Recognition: 1 theorem link
· Lean TheoremFSUNav: A Cerebrum-Cerebellum Architecture for Fast, Safe, and Universal Zero-Shot Goal-Oriented Navigation
Pith reviewed 2026-05-13 18:55 UTC · model grok-4.3
The pith
FSUNav splits navigation into a VLM-based reasoning module and an RL-based control module to enable zero-shot goal navigation that works on any robot type.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
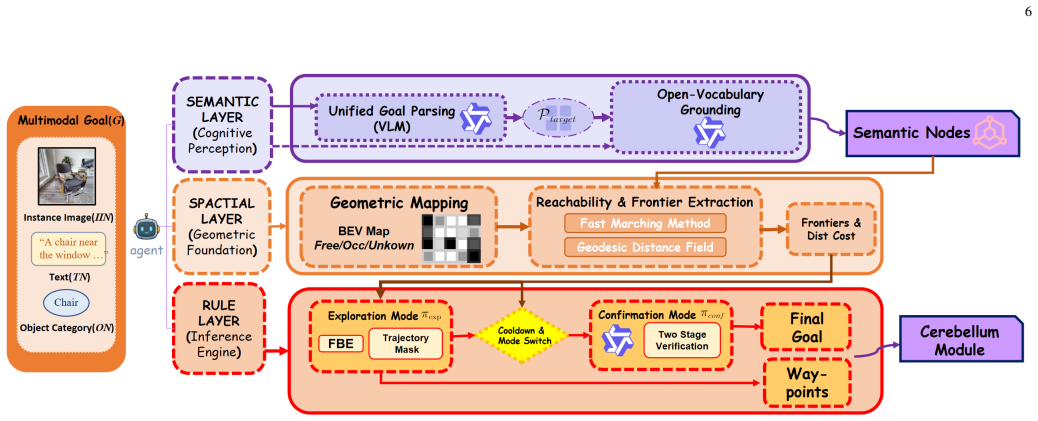
FSUNav builds a Cerebrum-Cerebellum architecture in which the cerebellum module runs a high-frequency end-to-end universal local planner trained with deep reinforcement learning to produce collision-free motion on any platform, while the cerebrum module uses a three-layer VLM reasoning stack to detect targets and verify progress, thereby supporting zero-shot open-vocabulary navigation from multimodal inputs without predefined object IDs.
What carries the argument
The Cerebrum-Cerebellum architecture: the cerebellum provides a universal RL local planner that operates at high frequency for safety and efficiency across platforms, while the cerebrum supplies a three-layer VLM model for end-to-end detection, reasoning, and verification that enables open-vocabulary zero-shot goal following.
If this is right
- Navigation code becomes platform-agnostic, so the same trained weights run on humanoid, quadruped, and wheeled robots.
- Open-vocabulary goals can be given without pre-registering object IDs or retraining the system.
- Multimodal commands (text, target images, or natural-language descriptions) are handled inside the same pipeline.
- State-of-the-art success rates are reported on MP3D, HM3D, and OVON benchmarks for object, instance-image, and task navigation.
- Real-world trials on diverse robots show reduced collisions and maintained speed.
Where Pith is reading between the lines
- A single navigation stack could replace the current practice of writing separate planners for each robot chassis in a mixed fleet.
- If the local planner generalizes further, the same safety layer might be reused for manipulation or mobile manipulation tasks.
- Deployment time in new buildings could drop to the time needed to describe the goal in language rather than the time needed to collect robot-specific data.
- Safety certification might become easier if the high-frequency collision-avoidance module can be tested and bounded independently of the language module.
Load-bearing premise
That adding vision-language models to the reinforcement-learning planner will keep real-time speed and safety on every robot without extra calibration and that zero-shot performance will hold in real environments never seen during training.
What would settle it
A test in which the system is placed on an untested robot platform or in a new building and either collides repeatedly, exceeds real-time latency limits, or fails to reach a goal specified only by a fresh image or description.
