Recognition: 1 theorem link
· Lean TheoremSD-FSMIS: Adapting Stable Diffusion for Few-Shot Medical Image Segmentation
Pith reviewed 2026-05-13 20:59 UTC · model grok-4.3
The pith
Adapting Stable Diffusion with support-query interaction and visual-to-textual translation enables competitive few-shot medical image segmentation with strong cross-domain generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
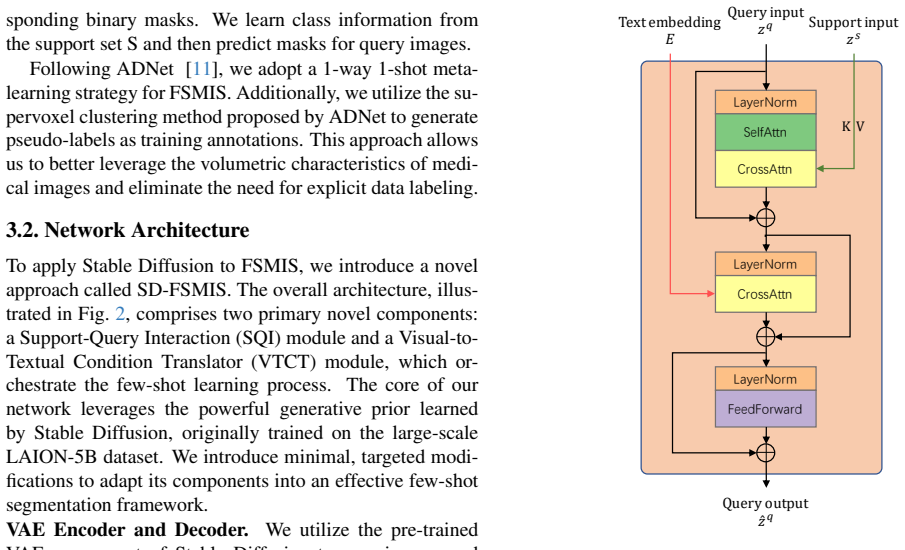
SD-FSMIS adapts the conditional generative architecture of Stable Diffusion for few-shot medical image segmentation by introducing Support-Query Interaction to integrate support and query images directly and a Visual-to-Textual Condition Translator to turn support-set visual information into guiding textual embeddings, yielding competitive accuracy in standard benchmarks and notably strong results under cross-domain shifts.
What carries the argument
Support-Query Interaction (SQI) and Visual-to-Textual Condition Translator (VTCT) modules that repurpose Stable Diffusion's pre-trained conditional generation for few-shot segmentation by fusing support-query data and translating visual conditions into textual embeddings.
If this is right
- Competitive segmentation accuracy on standard few-shot medical imaging benchmarks.
- Stronger performance than prior methods when source and target domains differ substantially.
- Reduced need for large annotated medical datasets by leveraging pre-trained generative priors.
- A template for adapting other large diffusion models to additional data-scarce imaging tasks.
Where Pith is reading between the lines
- Diffusion-model priors could lower annotation costs for clinical segmentation tools.
- The same adaptation pattern might apply to 3D volumes or multi-modal scans with minimal changes.
- Testing on entirely new medical modalities would reveal how far the natural-image priors extend.
Load-bearing premise
The visual priors learned by Stable Diffusion on natural images transfer effectively enough to medical images to support accurate segmentation from only a few examples despite domain differences.
What would settle it
A new cross-domain medical segmentation test set where SD-FSMIS falls substantially below existing state-of-the-art methods would falsify the generalization advantage.
