From Model-Based Screening to Data-Driven Surrogates: A Multi-Stage Workflow for Exploring Stochastic Agent-Based Models
Pith reviewed 2026-05-13 19:44 UTC · model grok-4.3
The pith
A multi-stage pipeline of automated screening followed by machine learning surrogates allows systematic exploration of high-dimensional stochastic agent-based models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
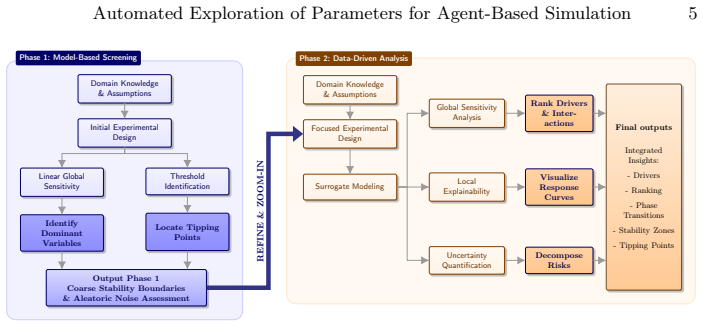
Using a predator-prey case study, the methodology shows that integrating the systematic design of experiments with machine learning surrogates in a multi-stage pipeline identifies dominant variables and segments the parameter space in the first step, then trains models to capture nonlinear interactions in the second step, thereby discovering unstable regions automatically.
What carries the argument
The two-stage pipeline where automated model-based screening identifies dominant variables and segments the parameter space before machine learning surrogates model nonlinear effects.
If this is right
- The framework provides modelers with a rigorous hands-off method for sensitivity analysis.
- Unstable regions in stochastic ABMs can be discovered without manual parameter tuning.
- Policy testing becomes feasible even for high-dimensional simulators.
- Outcome variability is assessed systematically during the screening phase.
Where Pith is reading between the lines
- This method could be tested on ABMs from fields like epidemiology or economics to see if similar unstable regions are found.
- The segmented spaces might allow for more targeted data collection in future simulations.
- Hybrid approaches like this may generalize to other types of stochastic models beyond agents.
Load-bearing premise
The automated model-based screening step can reliably identify dominant variables and segment the parameter space despite the inherent stochasticity of the agent-based simulator.
What would settle it
Running multiple instances of the screening on the predator-prey model with varied random seeds and checking if the identified dominant variables and unstable regions remain consistent across runs.
Figures
read the original abstract
Systematic exploration of Agent-Based Models (ABMs) is challenged by the curse of dimensionality and their inherent stochasticity. We present a multi-stage pipeline integrating the systematic design of experiments with machine learning surrogates. Using a predator-prey case study, our methodology proceeds in two steps. First, an automated model-based screening identifies dominant variables, assesses outcome variability, and segments the parameter space. Second, we train Machine Learning models to map the remaining nonlinear interaction effects. This approach automates the discovery of unstable regions where system outcomes are highly dependent on nonlinear interactions between many variables. Thus, this work provides modelers with a rigorous, hands-off framework for sensitivity analysis and policy testing, even when dealing with high-dimensional stochastic simulators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multi-stage workflow for systematic exploration of stochastic agent-based models (ABMs). It begins with an automated model-based screening step that identifies dominant variables, assesses outcome variability, and segments the parameter space, followed by training machine learning surrogates to capture remaining nonlinear interaction effects. The approach is demonstrated on a predator-prey case study that incorporates multiple replicates to handle stochasticity and uses variance-aware segmentation. The central claim is that this pipeline supplies modelers with a rigorous, hands-off framework for sensitivity analysis and policy testing in high-dimensional stochastic simulators.
Significance. If the reported results hold, the workflow addresses a practical challenge in ABM analysis by automating sensitivity screening and surrogate construction in the presence of stochasticity and high dimensionality. The explicit use of replicates and variance-aware segmentation in the predator-prey case study is a constructive element that could improve reliability over purely deterministic screening methods. The combination of model-based and data-driven stages offers a potentially useful template for modelers working with complex simulators where exhaustive enumeration is infeasible.
minor comments (3)
- [Abstract] Abstract: the summary states that the workflow 'automates the discovery of unstable regions' but supplies no quantitative metrics (e.g., surrogate prediction error, fraction of parameter space identified as unstable, or comparison against exhaustive sampling) from the predator-prey case study; adding one or two such numbers would strengthen the abstract.
