Recognition: no theorem link
Revealing Physical-World Semantic Vulnerabilities: Universal Adversarial Patches for Infrared Vision-Language Models
Pith reviewed 2026-05-13 19:39 UTC · model grok-4.3
The pith
A universal curved-grid patch disrupts semantic understanding in infrared vision-language models even after physical deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
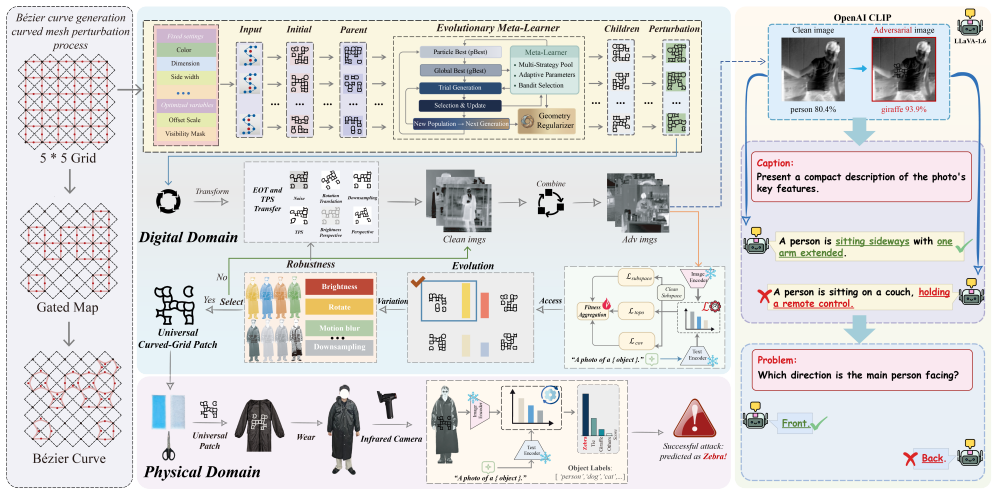
UCGP integrates Curved-Grid Mesh parameterization for continuous, low-frequency patch generation with a unified representation-driven objective that promotes subspace departure, topology disruption, and stealth. Combined with Meta Differential Evolution and EOT-augmented TPS deformation, the resulting patches weaken cross-modal semantic alignment and compromise semantic understanding across diverse IR-VLM architectures while preserving cross-model transferability, cross-dataset generalization, and physical effectiveness.
What carries the argument
Universal Curved-Grid Patch (UCGP) with Curved-Grid Mesh parameterization and a representation-driven objective that directly attacks the visual embedding space instead of labels or prompts.
If this is right
- UCGP transfers across different IR-VLM architectures without architecture-specific retraining.
- The patches generalize to unseen infrared datasets while keeping attack strength.
- Physical deployment remains effective after printing and under natural scene variations.
- The attack resists several existing defense strategies aimed at adversarial patches.
Where Pith is reading between the lines
- Representation-level attacks may prove more general than label-level attacks when models must handle open-ended semantic tasks.
- Security evaluations for multimodal systems should include physical patch testing in the infrared domain rather than digital-only checks.
- Similar mesh-based parameterization could be tested on other sensor-language combinations such as radar or depth data.
Load-bearing premise
The Curved-Grid Mesh parameterization and unified objective can be reliably optimized to retain effectiveness after physical printing, placement, and real-world imaging variations.
What would settle it
A controlled real-world test in which the printed UCGP is placed on objects and imaged with an actual infrared camera, then fed to multiple IR-VLMs, shows no measurable drop in semantic understanding accuracy relative to clean inputs.
