Recognition: 2 theorem links
· Lean TheoremHVG-3D: Bridging Real and Simulation Domains for 3D-Conditional Hand-Object Interaction Video Synthesis
Pith reviewed 2026-05-14 00:10 UTC · model grok-4.3
The pith
HVG-3D uses a 3D ControlNet in a diffusion model to synthesize hand-object videos from explicit 3D conditions drawn from real or simulated data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
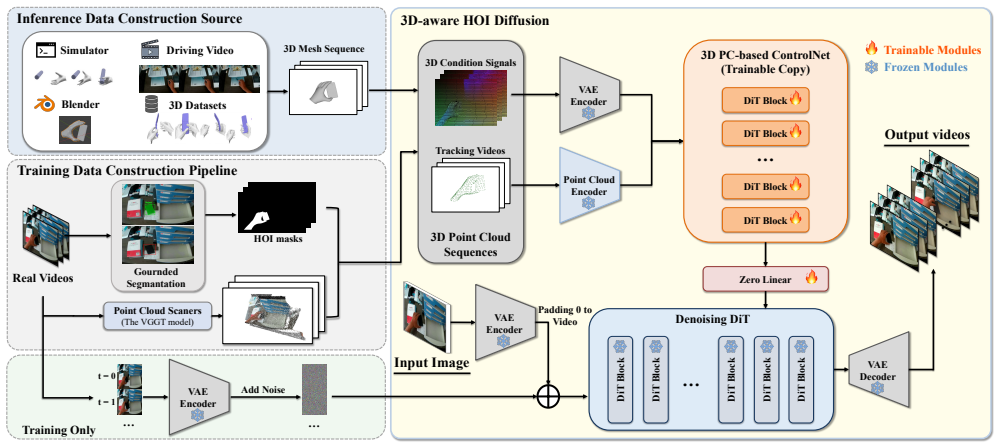
HVG-3D is a unified diffusion-based framework augmented with a 3D ControlNet that encodes geometric and motion cues from 3D inputs to enable explicit 3D reasoning during video synthesis, paired with a hybrid pipeline for constructing input and condition signals that supports flexible control and high-quality output from a single real image combined with either real or simulated 3D signals.
What carries the argument
The 3D ControlNet that augments the diffusion architecture to encode geometric and motion cues from 3D inputs and supply them for explicit 3D reasoning in hand-object interaction video generation.
If this is right
- State-of-the-art spatial fidelity, temporal coherence, and controllability on the TASTE-Rob dataset.
- Effective use of both real and simulated 3D data in the same training and inference pipeline.
- Precise spatial and temporal control during inference from a single real image plus a 3D control signal.
- Flexible construction of condition signals that works for both training and inference phases.
Where Pith is reading between the lines
- The same 3D-conditioning approach could be adapted to full-body human motion or multi-object scenes where explicit geometry is available.
- Synthetic 3D data could become a practical supplement to scarce real hand-object videos if the domain-bridging holds under larger gaps.
- Testing the model with noisy or incomplete 3D inputs from real captures would clarify its practical robustness.
- Accelerating the diffusion sampling step could open the door to real-time or interactive synthesis applications.
Load-bearing premise
That a 3D ControlNet can reliably encode cues from both real and simulated 3D data without major domain gaps that would impair synthesis quality.
What would settle it
A side-by-side comparison on the TASTE-Rob dataset showing that videos conditioned on simulated 3D signals have substantially lower spatial fidelity or temporal coherence than those conditioned on matched real 3D signals.
Figures



read the original abstract
Recent methods have made notable progress in the visual quality of hand-object interaction video synthesis. However, most approaches rely on 2D control signals that lack spatial expressiveness and limit the utilization of synthetic 3D conditional data. To address these limitations, we propose HVG-3D, a unified framework for 3D-aware hand-object interaction (HOI) video synthesis conditioned on explicit 3D representations. Specifically, we develop a diffusion-based architecture augmented with a 3D ControlNet, which encodes geometric and motion cues from 3D inputs to enable explicit 3D reasoning during video synthesis. To achieve high-quality synthesis, HVG-3D is designed with two core components: (i) a 3D-aware HOI video generation diffusion architecture that encodes geometric and motion cues from 3D inputs for explicit 3D reasoning; and (ii) a hybrid pipeline for constructing input and condition signals, enabling flexible and precise control during both training and inference. During inference, given a single real image and a 3D control signal from either simulation or real data, HVG-3D generates high-fidelity, temporally consistent videos with precise spatial and temporal control. Experiments on the TASTE-Rob dataset demonstrate that HVG-3D achieves state-of-the-art spatial fidelity, temporal coherence, and controllability, while enabling effective utilization of both real and simulated data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HVG-3D, a diffusion-based framework augmented by a 3D ControlNet for synthesizing hand-object interaction videos conditioned on explicit 3D representations from real or simulated sources. It introduces a hybrid pipeline for input/condition signals and claims state-of-the-art spatial fidelity, temporal coherence, and controllability on the TASTE-Rob dataset while enabling effective mixed-domain data utilization.