- [Methodology] Methodology section: the description of the ML surrogate training step should specify the exact algorithms (e.g., random forest, Gaussian process, neural network), hyperparameter selection procedure, and any cross-validation or uncertainty quantification used to ensure the surrogates faithfully reproduce the segmented nonlinear effects.
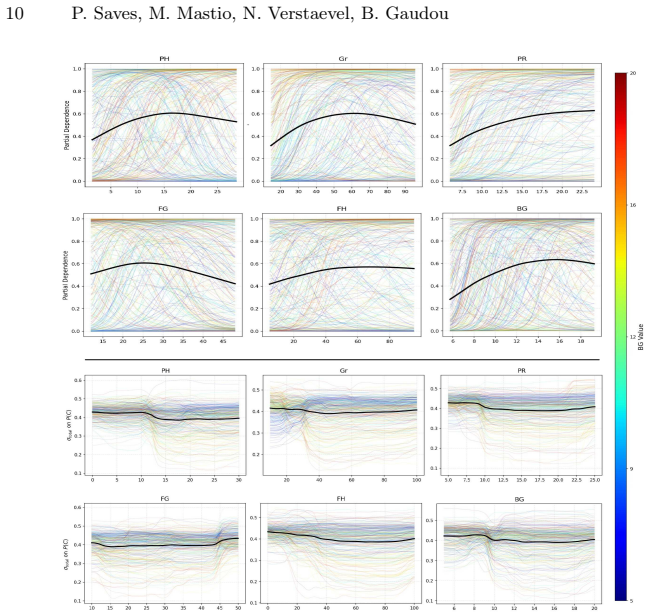
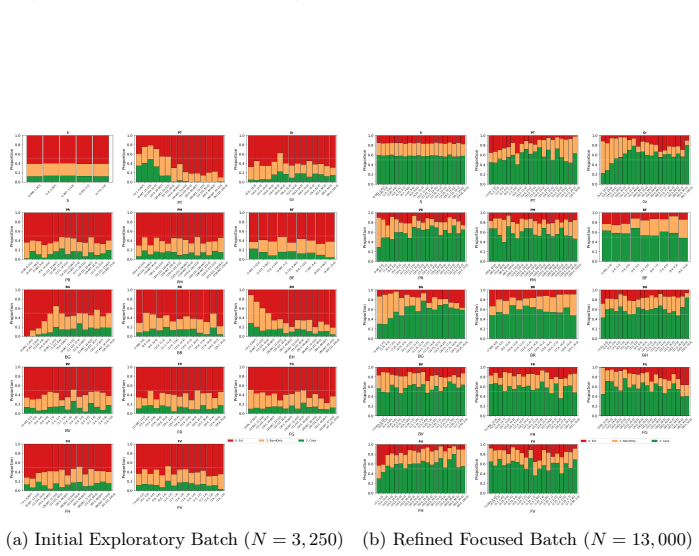
- [Case Study] Case-study results: figures showing segmented parameter regions would benefit from explicit statistical summaries (mean, variance, and replicate count per segment) and a direct comparison of screening runtime versus full-factorial enumeration to quantify the claimed efficiency gain.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the workflow's practical value in handling stochasticity and high dimensionality, and recommendation for minor revision. The explicit use of replicates and variance-aware segmentation is indeed central to reliability, and we are glad this was noted as a constructive element.
Circularity Check
No significant circularity in the multi-stage workflow
full rationale
The paper describes a forward methodological pipeline: automated model-based screening to identify dominant variables and segment parameter space, followed by training ML surrogates on the reduced space. No equations, derivations, or fitted quantities are presented that reduce by construction to inputs defined within the same pipeline. The predator-prey case study is used to illustrate the workflow with explicit handling of stochasticity via replicates, providing independent empirical support rather than self-referential definitions or load-bearing self-citations. The central claim of a hands-off framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Automated model-based screening can reliably identify dominant variables and segment the parameter space in the presence of stochasticity.
