Recognition: 2 theorem links
· Lean TheoremStoryScope: Investigating idiosyncrasies in AI fiction
Pith reviewed 2026-05-13 20:21 UTC · model grok-4.3
The pith
Narrative features alone distinguish AI fiction from human writing at 93 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
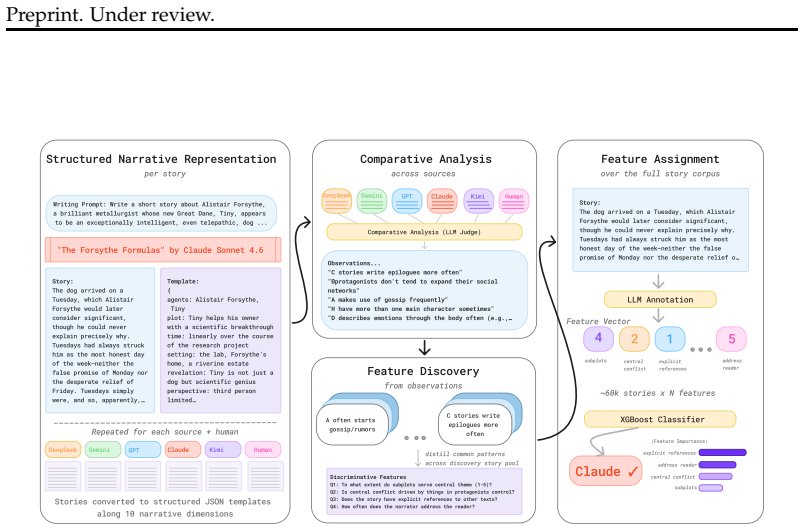
StoryScope automatically induces 304 interpretable discourse features across ten dimensions. On the parallel corpus, these features alone yield 93.2 percent macro-F1 for human-AI detection and 68.4 percent macro-F1 for six-way authorship attribution. AI stories over-explain themes, favor single-track plots, and cluster in a narrow region of narrative space, while human stories display greater diversity through morally ambiguous protagonist choices and higher chronological complexity. Individual models also show distinct fingerprints, such as flat event escalation for Claude and frequent dream sequences for GPT.
What carries the argument
StoryScope pipeline that extracts fine-grained, discourse-level narrative features such as character agency and chronological discontinuity across ten dimensions.
If this is right
- AI stories systematically over-explain themes and default to tidy single-track plots.
- Human stories frame protagonist choices with greater moral ambiguity and greater temporal complexity.
- Each AI model carries a distinct narrative fingerprint detectable without style cues.
- Human-authored stories occupy a wider, more diverse region of narrative space than AI outputs.
- A compact set of 30 core narrative features retains most of the detection and attribution signal.
Where Pith is reading between the lines
- The clustering of AI narratives suggests models converge on similar story-construction habits that could reduce long-term creative variety.
- Combining these discourse signals with existing style-based detectors would likely raise robustness against prompt-engineering attacks.
- The method could be adapted to measure originality in other long-form creative domains such as screenplays or interactive fiction.
- If narrative fingerprints prove stable across future models, they offer a content-agnostic way to track how AI writing evolves.
Load-bearing premise
The induced discourse features capture narrative choices independently of surface stylistic signals and the shared prompts sufficiently control for content so that measured differences reflect true narrative construction.
What would settle it
Apply the same 304 narrative features to a fresh collection of human and AI stories written from entirely new prompts never seen during feature induction or model training.
