Recognition: 1 theorem link
· Lean TheoremHigh-Precision Phase-Shift Transferable Neural Networks for High-Frequency Function Approximation and PDE Solution
Pith reviewed 2026-05-13 18:31 UTC · model grok-4.3
The pith
Phase-shift transferable neural networks achieve high-precision results for high-frequency function approximation and PDE solving by transferring learned phase shifts across frequency regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that phase-shift transferable neural networks, built by embedding transferable phase-shift parameters into the network architecture, deliver high-precision approximations for high-frequency target functions and PDE solutions, where conventional networks suffer from spectral bias and require prohibitive resolution or training effort.
What carries the argument
The phase-shift transferable mechanism, which learns frequency-dependent phase offsets from one regime and reuses them on new high-frequency inputs or PDEs to compensate for the network's natural bias toward low frequencies.
If this is right
- High-frequency oscillatory PDEs become solvable to engineering accuracy with a single trained model rather than frequency-specific retraining.
- Function approximation tasks in signal processing or acoustics gain orders-of-magnitude lower error at the same network size.
- Transfer of phase information reduces the data and compute needed when moving from one high-frequency regime to another.
- The approach extends naturally to time-dependent wave problems by carrying phase shifts across time steps.
Where Pith is reading between the lines
- If the transfer succeeds across PDE families, a single library of phase-shift modules could serve as a plug-in accelerator for many linear wave equations.
- Pairing the method with domain decomposition might allow scaling to very large spatial domains without retraining the entire network.
- Empirical checks on real sensor data from vibrating structures would test whether the synthetic high-frequency gains survive measurement noise.
Load-bearing premise
Phase shifts learned or transferred from one frequency regime will generalize effectively to arbitrary high frequencies and different PDE problems without significant accuracy loss.
What would settle it
Train the network on a low-frequency version of a wave equation, transfer the learned phases, then solve the same equation at ten times higher frequency and measure whether the L2 error stays below 10^-4 relative to an exact reference solution.
Figures





read the original abstract
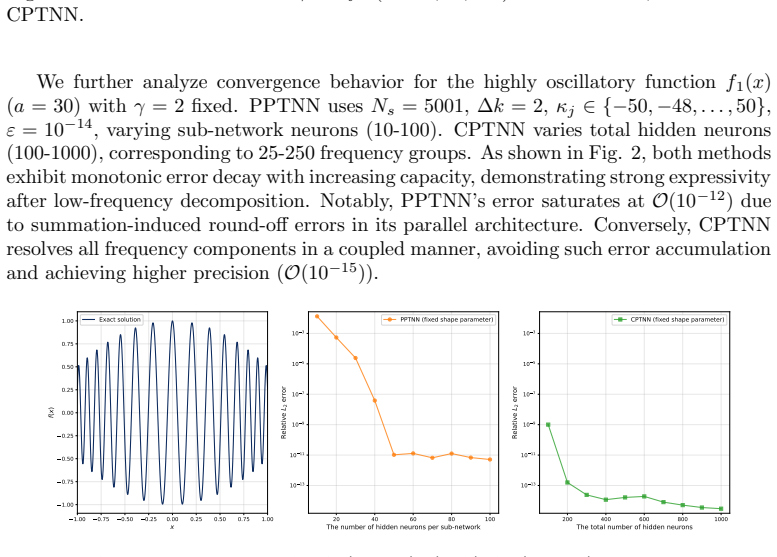
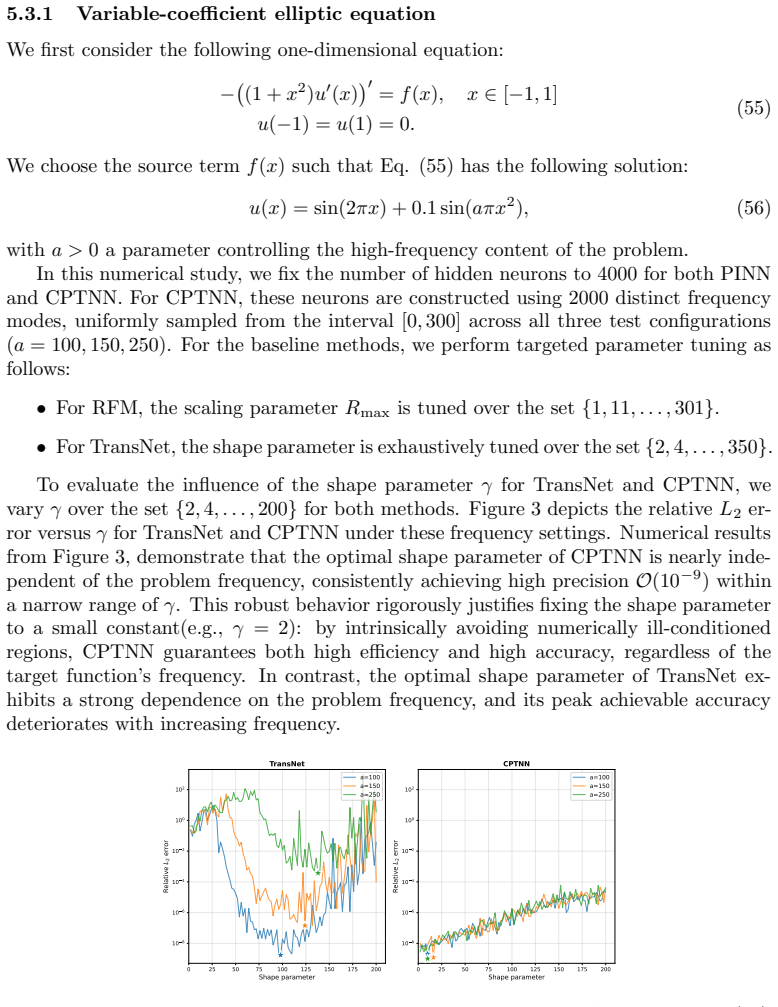
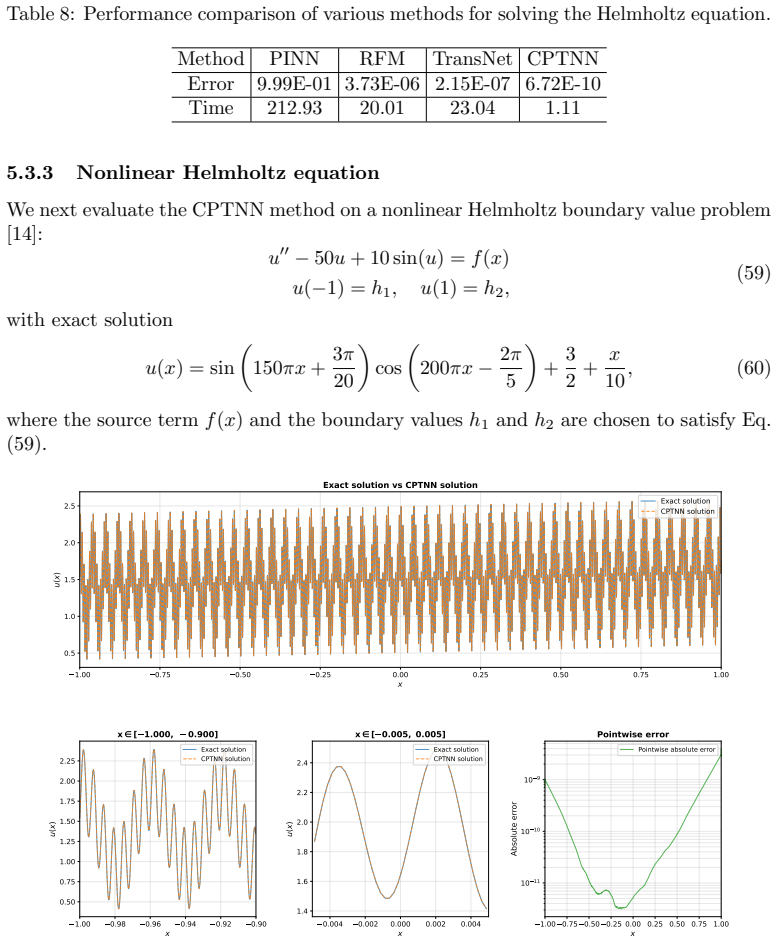
Neural network based methods have emerged as a promising paradigm for scientific computing, yet they face critical bottlenecks in high frequency function approximation and partial differential equation (PDE) solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces phase-shift transferable neural networks (PSTNNs) that extract or learn phase information from lower-frequency regimes and transfer it to enable high-precision approximation of high-frequency functions and solutions to high-frequency PDEs, addressing spectral bias in standard neural network approaches for scientific computing.
