Recognition: 2 theorem links
· Lean TheoremGradient Boosting within a Single Attention Layer
Pith reviewed 2026-05-13 20:19 UTC · model grok-4.3
The pith
A second attention pass inside one transformer layer can correct its own errors by mapping to gradient boosting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a squared reconstruction objective, gradient-boosted attention maps onto Friedman's gradient boosting machine, with each attention pass as a base learner and the per-dimension gate as the shrinkage parameter. A single Hopfield-style update erases query information orthogonal to the stored-pattern subspace, and further iteration under local contraction collapses distinct queries to the same fixed point. Separate projections for the correction pass recover residual information inaccessible to shared-projection twicing.
What carries the argument
A second attention pass with its own learned projections that attends to the prediction error of the first pass, gated by a per-dimension shrinkage factor.
If this is right
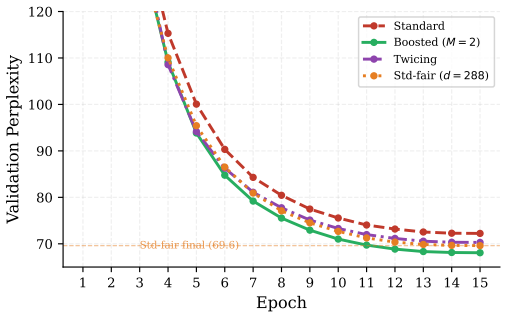
- Test perplexity improves by 6.0 percent on WikiText-103 and 5.6 percent on OpenWebText over standard attention on 10M-token subsets.
- Two correction rounds capture most of the gain while keeping parameter cost low.
- The method outperforms both Twicing Attention and a parameter-matched wider baseline on both benchmarks.
- The same architecture degrades perplexity under Post-LN normalization.
Where Pith is reading between the lines
- The mechanism could extend to other residual architectures beyond transformers if they preserve additive error signals between layers.
- Separate projections enable recovery of information that shared-projection methods such as twicing cannot access.
- Further iterations beyond two rounds may yield diminishing returns once local contraction has aligned queries to fixed points.
Load-bearing premise
The transformer must use the additive residual connections of Pre-LN normalization so the second pass can recover information the first pass missed.
What would settle it
Replacing Pre-LN with Post-LN normalization in the same architecture and observing whether perplexity degrades by 9.6 percent on the same data.
Figures







read the original abstract
Transformer attention computes a single softmax-weighted average over values -- a one-pass estimate that cannot correct its own errors. We introduce \emph{gradient-boosted attention}, which applies the principle of gradient boosting \emph{within} a single attention layer: a second attention pass, with its own learned projections, attends to the prediction error of the first and applies a gated correction. Under a squared reconstruction objective, the construction maps onto Friedman's gradient boosting machine, with each attention pass as a base learner and the per-dimension gate as the shrinkage parameter. We show that a single Hopfield-style update erases all query information orthogonal to the stored-pattern subspace, and that further iteration under local contraction can collapse distinct queries in the same region to the same fixed point. We also show that separate projections for the correction pass can recover residual information inaccessible to the shared-projection approach of Tukey's twicing. On 10M-token subsets of WikiText-103 and OpenWebText, gradient-boosted attention improves test perplexity by $6.0\%$ and $5.6\%$ over standard attention, outperforming both Twicing Attention and a parameter-matched wider baseline on both benchmarks, with two rounds capturing most of the benefit. We further show, both theoretically and empirically, that the mechanism requires the additive residual structure of Pre-LN transformers: under Post-LN, the same architecture degrades perplexity by $9.6\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes gradient-boosted attention, a two-pass mechanism inside a single attention layer. The first pass computes standard attention; the second attends to the residual error using separate learned projections and applies a per-dimension gated correction. Under a squared reconstruction objective the construction is claimed to map onto Friedman's gradient boosting machine, with each attention pass as a base learner and the gate as the shrinkage parameter. Theoretical analysis shows that a Hopfield-style update erases query information orthogonal to the stored-pattern subspace and that further iteration under local contraction collapses distinct queries. Empirically, on 10M-token subsets of WikiText-103 and OpenWebText the method improves test perplexity by 6.0% and 5.6% over standard attention, outperforming Twicing Attention and a parameter-matched wider baseline; most benefit is captured by two rounds. The architecture is shown to require the additive residual structure of Pre-LN transformers and degrades perplexity by 9.6% under Post-LN.
Significance. If the GBM equivalence holds and accounts for the gains, the work supplies a principled interpretation of attention refinement as iterative boosting and a practical single-layer improvement to transformers. The concrete perplexity deltas, fair baseline comparisons, and the Pre-LN versus Post-LN contrast are useful contributions. The Hopfield-style erasure and contraction results add theoretical insight into attention dynamics.
major comments (3)
- [Abstract and theoretical mapping] Abstract: the GBM mapping is derived only under a squared reconstruction objective, yet the reported experiments optimize autoregressive cross-entropy loss. The residual attended by the second pass is therefore not a squared-error residual, and it is not shown that the learned per-dimension gates continue to act as shrinkage parameters or that the boosting dynamics survive the change of loss. Without a derivation or ablation linking the two settings, the 6.0% and 5.6% perplexity improvements cannot be confidently attributed to the claimed GBM mechanism.
- [Experiments section] Pre-LN versus Post-LN experiments: the 9.6% degradation under Post-LN is presented as evidence that the mechanism requires additive residual structure. The manuscript should state whether the Post-LN baseline was otherwise identical (same layer-norm placement, same residual scaling) or whether any additional adjustments were made, so that the comparison isolates the effect of the residual connection.