Significance. If the quantitative claims are substantiated, the work would advance controllable HOI video generation by demonstrating that 3D conditioning can improve spatial reasoning and allow synthetic data to complement real captures. This has clear relevance for robotics simulation and AR/VR applications where precise 3D control is needed.
major comments (2)
- [Abstract] Abstract: the central claim that HVG-3D achieves SOTA spatial fidelity, temporal coherence, and controllability is unsupported because no quantitative metrics, baseline comparisons, or experimental protocol details are supplied, leaving the superiority assertion without visible evidence.
- [Method] Method description (3D ControlNet component): the architecture is presented as encoding geometric and motion cues from mixed real/simulated 3D inputs without any domain-specific normalization, feature alignment, or adaptation steps; this directly bears on the bridging claim and risks the model simply memorizing domain-specific patterns rather than learning transferable 3D reasoning.
minor comments (1)
- [Abstract] Abstract: the hybrid pipeline for constructing input and condition signals is referenced but lacks even high-level implementation details that would clarify how flexible control is achieved at inference.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses below and have revised the paper to address the concerns where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that HVG-3D achieves SOTA spatial fidelity, temporal coherence, and controllability is unsupported because no quantitative metrics, baseline comparisons, or experimental protocol details are supplied, leaving the superiority assertion without visible evidence.
Authors: We agree that the abstract should more explicitly support the SOTA claims. The full manuscript contains quantitative results in Section 4, including baseline comparisons on the TASTE-Rob dataset with metrics for spatial fidelity (e.g., PSNR, SSIM, FID), temporal coherence (e.g., FVD), and controllability. These demonstrate improvements over prior methods. We will revise the abstract to include key quantitative highlights and reference the experimental protocol details from the main text. revision: yes
-
Referee: [Method] Method description (3D ControlNet component): the architecture is presented as encoding geometric and motion cues from mixed real/simulated 3D inputs without any domain-specific normalization, feature alignment, or adaptation steps; this directly bears on the bridging claim and risks the model simply memorizing domain-specific patterns rather than learning transferable 3D reasoning.
Authors: This is a fair observation on the bridging claim. The hybrid pipeline enables mixed-domain use, but the manuscript does not sufficiently detail normalization or alignment. In the revision, we will expand the 3D ControlNet description to include explicit domain-specific normalization, feature alignment, and adaptation steps for real/simulated 3D inputs. We will also add ablation studies showing cross-domain generalization to support transferable 3D reasoning over memorization. revision: yes
Circularity Check
No circularity: HVG-3D extends diffusion+ControlNet with empirical validation only
full rationale
The paper proposes an architectural augmentation (diffusion model + 3D ControlNet) that encodes 3D cues for HOI video synthesis and reports empirical SOTA results on TASTE-Rob. No derivation chain, equations, or load-bearing claims reduce a prediction to a fitted parameter, self-citation, or input by construction. The method is presented as an extension of standard techniques with hybrid data pipeline; performance claims are benchmark-driven rather than self-referential. This is the common honest case of a self-contained empirical ML contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models conditioned on 3D geometric and motion cues can perform explicit 3D reasoning for video synthesis
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a diffusion-based architecture augmented with a 3D ControlNet, which encodes geometric and motion cues from 3D inputs to enable explicit 3D reasoning during video synthesis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
LottieGPT: Tokenizing Vector Animation for Autoregressive Generation
LottieGPT tokenizes Lottie animations into compact sequences and fine-tunes Qwen-VL to autoregressively generate coherent vector animations from natural language or visual prompts, outperforming prior SVG models.
