Recognition: no theorem link
Bridging the Dimensionality Gap: A Taxonomy and Survey of 2D Vision Model Adaptation for 3D Analysis
Pith reviewed 2026-05-13 20:23 UTC · model grok-4.3
The pith
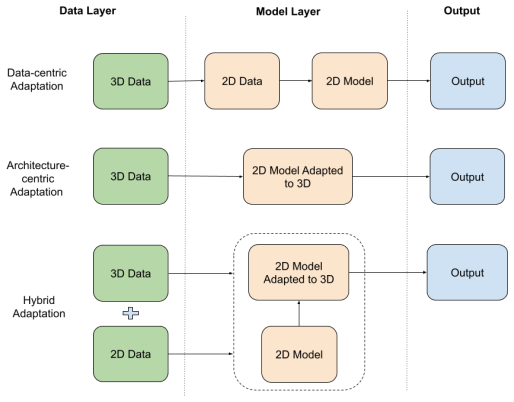
Adaptation of 2D vision models to 3D data analysis can be organized into data-centric, architecture-centric, and hybrid families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the gap between dense 2D grids and sparse 3D structures can be bridged by classifying adaptation methods into data-centric projections to leverage existing 2D models, architecture-centric designs for native 3D processing, and hybrid approaches that merge visual priors from 2D data with geometric reasoning from 3D models, while analyzing their respective trade-offs in complexity, pre-training reliance, and preservation of geometric inductive biases.
What carries the argument
The unified three-family taxonomy of adaptation strategies, which serves to classify existing methods and highlight their fundamental trade-offs.
If this is right
- Data-centric approaches enable immediate use of powerful pre-trained 2D models but risk losing explicit 3D geometric information.
- Architecture-centric methods better preserve geometric properties but often demand training from scratch without large-scale pre-training benefits.
- Hybrid methods aim to capture advantages from both but introduce additional design and integration challenges.
- Advancements in self-supervised learning for geometric data could reduce reliance on labeled 3D datasets across all families.
- Development of 3D foundation models would likely build on hybrid paradigms to scale up performance.
Where Pith is reading between the lines
- If the taxonomy is complete, new methods could be evaluated by seeing which family they best fit or extend.
- Practitioners might select methods based on whether their priority is speed, accuracy on geometry, or use of existing models.
- Connections to multi-modal integration suggest potential for combining vision with other signals like depth or language in future hybrids.
- Empirical testing of the trade-offs on standardized 3D benchmarks could validate or refine the described characterizations.
Load-bearing premise
The three-family taxonomy is exhaustive and the trade-offs in computational complexity, pre-training reliance, and geometric bias preservation are accurately characterized across the surveyed literature.
What would settle it
Discovery of an adaptation strategy that cannot be classified into data-centric, architecture-centric, or hybrid categories, or experimental evidence showing trade-offs different from those described, would challenge the taxonomy.
Figures

read the original abstract
The remarkable success of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in 2D vision has spurred significant research in extending these architectures to the complex domain of 3D analysis. Yet, a core challenge arises from a fundamental dichotomy between the regular, dense grids of 2D images and the irregular, sparse nature of 3D data such as point clouds and meshes. This survey provides a comprehensive review and a unified taxonomy of adaptation strategies that bridge this gap, classifying them into three families: (1) Data-centric methods that project 3D data into 2D formats to leverage off-the-shelf 2D models, (2) Architecture-centric methods that design intrinsic 3D networks, and (3) Hybrid methods, which synergistically combine the two modeling paradigms to benefit from both rich visual priors of large 2D datasets and explicit geometric reasoning of 3D models. Through this framework, we qualitatively analyze the fundamental trade-offs between these families concerning computational complexity, reliance on large-scale pre-training, and the preservation of geometric inductive biases. We discuss key open challenges and outline promising future research directions, including the development of 3D foundation models, advancements in self-supervised learning (SSL) for geometric data, and the deeper integration of multi-modal signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys strategies for adapting successful 2D vision models (CNNs and ViTs) to 3D analysis tasks on irregular data such as point clouds and meshes. It proposes a unified taxonomy that partitions adaptation methods into three families—data-centric (projecting 3D data into 2D formats), architecture-centric (designing intrinsic 3D networks), and hybrid (combining both paradigms)—and qualitatively examines trade-offs in computational complexity, reliance on large-scale pre-training, and preservation of geometric inductive biases. The manuscript also outlines open challenges and future directions including 3D foundation models and self-supervised learning for geometric data.