Figures



read the original abstract
Current vision-language navigation methods face substantial bottlenecks regarding heterogeneous robot compatibility, real-time performance, and navigation safety. Furthermore, they struggle to support open-vocabulary semantic generalization and multimodal task inputs. To address these challenges, this paper proposes FSUNav: a Cerebrum-Cerebellum architecture for fast, safe, and universal zero-shot goal-oriented navigation, which innovatively integrates vision-language models (VLMs) with the proposed architecture. The cerebellum module, a high-frequency end-to-end module, develops a universal local planner based on deep reinforcement learning, enabling unified navigation across heterogeneous platforms (e.g., humanoid, quadruped, wheeled robots) to improve navigation efficiency while significantly reducing collision risk. The cerebrum module constructs a three-layer reasoning model and leverages VLMs to build an end-to-end detection and verification mechanism, enabling zero-shot open-vocabulary goal navigation without predefined IDs and improving task success rates in both simulation and real-world environments. Additionally, the framework supports multimodal inputs (e.g., text, target descriptions, and images), further enhancing generalization, real-time performance, safety, and robustness. Experimental results on MP3D, HM3D, and OVON benchmarks demonstrate that FSUNav achieves state-of-the-art performance on object, instance image, and task navigation, significantly outperforming existing methods. Real-world deployments on diverse robotic platforms further validate its robustness and practical applicability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FSUNav, a Cerebrum-Cerebellum architecture that integrates vision-language models (VLMs) with a deep reinforcement learning local planner. The cerebellum module is presented as a high-frequency end-to-end universal planner for heterogeneous platforms (humanoid, quadruped, wheeled robots) to improve efficiency and reduce collisions. The cerebrum module uses VLMs in a three-layer reasoning model for zero-shot open-vocabulary detection/verification and supports multimodal inputs (text, descriptions, images). Experiments on MP3D, HM3D, and OVON benchmarks are reported to achieve state-of-the-art performance on object, instance image, and task navigation, with additional real-world validation across robotic platforms.
Significance. If the claimed real-time performance and safety properties hold under the VLM integration, the work would offer a practical modular approach to combining semantic reasoning with low-level control, potentially improving zero-shot generalization and cross-platform compatibility in vision-language navigation.
major comments (2)
- The central claim of high-frequency safe operation for the cerebellum planner is load-bearing for the SOTA results and real-world applicability, yet the manuscript provides no quantitative measurements of control-loop rate, VLM invocation frequency, caching, or synchronization between cerebrum and cerebellum modules. This omission directly affects the ability to verify that VLM calls do not violate the real-time and safety guarantees asserted in the abstract.
- The experimental claims of significantly outperforming existing methods on MP3D, HM3D, and OVON lack any reported details on baselines, exact metrics (success rate, SPL, etc.), number of episodes, or statistical tests, making it impossible to assess whether the data support the outperformance statements.
minor comments (2)
- Define all acronyms (MP3D, HM3D, OVON, VLM) on first use in the main text.
- Add a diagram or pseudocode clarifying the three-layer reasoning model and the interface between cerebrum and cerebellum.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate the requested details into the revised version to strengthen the presentation of our results.
read point-by-point responses
-
Referee: The central claim of high-frequency safe operation for the cerebellum planner is load-bearing for the SOTA results and real-world applicability, yet the manuscript provides no quantitative measurements of control-loop rate, VLM invocation frequency, caching, or synchronization between cerebrum and cerebellum modules. This omission directly affects the ability to verify that VLM calls do not violate the real-time and safety guarantees asserted in the abstract.
Authors: We agree that explicit quantitative measurements are necessary to fully substantiate the real-time and safety claims. The current manuscript describes the cerebellum as a high-frequency DRL-based planner and the cerebrum-cerebellum separation for latency management but does not report numerical values. In the revision we will add measured control-loop rates (typically 50-100 Hz across platforms), average VLM invocation frequency with the caching mechanism employed to reduce calls, and the synchronization protocol (including buffering and priority queuing) that ensures VLM latency does not interrupt the low-level control loop. revision: yes
-
Referee: The experimental claims of significantly outperforming existing methods on MP3D, HM3D, and OVON lack any reported details on baselines, exact metrics (success rate, SPL, etc.), number of episodes, or statistical tests, making it impossible to assess whether the data support the outperformance statements.
Authors: We acknowledge that the experimental section would benefit from greater transparency. While the manuscript states SOTA results on the three benchmarks, it does not enumerate the precise baselines, metric values, episode counts, or statistical analysis. In the revised manuscript we will include a detailed table listing all compared methods, exact success rate, SPL, and additional metrics, the number of episodes per task (500+), and statistical significance tests (e.g., paired t-tests with p-values) to support the reported improvements. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmark experiments
full rationale
The paper describes an architectural integration of VLMs for zero-shot reasoning and an end-to-end RL local planner for control, then reports SOTA results on MP3D, HM3D, and OVON benchmarks. No equations, fitted parameters presented as predictions, uniqueness theorems, or self-citations appear in the provided text that would reduce any central claim to its own inputs by construction. The performance assertions are tied to independent experimental validation rather than self-referential definitions or ansatzes smuggled via prior work. This is the standard non-circular outcome for an empirical systems paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The cerebellum module, a high-frequency end-to-end module, develops a universal local planner based on deep reinforcement learning... The cerebrum module constructs a three-layer reasoning model and leverages VLMs to build an end-to-end detection and verification mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. D. Reid, S. Gould, and A. van den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,”2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3674–3683, 2017. [Online]. Available: https://api.semanticsc...