Reference graph
Works this paper leans on
-
[1]
Interdyn: Con- trollable interactive dynamics with video diffusion models
Rick Akkerman, Haiwen Feng, Michael J Black, Dimitrios Tzionas, and Victoria Fern ´andez Abrevaya. Interdyn: Con- trollable interactive dynamics with video diffusion models. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 12467–12479, 2025. 2, 3, 5, 6
work page 2025
-
[2]
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Fan Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, et al. Intro- ducing hot3d: An egocentric dataset for 3d hand and object tracking.arXiv preprint arXiv:2406.09598, 2024. 5
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π0: A vision-language-action flow model for general robot control. corr, abs/2410.24164, 2024. doi: 10.48550.arXiv preprint ARXIV .2410.24164. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakr- ishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 2
work page 2024
-
[7]
Text2hoi: Text-guided 3d motion generation for hand- object interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, and Seungryul Baek. Text2hoi: Text-guided 3d motion generation for hand- object interaction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 1577–1585, 2024. 3
work page 2024
-
[8]
Idea23d: Collaborative lmm agents enable 3d model generation from interleaved multimodal inputs
Junhao Chen, Xiang Li, Xiaojun Ye, Chao Li, Zhaoxin Fan, and Hao Zhao. Idea23d: Collaborative lmm agents enable 3d model generation from interleaved multimodal inputs. In Proceedings of the 31st International Conference on Com- putational Linguistics, pages 4149–4166, 2025. 3
work page 2025
-
[9]
Dance- together: Generating interactive multi-person video without identity drifting
Junhao Chen, Mingjin Chen, Jianjin Xu, Xiang Li, Junt- ing Dong, Mingze Sun, Puhua Jiang, Hongxiang Li, Yuhang Yang, Hao Zhao, Xiao-Xiao Long, and Ruqi Huang. Dance- together: Generating interactive multi-person video without identity drifting. InThe Fourteenth International Conference on Learning Representations, 2026. 2, 3
work page 2026
-
[10]
Mingjin Chen, Junhao Chen, Huan-ang Gao, Xiaoxue Chen, Zhaoxin Fan, and Hao Zhao. Ultraman: ultra-fast and high- resolution texture generation for 3d human reconstruction from a single image.Machine Vision and Applications, 37 (2):24, 2026. 3
work page 2026
-
[11]
Lingwei Dang, Ruizhi Shao, Hongwen Zhang, Wei Min, Yebin Liu, and Qingyao Wu. Svimo: Synchronized diffu- sion for video and motion generation in hand-object interac- tion scenarios.arXiv preprint arXiv:2506.02444, 2025. 2
-
[12]
Google DeepMind. Veo 3.https : / / deepmind . google/technologies/veo/, 2024. 2
work page 2024
-
[13]
Fast graspability evalua- tion on single depth maps for bin picking with general grip- pers
Yukiyasu Domae, Haruhisa Okuda, Yuichi Taguchi, Kazuhiko Sumi, and Takashi Hirai. Fast graspability evalua- tion on single depth maps for bin picking with general grip- pers. In2014 IEEE International Conference on Robotics and Automation (ICRA), pages 1997–2004. IEEE, 2014. 2
work page 1997
-
[14]
Shiying Duan, Pei Ren, Nanxiang Jiang, Zhengping Che, Jian Tang, Zhaoxin Fan, Yifan Sun, and Wenjun Wu. Robopara: Dual-arm robot planning with parallel allo- cation and recomposition across tasks.arXiv preprint arXiv:2506.06683, 2025. 2
-
[15]
Arctic: A dataset for dexterous bimanual hand- object manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Otmar Hilliges. Arctic: A dataset for dexterous bimanual hand- object manipulation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 12943–12954, 2023. 3, 5
work page 2023
-
[16]
Hold: Category-agnostic 3d reconstruction of in- teracting hands and objects from video
Zicong Fan, Maria Parelli, Maria Eleni Kadoglou, Xu Chen, Muhammed Kocabas, Michael J Black, and Otmar Hilliges. Hold: Category-agnostic 3d reconstruction of in- teracting hands and objects from video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 494–504, 2024. 3
work page 2024
-
[17]
Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–12, 2025. 2, 5, 6
work page 2025
-
[18]
Learning joint reconstruction of hands and manipulated ob- jects