Figures






read the original abstract
As AI-generated fiction becomes increasingly prevalent, questions of authorship and originality are becoming central to how written work is evaluated. While most existing work in this space focuses on identifying surface-level signatures of AI writing, we ask instead whether AI-generated stories can be distinguished from human ones without relying on stylistic signals, focusing on discourse-level narrative choices such as character agency and chronological discontinuity. We propose StoryScope, a pipeline that automatically induces a fine-grained, interpretable feature space of discourse-level narrative features across 10 dimensions. We apply StoryScope to a parallel corpus of 10,272 writing prompts, each written by a human author and five LLMs, yielding 61,608 stories, each ~5,000 words, and 304 extracted features per story. Narrative features alone achieve 93.2% macro-F1 for human vs. AI detection and 68.4% macro-F1 for six-way authorship attribution, retaining over 97% of the performance of models that include stylistic cues. A compact set of 30 core narrative features captures much of this signal: AI stories over-explain themes and favor tidy, single-track plots while human stories frame protagonist' choices as more morally ambiguous and have increased temporal complexity. Per-model fingerprint features enable six-way attribution: for example, Claude produces notably flat event escalation, GPT over-indexes on dream sequences, and Gemini defaults to external character description. We find that AI-generated stories cluster in a shared region of narrative space, while human-authored stories exhibit greater diversity. More broadly, these results suggest that differences in underlying narrative construction, not just writing style, can be used to separate human-written original works from AI-generated fiction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
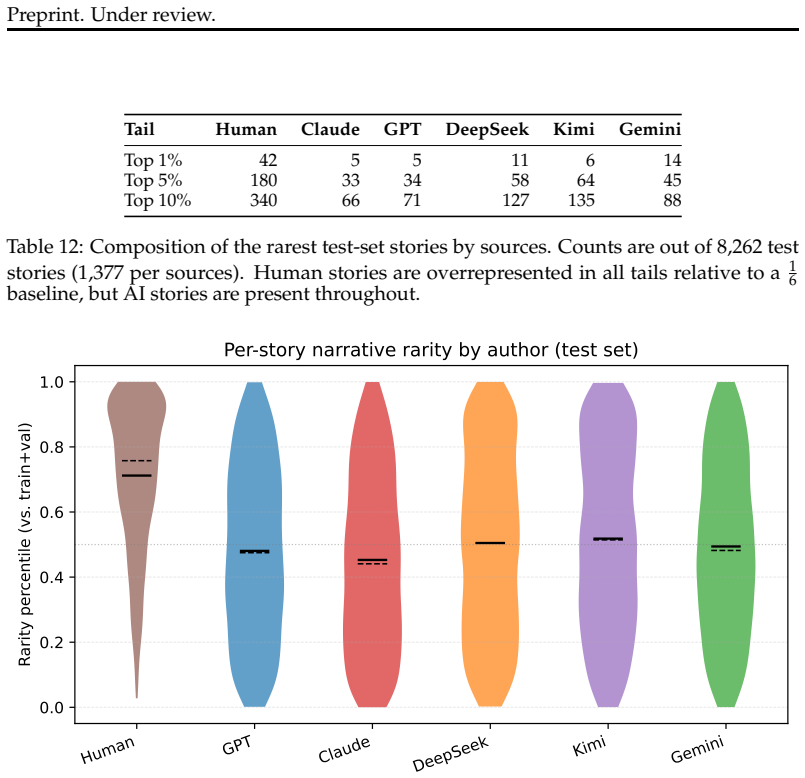
Summary. The paper presents StoryScope, a pipeline that automatically induces a set of 304 interpretable discourse-level narrative features across 10 dimensions from fiction stories. Applied to a parallel corpus of 10,272 prompts each completed by a human author and five different LLMs (yielding 61,608 stories of ~5,000 words each), the work demonstrates that these narrative features alone can achieve 93.2% macro-F1 score in human vs. AI detection and 68.4% macro-F1 in six-way authorship attribution. These results retain over 97% of the performance obtained when including stylistic cues. The paper further identifies specific narrative idiosyncrasies, such as AI stories tending to over-explain themes and use tidy single-track plots, while human stories exhibit more moral ambiguity in protagonist choices and greater temporal complexity. AI-generated stories are shown to cluster in a shared region of narrative space, contrasting with the greater diversity in human-authored stories.
Significance. If the results hold after addressing validation concerns, this work is significant as it shifts focus from surface stylistic markers to deeper narrative construction differences in distinguishing AI-generated fiction. Key strengths include the creation of a large parallel corpus that controls for prompt content, the development of an interpretable feature space with per-model fingerprints (e.g., Claude's flat event escalation, GPT's over-indexing on dream sequences), and the identification of a compact 30-feature subset that captures much of the signal. This provides both practical tools for detection and theoretical insights into how AI systems construct narratives differently from humans, advancing the field beyond black-box classifiers.
major comments (3)
- [Results on detection performance] Results on detection performance: The reported 93.2% macro-F1 for narrative features alone in human vs. AI detection lacks accompanying ablation studies or mutual information analysis to confirm that the 304 features (and the 30 core subset) are independent of stylistic signals captured by the automatic extraction pipeline. This is critical because the 97% retention of full-model performance could partly result from leakage via parsers or coreference tools sensitive to surface phrasing.