Figures





read the original abstract
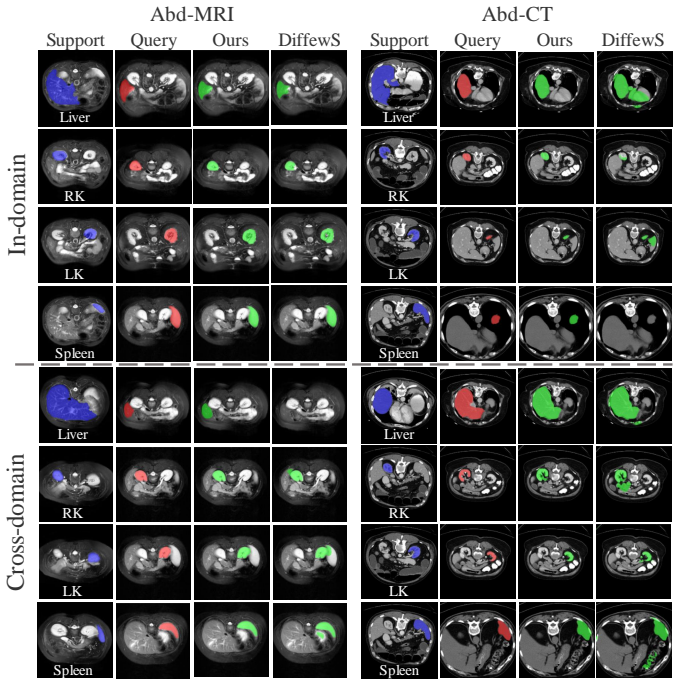
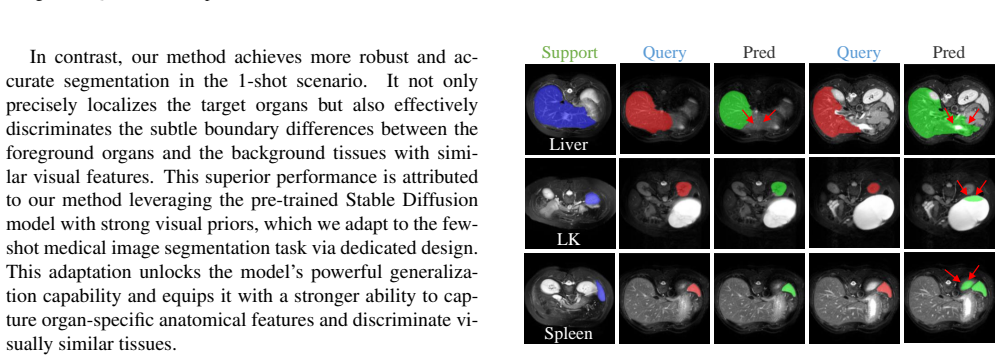
Few-Shot Medical Image Segmentation (FSMIS) aims to segment novel object classes in medical images using only minimal annotated examples, addressing the critical challenges of data scarcity and domain shifts prevalent in medical imaging. While Diffusion Models (DM) excel in visual tasks, their potential for FSMIS remains largely unexplored. We propose that the rich visual priors learned by large-scale DMs offer a powerful foundation for a more robust and data-efficient segmentation approach. In this paper, we introduce SD-FSMIS, a novel framework designed to effectively adapt the powerful pre-trained Stable Diffusion (SD) model for the FSMIS task. Our approach repurposes its conditional generative architecture by introducing two key components: a Support-Query Interaction (SQI) and a Visual-to-Textual Condition Translator (VTCT). Specifically, SQI provides a straightforward yet powerful means of adapting SD to the FSMIS paradigm. The VTCT module translates visual cues from the support set into an implicit textual embedding that guides the diffusion model, enabling precise conditioning of the generation process. Extensive experiments demonstrate that SD-FSMIS achieves competitive results compared to state-of-the-art methods in standard settings. Surprisingly, it also demonstrated excellent generalization ability in more challenging cross-domain scenarios. These findings highlight the immense potential of adapting large-scale generative models to advance data-efficient and robust medical image segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SD-FSMIS, a framework that adapts the pre-trained Stable Diffusion (SD) model for Few-Shot Medical Image Segmentation (FSMIS) by introducing two modules: Support-Query Interaction (SQI) to adapt the conditional generative architecture and Visual-to-Textual Condition Translator (VTCT) to convert support-set visual cues into implicit textual embeddings for guiding the diffusion process. It claims competitive performance versus state-of-the-art FSMIS methods on standard benchmarks together with strong generalization on cross-domain scenarios, attributing the gains to the rich visual priors learned by large-scale diffusion models.
