Recognition: 2 theorem links
· Lean TheoremScalable Variational Bayesian Fine-Tuning of LLMs via Orthogonalized Low-Rank Adapters
Pith reviewed 2026-05-13 19:56 UTC · model grok-4.3
The pith
PoLAR-VBLL uses orthogonalized low-rank adapters and variational inference on the last layer to deliver scalable Bayesian fine-tuning with calibrated uncertainty in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing standard LoRA with a polar-decomposed orthogonal low-rank adapter (PoLAR) optimized on the Riemannian manifold and placing variational inference over the parameters of a Bayesian last layer, the method performs alternating optimization that jointly learns the adapters and the approximate posterior, yielding scalable Bayesian fine-tuning that improves generalization and produces well-calibrated uncertainty on in- and out-of-distribution data for common-sense reasoning tasks.
What carries the argument
PoLAR (Polar-decomposed Low-rank Adapter Representation), an orthogonalized low-rank parameterization obtained via polar decomposition and Riemannian optimization that prevents rank collapse and supports more expressive, stable adaptation than standard LoRA.
If this is right
- Well-calibrated uncertainty estimates become available without multiple complete forward passes through the full LLM at inference time.
- Both generalization and uncertainty estimation improve on in-distribution and out-of-distribution data for common-sense reasoning tasks.
- Architecture-level changes to the adapter (orthogonalization plus Riemannian geometry) integrate directly with scalable variational inference over the last layer.
- The alternating optimization scheme jointly updates the PoLAR parameters and the approximate posterior of the last-layer weights.
Where Pith is reading between the lines
- If PoLAR remains stable across model sizes, the same parameterization could replace standard LoRA in other uncertainty-aware or Bayesian fine-tuning pipelines.
- The inference-time efficiency gain might make calibrated LLMs feasible for real-time safety-critical applications that currently rely on post-hoc calibration.
- A natural extension would test whether the same PoLAR-plus-variational-last-layer recipe transfers to other parameter-efficient methods or to generation rather than classification tasks.
Load-bearing premise
The PoLAR parameterization with Riemannian optimization provides meaningfully more expressive and stable adaptation than standard LoRA without introducing offsetting instabilities or requiring impractical hyperparameter tuning.
What would settle it
A side-by-side evaluation on the same common-sense reasoning benchmarks showing that PoLAR-VBLL produces higher expected calibration error or worse negative log likelihood than a standard LoRA-based variational Bayesian last layer model would falsify the performance claim.
Figures

read the original abstract
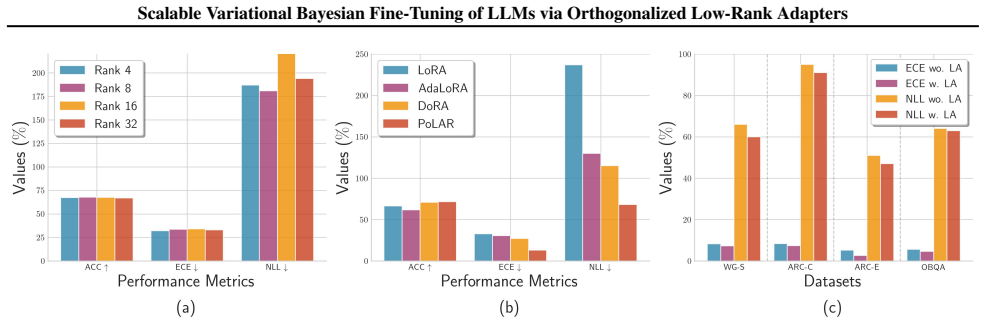
When deploying large language models (LLMs) to safety-critical applications, uncertainty quantification (UQ) is of utmost importance to self-assess the reliability of the LLM-based decisions. However, such decisions typically suffer from overconfidence, particularly after parameter-efficient fine-tuning (PEFT) for downstream domain-specific tasks with limited data. Existing methods to alleviate this issue either rely on Laplace approximation based post-hoc framework, which may yield suboptimal calibration depending on the training trajectory, or variational Bayesian training that requires multiple complete forward passes through the entire LLM backbone at inference time for Monte Carlo estimation, posing scalability challenges for deployment. To address these limitations, we build on the Bayesian last layer (BLL) model, where the LLM-based deterministic feature extractor is followed by random last layer parameters for uncertainty reasoning. Since existing low-rank adapters (LoRA) for PEFT have limited expressiveness due to rank collapse, we address this with Polar-decomposed Low-rank Adapter Representation (PoLAR), an orthogonalized parameterization