- [Theoretical analysis] Hopfield-style analysis: the claims that a single update erases all query information orthogonal to the stored-pattern subspace and that further iteration produces collapse under local contraction are stated, but their precise relationship to the GBM interpretation (as opposed to being an independent property of the attention operator) is not made explicit.
minor comments (2)
- [Method] The integration of the correction pass into the transformer block (shared versus separate residual path, exact placement relative to layer-norm) should be shown with a single diagram or explicit equations for reproducibility.
- [Experiments] Table or figure captions should explicitly state the number of tokens and the exact baseline configurations (e.g., hidden dimension of the wider model) so that the parameter-matched comparison is immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive evaluation of the significance of the work. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and theoretical mapping] Abstract: the GBM mapping is derived only under a squared reconstruction objective, yet the reported experiments optimize autoregressive cross-entropy loss. The residual attended by the second pass is therefore not a squared-error residual, and it is not shown that the learned per-dimension gates continue to act as shrinkage parameters or that the boosting dynamics survive the change of loss. Without a derivation or ablation linking the two settings, the 6.0% and 5.6% perplexity improvements cannot be confidently attributed to the claimed GBM mechanism.
Authors: We agree that the formal GBM equivalence is stated only under squared reconstruction loss. The language-modeling experiments use standard autoregressive cross-entropy. We will revise the abstract and introduction to more clearly separate the theoretical claim (squared loss) from the empirical results (cross-entropy). We will also add a short discussion and gate-value statistics confirming that the learned gates remain in (0,1) and continue to scale the correction term. A full derivation under cross-entropy is not provided and lies outside the current scope. revision: partial
-
Referee: [Experiments section] Pre-LN versus Post-LN experiments: the 9.6% degradation under Post-LN is presented as evidence that the mechanism requires additive residual structure. The manuscript should state whether the Post-LN baseline was otherwise identical (same layer-norm placement, same residual scaling) or whether any additional adjustments were made, so that the comparison isolates the effect of the residual connection.
Authors: The Post-LN baseline was identical to the Pre-LN version in every respect except the placement of layer normalization (after rather than before the residual addition). No changes were made to residual scaling or any other hyper-parameters. We will revise the experiments section to state this explicitly. revision: yes
-
Referee: [Theoretical analysis] Hopfield-style analysis: the claims that a single update erases all query information orthogonal to the stored-pattern subspace and that further iteration produces collapse under local contraction are stated, but their precise relationship to the GBM interpretation (as opposed to being an independent property of the attention operator) is not made explicit.
Authors: We will revise the theoretical section to make the link explicit. The erasure of orthogonal components after the first pass allows the second pass to operate on residual error within the aligned subspace, directly supporting the boosting-style correction. The contraction result under iteration further justifies the empirical observation that two rounds capture most of the gain. A connecting paragraph will be added. revision: yes
- Without a derivation or ablation linking the GBM mechanism to the cross-entropy loss used in the experiments, the perplexity improvements cannot be confidently attributed to the claimed GBM dynamics.
Circularity Check
No significant circularity; GBM mapping derived from squared objective
full rationale
The paper scopes its central equivalence explicitly to a squared reconstruction objective and derives the correspondence between the two-pass gated attention and Friedman's GBM (each pass as base learner, per-dimension gate as shrinkage) via the additive residual structure. This is presented as a mathematical consequence rather than a tautology or fitted input. Separate derivations cover Hopfield-style query erasure and residual recovery via distinct projections, independent of the GBM claim. No self-citations are invoked as load-bearing for the mapping, and the cross-entropy experiments are reported as empirical outcomes without claiming they are predicted by the squared-loss equivalence. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-dimension gate parameters
- correction-pass projection matrices
axioms (2)
- domain assumption Squared reconstruction objective
- domain assumption Additive residual structure of Pre-LN transformers
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearUnder a squared reconstruction objective, the construction maps onto Friedman's gradient boosting machine, with each attention pass as a base learner and the per-dimension gate as the shrinkage parameter.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_add unclearthe mechanism requires the additive residual structure of Pre-LN transformers
Reference graph
Works this paper leans on
-
[1]
PonderNet: Learning to ponder.arXiv preprint arXiv:2106.01345,
Andrea Banino, Jan Balaguer, and Charles Blundell. PonderNet: Learning to ponder.arXiv preprint arXiv:2106.01345,
-
[2]
DeepCrossAttention: Supercharging transformer residual connections.arXiv preprint arXiv:2502.06785,
Lucas Heddes et al. DeepCrossAttention: Supercharging transformer residual connections.arXiv preprint arXiv:2502.06785,
-
[3]
Attention residuals.arXiv preprint arXiv:2603.15031,
Kimi Team. Attention residuals.arXiv preprint arXiv:2603.15031,
-
[4]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zhenyu Qiu et al. Gated attention for large language models: Non-linearity, sparsity, and attention- sink-free.arXiv preprint arXiv:2505.06708,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Residual networks behave like boosting algorithms.arXiv preprint arXiv:1909.11790,
Chapman Siu. Residual networks behave like boosting algorithms.arXiv preprint arXiv:1909.11790,
-
[7]
16 A Hyperparameters and Training Details Table 7 lists all hyperparameters for the language modeling experiments. All models share the same training configuration; only the attention mechanism and normalization placement differ. OpenWebText experiments use the same hyperparameters with a separately trained BPE tokenizer. Table 7: Hyperparameters for lang...
work page 2000
-
[8]
K unit-normalized patterns p1,
and ablation studies (Section 6.3) use a synthetic pattern retrieval task. K unit-normalized patterns p1, . . . ,pK ∈R d are sampled uniformly from the unit sphere. A query is generated by selecting a pattern pj uniformly at random and adding isotropic Gaus- sian noise: ˜x=p j +ε , ε∼ N(0, σ 2I). Retrieval accuracy is the fraction of queries for which the...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.