Significance. If the central empirical claims are substantiated, the work would provide evidence that large-scale generative models can serve as effective backbones for data-efficient medical segmentation, particularly under domain shift. The introduction of SQI and VTCT offers a concrete adaptation strategy, but the lack of controls isolating the contribution of the pre-trained priors versus the added modules prevents a clear assessment of novelty or transferability.
major comments (2)
- [Experiments] Experiments section: the central claim that SD priors enable competitive standard-setting results and excellent cross-domain generalization rests on an untested assumption. No ablation freezes the pre-trained SD UNet weights while retaining SQI+VTCT, nor compares against an identically structured but randomly initialized backbone with the same modules; without this, it is impossible to attribute performance to the diffusion priors rather than the new conditioning components.
- [Method] Method section (SQI and VTCT definitions): the paper introduces SQI and VTCT as key innovations but provides no quantitative isolation of their individual contributions (e.g., performance with SQI alone, VTCT alone, or neither). This omission is load-bearing because the abstract frames the approach as an adaptation of SD priors, yet the added modules could be carrying the reported gains.
minor comments (2)
- [Abstract] Abstract: the claim of 'competitive results' and 'excellent generalization' is stated without any numerical values, dataset names, or baseline comparisons, reducing the reader's ability to gauge the strength of the empirical evidence before reaching the full experiments.
- [Method] Notation: the description of VTCT as translating 'visual cues into an implicit textual embedding' is conceptually clear but lacks a precise equation or diagram reference showing how the embedding is injected into the SD conditioning mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of empirical validation. We address each major point below and will revise the manuscript to incorporate the suggested ablations.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that SD priors enable competitive standard-setting results and excellent cross-domain generalization rests on an untested assumption. No ablation freezes the pre-trained SD UNet weights while retaining SQI+VTCT, nor compares against an identically structured but randomly initialized backbone with the same modules; without this, it is impossible to attribute performance to the diffusion priors rather than the new conditioning components.
Authors: We agree that isolating the contribution of the pre-trained SD priors versus the added modules is essential. In the revised manuscript we will add an ablation that freezes the SD UNet weights (keeping SQI and VTCT) and a second control that uses an identically structured but randomly initialized backbone with the same modules. These results will be reported on the standard benchmarks and cross-domain settings to clarify the source of the observed performance. revision: yes
-
Referee: [Method] Method section (SQI and VTCT definitions): the paper introduces SQI and VTCT as key innovations but provides no quantitative isolation of their individual contributions (e.g., performance with SQI alone, VTCT alone, or neither). This omission is load-bearing because the abstract frames the approach as an adaptation of SD priors, yet the added modules could be carrying the reported gains.
Authors: We acknowledge that separate ablations of SQI and VTCT are needed to quantify their individual and joint contributions. The revised version will include results for SQI alone, VTCT alone, and the full model on the same datasets, allowing readers to assess the incremental benefit of each component. revision: yes
Circularity Check
No circularity: empirical adaptation without derivations or self-referential reductions
full rationale
The paper presents SD-FSMIS as a practical framework that repurposes a pre-trained Stable Diffusion model by adding SQI and VTCT modules for few-shot medical image segmentation. Claims rest on experimental results showing competitive performance and cross-domain generalization rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central premise (rich visual priors from large-scale DMs) is treated as an external starting point justified by the model's established training, not derived internally. This is a standard empirical adaptation paper whose results are independently testable via ablation or replication and therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained Stable Diffusion models contain rich visual priors that transfer to medical image segmentation tasks.