paired with Riemannian optimization to enable more stable and expressive adaptation. Building on this PoLAR-BLL model, we leverage the variational (V) inference framework to put forth a scalable Bayesian fine-tuning approach which jointly seeks the PoLAR parameters and approximate posterior of the last layer parameters via alternating optimization. The resulting PoLAR-VBLL is a flexible framework that nicely integrates architecture-enhanced optimization with scalable Bayesian inference to endow LLMs with well-calibrated UQ. Our empirical results verify the effectiveness of PoLAR-VBLL in terms of generalization and uncertainty estimation on both in-distribution and out-of-distribution data for various common-sense reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PoLAR-VBLL, a scalable variational Bayesian fine-tuning framework for LLMs. It extends the Bayesian last layer (BLL) model by replacing standard LoRA adapters with Polar-decomposed Low-rank Adapter Representation (PoLAR), an orthogonalized parameterization trained via Riemannian optimization to mitigate rank collapse and increase expressiveness. The method performs alternating optimization between PoLAR parameters and the variational posterior over the last-layer weights, yielding well-calibrated uncertainty quantification at inference cost comparable to a single forward pass.
Significance. If the PoLAR parameterization and alternating scheme are shown to deliver stable, expressive adaptation without offsetting instabilities, the work would provide a practical route to parameter-efficient Bayesian fine-tuning that avoids both the suboptimality of post-hoc Laplace methods and the inference-time cost of full variational Monte Carlo sampling, which is relevant for safety-critical LLM deployment.
major comments (3)
- [Abstract] Abstract: the claim of empirical verification on reasoning tasks supplies no quantitative metrics, baselines, error bars, or ablation details, so the central assertion of well-calibrated UQ rests on unshown experimental controls.
- [PoLAR parameterization] PoLAR parameterization section: the assertion that polar decomposition plus Riemannian optimization provably prevents rank collapse and yields more expressive adapters than LoRA is not reduced to a derivation or convergence guarantee for the alternating VBLL scheme; the stability benefit therefore remains an untested modeling assumption.
- [Experiments] Experiments section: no comparison to standard LoRA-BLL, Laplace post-hoc baselines, or full variational methods is described, nor are any performance numbers, OOD detection metrics, or hyperparameter sensitivity results reported, leaving the scalability and calibration claims unsupported.
minor comments (1)
- [Introduction] The manuscript introduces the acronyms PoLAR and PoLAR-VBLL without an explicit comparison table to prior BLL and LoRA formulations, which would clarify the precise architectural and optimization differences.
Simulated Author's Rebuttal
We are grateful for the referee's constructive feedback on our manuscript. We address each major comment below and will make the necessary revisions to improve the clarity and completeness of the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of empirical verification on reasoning tasks supplies no quantitative metrics, baselines, error bars, or ablation details, so the central assertion of well-calibrated UQ rests on unshown experimental controls.
Authors: We will revise the abstract to include key quantitative results from our experiments, such as performance metrics on reasoning tasks with baselines, error bars, and ablation summaries. This will better support the claim of well-calibrated UQ. revision: yes
-
Referee: [PoLAR parameterization] PoLAR parameterization section: the assertion that polar decomposition plus Riemannian optimization provably prevents rank collapse and yields more expressive adapters than LoRA is not reduced to a derivation or convergence guarantee for the alternating VBLL scheme; the stability benefit therefore remains an untested modeling assumption.