Figures









read the original abstract
Infrared vision-language models (IR-VLMs) have emerged as a promising paradigm for multimodal perception in low-visibility environments, yet their robustness to adversarial attacks remains largely unexplored. Existing adversarial patch methods are mainly designed for RGB-based models in closed-set settings and are not readily applicable to the open-ended semantic understanding and physical deployment requirements of infrared VLMs. To bridge this gap, we propose Universal Curved-Grid Patch (UCGP), a universal physical adversarial patch framework for IR-VLMs. UCGP integrates Curved-Grid Mesh (CGM) parameterization for continuous, low-frequency, and deployable patch generation with a unified representation-driven objective that promotes subspace departure, topology disruption, and stealth. To improve robustness under real-world deployment and domain shift, we further incorporate Meta Differential Evolution and EOT-augmented TPS deformation modeling. Rather than manipulating labels or prompts, UCGP directly disrupts the visual representation space, weakening cross-modal semantic alignment. Extensive experiments demonstrate that UCGP consistently compromises semantic understanding across diverse IR-VLM architectures while maintaining cross-model transferability, cross-dataset generalization, real-world physical effectiveness, and robustness against defenses. These findings reveal a previously overlooked robustness vulnerability in current infrared multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Universal Curved-Grid Patch (UCGP) framework for generating universal physical adversarial patches targeting infrared vision-language models (IR-VLMs). It introduces Curved-Grid Mesh (CGM) parameterization for continuous low-frequency patch generation combined with a unified representation-driven objective that targets subspace departure, topology disruption, and stealth. Optimization employs Meta Differential Evolution and EOT-augmented TPS deformation modeling to enhance robustness under domain shift. The central claim is that UCGP compromises semantic understanding across diverse IR-VLM architectures while achieving cross-model transferability, cross-dataset generalization, real-world physical effectiveness, and defense robustness, without directly manipulating labels or prompts.
Significance. If the physical and transfer results hold under rigorous validation, the work is significant for exposing a previously unexamined vulnerability in IR-VLMs, which are increasingly relevant for low-visibility multimodal perception in safety-critical domains. The shift from closed-set classification attacks to open-ended semantic disruption via representation-space methods is a useful extension of prior adversarial patch literature. The parameterization and deformation modeling could support reproducible follow-up work if code and exact experimental protocols are released.
major comments (3)
- [§5.2] §5.2 (Physical Deployment): The physical-world effectiveness claim rests on EOT-augmented TPS deformation bridging simulation to real IR sensors, yet no quantitative ablation compares attack success rates with and without thermal-drift or emissivity modeling; this directly affects whether the reported robustness generalizes beyond controlled indoor conditions.
- [Table 3] Table 3 (Cross-Dataset Results): Reported success rates for cross-dataset generalization lack error bars, statistical significance tests, or per-run variance; without these, the generalization claim cannot be assessed as load-bearing for the overall vulnerability revelation.
- [§4.1] §4.1 (Objective Formulation): The unified representation-driven objective combines subspace departure and topology disruption, but the relative weighting between terms is not ablated; this leaves unclear whether the reported effectiveness is driven by the CGM parameterization or by the specific loss combination.
minor comments (2)
- [Abstract] Abstract: The abstract asserts 'extensive experiments' and 'robustness against defenses' without summarizing any quantitative metrics, success rates, or ablation highlights; adding a single sentence with key numbers would improve clarity.
- [§3.1] Notation: The definition of the Curved-Grid Mesh parameterization in §3.1 uses several free parameters whose ranges are not explicitly bounded in the text, which could hinder reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate to strengthen the paper.
read point-by-point responses
-
Referee: [§5.2] §5.2 (Physical Deployment): The physical-world effectiveness claim rests on EOT-augmented TPS deformation bridging simulation to real IR sensors, yet no quantitative ablation compares attack success rates with and without thermal-drift or emissivity modeling; this directly affects whether the reported robustness generalizes beyond controlled indoor conditions.
Authors: We acknowledge that while EOT-augmented TPS captures geometric deformations, an explicit quantitative ablation isolating thermal-drift and emissivity effects was not included. In the revised manuscript, we will add this ablation study to §5.2, reporting attack success rates under simulated thermal variations with and without these factors to better substantiate generalization claims beyond controlled conditions. revision: yes
-
Referee: [Table 3] Table 3 (Cross-Dataset Results): Reported success rates for cross-dataset generalization lack error bars, statistical significance tests, or per-run variance; without these, the generalization claim cannot be assessed as load-bearing for the overall vulnerability revelation.
Authors: We agree that statistical rigor is necessary to support the generalization claims. We will revise Table 3 to include error bars (standard deviations across runs), per-run variance, and statistical significance tests such as paired t-tests between datasets. revision: yes
-
Referee: [§4.1] §4.1 (Objective Formulation): The unified representation-driven objective combines subspace departure and topology disruption, but the relative weighting between terms is not ablated; this leaves unclear whether the reported effectiveness is driven by the CGM parameterization or by the specific loss combination.