invented entities (2)
-
Support-Query Interaction (SQI)
no independent evidence
-
Visual-to-Textual Condition Translator (VTCT)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach repurposes its conditional generative architecture by introducing two key components: a Support-Query Interaction (SQI) and a Visual-to-Textual Condition Translator (VTCT).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tomer Amit, Tal Shaharbany, Eliya Nachmani, and Lior Wolf. Segdiff: Image segmentation with diffusion proba- bilistic models.arXiv preprint arXiv:2112.00390, 2021. 2, 3
-
[2]
Label-efficient semantic segmentation with diffusion models.arXiv preprint arXiv:2112.03126, 2021
Dmitry Baranchuk, Ivan Rubachev, Andrey V oynov, Valentin Khrulkov, and Artem Babenko. Label-efficient se- mantic segmentation with diffusion models.arXiv preprint arXiv:2112.03126, 2021. 3
-
[3]
Yuntian Bo, Yazhou Zhu, Lunbo Li, and Haofeng Zhang. Famnet: Frequency-aware matching network for cross- domain few-shot medical image segmentation.arXiv preprint arXiv:2412.09319, 2024. 7
-
[4]
Uni- verseg: Universal medical image segmentation
Victor Ion Butoi, Jose Javier Gonzalez Ortiz, Tianyu Ma, Mert R Sabuncu, John Guttag, and Adrian V Dalca. Uni- verseg: Universal medical image segmentation. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 21438–21451, 2023. 8, 2
work page 2023
-
[5]
Dual interspersion and flex- ible deployment for few-shot medical image segmentation
Ziming Cheng, Shidong Wang, Yang Long, Tao Zhou, Haofeng Zhang, and Ling Shao. Dual interspersion and flex- ible deployment for few-shot medical image segmentation. IEEE Transactions on Medical Imaging, 2025. 2, 6, 7, 1
work page 2025
-
[6]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 2
work page 2021
-
[7]
Few-shot medical image segmentation with cycle- resemblance attention
Hao Ding, Changchang Sun, Hao Tang, Dawen Cai, and Yan Yan. Few-shot medical image segmentation with cycle- resemblance attention. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2488–2497, 2023. 3
work page 2023
-
[8]
Few-shot semantic segmen- tation with prototype learning
Nanqing Dong and Eric P Xing. Few-shot semantic segmen- tation with prototype learning. InBMVC, page 4, 2018. 2
work page 2018
-
[9]
Self- support few-shot semantic segmentation
Qi Fan, Wenjie Pei, Yu-Wing Tai, and Chi-Keung Tang. Self- support few-shot semantic segmentation. InEuropean Con- ference on Computer Vision, pages 701–719. Springer, 2022. 4
work page 2022
-
[10]
Ruiwei Feng, Xiangshang Zheng, Tianxiang Gao, Jintai Chen, Wenzhe Wang, Danny Z Chen, and Jian Wu. Interac- tive few-shot learning: Limited supervision, better medical image segmentation.IEEE Transactions on Medical Imag- ing, 40(10):2575–2588, 2021. 3
work page 2021
-
[11]
Stine Hansen, Srishti Gautam, Robert Jenssen, and Michael Kampffmeyer. Anomaly detection-inspired few-shot medi- cal image segmentation through self-supervision with super- voxels.Medical Image Analysis, 78:102385, 2022. 3, 4, 6, 1
work page 2022
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 1
work page 2016
-
[13]
Apseg: Auto-prompt network for cross-domain few-shot semantic segmentation
Weizhao He, Yang Zhang, Wei Zhuo, Linlin Shen, Jiaqi Yang, Songhe Deng, and Liang Sun. Apseg: Auto-prompt network for cross-domain few-shot semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23762–23772, 2024. 1
work page 2024
-
[14]
Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. Unsupervised semantic correspondence using stable diffu- sion.Advances in Neural Information Processing Systems, 36:8266–8279, 2023. 2, 3
work page 2023
-
[15]
Wendong Huang, Jinwu Hu, Junhao Xiao, Yang Wei, Xiuli Bi, and Bin Xiao. Prototype-guided graph reasoning network for few-shot medical image segmentation.IEEE Transac- tions on Medical Imaging, 2024. 6
work page 2024
-
[16]