- domain assumption Machine-learning surrogates can accurately capture nonlinear interaction effects once the parameter space has been segmented.
Reference graph
Works this paper leans on
-
[1]
Angione, C., Silverman, E., Yaneske, E.: Using machine learning as a surrogate model for agent-based simulations. PLOS One17(2022)
work page 2022
-
[2]
In: Agent-based Spatial Simulation with NetLogo, pp
Banos, A., Caillou, P., Gaudou, B., Marilleau, N.: Agent-based model exploration. In: Agent-based Spatial Simulation with NetLogo, pp. 125–181. Elsevier (2015)
work page 2015
-
[3]
SAR and QSAR in Environmental Re- search17(3), 337–352 (2006)
Chen, J.J., Tsai, C.A., Moon, H., Ahn, H., Young, J.J., Chen, C.H.: Decision threshold adjustment in class prediction. SAR and QSAR in Environmental Re- search17(3), 337–352 (2006)
work page 2006
-
[4]
De Bosscher, B., Ziabari, S.S.M., Sharpanskykh, A.: Towards a better understand- ing of agent-based airport terminal operations using surrogate modeling. In: MABS (2023)
work page 2023
-
[5]
journal of Computational and Graphical Statistics24(1), 44–65 (2015)
Goldstein, A., Kapelner, A., Bleich, J., Pitkin, E.: Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. journal of Computational and Graphical Statistics24(1), 44–65 (2015)
work page 2015
-
[6]
Goodfellow, I.: Deep learning (2016)
work page 2016
-
[7]
In: Individual- based modeling and ecology
Grimm, V., Railsback, S.F.: Individual-based modeling and ecology. In: Individual- based modeling and ecology. Princeton university press (2013)