Authors: We recognize that the relative weights were determined via preliminary tuning without a full ablation. In the revised manuscript, we will add an ablation study in §4.1 that varies the weights of the subspace departure and topology disruption terms, reporting their individual contributions and combined effects on performance to clarify the role of each component versus the CGM parameterization. revision: yes
Circularity Check
No circularity: UCGP framework integrates standard optimization with new parameterization without self-referential reductions
full rationale
The paper defines UCGP via Curved-Grid Mesh (CGM) parameterization plus a representation-driven objective (subspace departure + topology disruption), then optimizes via Meta Differential Evolution and EOT-augmented TPS. These steps are presented as constructive engineering choices applied to the IR-VLM attack problem, not as quantities fitted to the target metric and then renamed as predictions. No equations equate the claimed physical effectiveness to the inputs by construction, and no load-bearing self-citation chain or uniqueness theorem is invoked to force the result. Experiments are offered as external validation rather than tautological confirmation.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Universal Curved-Grid Patch (UCGP)
no independent evidence
-
Curved-Grid Mesh (CGM)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
LLM-as-Judge Framework for Evaluating Tone-Induced Hallucination in Vision-Language Models
Ghost-100 benchmark shows prompt tone drives hallucination rates and intensities in VLMs, with non-monotonic peaks at intermediate pressure and task-specific differences that aggregate metrics hide.
Reference graph
Works this paper leans on
-
[1]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021. URLhttps://arxiv.org/ abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Infrared-llava: Enhancing understanding of infrared images in multi-modal large language models
Shixin Jiang, Zerui Chen, Jiafeng Liang, Yanyan Zhao, Ming Liu, and Bing Qin. Infrared-llava: Enhancing understanding of infrared images in multi-modal large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8573– 8591, 2024. doi: 10.18653/v1/2024.findings-emnlp.501. URL https://aclanthology.org/2024.findings-...
-
[3]
Zhe Cao, Jin Zhang, and Ruiheng Zhang. IRGPT: Under- standing real-world infrared image with bi-cross-modal curriculum on large-scale benchmark. arXiv preprint arXiv:2507.14449, 2025. URLhttps://arxiv.org/ abs/2507.14449. Accepted by ICCV 2025
-
[4]
RGB-Th-Bench: A dense benchmark for visual-thermal understanding of vision language models
MehdiMoshtaghi,SiavashH.Khajavi,andJoniPajarinen. RGB-Th-Bench: A dense benchmark for visual-thermal understanding of vision language models. arXiv preprint arXiv:2503.19654, 2025. URLhttps://arxiv.org/ abs/2503.19654. arXiv:2503.19654
-
[5]
IF-Bench: Benchmarking and enhancing mllms for infrared images with generative visual prompt- ing
Tao Zhang, Yuyang Hong, Yang Xia, Kun Ding, Zeyu Zhang, Ying Wang, Shiming Xiang, and Chunhong Pan. IF-Bench: Benchmarking and enhancing mllms for infrared images with generative visual prompt- ing. https://arxiv.org/abs/2512.09663 , 2025. arXiv:2512.09663
-
[6]
ThermEval: A structured bench- markforevaluationofvision-languagemodelsonthermal imagery
Ayush Shrivastava, Kirtan Gangani, Laksh Jain, Mayank Goel, and Nipun Batra. ThermEval: A structured bench- markforevaluationofvision-languagemodelsonthermal imagery. https : / / arxiv . org / abs / 2602 . 14989,
-
[7]
Synthesizing robust adversarial examples
AnishAthalye,LoganEngstrom,AndrewIlyas,andKevin Kwok. Synthesizing robust adversarial examples. InPro- ceedingsofthe35thInternationalConferenceonMachine Learning, volume 80 ofProceedings of Machine Learn- ing Research, pages 284–293, Stockholm, Sweden, 2018. PMLR. URL https://proceedings.mlr.press/ v80/athalye18b.html
work page 2018
-
[8]
Robustphysical-worldattackson deep learning visual classification
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno,andDawnSong. Robustphysical-worldattackson deep learning visual classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1625–1634, Salt Lake City, UT, USA,
