Recognition: 1 theorem link
· Lean TheoremWhen Sinks Help or Hurt: Unified Framework for Attention Sink in Large Vision-Language Models
Pith reviewed 2026-05-13 23:17 UTC · model grok-4.3
The pith
Sinks in vision-language models encode global scene priors but suppress local visual details, and a simple per-layer gating mechanism can restore the balance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Attention sinks, defined as tokens that attract disproportionate attention, come in two forms in LVLMs: V-sinks that originate in the vision encoder and L-sinks that emerge in the LLM layers. While they encode useful global scene-level priors, their dominance suppresses fine-grained visual evidence for local perception. Specific functional layers are identified where modulating these sinks has the largest impact. The proposed Layer-wise Sink Gating (LSG) dynamically scales the attention of V-sinks versus other visual tokens, trained only with next-token prediction and no additional supervision.
What carries the argument
Layer-wise Sink Gating (LSG), a plug-and-play module that dynamically scales the attention contributions of V-sink tokens and the remaining visual tokens in identified functional layers.
If this is right
- LSG improves performance on multimodal benchmarks by balancing global reasoning and local evidence.
- Modulation in specific layers most significantly affects downstream tasks.
- Sinks provide global priors that are beneficial when not over-dominant.
- The module trains with standard next-token prediction without task-specific labels or backbone changes.
Where Pith is reading between the lines
- The gating technique could extend to other attention-heavy multimodal architectures to correct scale biases in perception.
- Similar sink phenomena might appear in pure vision or language transformers and require analogous fixes for balanced detail.
- The global-local trade-off points to a general property of attention mechanisms that prioritize broad context over details unless explicitly adjusted.
Load-bearing premise
The functional layers for effective sink modulation are consistent across various LVLM architectures, and the global-local attention balance is the main factor behind observed performance improvements.
What would settle it
If LSG applied to an unseen LVLM architecture fails to improve local perception tasks or harms global reasoning on benchmarks, the layer-specific trade-off claim would not hold.
Figures



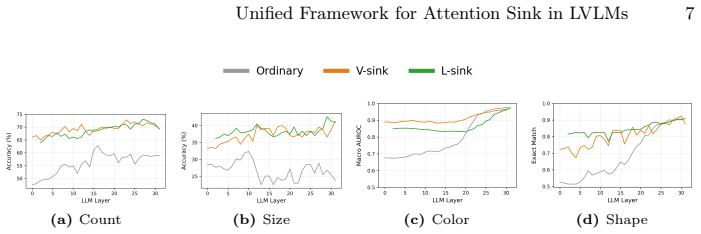

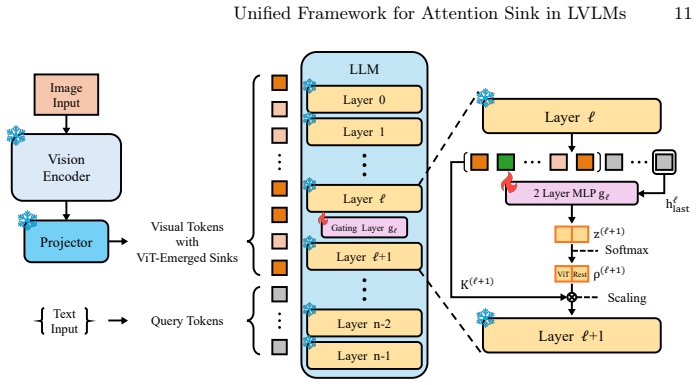

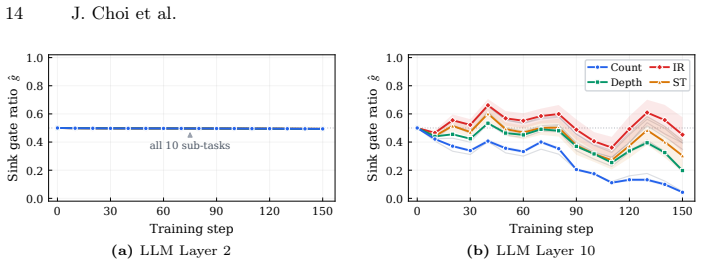
read the original abstract
Attention sinks are defined as tokens that attract disproportionate attention. While these have been studied in single modality transformers, their cross-modal impact in Large Vision-Language Models (LVLM) remains largely unexplored: are they redundant artifacts or essential global priors? This paper first categorizes visual sinks into two distinct categories: ViT-emerged sinks (V-sinks), which propagate from the vision encoder, and LLM-emerged sinks (L-sinks), which arise within deep LLM layers. Based on the new definition, our analysis reveals a fundamental performance trade-off: while sinks effectively encode global scene-level priors, their dominance can suppress the fine-grained visual evidence required for local perception. Furthermore, we identify specific functional layers where modulating these sinks most significantly impacts downstream performance. To leverage these insights, we propose Layer-wise Sink Gating (LSG), a lightweight, plug-and-play module that dynamically scales the attention contributions of V-sink and the rest visual tokens. LSG is trained via standard next-token prediction, requiring no task-specific supervision while keeping the LVLM backbone frozen. In most layers, LSG yields improvements on representative multimodal benchmarks, effectively balancing global reasoning and precise local evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper categorizes attention sinks in LVLM into ViT-emerged V-sinks and LLM-emerged L-sinks, argues for a fundamental trade-off in which sinks encode global scene priors but can suppress fine-grained local visual evidence, identifies specific functional layers where modulation matters most, and introduces a lightweight Layer-wise Sink Gating (LSG) module that dynamically scales sink versus non-sink visual token contributions; LSG is trained only with next-token prediction on a frozen backbone and is reported to improve representative multimodal benchmarks.