Authors: The PoLAR parameterization is designed to prevent rank collapse through orthogonalization, as motivated in the section. We will add a short derivation showing the expressiveness benefit and note that the alternating scheme's stability is validated empirically. A full convergence guarantee is not provided and we will state this limitation explicitly. revision: partial
-
Referee: [Experiments] Experiments section: no comparison to standard LoRA-BLL, Laplace post-hoc baselines, or full variational methods is described, nor are any performance numbers, OOD detection metrics, or hyperparameter sensitivity results reported, leaving the scalability and calibration claims unsupported.
Authors: We will update the experiments section to include direct comparisons to LoRA-BLL, Laplace post-hoc, and full variational methods, along with specific performance numbers, OOD metrics, and hyperparameter sensitivity results with error bars. These additions will strengthen the support for our scalability and calibration claims. revision: yes
Circularity Check
No circularity: novel PoLAR parameterization introduced independently of prior fits or self-citations
full rationale
The paper's derivation chain proposes PoLAR (polar-decomposed low-rank adapters with Riemannian optimization) as a new response to LoRA rank collapse, then integrates it into the existing BLL model via alternating variational optimization. No equations, fitted parameters, or self-citations are shown reducing the claimed stability/expressiveness or calibration benefits to inputs by construction. The framework builds on BLL and LoRA literature but treats the orthogonalized parameterization as an independent architectural choice whose advantages are asserted via empirical results rather than tautological re-derivation. This is the most common honest non-finding for papers that introduce new parameterizations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Variational inference provides a sufficiently accurate approximation to the posterior over last-layer parameters for calibration purposes
- ad hoc to paper Polar decomposition plus Riemannian optimization prevents rank collapse and yields more expressive low-rank adapters than standard LoRA
invented entities (2)
-
PoLAR
no independent evidence
-
PoLAR-VBLL
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPolar-decomposed Low-rank Adapter Representation (PoLAR), an orthogonalized parameterization paired with Riemannian optimization to enable more stable and expressive adaptation... ΔW=UΛV⊤ with U∈St(m,r), V∈St(n,r)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearvariational (V) inference framework... closed-form Jensen-tightened evidence lower bound (ELBO)... PoLAR-VBLL jointly seeks the PoLAR parameters and approximate posterior of the last layer parameters via alternating optimization
Reference graph
Works this paper leans on
-
[1]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language Models are Few-Shot Learn- ers.Proc. Adv. Neural Inf. Process. Syst., 33:1877–1901,
work page 1901
-
[2]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Eschenhagen, R., Daxberger, E., Hennig, P., and Kristiadi, A. Mixtures of laplace approximations for improved post-hoc uncertainty in deep learning.arXiv preprint arXiv:2111.03577,
-
[5]
Language Models (Mostly) Know What They Know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Polar: Polar- decomposed low-rank adapter representation.arXiv preprint arXiv:2506.03133,
9 Scalable Variational Bayesian Fine-Tuning of LLMs via Orthogonalized Low-Rank Adapters Lion, K., Zhang, L., Li, B., and He, N. Polar: Polar- decomposed low-rank adapter representation.arXiv preprint arXiv:2506.03133,
-
[7]
F., Cheng, K.-T., and Chen, M.-H
Liu, S.-Y ., Wang, C.-Y ., Yin, H., Molchanov, P., Wang, Y .-C. F., Cheng, K.-T., and Chen, M.-H. Dora: Weight-decomposed low-rank adaptation.arXiv preprint arXiv:2402.09353,
-
[8]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I. and Hutter, F. Sgdr: Stochastic gra- dient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Paszke, A. Pytorch: An imperative style, high-performance deep learning library.arXiv preprint arXiv:1912.01703,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[11]