A Emre Kavur, N Sinem Gezer, Mustafa Barıs ¸, Sinem Aslan, Pierre-Henri Conze, Vladimir Groza, Duc Duy Pham, Soumick Chatterjee, Philipp Ernst, Savas ¸¨Ozkan, et al. Chaos challenge-combined (ct-mr) healthy abdominal organ seg- mentation.Medical image analysis, 69:101950, 2021. 5
work page 2021
-
[17]
Repurpos- ing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met- zger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos- ing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9492– 9502, 2024. 4
work page 2024
-
[18]
Miccai multi- atlas labeling beyond the cranial vault–workshop and chal- lenge
Bennett Landman, Zhoubing Xu, Juan Igelsias, Martin Styner, Thomas Langerak, and Arno Klein. Miccai multi- atlas labeling beyond the cranial vault–workshop and chal- lenge. InProc. MICCAI multi-atlas labeling beyond cra- nial vault—workshop challenge, page 12. Munich, Germany,
-
[19]
Learning what not to segment: A new perspective on few- shot segmentation
Chunbo Lang, Gong Cheng, Binfei Tu, and Junwei Han. Learning what not to segment: A new perspective on few- shot segmentation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8057–8067, 2022. 2
work page 2022
-
[20]
Ex- ploiting diffusion prior for generalizable dense prediction
Hsin-Ying Lee, Hung-Yu Tseng, and Ming-Hsuan Yang. Ex- ploiting diffusion prior for generalizable dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 7861–7871, 2024. 3
work page 2024
-
[21]
Your diffusion model is secretly a zero-shot classifier
Alexander C Li, Mihir Prabhudesai, Shivam Duggal, Ellis Brown, and Deepak Pathak. Your diffusion model is secretly a zero-shot classifier. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 2206–2217,
-
[22]
Stable diffusion segmentation for biomed- ical images with single-step reverse process
Tianyu Lin, Zhiguang Chen, Zhonghao Yan, Weijiang Yu, and Fudan Zheng. Stable diffusion segmentation for biomed- ical images with single-step reverse process. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 656–666. Springer, 2024. 1, 3
work page 2024
-
[23]
Few shot medical image segmentation with cross attention transformer
Yi Lin, Yufan Chen, Kwang-Ting Cheng, and Hao Chen. Few shot medical image segmentation with cross attention transformer. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 233–
-
[24]
Diffusion hyperfeatures: Search- ing through time and space for semantic correspondence
Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holyn- ski, and Trevor Darrell. Diffusion hyperfeatures: Search- ing through time and space for semantic correspondence. Advances in Neural Information Processing Systems, 36: 47500–47510, 2023. 3
work page 2023
-
[25]
Ospa: Enhanc- ing identity-preserving image generation via online self- preference alignment
Xusen Ma, Xiaoqin Wang, Xianxu Hou, Meidan Ding, Zhe Kong, Junliang Chen, and Linlin Shen. Ospa: Enhanc- ing identity-preserving image generation via online self- preference alignment. 2
-
[26]
Cross-domain few-shot segmentation via iterative support-query correspon- dence mining
Jiahao Nie, Yun Xing, Gongjie Zhang, Pei Yan, Aoran Xiao, Yap-Peng Tan, Alex C Kot, and Shijian Lu. Cross-domain few-shot segmentation via iterative support-query correspon- dence mining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3380– 3390, 2024. 7, 2
work page 2024
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Self-supervision with superpixels: Training few-shot medical image segmentation without an- notation
Cheng Ouyang, Carlo Biffi, Chen Chen, Turkay Kart, Huaqi Qiu, and Daniel Rueckert. Self-supervision with superpixels: Training few-shot medical image segmentation without an- notation. InEuropean conference on computer vision, pages 762–780. Springer, 2020. 3, 6, 7, 2
work page 2020
-
[29]
Bastien Rigaud, Brian M Anderson, H Yu Zhiqian, Maxime Gobeli, Guillaume Cazoulat, Jonas S ¨oderberg, Elin Samuelsson, David Lidberg, Christopher Ward, Nicolette Taku, et al. Automatic segmentation using deep learning to enable online dose optimization during adaptive radiation therapy of cervical cancer.International Journal of Radia- tion Oncology* Biol...