- [Feature induction pipeline] Feature induction pipeline: The parallel corpus design controls for topic via shared prompts but does not address how the same plot points are realized differently (e.g., explicit vs. implicit agency). Without reported controls or examples in the pipeline description, it remains unclear whether the features truly isolate narrative choices independent of style.
- [Core feature selection] Core feature selection: The selection of the compact set of 30 core narrative features is not detailed with respect to validation procedures or avoidance of post-hoc selection bias, which could inflate the reported performance metrics.
minor comments (2)
- [Abstract] Typo: 'protagonist'' should be 'protagonists'' in the sentence describing human stories.
- [Abstract] The 10 dimensions of narrative features are mentioned but not listed explicitly; including a brief enumeration would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and rigor of our work. We address each of the major comments point by point below, indicating the revisions made to the manuscript.
read point-by-point responses
-
Referee: Results on detection performance: The reported 93.2% macro-F1 for narrative features alone in human vs. AI detection lacks accompanying ablation studies or mutual information analysis to confirm that the 304 features (and the 30 core subset) are independent of stylistic signals captured by the automatic extraction pipeline. This is critical because the 97% retention of full-model performance could partly result from leakage via parsers or coreference tools sensitive to surface phrasing.
Authors: We agree that demonstrating independence from stylistic signals is essential for the validity of our claims. Although the pipeline prioritizes discourse-level annotations (e.g., temporal relations and agency markers derived from syntactic structure), we acknowledge the potential for indirect leakage. In the revised version, we have incorporated ablation experiments that isolate narrative features by masking stylistic elements and report mutual information scores between feature categories. These additions show that narrative features contribute the majority of the discriminative power, supporting our original findings while addressing the concern directly. revision: yes
-
Referee: Feature induction pipeline: The parallel corpus design controls for topic via shared prompts but does not address how the same plot points are realized differently (e.g., explicit vs. implicit agency). Without reported controls or examples in the pipeline description, it remains unclear whether the features truly isolate narrative choices independent of style.
Authors: The referee correctly notes that topic control alone does not fully isolate narrative choices. Our features target specific discourse phenomena, such as the explicitness of agency through coreference patterns and event sequencing. We have now included concrete examples in the methods section illustrating feature extraction for equivalent plot points realized with varying agency and temporality. While perfect isolation from all stylistic influences is inherently difficult, the parallel corpus and feature definitions provide substantial controls, and we have clarified this in the updated manuscript. revision: partial
-
Referee: Core feature selection: The selection of the compact set of 30 core narrative features is not detailed with respect to validation procedures or avoidance of post-hoc selection bias, which could inflate the reported performance metrics.
Authors: We thank the referee for pointing out the need for greater transparency in feature selection. The 30 features were chosen via recursive feature elimination with cross-validation on a separate validation partition to prevent overfitting to the test data. We have expanded the relevant section to detail the exact procedure, including the number of folds, performance stability across subsets, and confirmation that selection was performed prior to final evaluation. This mitigates concerns of post-hoc bias. revision: yes
Circularity Check
No circularity: empirical feature extraction and supervised classification
full rationale
The paper describes an automatic pipeline that induces 304 discourse-level narrative features from a parallel corpus of 61,608 stories and then trains standard supervised classifiers to report macro-F1 scores on held-out data. No equations, derivations, or first-principles predictions are present that reduce any claimed result to its own inputs by construction. Feature induction is presented as a data-driven process rather than a self-referential definition, and no load-bearing self-citations or uniqueness theorems are invoked. The performance numbers are ordinary empirical outcomes of training and evaluation, not statistical artifacts forced by the method itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- Core feature count
axioms (2)
- domain assumption Discourse-level narrative features can be induced automatically from raw text
- domain assumption Parallel prompts control for content sufficiently to isolate narrative differences
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Narrative features alone achieve 93.2% macro-F1 for human vs. AI detection... focusing on discourse-level narrative choices such as character agency and chronological discontinuity.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose STORYSCOPE, a pipeline that automatically induces a fine-grained, interpretable feature space of discourse-level narrative features across 10 dimensions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://www.nature.com/articles/ s41599-024-03868-8
doi: 10.1057/s41599-024-03868-8. URL https://www.nature.com/articles/ s41599-024-03868-8. Margaret A. Boden.The Creative Mind: Myths and Mechanisms. Routledge, 2 edition, 2004. Book Industry Study Group. Bisac subject headings list. https://www.bisg.org/ complete-bisac-subject-headings-list , 2024. Industry standard for categorizing books by subject; acce...