Significance. If the trade-off and layer-specific effects are causally confirmed and the reported gains hold under controlled evaluation, the work would supply a practical, plug-and-play mechanism for balancing global and local perception in multimodal transformers without backbone retraining, together with a unified taxonomy that could guide future attention analyses across vision-language architectures.
major comments (2)
- Abstract and §4 (empirical section): the central claims of a 'fundamental performance trade-off' and 'improvements on representative multimodal benchmarks' are stated without any quantitative results, tables, error analysis, ablation details, or experimental protocol, leaving the empirical support for the trade-off and LSG efficacy invisible.
- §3 (analysis of sink dominance): the claim that sink dominance suppresses fine-grained local evidence rests on observational attention-pattern correlations; no interventional experiment (targeted scaling or masking of V-sinks/L-sinks in the identified layers while holding other tokens fixed) is described to isolate the causal effect on local-perception metrics.
minor comments (1)
- Notation: the distinction between V-sinks and L-sinks is introduced in the abstract but the precise mathematical definition (e.g., attention-mass threshold or layer index) is not stated explicitly before the LSG equations.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will revise the manuscript to improve clarity and strengthen the empirical support.
read point-by-point responses
-
Referee: Abstract and §4 (empirical section): the central claims of a 'fundamental performance trade-off' and 'improvements on representative multimodal benchmarks' are stated without any quantitative results, tables, error analysis, ablation details, or experimental protocol, leaving the empirical support for the trade-off and LSG efficacy invisible.
Authors: We agree that the abstract and opening of §4 should make the quantitative support immediately visible. The full manuscript does contain tables in §4 reporting benchmark gains (e.g., +1.8–4.2 points on VQA v2, GQA, and RefCOCO under the frozen-backbone setting) together with layer-wise ablations, but these numbers are not summarized early enough. We will revise the abstract to include the key deltas and error bars, add a concise experimental-protocol paragraph at the start of §4, and expand the ablation table to show per-layer LSG effects and standard deviations across three random seeds. revision: yes
-
Referee: §3 (analysis of sink dominance): the claim that sink dominance suppresses fine-grained local evidence rests on observational attention-pattern correlations; no interventional experiment (targeted scaling or masking of V-sinks/L-sinks in the identified layers while holding other tokens fixed) is described to isolate the causal effect on local-perception metrics.