-
[9]
IEEE. doi: 10.1109/CVPR.2018.00175
-
[10]
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak aligned large language models.ProceedingsoftheAAAIConferenceonArtificial Intelligence, 38(19):21527–21536, 2024. doi: 10.1609/ aaai.v38i19.30150
work page 2024
-
[11]
Peng Xie, Yequan Bie, Jianda Mao, Yangqiu Song, Yang Wang, Hao Chen, and Kani Chen. Chain of attack: On the robustness of vision-language models against transfer- basedadversarialattacks.InProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14752–14761, Nashville, TN, USA, 2025. IEEE. doi: 10.1109/CVPR52734.2025.01368. 9
-
[12]
arXiv preprint arXiv:2312.14217, 2024
ChengyinHuandWeiwenShi.Adversarialinfraredcurves: An attack on infrared pedestrian detectors in the physical world. arXiv preprint arXiv:2312.14217, 2024. URL https://arxiv.org/abs/2312.14217
-
[13]
Kalibinuer Tiliwalidi, Chengyin Hu, and Weiwen Shi. Multi-view black-box physical attacks on infrared pedes- trian detectors using adversarial infrared grid. arXiv preprintarXiv:2407.01168,2024. URL https://arxiv. org/abs/2407.01168
-
[14]
Review on infrared imaging technology.Sustainability, 14(18):11161, 2022
Fujin Hou, Yan Zhang, Yong Zhou, Mei Zhang, Bin Lv, and Jianqing Wu. Review on infrared imaging technology.Sustainability, 14(18):11161, 2022. doi: 10.3390/su141811161
-
[15]
In2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, and Wenli Zhou. Llvip: A visible-infrared paired dataset for low-light vision. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 3489–3497, Montreal, QC, Canada, 2021. IEEE. doi: 10.1109/ICCVW54120.2021.00389
-
[16]
Wanqi Zhou, Shuanghao Bai, Danilo P. Mandic, Qibin Zhao, and Badong Chen. Revisiting the adversarial ro- bustness of vision language models: a multimodal per- spective. arXiv preprint arXiv:2404.19287, 2024. URL https://arxiv.org/abs/2404.19287
-
[17]
Explaining and Harnessing Adversarial Examples
IanJ.Goodfellow,JonathonShlens,andChristianSzegedy. Explaining and harnessing adversarial examples. InInter- national Conference on Learning Representations, 2015. URLhttps://arxiv.org/abs/1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Xiaopei Zhu, Zhanhao Hu, Siyuan Huang, Jianmin Li, and Xiaolin Hu. Infrared invisible clothing: Hiding frominfrareddetectorsatmultipleanglesinrealworld. In ProceedingsoftheIEEE/CVFConferenceonComputerVi- sion and Pattern Recognition, 2022. doi: 10.48550/arXiv. 2205.05909. URL https : / / openaccess . thecvf . com / content / CVPR2022 / html / Zhu _ Infrar...
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[19]
Physically ad- versarial infrared patches with learnable shapes and lo- cations
Xingxing Wei, Jie Yu, and Yao Huang. Physically ad- versarial infrared patches with learnable shapes and lo- cations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. doi: 10.48550/arXiv.2303.13868. URL https://arxiv. org/abs/2303.13868
-
[20]
arXivpreprintarXiv:2304.10712,2023
Chengyin Hu, Weiwen Shi, Tingsong Jiang, Wen Yao, LingTian,andXiaoqianChen.Adversarialinfraredblocks: Amulti-viewblack-boxattacktothermalinfrareddetectors inphysicalworld. arXivpreprintarXiv:2304.10712,2023. URLhttps://arxiv.org/abs/2304.10712
-
[21]
Rainer Storn and Kenneth Price. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces.Journal of Global Optimization, 11(4):341–359, 1997. doi: 10.1023/A:1008202821328
-
[22]
Completely derandomized self-adaptation in evolution strategies
Nikolaus Hansen and Andreas Ostermeier. Completely derandomized self-adaptation in evolution strategies. Evolutionary Computation, 9(2):159–195, 2001. doi: 10.1162/106365601750190398
-
[23]
Black-box adversarial attacks with limited queries and information
Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. InProceedings of the 35th Interna- tional Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 2142– 2151, Stockholm, Sweden, 2018. PMLR. URLhttp: //proceedings.mlr.press/v80/ilyas18a.html
work page 2018
-
[24]
Square attack: A query-efficient black-box adversarial attack via random search
Maksym Andriushchenko and Francesco Croce. Square attack: A query-efficient black-box adversarial attack via random search. InComputer Vision – ECCV 2020, volume 12368 ofLecture Notes in Computer Science, pages 484–501, Cham, Switzerland, 2020. Springer. doi: 10.1007/978-3-030-58592-1_29