Significance. If the transfer mechanism proves robust, the work could provide a practical route to frequency-independent accuracy in neural PDE solvers and function approximators, with potential impact on applications such as wave propagation and high-frequency scattering; the emphasis on transferability rather than retraining from scratch is a notable strength if supported by systematic evidence.
major comments (2)
- [§3.2] §3.2, Eq. (7): the phase-shift transfer operator is defined via a simple additive shift in the argument of the activation; this construction does not automatically guarantee that the same shift remains optimal for arbitrary unseen frequencies or for PDEs with variable coefficients, yet the paper presents no a-priori error estimate showing how the approximation error scales with frequency mismatch.
- [§5.3] §5.3, Table 4: reported L² errors remain below 10^{-5} only for the specific 1-D linear test problems shown; the cross-PDE transfer experiments are limited to two canonical cases and do not include nonlinear or multi-dimensional problems, leaving the central claim of broad transferability without load-bearing validation.
minor comments (2)
- [§2] Notation for the phase-shift parameter is introduced inconsistently between §2 and §4; a single unified definition would improve readability.
- [Figure 3] Figure 3 caption does not specify the exact frequency values used in the transfer test; adding this information would allow readers to assess the range of generalization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript on phase-shift transferable neural networks. Below we provide point-by-point responses to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: §3.2, Eq. (7): the phase-shift transfer operator is defined via a simple additive shift in the argument of the activation; this construction does not automatically guarantee that the same shift remains optimal for arbitrary unseen frequencies or for PDEs with variable coefficients, yet the paper presents no a-priori error estimate showing how the approximation error scales with frequency mismatch.
Authors: We agree that the simple additive phase shift does not come with an automatic guarantee of optimality for arbitrary frequencies or variable-coefficient PDEs, and that a general a-priori error estimate is absent from the manuscript. The construction is motivated by the observation that phase information learned at lower frequencies can be transferred, as demonstrated numerically. In the revision we will add a paragraph in §3.2 discussing the assumptions under which the transfer is expected to perform well and explicitly noting the lack of a frequency-mismatch error bound as a limitation for future work. revision: partial
-
Referee: §5.3, Table 4: reported L² errors remain below 10^{-5} only for the specific 1-D linear test problems shown; the cross-PDE transfer experiments are limited to two canonical cases and do not include nonlinear or multi-dimensional problems, leaving the central claim of broad transferability without load-bearing validation.