-
[2]
Giorgio Franceschelli and Mirco Musolesi
URLhttps://arxiv.org/abs/2402.14873. Giorgio Franceschelli and Mirco Musolesi. On the creativity of large language models.arXiv preprint arXiv:2304.00008, 2023. URLhttps://arxiv.org/abs/2304.00008. Gemini Team. Gemini: A family of highly capable multimodal models, 2023. URL https: //arxiv.org/abs/2312.11805. Gemini Team. Gemini 2.5: Pushing the frontier w...
-
[3]
Andrea Cristina McGlinchey and Peter J
doi: 10.1038/s42256-019-0138-9. Andrea Cristina McGlinchey and Peter J. Barclay. Using machine learning to distinguish human-written from machine-generated creative fiction, 2024. URL https://arxiv.org/ abs/2412.15253. Hope McGovern, Rickard Stureborg, Yoshi Suhara, and Dimitris Alikaniotis. Your large language models are leaving fingerprints. In Firoj Al...
-
[4]
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer
URLhttps://arxiv.org/abs/2312.06281. Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. TopicGPT: A prompt-based topic modeling framework. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo...
-
[5]
Association for Computational Linguistics. doi: 10.18653/v1/2024.wnu-1.4. URL https://aclanthology.org/2024.wnu-1.4/. Shawn Presser. Books3, 2020. URL https://twitter.com/theshawwn/status/ 1320282149329784833. Alex Reinhart, Ben Markey, Michael Laudenbach, Kachatad Pantusen, Ronald Yurko, Gor- don Weinberg, and David West Brown. Do LLMs write like humans?...
-
[6]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
U.S. Supreme Court. Manya Wadhwa, Tiasa Singha Roy, Harvey Lederman, Junyi Jessy Li, and Greg Durrett. Create: Testing llms for associative creativity, 2026. URL https://arxiv.org/abs/2603. 09970. Zihan Wang, Jingbo Shang, and Ruiqi Zhong. Goal-driven explainable clustering via language descriptions. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Pro...
-
[7]
Stylometric baseline.We extract 144 surface features from each story, including sentence-, word-, and paragraph-length statistics, document-level counts, vocabu- lary richness metrics, 100 function-word frequencies, punctuation rates, dialogue features, and readability indices
-
[8]
TF-IDF baseline.We fit a unigram/bigram TF-IDF vectorizer. The resulting matrix is passed through the same XGBoost sweep and train/val/test protocol as the stylometric baseline
-
[9]
ModernBERT baseline.We fine-tune ModernBERT-base (Warner et al., 2025) directly on raw story text using the same train/val/test split
work page 2025
-
[10]
Binoculars.We run Binoculars in accuracy mode with all other settings left at their defaults. Feature encoding.For the binary task we set XGBoost’s scale_pos_weight= 5 to match the 5:1 AI-to-human class ratio. Multiclass uses uniform class weights. Features are encoded with one-hot columns for nominal and binary types and explicit integer encoding for ord...
work page 2020
- [11]
-
[12]
Continue the sentence with **"where...", "about...", "following...", or "from the perspective of..."** and then introduce at least one key character or setting by name. This keeps the opening grammatically smooth. - If a first-person narrator is unnamed, refer to them as "the narrator" without inventing a new name. Otherwise, provide their name explicitly
-
[13]
Conveys the story's distinctive **essence / theme / style**, giving the writer a clear sense of mood and direction, and includes **some concrete details** (character, location, object, striking event) as needed - don't overload with minutiae
-
[14]
Offers enough narrative guidance to get the writer started (situation + conflict or question to explore) yet leaves room for their own twists
- [15]
-
[16]
Refer to the concrete names / details directly
Avoid vague hedge words (*maybe*, *perhaps*, *consider*) **and** absolutely do NOT use comparison phrases or qualifiers such as *like*, *much like*, *similar to*, *reminiscent of*, *in the style of*. Refer to the concrete names / details directly. Do not invent character names that do not appear
-
[17]
Single paragraph <= 120 words. Return ONLY the prompt text--**no extra commentary**. If anything else is included, keep it on the same line separated by a single space. STORY TO ANALYSE: batch_text Figure 6: Prompt used to generate benchmark writing prompts from source stories We do not use a single writing template; each story is generated from a standal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.