Recognition: 1 theorem link
· Lean TheoremABTest: Behavior-Driven Testing for AI Coding Agents
Pith reviewed 2026-05-13 18:32 UTC · model grok-4.3
The pith
ABTest converts 400 real user-reported failures into 647 executable tests that flag 1,573 anomalies across three AI coding agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ABTest (1) mines user-reported anomalies to derive 47 Interaction Patterns and 128 Action types, (2) composes them into stepwise fuzzing templates, (3) instantiates executable test cases in real repositories, (4) executes them against coding agents while recording traces, and (5) detects and validates anomalous behaviors. Applied to 400 developer-confirmed failures, the framework generates 647 repository-grounded cases whose execution flags 1,573 anomalies, 642 of which are manually confirmed as new true anomalies at 40.8 percent precision.
What carries the argument
Interaction Patterns and Action types mined from user-reported anomalies, composed into stepwise fuzzing templates that are instantiated as executable test cases inside real repositories.
If this is right
- ABTest exposes measurable robustness differences among distinct coding-agent families when the same test bundle is executed.
- The framework surfaces failure modes that were not previously documented in the literature or vendor reports.
- The 40.8 percent precision rate indicates that roughly two-fifths of the flagged anomalies are genuine new issues warranting developer attention.
- Repository-grounded instantiation ensures the generated tests reflect actual code contexts rather than synthetic toy problems.
Where Pith is reading between the lines
- Developers could embed the pattern-mining step inside issue trackers so that every new confirmed failure automatically expands the test suite.
- The same mining-to-fuzzing pipeline could be applied to non-coding AI agents such as planning or debugging assistants.
- Periodic re-execution of the 647-case bundle after model updates would give a quantitative regression signal for agent robustness.
- The Action-type taxonomy might serve as a lightweight specification language for future agent safety benchmarks.
Load-bearing premise
The 400 user-reported anomalies are representative of the full space of agent failures and the derived patterns capture essential behaviors without significant selection bias.
What would settle it
Applying the same mining and generation process to an independent, larger corpus of confirmed agent failures and obtaining a materially lower rate of new true anomalies would falsify the claim that the extracted patterns generalize.
Figures





read the original abstract
AI coding agents are increasingly integrated into real-world software development workflows, yet their robustness under diverse and adversarial scenarios remains poorly understood. We present ABTest, a behavior-driven fuzzing framework that systematically tests coding agents by turning real-world failure reports into repository-grounded behavioral tests. ABTest (1) mines user-reported anomalies to derive reusable workflow patterns (Interaction Patterns) and behaviors (Action types); (2) composes them into stepwise fuzzing templates; (3) instantiates executable test cases in real repositories; (4) executes them with coding agents while recording traces and artifacts; and (5) detects and validates anomalous behaviors. We apply ABTest to three widely used coding agents: Claude Code, OpenAI Codex CLI, and Gemini CLI. From 400 user-reported developer-confirmed agent failures, we extract 47 Interaction Patterns and 128 Action types, generating 647 repository-grounded fuzzing cases. Executing the 647-case bundle once per evaluated configuration, ABTest flags 1,573 behavioral anomalies across the three coding agent families, of which 642 are manually confirmed as new true anomalies, achieving a detection precision of 40.8%. Our results demonstrate that ABTest effectively uncovers real-world failures, exposes robustness differences across models, and reveals previously unreported failure modes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ABTest, a behavior-driven fuzzing framework that mines 400 user-reported developer-confirmed failures to derive 47 Interaction Patterns and 128 Action types, composes them into 647 repository-grounded test cases, executes the cases on Claude Code, OpenAI Codex CLI, and Gemini CLI, flags 1,573 behavioral anomalies, and manually confirms 642 as new true anomalies at 40.8% precision. It claims this approach uncovers real-world failures, exposes robustness differences across agents, and reveals previously unreported failure modes.
