypasses the burdensome per-frame optimization required in optimization-based GS-SLAM, achieving a $\textbf{10x}$ speedup while ensuring high-quality rendering. The power of our recurrent architecture extends beyond efficient prediction. The hidden states act as compact submap descriptors, facilitating efficient loop closure and global $\mathrm{Sim}(3)$ optimization to mitigate the long-standing challenge of drift. For enhanced geometric fidelity, we replace conventional 3D Gaussian ellipsoids with 2D Gaussian surfels. Extensive experiments demonstrate that Flash-Mono achieves state-of-the-art performance in both tracking and mapping quality, highlighting its potential for embodied perception and real-time reconstruction applications. Project page: https://victkk.github.io/flash-mono.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Flash-Mono, a monocular SLAM system based on Gaussian Splatting that replaces per-frame optimization with a recurrent feed-forward neural network. The frontend aggregates multi-frame visual features via cross-attention into hidden states to jointly predict camera poses and per-pixel 2D Gaussian surfel attributes. A 2D Gaussian Splatting backend performs mapping, while hidden states serve as compact descriptors for efficient Sim(3) loop closure to mitigate drift. The work claims a 10x speedup over optimization-based GS-SLAM methods and state-of-the-art performance in both tracking and mapping quality on standard benchmarks.
Significance. If the empirical claims hold, the shift to a feed-forward paradigm with recurrent hidden-state aggregation would represent a meaningful advance for real-time monocular SLAM, enabling faster reconstruction suitable for embodied perception. The replacement of 3D ellipsoids with 2D Gaussian surfels for improved geometric fidelity and the dual use of hidden states for both prediction and loop closure are technically interesting contributions. The absence of post-hoc parameter fitting to the target metrics is a positive aspect of the approach.
major comments (3)
- [§5 Experiments and §5.3] §5 Experiments and §5.3: No cross-dataset evaluation or results on long sequences from environments outside the training distribution are reported. This is load-bearing for the central claim that the recurrent frontend generalizes while preserving inter-frame scale consistency, as all quantitative results appear confined to standard benchmarks that may overlap with training data.
- [§3.2 Recurrent Feed-Forward Frontend] §3.2 Recurrent Feed-Forward Frontend: The hidden-state dimension is treated as a free hyperparameter with no ablation study showing its effect on scale consistency or long-term drift; without this, the robustness of the Sim(3) loop-closure correction cannot be fully assessed.
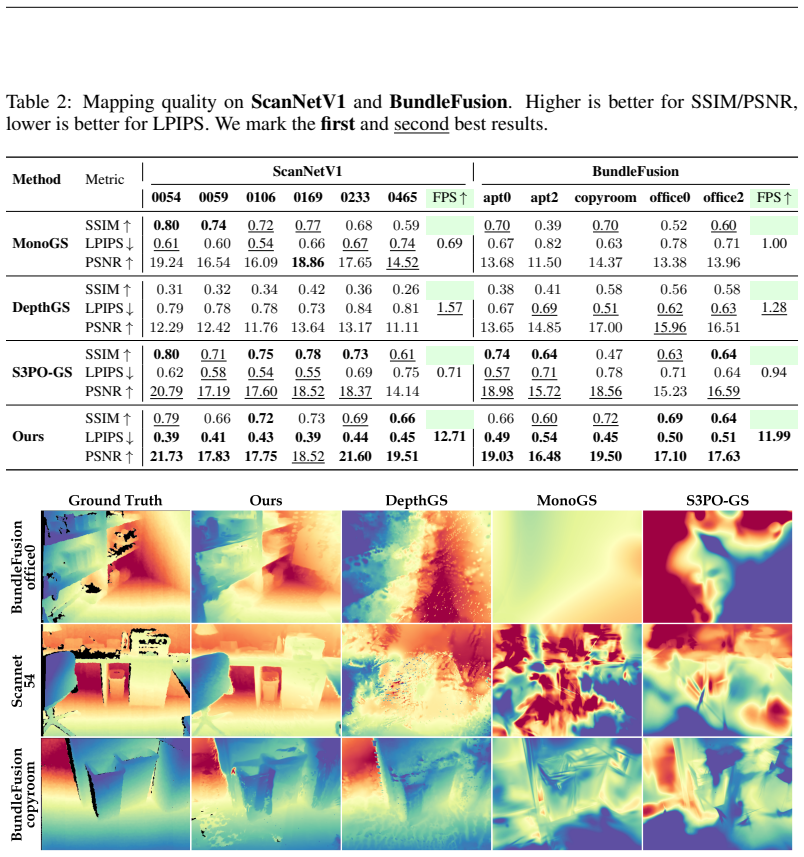
- [Table 2 (Tracking) and Table 3 (Mapping)] Table 2 (Tracking) and Table 3 (Mapping): The reported ATE/RPE and rendering metrics claim SOTA performance, but lack error bars, number of runs, or statistical significance tests, making it difficult to confirm that the 10x speedup and quality gains are reliable rather than sensitive to post-hoc choices.