work page 2018
-
[2]
Vision-and- language navigation: A survey of tasks, methods, and future directions,
J. Gu, E. Stefani, Q. Wu, J. Thomason, and X. E. Wang, “Vision-and- language navigation: A survey of tasks, methods, and future directions,” inAnnual Meeting of the Association for Computational Linguistics,
-
[3]
[Online]. Available: https://api.semanticscholar.org/CorpusID: 247627890 8 Fig. 4: Under a maximum locomotion speed of 0.6 m/s, the quadruped robot successfully completed the open-vocabulary object goal navigation task targeting “umbrella.” During the experiment, the robot not only demonstrated efficient mobility but also exhibited real-time dynamic obsta...
-
[4]
The dynamic window approach to collision avoidance,
D. Fox, W. Burgard, and S. Thrun, “The dynamic window approach to collision avoidance,”IEEE Robotics & Automation Magazine, vol. 4, no. 1, pp. 23–33, 1997
work page 1997
-
[5]
Trajectory modification considering dynamic constraints of autonomous robots,
C. Roesmann, W. Feiten, T. Woesch, F. Hoffmann, and T. Bertram, “Trajectory modification considering dynamic constraints of autonomous robots,” inROBOTIK 2012; 7th German Conference on Robotics, 2012, pp. 1–6
work page 2012
-
[6]
Soat: A scene- and object-aware transformer for vision-and-language navigation,
A. Moudgil, A. Majumdar, H. Agrawal, S. Lee, and D. Batra, “Soat: A scene- and object-aware transformer for vision-and-language navigation,” inNeural Information Processing Systems, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:239998205
work page 2021
-
[7]
Vln⟳bert: A recurrent vision-and-language bert for navigation,
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould, “Vln⟳bert: A recurrent vision-and-language bert for navigation,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1643–1653, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:227228335
work page 2021
-
[8]
Beyond the nav-graph: Vision-and-language navigation in continuous environments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” inEuropean Conference on Computer Vision, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:214802389
work page 2020
-
[9]
Zson: Zero-shot object-goal navigation using multimodal goal embed- dings,
A. Majumdar, G. Aggarwal, B. Devnani, J. Hoffman, and D. Batra, “Zson: Zero-shot object-goal navigation using multimodal goal embed- dings,”ArXiv, vol. abs/2206.12403, 2022
-
[10]
Procthor: Large- scale embodied ai using procedural generation,
M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, K. Ehsani, J. Salvador, W. Han, E. Kolve, A. Kembhavi, and R. Mottaghi, “Procthor: Large- scale embodied ai using procedural generation,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. ...