Significance. If the anomaly detection and manual validation steps can be made fully reproducible, the work supplies a concrete, repository-grounded method for stress-testing AI coding agents at scale. The reported counts (647 cases, 1,573 anomalies, 642 confirmed) and cross-agent comparison provide empirical evidence that could inform both agent development and future testing frameworks in software engineering.
major comments (3)
- [§4] §4 (Pattern Mining): The derivation of the 47 Interaction Patterns and 128 Action types from the 400 reports is described only at a high level; no coding protocol, inter-annotator agreement statistic, or explicit handling of selection bias is supplied. This directly affects the claim that the 647 generated cases are representative of the failure space.
- [§5.2] §5.2 (Anomaly Detection): The rules or heuristics used to flag the 1,573 anomalies from execution traces are not stated explicitly (e.g., no decision criteria, thresholds, or trace features). Without these, the 40.8% precision figure cannot be independently verified or reproduced.
- [§5.3] §5.3 (Validation): The manual confirmation step that yields the 642 'new true anomalies' provides no rubric for (a) distinguishing novelty from rediscovery of the original 400 reports or the 47 patterns, (b) operational definition of 'true anomaly' versus expected behavior, or (c) blinding or inter-rater reliability. This step is load-bearing for both the precision number and the 'previously unreported' claim.
minor comments (2)
- [Abstract] Abstract: The phrase 'manually confirmed as new true anomalies' should include a forward reference to the validation subsection that defines the confirmation criteria.
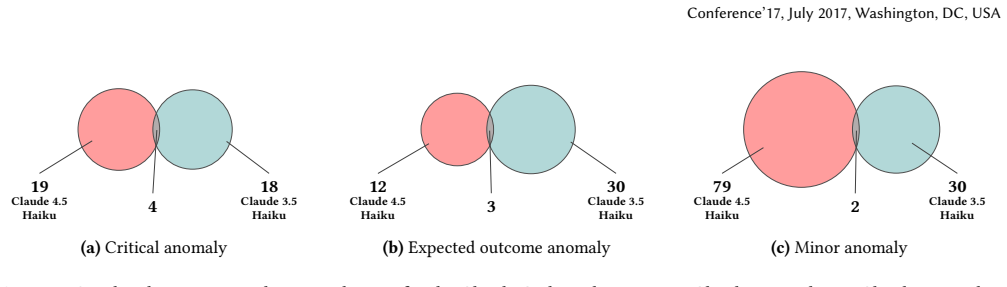
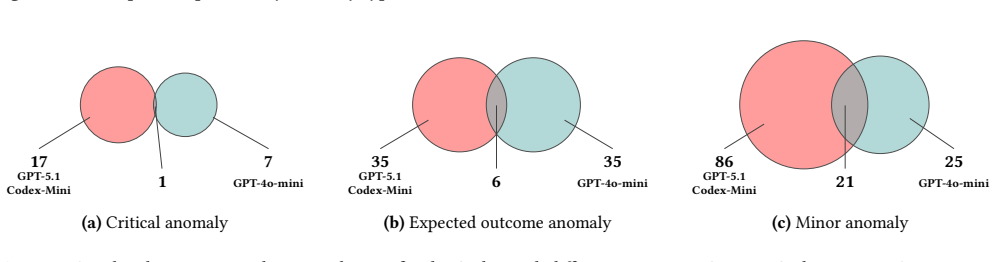
- [Results] Table 2 (or equivalent results table): Per-agent and per-pattern anomaly counts are summarized at too high a level to allow readers to assess which Interaction Patterns drive the robustness differences.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that improving the reproducibility of our methodology is essential and will revise the manuscript accordingly to address the concerns raised in sections 4, 5.2, and 5.3. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [§4] §4 (Pattern Mining): The derivation of the 47 Interaction Patterns and 128 Action types from the 400 reports is described only at a high level; no coding protocol, inter-annotator agreement statistic, or explicit handling of selection bias is supplied. This directly affects the claim that the 647 generated cases are representative of the failure space.