Significance. If the taxonomy accurately organizes the literature and the qualitative trade-off characterizations are representative, the survey supplies a practical organizational lens that can help researchers select and combine adaptation strategies. It highlights concrete directions (multi-modal integration, SSL for geometry) that align with current trends toward foundation models in vision.
major comments (1)
- [Abstract and §1] Abstract and §1: The central claim that the three-family taxonomy is exhaustive and that the described trade-offs (complexity, pre-training reliance, geometric bias) are comprehensively characterized rests on the authors' literature selection. A table or subsection enumerating coverage of representative works (e.g., PointNet-style methods, recent 3D transformers, multi-view projection baselines) would allow readers to assess whether boundary cases or rapidly evolving lines of work are omitted.
minor comments (2)
- [Taxonomy sections] The qualitative trade-off analysis would be clearer if each family section included a short summary paragraph or bullet list of the dominant complexity and bias characteristics before moving to examples.
- Figure illustrating the taxonomy (if present) should explicitly label representative methods under each family to aid quick comprehension.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central claim that the three-family taxonomy is exhaustive and that the described trade-offs (complexity, pre-training reliance, geometric bias) are comprehensively characterized rests on the authors' literature selection. A table or subsection enumerating coverage of representative works (e.g., PointNet-style methods, recent 3D transformers, multi-view projection baselines) would allow readers to assess whether boundary cases or rapidly evolving lines of work are omitted.
Authors: We agree that explicitly enumerating representative works would improve transparency and allow readers to better evaluate the taxonomy's coverage and the representativeness of the qualitative trade-off analysis. In the revised manuscript we will add a new table (placed in §1) that systematically lists key examples from each family, including PointNet-style architectures and recent 3D transformers under architecture-centric methods, multi-view projection baselines under data-centric methods, and representative hybrid approaches. The table will also cross-reference the trade-offs in computational complexity, pre-training reliance, and geometric inductive bias discussed in the text. This addition clarifies scope without altering the three-family taxonomy itself. revision: yes
Circularity Check
No significant circularity: survey taxonomy is organizational, not derived
full rationale
The manuscript is a literature survey that proposes a three-family taxonomy (data-centric projection, architecture-centric 3D networks, hybrid) as an organizing lens for existing work. No equations, fitted parameters, predictions, or deductive derivations appear. All claims reference external papers; the taxonomy itself is presented as a useful classification rather than a result forced by self-citation or self-definition. Central trade-off analysis is qualitative and drawn from the cited literature, with no reduction to the authors' own prior outputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Afham, M., Dissanayake, I., Dissanayake, D., Dharmasiri, A., Thilakarathna, K., and Rodrigo, R. (2022). Cross- point: Self-supervised cross-modal contrastive learn- ing for 3d point cloud understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9902–9912. Alaba, S. Y . and Ball, J. E. (2022). A survey on de...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
S., Geiger, M., K ¨ohler, J., and Welling, M
Cohen, T. S., Geiger, M., K ¨ohler, J., and Welling, M. (2018). Spherical cnns. InInternational Conference on Learning Representations. Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei- Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Com- puter Vision and Pattern Recognition, pages 248–255. Dong, R....
-
[3]
Lai, X., Liu, J., Jiang, L., Wang, L., Zhao, H., Liu, S., and Jia, J. (2022). Stratified transformer for 3d point cloud segmentation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 8500–8509. Lang, A. H., V ora, S., Caesar, H., Zhou, L., Yang, J., and Beijbom, O. (2019). Pointpillars: Fast encoders for object ...
-
[4]
W., Meng, T., Caine, B., Ngiam, J., Peng, D., and Tan, M
Li, Y ., Yu, A. W., Meng, T., Caine, B., Ngiam, J., Peng, D., and Tan, M. (2022a). Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17182–17191. Li, Z., Chen, Z., Li, A., Fang, L., Jiang, Q., Liu, X., and Zhao, H. (2022b). Simipu: Simple 2...
-
[5]
Qian, G., Zhang, X., Hamdi, A., and Ghanem, B. (2022). Pix4point: Image pretrained transformers for 3d point cloud understanding. InEuropean Conference on Computer Vision, pages 657–675. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. (2021). Learning transferable visual models...
work page 2022
-
[6]
Sindagi, V . A., Zhou, Y ., and Tuzel, O. (2019). Mvx-net: Multimodal voxelnet for 3d object detection. pages 7276–7282. Su, H., Maji, S., Kalogerakis, E., and Learned-Miller, E. (2015). Multi-view convolutional neural networks for 3d shape recognition. InProceedings of the IEEE International Conference on Computer Vision, pages 945–953. Tang, Y ., Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
Wu, B., Wan, A., Yue, X., and Keutzer, K. (2018). Squeeze- seg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1887–1893. Wu, Z., Li, Y ., Huang, Y ., Gu, L., Harada, T., and Sato, H. (2022). 3d segmenter: 3d transf...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.