work page 2021
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3
work page 2022
-
[31]
‘squeeze & ex- cite’guided few-shot segmentation of volumetric images
Abhijit Guha Roy, Shayan Siddiqui, Sebastian P ¨olsterl, Nassir Navab, and Christian Wachinger. ‘squeeze & ex- cite’guided few-shot segmentation of volumetric images. Medical image analysis, 59:101587, 2020. 3, 6
work page 2020
-
[32]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022. 2, 3
work page 2022
-
[33]
One-shot learning for semantic segmentation
Amirreza Shaban, Shray Bansal, Zhen Liu, Irfan Essa, and Byron Boots. One-shot learning for semantic segmentation. arXiv preprint arXiv:1709.03410, 2017. 2
-
[34]
Q-net: Query-informed few-shot medical image segmentation
Qianqian Shen, Yanan Li, Jiyong Jin, and Bin Liu. Q-net: Query-informed few-shot medical image segmentation. In Proceedings of SAI Intelligent Systems Conference, pages 610–628. Springer, 2023. 3, 6
work page 2023
-
[35]
Yue Shen, Wanshu Fan, Cong Wang, Wenfei Liu, Wei Wang, Qiang Zhang, and Dongsheng Zhou. Dual-guided prototype alignment network for few-shot medical image segmenta- tion.IEEE Transactions on Instrumentation and Measure- ment, 2024. 6
work page 2024
-
[36]
Michael V Sherer, Diana Lin, Sharif Elguindi, Simon Duke, Li-Tee Tan, Jon Cacicedo, Max Dahele, and Erin F Gillespie. Metrics to evaluate the performance of auto-segmentation for radiation treatment planning: A critical review.Radiother- apy and Oncology, 160:185–191, 2021. 1
work page 2021
-
[37]
Domain-rectifying adapter for cross-domain few-shot segmentation
Jiapeng Su, Qi Fan, Wenjie Pei, Guangming Lu, and Fanglin Chen. Domain-rectifying adapter for cross-domain few-shot segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24036– 24045, 2024. 7, 2
work page 2024
-
[38]
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion.Advances in Neural Information Pro- cessing Systems, 36:1363–1389, 2023. 3
work page 2023
-
[39]
Zhuotao Tian, Hengshuang Zhao, Michelle Shu, Zhicheng Yang, Ruiyu Li, and Jiaya Jia. Prior guided feature enrich- ment network for few-shot segmentation.IEEE transactions on pattern analysis and machine intelligence, 44(2):1050– 1065, 2020. 2
work page 2020
-
[40]
Panet: Few-shot image semantic seg- mentation with prototype alignment
Kaixin Wang, Jun Hao Liew, Yingtian Zou, Daquan Zhou, and Jiashi Feng. Panet: Few-shot image semantic seg- mentation with prototype alignment. Inproceedings of the IEEE/CVF international conference on computer vision, pages 9197–9206, 2019. 2, 3, 6, 7
work page 2019
-
[41]
Xiaoqin Wang, Xianxu Hou, Meidan Ding, Junliang Chen, Kaijun Deng, Jinheng Xie, and Linlin Shen. Disfacerep: Representation disentanglement for co-occurring facial com- ponents in weakly supervised face parsing. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4020–4029, 2025. 1
work page 2025
-
[42]
Xiaoqin Wang, Xusen Ma, Xianxu Hou, Meidan Ding, Yudong Li, Junliang Chen, Wenting Chen, Xiaoyang Peng, and Linlin Shen. Facebench: A multi-view multi-level fa- cial attribute vqa dataset for benchmarking face perception mllms. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9154–9164, 2025. 1
work page 2025
-