Authors: We acknowledge that §4 provides a high-level overview of the pattern mining process. In the revised version, we will expand this section to include: (1) the full coding protocol and annotation guidelines used by the researchers; (2) inter-annotator agreement statistics (e.g., Cohen's kappa or percentage agreement) calculated on a subset of the reports; and (3) a discussion of potential selection biases in the 400 reports and how we mitigated them (e.g., by sampling from diverse sources). These additions will better support the representativeness of the 647 test cases. revision: yes
-
Referee: [§5.2] §5.2 (Anomaly Detection): The rules or heuristics used to flag the 1,573 anomalies from execution traces are not stated explicitly (e.g., no decision criteria, thresholds, or trace features). Without these, the 40.8% precision figure cannot be independently verified or reproduced.
Authors: We agree that explicit rules are necessary for reproducibility. In the revision, we will detail the anomaly detection heuristics in §5.2, including the specific decision criteria, thresholds applied to trace features (such as execution logs, output differences, and error patterns), and any automated filters used to identify the 1,573 anomalies. This will allow independent verification of the process leading to the 40.8% precision. revision: yes
-
Referee: [§5.3] §5.3 (Validation): The manual confirmation step that yields the 642 'new true anomalies' provides no rubric for (a) distinguishing novelty from rediscovery of the original 400 reports or the 47 patterns, (b) operational definition of 'true anomaly' versus expected behavior, or (c) blinding or inter-rater reliability. This step is load-bearing for both the precision number and the 'previously unreported' claim.
Authors: We recognize the importance of transparency in the validation process. We will revise §5.3 to include: (a) a rubric for assessing novelty, such as checking against the original 400 reports and patterns; (b) an operational definition of 'true anomaly' (e.g., behaviors that deviate from expected agent functionality in a way that could impact real-world use); and (c) details on the validation procedure, including whether blinding was employed and any measures of inter-rater reliability. If the original process did not include blinding, we will note this as a limitation and describe how we ensured consistency. This will strengthen the claims regarding the 642 confirmed anomalies. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's chain mines 400 external user reports into 47 Interaction Patterns and 128 Action types, synthesizes 647 repository-grounded test cases, executes them on three independent coding agents, flags 1,573 anomalies, and manually confirms 642 as new. No equations, fitted parameters, or self-citations reduce the precision figure, anomaly counts, or 'previously unreported' claim to the input reports by construction. The manual confirmation step, while lacking an explicit rubric in the provided text, operates as an independent validation layer rather than a definitional loop. The overall methodology remains self-contained against the external agent executions and report-derived inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User-reported anomalies are representative of real-world agent failures and sufficient to derive reusable patterns
invented entities (2)
-
Interaction Patterns
no independent evidence
-
Action types
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearABTest (1) mines user-reported anomalies to derive reusable workflow patterns (Interaction Patterns) and behaviors (Action types); (2) composes them into stepwise fuzzing templates...