Authors: The current §3 analysis is indeed correlational, relying on attention-map statistics and layer-wise sink dominance scores. To establish causality we will add a controlled intervention subsection: for the layers identified as most sensitive, we will (i) zero-out or scale the V-sink and L-sink attention weights while keeping all other token contributions fixed, and (ii) measure the resulting change in accuracy on local-perception tasks (RefCOCO, TextVQA). These results will be reported alongside the original observational plots. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines V-sinks and L-sinks from observed attention patterns in the vision encoder and LLM layers, then reports an empirical trade-off between global priors and local evidence suppression based on layer-wise analysis. The LSG module is introduced as a separate lightweight gating mechanism trained independently via next-token prediction on a frozen backbone with no task-specific labels. No equations, definitions, or self-citations reduce the reported benchmark improvements or the identified functional layers back to the input analysis by construction; the central claims rest on external multimodal benchmarks rather than self-referential fitting or renaming. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention sinks in LVLM can be distinctly categorized as ViT-emerged (V-sinks) and LLM-emerged (L-sinks)
invented entities (1)
-
Layer-wise Sink Gating (LSG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
while sinks effectively encode global scene-level priors, their dominance can suppress the fine-grained visual evidence required for local perception... LSG yields improvements on representative multimodal benchmarks, effectively balancing global reasoning and precise local evidence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: others. 2025. qwen2. 5-vl technical report. arXiv preprint arXiv:2502.139234(5) (1)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
IEEE Transactions on Image Processing (2025) 16 J
Bai, S., Liu, Y., Han, Y., Zhang, H., Tang, Y., Zhou, J., Lu, J.: Self-calibrated clip for training-free open-vocabulary segmentation. IEEE Transactions on Image Processing (2025) 16 J. Choi et al
work page 2025
-
[3]
Cancedda, N.: Spectral filters, dark signals, and attention sinks, 2024. URL https://arxiv. org/abs/2402.09221 (2024)
-
[4]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., et al.: Are we on the right way for evaluating large vision- language models? Advances in Neural Information Processing Systems37, 27056– 27087 (2024)
work page 2024
-
[5]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., Jitsev, J.: Reproducible scaling laws for contrastive language-image learning. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 2818–2829 (2023)
work page 2023
-
[6]
In: The Twelfth International Conference on Learning Representations (2024)
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need regis- ters. In: The Twelfth International Conference on Learning Representations (2024)
work page 2024
-
[7]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Feucht, S., Atkinson, D., Wallace, B.C., Bau, D.: Token erasure as a footprint of implicit vocabulary items in llms. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 9727–9739 (2024)
work page 2024
-
[8]
In: Second Conference on Language Modeling (2025)
Fu, S., Guillory, D., Darrell, T., et al.: Hidden in plain sight: Vlms overlook their visual representations. In: Second Conference on Language Modeling (2025)
work page 2025
-
[9]
In: Proceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing
Geva, M., Bastings, J., Filippova, K., Globerson, A.: Dissecting recall of factual associations in auto-regressive language models. In: Proceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing. pp. 12216–12235 (2023)
work page 2023
-
[10]
In: The Thirteenth International Conference on Learning Representations (2025)
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y., Lin, M.: When attention sink emerges in language models: An empirical view. In: The Thirteenth International Conference on Learning Representations (2025)
work page 2025
-
[11]
arXiv preprint arXiv:2505.11739 (2025)
Han, F., Yu, X., Tang, J., Rao, D., Du, W., Ungar, L.: Zerotuning: Unlocking the initial token’s power to enhance large language models without training. arXiv preprint arXiv:2505.11739 (2025)
-
[12]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
work page 2022
-
[13]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
work page 2019
-
[14]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Jiang, N., Dravid, A., Efros, A.A., Gandelsman, Y.: Vision transformers don’t need trained registers. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kaduri, O., Bagon, S., Dekel, T.: What’s in the image? a deep-dive into the vision of vision language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14549–14558 (2025)
work page 2025
-
[16]
In: The Fourteenth International Conference on Learning Representations (2026)
Kan, Z., Li, X., Liu, Y., Yang, X., Jiang, X., Liu, Y., Jiang, D., Sun, X., Liao, Q., Yang, W.: Rar: Reversing visual attention re-sinking for unlocking potential in multimodal large language models. In: The Fourteenth International Conference on Learning Representations (2026)
work page 2026
-
[17]
In: The Thirteenth International Conference on Learning Representations (2025)
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. In: The Thirteenth International Conference on Learning Representations (2025)
work page 2025
-
[18]
In: Mechanistic Interpretability Workshop at NeurIPS 2025 (2025)
Kim, J., Kang, S., Park, J., Kim, J., Hwang, S.J.: Interpreting attention heads for image-to-text information flow in large vision–language models. In: Mechanistic Interpretability Workshop at NeurIPS 2025 (2025)