minor comments (2)
- [Abstract and §4] Abstract and §4: The 2D Gaussian surfel formulation is introduced without an explicit equation contrasting its covariance and rendering integral against standard 3D Gaussian ellipsoids; adding this would improve clarity.
- [§3.1] §3.1: The cross-attention aggregation into hidden states is described at a high level; a diagram or pseudocode for the recurrent update rule would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and describe the revisions we will make to strengthen the claims on generalization, robustness, and statistical reliability.
read point-by-point responses
-
Referee: [§5 Experiments and §5.3] No cross-dataset evaluation or results on long sequences from environments outside the training distribution are reported. This is load-bearing for the central claim that the recurrent frontend generalizes while preserving inter-frame scale consistency, as all quantitative results appear confined to standard benchmarks that may overlap with training data.
Authors: We agree this is an important gap. Our training used sequences from TUM-RGBD, Replica, and ScanNet, but to demonstrate generalization we will add cross-dataset results on long KITTI sequences (not seen during training) in the revised §5. These will include ATE/RPE on trajectories with large scale changes to directly support the recurrent frontend's scale consistency and Sim(3) loop-closure effectiveness outside the training distribution. revision: yes
-
Referee: [§3.2 Recurrent Feed-Forward Frontend] The hidden-state dimension is treated as a free hyperparameter with no ablation study showing its effect on scale consistency or long-term drift; without this, the robustness of the Sim(3) loop-closure correction cannot be fully assessed.
Authors: We will add a dedicated ablation subsection (or extend §3.2) evaluating hidden-state dimensions of 128, 256, and 512. The study will report ATE, pre- and post-loop-closure scale drift, and mapping quality on representative sequences, allowing readers to assess how dimension choice affects long-term consistency and Sim(3) correction robustness. revision: yes
-
Referee: [Table 2 (Tracking) and Table 3 (Mapping)] The reported ATE/RPE and rendering metrics claim SOTA performance, but lack error bars, number of runs, or statistical significance tests, making it difficult to confirm that the 10x speedup and quality gains are reliable rather than sensitive to post-hoc choices.
Authors: We accept this criticism. In the revised Tables 2 and 3 we will report mean ± standard deviation over five independent runs with varied random seeds. We will also add a short paragraph confirming that the 10x speedup (arising from the feed-forward design) remains consistent across runs and is not sensitive to post-hoc tuning. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central claim rests on a trained recurrent feed-forward network that aggregates multi-frame features via cross-attention to jointly predict poses and per-pixel Gaussian properties. This architecture directly outputs the quantities needed for 2D Gaussian surfel mapping and hidden-state loop closure, bypassing per-frame optimization by design. No equation defines a quantity in terms of its own output, no fitted parameter is relabeled as a prediction, and no load-bearing premise reduces to a self-citation whose validity is internal to the present work. Performance numbers (including the reported 10x speedup) are obtained from external experimental evaluation rather than from any tautological reduction of the claimed result to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- hidden-state dimension
axioms (1)
- domain assumption A recurrent network with cross-attention can learn inter-frame scale-consistent geometry from monocular image sequences.
invented entities (1)
-
2D Gaussian surfels
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
recurrent feed-forward frontend model that progressively aggregates multi-frame visual features into a hidden state via cross attention and jointly predicts camera poses and per-pixel Gaussian properties
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By directly predicting Gaussian attributes, our method bypasses the burdensome per-frame optimization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.