Authors: The numerical studies in §5.3 were designed to demonstrate the transfer mechanism on well-controlled 1D linear problems where reference solutions are readily available. We recognize that this leaves the broader applicability to nonlinear and multi-dimensional settings insufficiently validated. We will expand the experiments to include a 2D Helmholtz equation and a nonlinear Burgers' equation example, reporting the corresponding L² errors to provide additional support for the transferability claim. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces phase-shift transferable neural networks for high-frequency approximation and PDEs. Its core architecture and transfer mechanism are defined independently via explicit network layers and training procedures that do not reduce to self-definition of outputs from inputs, fitted parameters renamed as predictions, or load-bearing self-citations. No uniqueness theorems or ansatzes are smuggled via prior self-work; the claims rest on empirical validation and architectural choices that remain falsifiable against external benchmarks. The derivation chain is self-contained without tautological reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPhaseTNN integrates phase-shift frequency decomposition with TransNet’s efficient least-squares training... γm = 2 throughout this work
Reference graph
Works this paper leans on
-
[1]
Ainsworth, M., Dong, J. Galerkin neural network approximation of singularly- perturbed elliptic systems.Computer Methods in Applied Mechanics and Engi- neering, 2022, 402: 115169. 29
work page 2022
-
[2]
Baldi, P., Hornik, K. Neural networks and principal component analysis: learning from examples without local minima.Neural Networks, 1989, 2(1): 53–58
work page 1989
-
[3]
Optimization methods for large-scale machine learning.SIAM Review, 2018, 60(2): 223–311
Bottou, L., Curtis, F.E., Nocedal, J. Optimization methods for large-scale machine learning.SIAM Review, 2018, 60(2): 223–311
work page 2018
-
[4]
Brown, T., et al. Language models are few-shot learners.Advances in Neural In- formation Processing Systems, 2020, 33: 1877–1901
work page 2020
-
[5]
A statistical approach to machine translation.Computational Linguistics, 1990, 16(2): 79–85
Brown, P.F., et al. A statistical approach to machine translation.Computational Linguistics, 1990, 16(2): 79–85
work page 1990
-
[6]
Cai, W., Li, X., Liu, L. A phase shift deep neural network for high frequency approximation and wave problems.SIAM Journal on Scientific Computing, 2020, 42(5): A3285–A3312
work page 2020
-
[7]
Chen, J., Chi, X., E, W., Yang, Z. Bridging traditional and machine learning-based algorithms for solving PDEs: the random feature method.Journal of Machine Learning, 2022, 1(3): 268–298
work page 2022
-
[8]
Chen, J.-R., E, W., Luo, Y.-X. The random feature method for time-dependent problems.East Asian Journal on Applied Mathematics, 2023, 13(3): 435–463
work page 2023
-
[9]
Chiu, P.-H., et al. CAN-PINN: a fast physics-informed neural network based on coupled automatic–numerical differentiation method.Computer Methods in Applied Mechanics and Engineering, 2022, 395: 114909
work page 2022
-
[10]
Chowdhary, K.R. Natural language processing. In:Fundamentals of Artificial In- telligence, Springer, 2020: 603–649
work page 2020
-
[11]
A unified architecture for natural language processing: deep neural networks with multitask learning
Collobert, R., Weston, J. A unified architecture for natural language processing: deep neural networks with multitask learning. In:ICML, 2008: 160–167
work page 2008
-
[12]
BERT: pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.-W., Lee, K., Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In:NAACL-HLT, 2019: 4171–4186
work page 2019
-
[13]
Dong, S., Yang, J. On computing the hyperparameter of extreme learning ma- chines: algorithm and application to computational PDEs, and comparison with classical and high-order finite elements.Journal of Computational Physics, 2022, 463: 111290
work page 2022
-
[14]