-
[25]
FredL.Bookstein.Principalwarps: Thin-platesplinesand thedecompositionofdeformations.IEEETransactionson PatternAnalysisandMachineIntelligence,11(6):567–585,
-
[26]
doi: 10.1109/34.24792
-
[27]
Xingxing Wei, Yao Huang, Yitong Sun, and Jie Yu. Uni- fied adversarial patch for visible-infrared cross-modal attacks in the physical world.IEEE Transactions on Pat- ternAnalysisandMachineIntelligence,46(4):2348–2363, 2023
work page 2023
-
[28]
Geoffrey E. Hinton and Sam T. Roweis. Stochastic neigh- bor embedding. InAdvances in Neural Information Pro- cessing Systems 15, 2002
work page 2002
-
[29]
Visualizing data using t-sne.Journal of Machine Learning Research, 9:2579–2605, 2008
LaurensvanderMaatenandGeoffreyHinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9:2579–2605, 2008
work page 2008
-
[30]
Metade: Evolving differential evolution by differential evolution
Minyang Chen, Chenchen Feng, and Ran Cheng. Metade: Evolving differential evolution by differential evolution. IEEE Transactions on Evolutionary Computation, 30(1): 141–155, 2026. doi: 10.1109/TEVC.2025.3541587
-
[31]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Mi- crosoft coco: Common objects in context. InEuropean Conference on Computer Vision, pages 740–755, 2014
work page 2014
-
[32]
Lsotb-tir: A large-scale high-diversity thermal infraredobjecttrackingbenchmark
QiaoLiu,XinLi,ZhenyuHe,ChenglongLi,JunLi,Zikun Zhou, Di Yuan, Jing Li, Kai Yang, Nana Fan, and Feng Zheng. Lsotb-tir: A large-scale high-diversity thermal infraredobjecttrackingbenchmark. InProceedingsofthe 28thACMInternationalConferenceonMultimedia,pages 3847–3856, New York, NY, USA, 2020. Association for Computing Machinery. doi: 10.1145/3394171.3413922. 10
-
[33]
Multispectral pedestrian detection: Benchmark dataset and baseline
SoonminHwang, JaesikPark, NamilKim, YukyungChoi, and In So Kweon. Multispectral pedestrian detection: Benchmark dataset and baseline. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, pages 1037–1045, Boston, MA, USA, 2015. IEEE. doi: 10.1109/CVPR.2015.7298706
-
[34]
FLIR Systems. FLIR ADAS Dataset v1.3. Online, 2018. URL https : / / www . flir . com / oem / adas / adas - dataset- form/. Referenced in RGB-T detection lit- erature as the FLIR thermal dataset; accessed March 2026
work page 2018
-
[35]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
-
[36]
Llava-next: Improved reasoning, ocr, and world knowledge
Haotian Liu, Chunyuan Li, Yuheng Li, Brandon Li, Yuan- han Zhang, Shijie Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge. Project page, 2024. URL https://llava- vl.github.io/ blog/2024-01-30-llava-next/. Model release page
work page 2024
-
[38]
URLhttps://arxiv.org/abs/2308.01390
work page internal anchor Pith review arXiv
-
[39]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023. URLhttps: //arxiv.org/abs/2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
WenliangDai,JunnanLi,DongxuLi,AnthonyMengHuat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung,andStevenC.H.Hoi. Instructblip: Towardsgeneral- purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023. URLhttps: //arxiv.org/abs/2305.06500
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jit- sev. Reproducible scaling laws for contrastive language- image learning. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 2818–2829, Vancouver, BC, Canada, 2023. IEEE...
-
[42]
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, RussellHowes,VasuSharma,Shang-WenLi,GargiGhosh, Luke Zettlemoyer, and Christoph Feichtenhofer. Demysti- fying clip data. arXiv preprint arXiv:2309.16671, 2023. URLhttps://arxiv.org/abs/2309.16671
-
[43]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023. URL https://arxiv.org/abs/2303.15389
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Repre- sentations, 2022
work page 2022
-
[45]
Hanqing Liu, Shouwei Ruan, Yao Huang, Shiji Zhao, and Xingxing Wei. When lighting deceives: Exposing vision- language models’ illumination vulnerability through il- lumination transformation attack. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 11
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.