Yana Hasson, Gul Varol, Dimitrios Tzionas, Igor Kale- vatykh, Michael J Black, Ivan Laptev, and Cordelia Schmid. Learning joint reconstruction of hands and manipulated ob- jects. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 11807–11816,
-
[19]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Clipscore: A reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning. InProceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 7514–7528, 2021. 5
work page 2021
-
[21]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InAdvances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2017. 5
work page 2017
-
[22]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
work page 2020
-
[23]
Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022. 2
work page 2022
-
[24]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Gal- liker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page 2025
-
[25]
Peekaboo: Interactive video generation via masked- diffusion
Yash Jain, Anshul Nasery, Vibhav Vineet, and Harkirat Behl. Peekaboo: Interactive video generation via masked- diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8079– 8088, 2024. 2
work page 2024
-
[26]
Sangwon Jang, Taekyung Ki, Jaehyeong Jo, Jaehong Yoon, Soo Ye Kim, Zhe Lin, and Sung Ju Hwang. Frame guidance: Training-free guidance for frame-level control in video dif- fusion models.arXiv preprint arXiv:2506.07177, 2025. 3
-
[27]
Yolo by ultralytics.https://github.com/ultralytics/ ultralytics, 2023
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Yolo by ultralytics.https://github.com/ultralytics/ ultralytics, 2023. 4
work page 2023
-
[28]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[29]
Sapiens: Foundation for human vision mod- els.arXiv preprint arXiv:2408.12569, 2024
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, and Shunsuke Saito. Sapiens: Foundation for human vision mod- els.arXiv preprint arXiv:2408.12569, 2024. 3
-
[30]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 4
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[31]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [32]
-
[33]
Ariel Lapid, Idan Achituve, Lior Bracha, and Ethan Fetaya. Gd-vdm: Generated depth for better diffusion-based video generation.arXiv preprint arXiv:2306.11173, 2023. 3
-
[34]
Yujian Lee, Peng Gao, Yongqi Xu, and Wentao Fan. How do optical flow and textual prompts collaborate to assist in audio-visual semantic segmentation? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23342–23352, 2025. 2
work page 2025
-
[35]
Biwen Lei, Yang Li, Xinhai Liu, Shuhui Yang, Lixin Xu, Jingwei Huang, Ruining Tang, Haohan Weng, Jian Liu, Jing Xu, et al. Hunyuan3d studio: End-to-end ai pipeline for game-ready 3d asset generation.arXiv preprint arXiv:2509.12815, 2025. 3
-
[36]
Hongxiang Li, Yaowei Li, Yuhang Yang, Junjie Cao, Zhi- hong Zhu, Xuxin Cheng, and Long Chen. Dispose: Disen- tangling pose guidance for controllable human image anima- tion.arXiv preprint arXiv:2412.09349, 2024. 3
-
[37]
Building egocentric pro- cedural ai assistant: Methods, benchmarks, and challenges
Junlong Li, Huaiyuan Xu, Sijie Cheng, Kejun Wu, Kim-Hui Yap, Lap-Pui Chau, and Yi Wang. Building egocentric pro- cedural ai assistant: Methods, benchmarks, and challenges. arXiv preprint arXiv:2511.13261, 2025. 3
-
[38]
Pshuman: Photorealistic single-view human reconstruction using cross-scale diffusion
Peng Li, Wangguandong Zheng, Yuan Liu, Tao Yu, Yang- guang Li, Xingqun Qi, Xiaowei Chi, Siyu Xia, Yan-Pei Cao, Wei Xue, et al. Pshuman: Photorealistic single-view human reconstruction using cross-scale diffusion. 2024. 3
work page 2024
-
[39]
Image conductor: Precision control for interactive video syn- thesis
Yaowei Li, Xintao Wang, Zhaoyang Zhang, Zhouxia Wang, Ziyang Yuan, Liangbin Xie, Ying Shan, and Yuexian Zou. Image conductor: Precision control for interactive video syn- thesis. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5031–5038, 2025. 2
work page 2025
-
[40]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Wonder3d: Sin- gle image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Sin- gle image to 3d using cross-domain diffusion. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9970–9980, 2024. 3
work page 2024
-
[42]
Dreamactor-m1: Holistic, expres- sive and robust human image animation with hybrid guid- ance