Dong, S., Li, Z. Local extreme learning machines and domain decomposition for solving linear and nonlinear partial differential equations.Computer Methods in Applied Mechanics and Engineering, 2021, 387: 114129
work page 2021
-
[15]
Dwivedi, V., Srinivasan, B. Physics informed extreme learning machine (PIELM)–a rapid method for the numerical solution of partial differential equations.Neurocom- puting, 2020, 391: 96–118
work page 2020
-
[16]
Han, J., Jentzen, A. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equa- tions.Communications in Mathematics and Statistics, 2017, 5(4): 349–380. 30
work page 2017
-
[17]
Han, J., Jentzen, A., E, W. Solving high-dimensional partial differential equations using deep learning.PNAS, 2018, 115(34): 8505–8510
work page 2018
-
[18]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., Sun, J. Deep residual learning for image recognition. In:CVPR, 2016: 770–778
work page 2016
-
[19]
Multilayer feedforward networks are uni- versal approximators.Neural Networks, 1989, 2(5): 359–366
Hornik, K., Stinchcombe, M., White, H. Multilayer feedforward networks are uni- versal approximators.Neural Networks, 1989, 2(5): 359–366
work page 1989
-
[20]
Howard, A.A., et al. Stacked networks improve physics-informed training: ap- plications to neural networks and deep operator networks. arXiv preprint arXiv:2311.06483, 2023
-
[21]
Extreme learning machine: theory and applications.Neurocomputing, 2006, 70(1–3): 489–501
Huang, G.-B., Zhu, Q.-Y., Siew, C.-K. Extreme learning machine: theory and applications.Neurocomputing, 2006, 70(1–3): 489–501
work page 2006
-
[22]
Jagtap, A.D., Karniadakis, G.E. Extended physics-informed neural networks (XPINNs): a generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations.Communications in Compu- tational Physics, 2020, 28(5)
work page 2020
-
[23]
John Xu, Z.-Q., Zhang, Y., Luo, T., Xiao, Y., Ma, Z. Frequency principle: Fourier analysis sheds light on deep neural networks.Communications in Computational Physics, 2020, 28(5): 1746–1767
work page 2020
-
[24]
Kiyani, E., et al. Optimizing the optimizer for physics-informed neural networks and Kolmogorov-Arnold networks.Computer Methods in Applied Mechanics and Engineering, 2025, 446: 118308
work page 2025
-
[25]
Kopaniˇ c´ akov´ a, A., Kothari, H., Karniadakis, G.E., Krause, R. Enhancing training of physics-informed neural networks using domain decomposition–based precondi- tioning strategies.SIAM Journal on Scientific Computing, 2024, 46(5): S46–S67
work page 2024
-
[26]
Krishnapriyan, A., et al. Characterizing possible failure modes in physics-informed neural networks.Advances in Neural Information Processing Systems, 2021, 34: 26548–26560
work page 2021
-
[27]
Deep learning.Nature, 2015, 521(7553): 436– 444
LeCun, Y., Bengio, Y., Hinton, G. Deep learning.Nature, 2015, 521(7553): 436– 444
work page 2015
-
[28]
KAN: Kolmogorov-Arnold Networks
Liu, Z., et al. KAN: Kolmogorov-Arnold networks. arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Lu, T., Ju, L., Zhu, L. A multiple transferable neural network method with domain decomposition for elliptic interface problems.Journal of Computational Physics, 2025, 530: 113902
work page 2025
-
[30]
An upper limit of decaying rate with respect to frequency in linear frequency principle model
Luo, T., Ma, Z., Wang, Z., Xu, Z.J., Zhang, Y. An upper limit of decaying rate with respect to frequency in linear frequency principle model. In:MSML, PMLR, 2022: 205–214
work page 2022
-
[31]
Mildenhall, B., et al. NeRF: representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 2021, 65(1): 99–106. 31
work page 2021
-
[32]
Moseley, B., Markham, A., Nissen-Meyer, T. Finite basis physics-informed neu- ral networks (FBPINNs): a scalable domain decomposition approach for solving differential equations.Advances in Computational Mathematics, 2023, 49(4): 62
work page 2023
-
[33]
Achieving high accuracy with PINNs via energy natural gradient descent
M¨ uller, J., Zeinhofer, M. Achieving high accuracy with PINNs via energy natural gradient descent. In:ICML, PMLR, 2023: 25471–25485
work page 2023
-
[34]
Ni, N., Dong, S. Numerical computation of partial differential equations by hidden- layer concatenated extreme learning machine.Journal of Scientific Computing, 2023, 95(2): 35