On the practicality of deterministic epistemic uncertainty.arXiv preprint arXiv:2107.00649,
Postels, J., Segu, M., Sun, T., Sieber, L., Van Gool, L., Yu, F., and Tombari, F. On the practicality of deterministic epistemic uncertainty.arXiv preprint arXiv:2107.00649,
-
[12]
H., Jantre, S., Zhang, W., Wang, Y ., Yoon, B.-J., Urban, N
Rahmati, A. H., Jantre, S., Zhang, W., Wang, Y ., Yoon, B.-J., Urban, N. M., and Qian, X. C-lora: Contextual low-rank adaptation for uncertainty estimation in large language models.arXiv preprint arXiv:2505.17773,
-
[13]
D., Acharya, M., Kaur, R., and Jha, S
Samplawski, C., Cobb, A. D., Acharya, M., Kaur, R., and Jha, S. Scalable bayesian low-rank adaptation of large language models via stochastic variational subspace in- ference.arXiv preprint arXiv:2506.21408,
-
[14]
Shi, H., Wang, Y ., Han, L., Zhang, H., and Wang, H. Training-free bayesianization for low-rank adapters of large language models.arXiv preprint arXiv:2412.05723,
-
[15]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
LoRA ensembles for large language model fine-tuning.arXiv preprint arXiv:2310.00035,
Wang, X., Aitchison, L., and Rudolph, M. LoRA ensembles for large language model fine-tuning.arXiv preprint arXiv:2310.00035,
-
[17]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Zhang, Q., Chen, M., Bukharin, A., He, P., Cheng, Y ., Chen, W., and Zhao, T. Adaptive budget alloca- tion for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Zhao, J., Zhang, Z., Chen, B., Wang, Z., Anandkumar, A., and Tian, Y . Galore: Memory-efficient llm train- ing by gradient low-rank projection.arXiv preprint arXiv:2403.03507,
-
[19]
14 Scalable Variational Bayesian Fine-Tuning of LLMs via Orthogonalized Low-Rank Adapters B. Implementation Details B.1. Training Settings Model Architecture.Our implementation builds upon the LlaMA-3.1-8B and LLaMA-2-7B foundation models (Tou- vron et al., 2023), utilizing its pre-trained language modeling head for VBLL mean initialization. PoLAR Configu...
work page 2023
-
[20]
with gradient type set to ”landing”. The Landing Field callback is enabled during training to maintain stability in optimization on the Grassmann manifold. VBLL Parameterization.For VBLL, we adopt the dense parameterization for computational efficiency while maintaining uncertainty quantification capabilities. The Jensen bound is used for approximating th...
work page 2024
-
[21]
Baselines are reproduced strictly according to the implementations in their official repositories
optimizers with learning rate 10−4 and a CosineAnnealingWarmRestarts scheduler (Loshchilov & Hutter, 2016). Baselines are reproduced strictly according to the implementations in their official repositories. For sampling-based methods (BLoB, TFB, ScalaBL, C-LoRA), we set training sampling Ktrain = 1 (single sample per forward pass) and inference sampling Keval =
work page 2016
-
[22]
for adapter implementations, custom Laplace approximation libraries (Yang et al., 2024; Daxberger et al., 2021; Kristiadi et al.,
work page 2024
-
[23]
for post-hoc uncertainty calibration, PoLAR optimization libraries (Lion et al., 2025), and VBLL (Variational Bayesian Last Layer) implementations (Harrison et al., 2024). Complete dependency specifications and version information are provided in our requirements.txt file, which will be made available upon acceptance. C. Extend Experiments C.1. Additional...
work page 2025
-
[24]
As shown in Table 3, PoLAR-VBLL achieves approximately 7× inference speedup compared to BLoB-based methods (12s vs. 80–90s) while maintaining a competitive memory footprint significantly lower than full-network Laplace approximations (18,423 MB vs.∼41,000 MB for PoLAR-LA and LoRA-LA). The efficiency of PoLAR-VBLL stems from two key design choices. First, ...
work page 2025
-
[25]
demonstrates that distance-aware features, where semantically distinct inputs remain well-separated in the feature space, are essential for reliable uncertainty estimation. We argue that VBLL shares this requirement: when the Bayesian last layer receives features from a distance- preserving extractor, it can effectively distinguish between in-distribution...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.