work page 2025
-
[19]
Lappe, A., Giese, M.A.: Register and [cls] tokens induce a decoupling of local and global features in large vits. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) Unified Framework for Attention Sink in LVLMs 17
work page 2025
-
[20]
Transactions on Machine Learning Research (2024)
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. Transactions on Machine Learning Research (2024)
work page 2024
-
[21]
Transactions on Machine Learning Research (2025)
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. Transactions on Machine Learning Research (2025)
work page 2025
-
[22]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
work page 2023
-
[23]
In: The Fourteenth International Conference on Learning Representations (2026)
Liu, X., Chen, G., Wang, W.: Sinktrack: Attention sink based context anchoring for large language models. In: The Fourteenth International Conference on Learning Representations (2026)
work page 2026
-
[24]
Science China Information Sciences67(12), 220102 (2024)
Liu, Y., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.C., Liu, C.L., Jin, L., Bai, X.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences67(12), 220102 (2024)
work page 2024
-
[25]
arXiv preprint arXiv:2507.16018 (2025)
Lu, A., Liao, W., Wang, L., Yang, H., Shi, J.: Artifacts and attention sinks: Structured approximations for efficient vision transformers. arXiv preprint arXiv:2507.16018 (2025)
-
[26]
In: The Twelfth International Conference on Learning Representations (2024)
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In: The Twelfth International Conference on Learning Representations (2024)
work page 2024
-
[27]
arXiv preprint arXiv:2510.08510 (2025)
Luo, J., Fan, W.C., Wang, L., He, X., Rahman, T., Abolmaesumi, P., Sigal, L.: To sink or not to sink: Visual information pathways in large vision-language models. arXiv preprint arXiv:2510.08510 (2025)
-
[28]
In: The Eleventh International Conference on Learning Representa- tions (2023)
Merullo, J., Castricato, L., Eickhoff, C., Pavlick, E.: Linearly mapping from image to text space. In: The Eleventh International Conference on Learning Representa- tions (2023)
work page 2023
-
[29]
In: The Thirteenth International Conference on Learning Representations (2025)
Neo, C., Ong, L., Torr, P., Geva, M., Krueger, D., Barez, F.: Towards interpret- ing visual information processing in vision-language models. In: The Thirteenth International Conference on Learning Representations (2025)
work page 2025
-
[30]
Transactions on Machine Learning Research Journal (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal (2024)
work page 2024
-
[31]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[32]
What are you sink- ing? a geometric approach on attention sink.arXiv preprint arXiv:2508.02546,
Ruscio, V., Nanni, U., Silvestri, F.: What are you sinking? a geometric approach on attention sink. arXiv preprint arXiv:2508.02546 (2025)
-
[33]
arXiv preprint arXiv:2509.24791 (2025)
Shi, C., Yu, Y., Yang, S.: Vision function layer in multimodal llms. arXiv preprint arXiv:2509.24791 (2025)
-
[34]
arXiv preprint arXiv:2507.09071 (2025)
Srikrishnan, T.A., Shah, D., Reinhardt, S.K.: Blindsight: Harnessing sparsity for efficient vlms. arXiv preprint arXiv:2507.09071 (2025)
-
[35]
arXiv preprint arXiv:2508.04257 (2025)
Su, Z., Yuan, K.: Kvsink: Understanding and enhancing the preservation of at- tention sinks in kv cache quantization for llms. arXiv preprint arXiv:2508.04257 (2025)
-
[36]
Sun, M., Chen, X., Kolter, J.Z., Liu, Z.: Massive activations in large language models. arXiv preprint arXiv:2402.17762 (2024) 18 J. Choi et al
-
[37]
Advances in Neural Information Processing Systems 37, 87310–87356 (2024)
Tong, P., Brown, E., Wu, P., Woo, S., Iyer, A.J.V., Akula, S.C., Yang, S., Yang, J., Middepogu, M., Wang, Z., et al.: Cambrian-1: A fully open, vision-centric ex- ploration of multimodal llms. Advances in Neural Information Processing Systems 37, 87310–87356 (2024)
work page 2024
-
[38]
In: European con- ference on computer vision
Touvron, H., Cord, M., Jégou, H.: Deit iii: Revenge of the vit. In: European con- ference on computer vision. pp. 516–533. Springer (2022)
work page 2022
-
[39]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Wang, Q., Hu, J., Jiang, M.: V-seam: Visual semantic editing and attention mod- ulating for causal interpretability of vision-language models. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 17407–17431 (2025)
work page 2025
-
[41]
In: 34th USENIX Security Symposium (USENIX Security 25)
Wang, Y., Zhang, M., Sun, J., Wang, C., Yang, M., Xue, H., Tao, J., Duan, R., Liu, J.: Mirage in the eyes: Hallucination attack on multi-modal large language models with only attention sink. In: 34th USENIX Security Symposium (USENIX Security 25). pp. 3707–3726 (2025)
work page 2025
-
[42]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., et al.: Qwen2 technical report. arXiv preprint arXiv:2407.10671 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
arXiv preprint arXiv:2406.15765 (2024)
Yu, Z., Wang, Z., Fu, Y., Shi, H., Shaikh, K., Lin, Y.C.: Unveiling and harnessing hidden attention sinks: Enhancing large language models without training through attention calibration. arXiv preprint arXiv:2406.15765 (2024)
-
[46]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
work page 2023
-
[47]
Zhao, Q., Xu, M., Gupta, K., Asthana, A., Zheng, L., Gould, S.: The first to know: How token distributions reveal hidden knowledge in large vision-language models? In: European Conference on Computer Vision. pp. 127–142. Springer (2024) Unified Framework for Attention Sink in LVLMs S1 Supplementary Materials This supplement is organized as follows. – Sect...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.