work page 2023
-
[35]
On the spectral bias of neural networks
Rahaman, N., et al. On the spectral bias of neural networks. In:ICML, PMLR, 2019: 5301–5310
work page 2019
-
[36]
Raissi, M., Perdikaris, P., Karniadakis, G.E. Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving non- linear partial differential equations.Journal of Computational Physics, 2019, 378: 686–707
work page 2019
-
[37]
U-Net: convolutional networks for biomed- ical image segmentation
Ronneberger, O., Fischer, P., Brox, T. U-Net: convolutional networks for biomed- ical image segmentation. In:MICCAI, 2015: 234–241
work page 2015
-
[38]
Shukla, K., et al. A comprehensive and FAIR comparison between MLP and KAN representations for differential equations and operator networks.Computer Methods in Applied Mechanics and Engineering, 2024, 431: 117290
work page 2024
-
[39]
Sirignano, J., Spiliopoulos, K. DGM: a deep learning algorithm for solving partial differential equations.Journal of Computational Physics, 2018, 375: 1339–1364
work page 2018
-
[40]
Urb´ an, J.F., Stefanou, P., Pons, J.A. Unveiling the optimization process of physics informed neural networks: how accurate and competitive can PINNs be?Journal of Computational Physics, 2025, 523: 113656
work page 2025
-
[41]
Attention is all you need.Advances in Neural Information Processing Systems, 2017, 30
Vaswani, A., et al. Attention is all you need.Advances in Neural Information Processing Systems, 2017, 30
work page 2017
-
[42]
Gradient alignment in physics- informed neural networks: a second-order optimization perspective
Wang, S., Bhartari, A.K., Li, B., Perdikaris, P. Gradient alignment in physics- informed neural networks: a second-order optimization perspective. arXiv preprint arXiv:2502.00604, 2025
-
[43]
Wang, Y., Lai, C.-Y. Multi-stage neural networks: function approximator of ma- chine precision.Journal of Computational Physics, 2024, 504: 112865
work page 2024
-
[44]
Wang, S., Teng, Y., Perdikaris, P. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Com- puting, 2021, 43(5): A3055–A3081
work page 2021
-
[45]
Wang, S., Yu, X., Perdikaris, P. When and why PINNs fail to train: a neural tangent kernel perspective.Journal of Computational Physics, 2022, 449: 110768
work page 2022
-
[46]
Multi-grade deep learning.Communications on Applied Mathematics and Computation, 2025: 1–52
Xu, Y. Multi-grade deep learning.Communications on Applied Mathematics and Computation, 2025: 1–52. 32
work page 2025
-
[47]
Xu, M., Zhang, L., Wu, B., Liu, K. A novel class of hessian recovery-based numer- ical methods for solving biharmonic equations and their applications in phase field modeling.Finite Elements in Analysis and Design, 2025, 251: 104405
work page 2025
-
[48]
Xu, Z.-Q.J., Zhang, Y., Luo, T. Overview frequency principle/spectral bias in deep learning.Communications on Applied Mathematics and Computation, 2025, 7(3): 827–864
work page 2025
-
[49]
Xu, Z.-Q.J., Zhang, L., Cai, W. On understanding and overcoming spectral biases of deep neural network learning methods for solving PDEs.Journal of Computa- tional Physics, 2025, 530: 113905
work page 2025
-
[50]
Yang, Y., Hou, M., Luo, J. A novel improved extreme learning machine algorithm in solving ordinary differential equations by Legendre neural network methods. Advances in Difference Equations, 2018, 2018(1): 469
work page 2018
-
[51]
Yu, B. The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 2018, 6(1): 1–12
work page 2018
-
[52]
Zang, Y., Bao, G., Ye, X., Zhou, H. Weak adversarial networks for high-dimensional partial differential equations.Journal of Computational Physics, 2020, 411: 109409
work page 2020
-
[53]
Zhang, Z., Naga, A. A new finite element gradient recovery method: superconver- gence property.SIAM Journal on Scientific Computing, 2005, 26(4): 1192–1213
work page 2005
-
[54]
Zhang, Z., Bao, F., Ju, L., Zhang, G. Transferable neural networks for partial differential equations.Journal of Scientific Computing, 2024, 99(1): 2. 33
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.