work page 2013
-
[8]
Machine learning110(3), 457– 506 (2021)
Hüllermeier, E., Waegeman, W.: Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine learning110(3), 457– 506 (2021)
work page 2021
-
[9]
Iooss, B., Lemaître, P.: A review on global sensitivity analysis methods. Uncer- tainty management in simulation-optimization of complex systems: algorithms and applications pp. 101–122 (2015)
work page 2015
-
[10]
Lamperti, F., Mandel, A., Napoletano, M., Sapio, A., Roventini, A., Balint, T., Khorenzhenko, I.: Towards agent-based integrated assessment models: examples, challenges, and future developments. Reg. Env. Change19(3), 747–762 (2019)
work page 2019
-
[11]
In: Pro- ceedings of AAMAS 2026
Mastio, M., Saves, P., Gaudou, B., Verstaevel, N.: Adaptive agents in spatial double-auction markets: Modeling the emergence of industrial symbiosis. In: Pro- ceedings of AAMAS 2026. vol. 2026, pp. 1–10. IFAAMAS (2026)
work page 2026
-
[12]
Montgomery, D.C.: Design and analysis of experiments. John wiley & sons (2017)
work page 2017
-
[13]
Novak, M., Wilensky, U.: NetLogo Bug Hunt Predators and Invasive Species (2011)
work page 2011
-
[14]
Princeton university press (2019)
Railsback, S.F., Grimm, V.: Agent-based and individual-based modeling: a practi- cal introduction. Princeton university press (2019)
work page 2019
-
[15]
Saves, P., Hallé-Hannan, E., Bussemaker, J., Diouane, Y., Bartoli, N.: Modeling hi- erarchical spaces: A review and unified framework for surrogate-based architecture design. Structural and Multidisciplinary Optimization (2026) Automated Exploration of Parameters for Agent-Based Simulation 13