Reference graph
Works this paper leans on
-
[1]
[n. d.]. American Fuzzy Lop (AFL) GitHub Repository. URL: https://github.com/google/afl
-
[2]
2025. Claude Code. https://www.claude.com/product/claude-code. Accessed: 2025-12-12
work page 2025
- [3]
- [4]
-
[5]
Mohammad Abdollahi, Ruixin Zhang, Nima Shiri Harzevili, Jiho Shin, Song Wang, and Hadi Hemmati. 2026. Surveying the Benchmarking Landscape of Large Language Models in Code Intelligence. TOSEM 2026 (2026)
work page 2026
-
[6]
Shivani Acharya and Vidhi Pandya. 2012. Bridge between black Box and white Box–gray Box testing technique. International Journal of Electronics and Computer Science Engineering 2, 1 (2012), 175–185
work page 2012
-
[7]
Chuyang Chen and Brendan Dolan-Gavitt. 2025. {ELFuzz}: Efficient Input Generation via {LLM-driven} Synthesis Over Fuzzer Space. In 34th USENIX Security Symposium (USENIX Security 25) . 6279–6298
work page 2025
-
[8]
Patrice Godefroid, Michael Y. Levin, and David Molnar. 2012. SAGE: whitebox fuzzing for security testing. Commun. Association for Com- puting Machinery (ACM) 55, 3 (March 2012), 40–44. doi: 10.1145/ 2093548.2093564
-
[9]
Patrice Godefroid, Hila Peleg, and Rishabh Singh. 2017. Learn&fuzz: Machine learning for input fuzzing. In ASE 2017. IEEE, 50–59
work page 2017
-
[10]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InInternational Conference on Learning Representations
work page 2024
- [11]
-
[12]
Mohd Ehmer Khan and Farmeena Khan. 2012. A comparative study of white box, black box and grey box testing techniques. International Journal of Advanced Computer Science and Applications 3, 6 (2012)
work page 2012
- [13]
- [14]
-
[15]
Barton P Miller, Gregory Cooksey, and Fredrick Moore. 2006. An empirical study of the robustness of macos applications using random testing. In Proceedings of the 1st international workshop on Random testing. 46–54
work page 2006
-
[16]
Miller, Lars Fredriksen, and Bryan So
Barton P. Miller, Lars Fredriksen, and Bryan So. 1990. An Empirical Study of the Reliability of UNIX Utilities. Commun. ACM 33, 12 (1990), 32–44. doi: 10.1145/96267.96279
-
[17]
Yaroslav Oliinyk, Michael Scott, Ryan Tsang, Chongzhou Fang, Houman Homayoun, et al . 2024. Fuzzing {BusyBox}: Leveraging {LLM} and crash reuse for embedded bug unearthing. In 33rd USENIX Security Symposium (USENIX Security 24) . 883–900
work page 2024
- [18]
-
[19]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision. TSE 50, 4 (2024), 911–936
work page 2024
-
[20]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Jun- yang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig
-
[21]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
OpenHands: An Open Platform for AI Software Developers as Generalist Agents. arXiv preprint arXiv:2407.16741 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Yanlin Wang, Wanjun Zhong, Yanxian Huang, Ensheng Shi, Min Yang, Jiachi Chen, Hui Li, Yuchi Ma, Qianxiang Wang, and Zibin Zheng
-
[23]
Automated Software Engineering 32, 2 (2025), 70
Agents in software engineering: Survey, landscape, and vision. Automated Software Engineering 32, 2 (2025), 70
work page 2025
-
[24]
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. 2024. Fuzz4all: Universal fuzzing with large language models. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering . 1–13
work page 2024
-
[25]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent- Computer Interfaces Enable Automated Software Engineering. arXiv preprint arXiv:2405.15793 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Ao Zhang, Yiying Zhang, Yao Xu, Cong Wang, and Siwei Li. 2023. Machine learning-based fuzz testing techniques: A survey.IEEE Access 12 (2023), 14437–14454
work page 2023
-
[27]
Kunpeng Zhang, Zongjie Li, Daoyuan Wu, Shuai Wang, and Xin Xia
-
[28]
In 34th USENIX Security Symposium (USENIX Security 25)
{Low-Cost} and Comprehensive Non-textual Input Fuzzing with {LLM-Synthesized} Input Generators. In 34th USENIX Security Symposium (USENIX Security 25) . 6999–7018
-
[29]
Ruixin Zhang, Wuyang Dai, Hung Viet Pham, Gias Uddin, Jinqiu Yang, and Song Wang. 2026. Engineering Pitfalls in AI Coding Tools: An Empirical Study of Bugs in Claude Code, Codex, and Gemini CLI. In FSE 2026
work page 2026
-
[30]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury
-
[31]
AutoCodeRover: Au- tonomous program improvement.arXiv preprint arXiv:2404.05427, 2024
AutoCodeRover: Autonomous Program Improvement. arXiv preprint arXiv:2404.05427 (2024). Received 28 September 2023; revised 5 March 2024; accepted 16 April 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.