Yuxuan Luo, Zhengkun Rong, Lizhen Wang, Longhao Zhang, and Tianshu Hu. Dreamactor-m1: Holistic, expres- sive and robust human image animation with hybrid guid- ance. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 11036–11046, 2025. 3
work page 2025
-
[43]
Jeremy Maitin-Shepard, Marco Cusumano-Towner, Jinna Lei, and Pieter Abbeel. Cloth grasp point detection based on multiple-view geometric cues with application to robotic towel folding. In2010 IEEE International Conference on Robotics and Automation, pages 2308–2315. IEEE, 2010. 2
work page 2010
-
[44]
Dexvip: Learning dexterous grasping with human hand pose priors from video
Priyanka Mandikal and Kristen Grauman. Dexvip: Learning dexterous grasping with human hand pose priors from video. InConference on Robot Learning, pages 651–661. PMLR,
-
[45]
Xingyu Miao, Junting Dong, Qin Zhao, Yuhang Yang, Jun- hao Chen, and Yang Long. From frames to sequences: Tem- porally consistent human-centric dense prediction.arXiv preprint arXiv:2602.01661, 2026. 3
-
[46]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 3
work page 2021
-
[47]
Efficient motion weighted spatio-temporal video ssim index
Anush K Moorthy and Alan C Bovik. Efficient motion weighted spatio-temporal video ssim index. InHuman Vision and Electronic Imaging XV, pages 440–448. SPIE, 2010. 5
work page 2010
-
[48]
Koichi Namekata, Sherwin Bahmani, Ziyi Wu, Yash Kant, Igor Gilitschenski, and David B Lindell. Sg-i2v: Self-guided trajectory control in image-to-video generation.arXiv preprint arXiv:2411.04989, 2024. 2
-
[49]
Muyao Niu, Xiaodong Cun, Xintao Wang, Yong Zhang, Ying Shan, and Yinqiang Zheng. Mofa-video: Controllable image animation via generative motion field adaptions in frozen image-to-video diffusion model. InEuropean Con- ference on Computer Vision, pages 111–128. Springer, 2024. 2
work page 2024
-
[50]
Manivideo: Generating hand-object manipulation video with dexterous and generalizable grasping
Youxin Pang, Ruizhi Shao, Jiajun Zhang, Hanzhang Tu, Yun Liu, Boyao Zhou, Hongwen Zhang, and Yebin Liu. Manivideo: Generating hand-object manipulation video with dexterous and generalizable grasping. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12209–12219, 2025. 2
work page 2025
-
[51]
Dreamdance: Animating human images by enriching 3d geometry cues from 2d poses
Yatian Pang, Bin Zhu, Bin Lin, Mingzhe Zheng, Francis EH Tay, Ser-Nam Lim, Harry Yang, and Li Yuan. Dreamdance: Animating human images by enriching 3d geometry cues from 2d poses. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 14039–14050,
-
[52]
Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming- Chang Yang, and Jiaya Jia. Controlnext: Powerful and effi- cient control for image and video generation.arXiv preprint arXiv:2408.06070, 2024. 2, 3
-
[53]
Haonan Qiu, Zhaoxi Chen, Zhouxia Wang, Yingqing He, Menghan Xia, and Ziwei Liu. Freetraj: Tuning-free tra- jectory control in video diffusion models.arXiv preprint arXiv:2406.16863, 2024. 2
-
[54]
Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun Wang, Weikang Bian, Dasong Li, Yi Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, et al. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024. 2
work page 2024
-
[55]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Magicarticulate: Make your 3d mod- els articulation-ready
Chaoyue Song, Jianfeng Zhang, Xiu Li, Fan Yang, Yiwen Chen, Zhongcong Xu, Jun Hao Liew, Xiaoyang Guo, Fayao Liu, Jiashi Feng, et al. Magicarticulate: Make your 3d mod- els articulation-ready. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15998–16007,
-
[57]
Yuejiao Su, Yi Wang, Lei Yao, Yawen Cui, and Lap-Pui Chau. Interaction-aware representation modeling with co- occurrence consistency for egocentric hand-object parsing. arXiv preprint arXiv:2602.20597, 2026. 3
-
[58]
Controlling the world by sleight of hand, 2024
Sruthi Sudhakar, Ruoshi Liu, Basile Van Hoorick, Carl V on- drick, and Richard Zemel. Controlling the world by sleight of hand, 2024. 2, 3
work page 2024
-
[59]
Drive: Diffusion-based rigging em- powers generation of versatile and expressive characters
Mingze Sun, Junhao Chen, Junting Dong, Yurun Chen, Xinyu Jiang, Shiwei Mao, Puhua Jiang, Jingbo Wang, Bo Dai, and Ruqi Huang. Drive: Diffusion-based rigging em- powers generation of versatile and expressive characters. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21170–21180, 2025. 3