work page 2022
-
[11]
Object goal navigation using goal-oriented semantic exploration,
D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,”Advances in Neural Information Processing Systems, vol. 33, pp. 4247–4258, 2020
work page 2020
-
[12]
Esc: Exploration with soft commonsense constraints for zero-shot object navigation,
K.-Q. Zhou, K. Zheng, C. Pryor, Y . Shen, H. Jin, L. Getoor, and X. E. Wang, “Esc: Exploration with soft commonsense constraints for zero-shot object navigation,” inInternational Conference on Machine Learning, 2023
work page 2023
-
[13]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,”Advances in neural information processing systems, vol. 37, pp. 5285–5307, 2024
work page 2024
-
[14]
Instance- specific image goal navigation: Training embodied agents to find object instances,
J. Krantz, S. Lee, J. Malik, D. Batra, and D. S. Chaplot, “Instance- specific image goal navigation: Training embodied agents to find object instances,”arXiv preprint arXiv:2211.15876, 2022
-
[15]
Matterport3d: Learning from rgb-d data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”International Conference on 3D Vision (3DV), 2017
work page 2017
-
[16]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, M. Savva, Y . Zhao, and D. Batra, “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,”ArXiv, vol. abs/2109.08238, 2021
work page internal anchor Pith review arXiv 2021
-
[17]
Prioritized semantic learning for zero-shot instance navigation,
X. Sun, L. Lau, H. Zhi, R. Qiu, and J. Liang, “Prioritized semantic learning for zero-shot instance navigation,”ArXiv, vol. abs/2403.11650, 2024
-
[18]
Neural topological slam for visual navigation,
D. S. Chaplot, R. Salakhutdinov, A. K. Gupta, and S. Gupta, “Neural topological slam for visual navigation,”2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12 872–12 881,
work page 2020
-
[19]
Available: https://api.semanticscholar.org/CorpusID: 214754592
[Online]. Available: https://api.semanticscholar.org/CorpusID: 214754592
-
[20]
Unigoal: Towards universal zero-shot goal-oriented navigation,
H. Yin, X. Xu, L. Zhao, Z. Wang, J. Zhou, and J. Lu, “Unigoal: Towards universal zero-shot goal-oriented navigation,”2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19 057–19 066, 2025
work page 2025
-
[21]
Vlfm: Vision- language frontier maps for zero-shot semantic navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “Vlfm: Vision- language frontier maps for zero-shot semantic navigation,”2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 42– 48, 2023
work page 2024
-
[22]
Wmnav: Integrating vision-language models into world models for object goal navigation,
D. Nie, X. Guo, Y . Duan, R. Zhang, and L. Chen, “Wmnav: Integrating vision-language models into world models for object goal navigation,” ArXiv, vol. abs/2503.02247, 2025
-
[23]
W. Zhang, S. Wang, M. Tan, Z. Yang, X. Wang, and X. Shen, “Drl- dclp: A deep reinforcement learning-based dimension-configurable local planner for robot navigation,”IEEE Robotics and Automation Letters, vol. 10, no. 4, pp. 3636–3643, 2025
work page 2025
-
[24]
M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y . Min, K. Shah, C. Paxton, S. Gupta, D. Batra, R. Mottaghi, J. Malik, and D. S. Chaplot, “Goat: Go to any thing,”ArXiv, vol. abs/2311.06430, 2023
-
[25]
Learning on the go: A meta-learning object navigation model,
X. Qin, X. Song, S. Zhang, X. Yu, X. Zhang, and S. Jiang, “Learning on the go: A meta-learning object navigation model,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 8939–8949
work page 2025
-
[26]
Openfmnav: Towards open-set zero- shot object navigation via vision-language foundation models,
Y . Kuang, H. Lin, and M. Jiang, “Openfmnav: Towards open-set zero- shot object navigation via vision-language foundation models,”ArXiv, vol. abs/2402.10670, 2024. 9
-
[27]
Cognav: Cognitive process modeling for object goal navigation with llms,
Y . Cao, J. Zhang, Z. Yu, S. Liu, Z. Qin, Q. Zou, B. Du, and K. Xu, “Cognav: Cognitive process modeling for object goal navigation with llms,”ArXiv, vol. abs/2412.10439, 2024
-
[28]
Rest: Receding horizon explorative steiner tree for zero-shot object-goal navigation,
S. Xiao, M. Ghaffari, C. Xu, and H. Kong, “Rest: Receding horizon explorative steiner tree for zero-shot object-goal navigation,”
-
[29]
Available: https://api.semanticscholar.org/CorpusID: 286673854
[Online]. Available: https://api.semanticscholar.org/CorpusID: 286673854
-
[30]
Instance-aware exploration-verification-exploitation for instance imagegoal navigation,
X. L. Lei, M. Wang, W. gang Zhou, L. Li, and H. Li, “Instance-aware exploration-verification-exploitation for instance imagegoal navigation,” 2024 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pp. 16 329–16 339, 2024
work page 2024
-
[31]
Z. Zhu, X. Wang, Y . Li, Z. Zhang, X. Ma, Y . Chen, B. Jia, W. Liang, Q. Yu, Z. Deng, S. Huang, and Q. Li, “Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation,”ArXiv, vol. abs/2507.04047, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:280150952
-
[32]
Visor: Visual spatial object reasoning for language- driven object navigation,
F. Taioli, S. Yang, S. Raychaudhuri, M. Cristani, U. Jain, and A. X. Chang, “Visor: Visual spatial object reasoning for language- driven object navigation,”ArXiv, vol. abs/2602.07555, 2026. [Online]. Available: https://api.semanticscholar.org/CorpusID:285452034
-
[33]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A platform for embodied ai research,”2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9338–9346, 2019
work page 2019
-
[34]
S. Bai, Y . Cai, R. Chenet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.