work page 2026
-
[16]
arXiv preprint arXiv:2510.16742;2025 (2025)
Saves, P., Palar, P.S., Robani, M.D., Verstaevel, N., Garouani, M., Aligon, J., Gau- dou, B., Shimoyama, K., Morlier, J.: Surrogate modeling and explainable artificial intelligence for complex systems: A workflow for automated simulation exploration. arXiv preprint arXiv:2510.16742;2025 (2025)
-
[17]
Journal of Machine Learn- ing Research9(3) (2008)
Shafer, G., Vovk, V.: A tutorial on conformal prediction. Journal of Machine Learn- ing Research9(3) (2008)
work page 2008
-
[18]
Journal of Artificial Societies and Social Simulation17(3), 11 (2014)
Thiele, J.C., Kurth, W., Grimm, V.: Facilitating parameter estimation and sensi- tivity analysis of agent-based models: A cookbook using NetLogo and R. Journal of Artificial Societies and Social Simulation17(3), 11 (2014)
work page 2014
- [19]
-
[20]
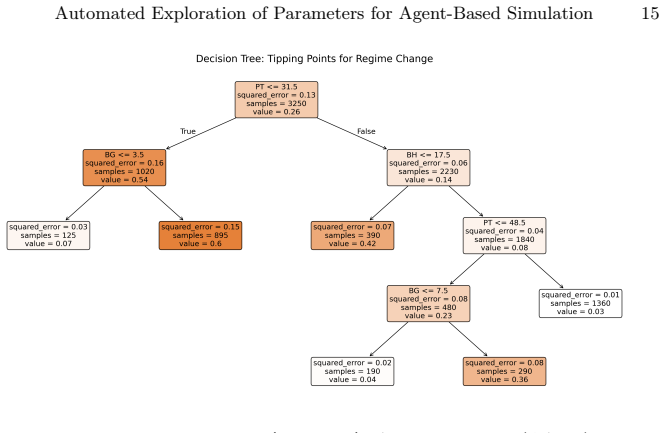
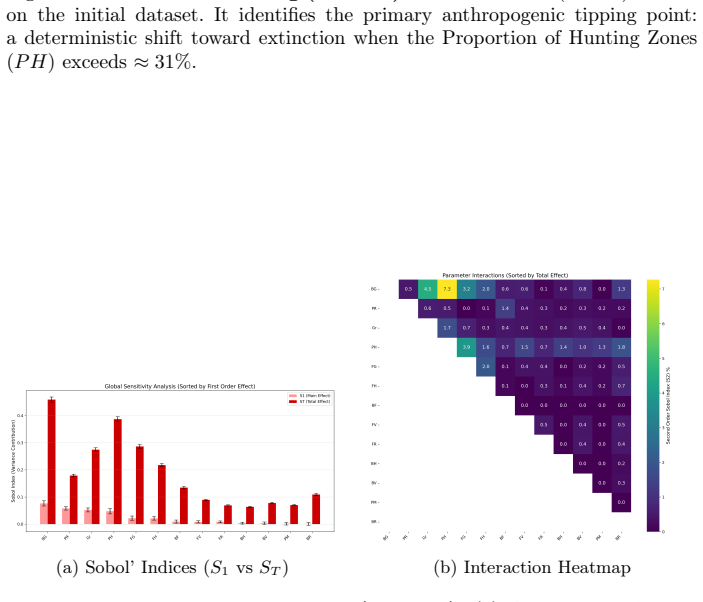
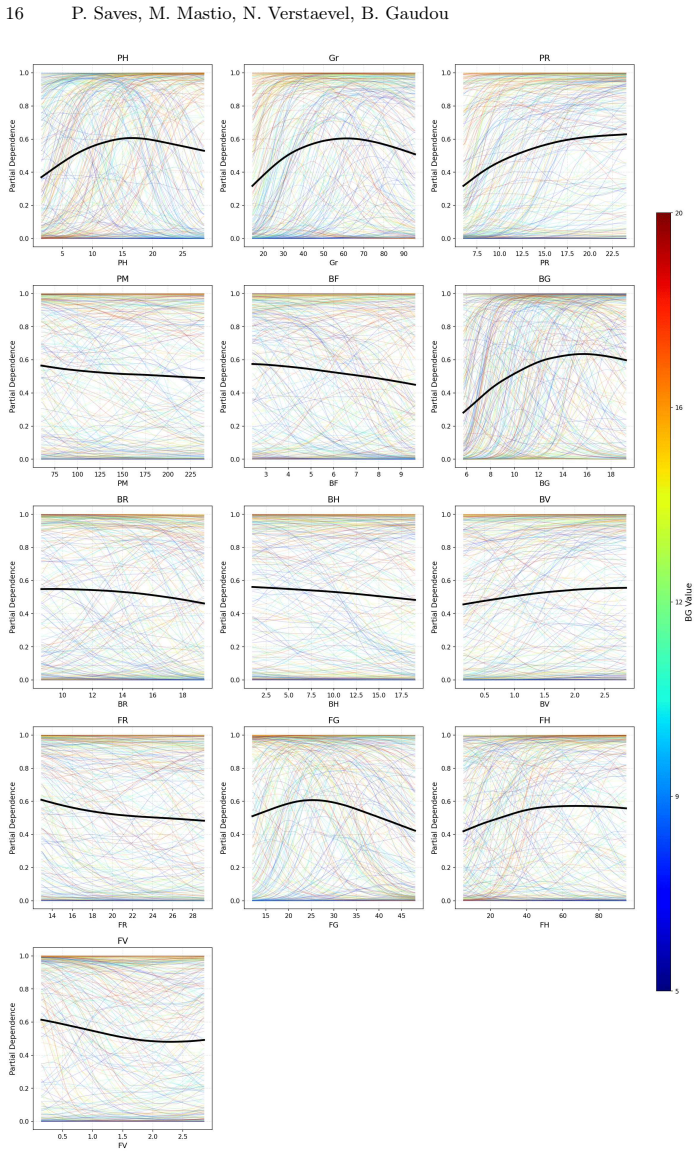
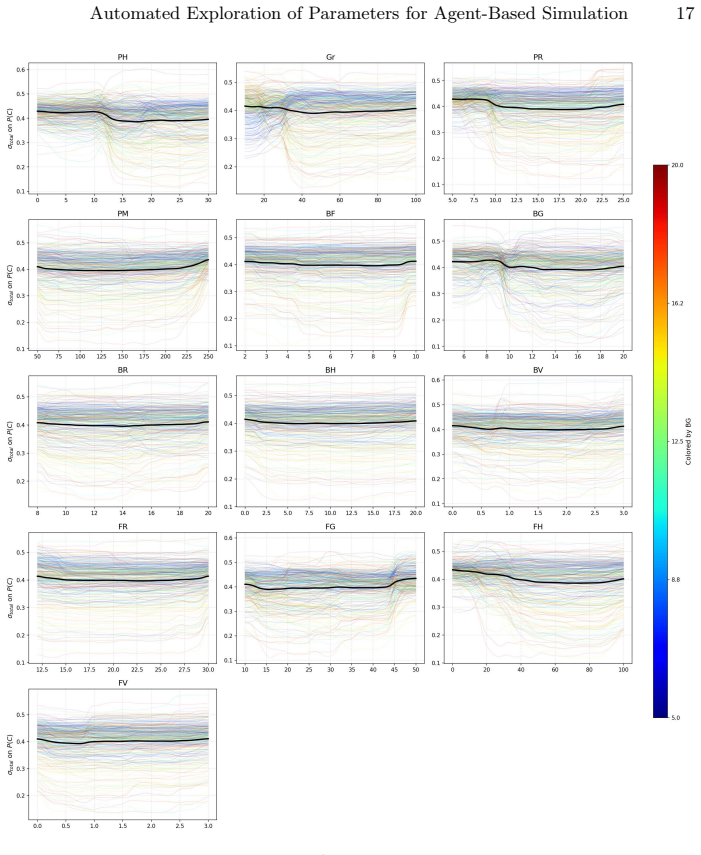
Wilensky, U.: Netlogo: Center for connected learning and computer-based model- ing. Northwestern University, Evanston, IL4952(1999) 14 P. Saves, M. Mastio, N. Verstaevel, B. Gaudou Supplementary Materials: Generated Figures Fig.3: Simulation results showing the relationship between variables X and Y. (a) Initial Exploratory Batch (N= 3,250) (b) Refined Fo...
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.