work page 2025
-
[60]
Stableanimator: High- quality identity-preserving human image animation
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, and Zuxuan Wu. Stableanimator: High- quality identity-preserving human image animation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 21096–21106, 2025. 2, 5
work page 2025
-
[61]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Rapha¨el Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019. 5
work page 2019
-
[62]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Jiawei Wang, Yuchen Zhang, Jiaxin Zou, Yan Zeng, Guo- qiang Wei, Liping Yuan, and Hang Li. Boximator: Generat- ing rich and controllable motions for video synthesis.arXiv preprint arXiv:2402.01566, 2024. 2
-
[64]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 5
work page 2025
-
[65]
Vividpose: Advancing stable video diffusion for realistic human image animation
Qilin Wang, Zhengkai Jiang, Chengming Xu, Jiangning Zhang, Yabiao Wang, Xinyi Zhang, Yun Cao, Weijian Cao, Chengjie Wang, and Yanwei Fu. Vividpose: Advancing stable video diffusion for realistic human image animation. arXiv preprint arXiv:2405.18156, 2024. 2, 3
-
[66]
Youzhuo Wang, Jiayi Ye, Chuyang Xiao, Yiming Zhong, Heng Tao, Hang Yu, Yumeng Liu, Jingyi Yu, and Yuexin Ma. Dexh2r: A benchmark for dynamic dexterous grasping in human-to-robot handover.arXiv preprint arXiv:2506.23152,
-
[67]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600–612, 2004. 5
work page 2004
-
[68]
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Youqing Fang, Yuwei Guo, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, et al. Humanvid: Demystifying training data for camera-controllable human image animation.Advances in Neural Information Processing Systems, 37:20111–20131,
-
[69]
arXiv preprint arXiv:2411.09595 , year=
Zhengyi Wang, Jonathan Lorraine, Yikai Wang, Hang Su, Jun Zhu, Sanja Fidler, and Xiaohui Zeng. Llama-mesh: Unifying 3d mesh generation with language models.arXiv preprint arXiv:2411.09595, 2024. 3
-
[70]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Pa- pers, pages 1–11, 2024. 2
work page 2024
-
[71]
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Yuwei Guo, Dahua Lin, Tianfan Xue, and Bo Dai. Multi-identity hu- man image animation with structural video diffusion.arXiv preprint arXiv:2504.04126, 2025. 3
-
[72]
Garmentgpt: Com- positional garment pattern generation via discrete latent to- kenization
Fangsheng Weng, Junhao Chen, Xiang Li, Jie Qin, Hanzhong Guo, Xiaoguang Han, et al. Garmentgpt: Com- positional garment pattern generation via discrete latent to- kenization. InThe Fourteenth International Conference on Learning Representations, 2026. 3
work page 2026
-
[73]
Spatialtracker: Tracking any 2d pixels in 3d space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. Spatialtracker: Tracking any 2d pixels in 3d space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20406–20417, 2024. 5
work page 2024
-
[74]
Peng Yan, Xuanqin Mou, and Wufeng Xue. Video qual- ity assessment via gradient magnitude similarity deviation of spatial and spatiotemporal slices. InMobile Devices and Multimedia: Enabling Technologies, Algorithms, and Appli- cations 2015, pages 182–191. SPIE, 2015. 5
work page 2015
-
[75]
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, and Jenq-Neng Hwang. Samurai: Adapting segment anything model for zero-shot visual tracking with motion-aware memory.arXiv preprint arXiv:2411.11922,
-
[76]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging
Chongjie Ye, Yushuang Wu, Ziteng Lu, Jiahao Chang, Xi- aoyang Guo, Jiaqing Zhou, Hao Zhao, and Xiaoguang Han. Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 25050– 25061, 2025. 3
work page 2025
-
[78]
Wang Yifan, Felice Serena, Shihao Wu, Cengiz ¨Oztireli, and Olga Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing.ACM Transactions On Graphics (TOG), 38(6):1–14, 2019. 3
work page 2019
-
[79]
arXiv preprint arXiv:2308.08089 , year=
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089, 2023. 2
-
[80]
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neu- ral fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023. 4
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.