[43]
Hallee E Wong, Jose Javier Gonzalez Ortiz, John Guttag, and Adrian V Dalca. Multiverseg: scalable interactive segmen- tation of biomedical imaging datasets with in-context guid- ance. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 20966–20980, 2025. 8, 2
work page 2025
-
[44]
Huisi Wu, Fangyan Xiao, and Chongxin Liang. Dual con- trastive learning with anatomical auxiliary supervision for few-shot medical image segmentation. InEuropean Con- ference on Computer Vision, pages 417–434. Springer, 2022. 6
work page 2022
-
[45]
One-prompt to segment all med- ical images
Junde Wu and Min Xu. One-prompt to segment all med- ical images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11302– 11312, 2024. 8
work page 2024
-
[46]
Medsegdiff: Medical image segmentation with diffusion probabilistic model
Junde Wu, Rao Fu, Huihui Fang, Yu Zhang, Yehui Yang, Haoyi Xiong, Huiying Liu, and Yanwu Xu. Medsegdiff: Medical image segmentation with diffusion probabilistic model. InMedical Imaging with Deep Learning, pages 1623–1639. PMLR, 2024. 3
work page 2024
-
[47]
Medsegdiff-v2: Diffusion-based medical im- age segmentation with transformer
Junde Wu, Wei Ji, Huazhu Fu, Min Xu, Yueming Jin, and Yanwu Xu. Medsegdiff-v2: Diffusion-based medical im- age segmentation with transformer. InProceedings of the AAAI conference on artificial intelligence, pages 6030–6038,
-
[48]
Open-vocabulary panop- tic segmentation with text-to-image diffusion models
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiao- long Wang, and Shalini De Mello. Open-vocabulary panop- tic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2955–2966, 2023. 3, 5
work page 2023
-
[49]
Open-vocabulary panop- tic segmentation with text-to-image diffusion models
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiao- long Wang, and Shalini De Mello. Open-vocabulary panop- tic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2955–2966, 2023. 2, 3
work page 2023
-
[50]
Junyi Zhang, Charles Herrmann, Junhwa Hur, Luisa Pola- nia Cabrera, Varun Jampani, Deqing Sun, and Ming-Hsuan Yang. A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence.Advances in Neural Information Processing Systems, 36:45533–45547,
-
[51]
Muzhi Zhu, Yang Liu, Zekai Luo, Chenchen Jing, Hao Chen, Guangkai Xu, Xinlong Wang, and Chunhua Shen. Unleash- ing the potential of the diffusion model in few-shot semantic segmentation.Advances in Neural Information Processing Systems, 37:42672–42695, 2024. 1, 3, 4, 5, 6, 7
work page 2024
-
[52]
Few-shot medical image segmentation via a region-enhanced prototypical transformer
Yazhou Zhu, Shidong Wang, Tong Xin, and Haofeng Zhang. Few-shot medical image segmentation via a region-enhanced prototypical transformer. InInternational Conference on Medical Image Computing and Computer-Assisted Interven- tion, pages 271–280. Springer, 2023. 2, 5, 6, 7, 1
work page 2023
-
[53]
Yazhou Zhu, Shidong Wang, Tong Xin, Zheng Zhang, and Haofeng Zhang. Partition-a-medical-image: Extracting mul- tiple representative sub-regions for few-shot medical image segmentation.IEEE Transactions on Instrumentation and Measurement, 2024. 6
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.