Are Arabic Benchmarks Reliable? QIMMA's Quality-First Approach to LLM Evaluation
Pith reviewed 2026-05-13 19:31 UTC · model grok-4.3
The pith
QIMMA validates and cleans existing Arabic benchmarks with LLM and human review to produce a more reliable 52k-sample evaluation suite.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
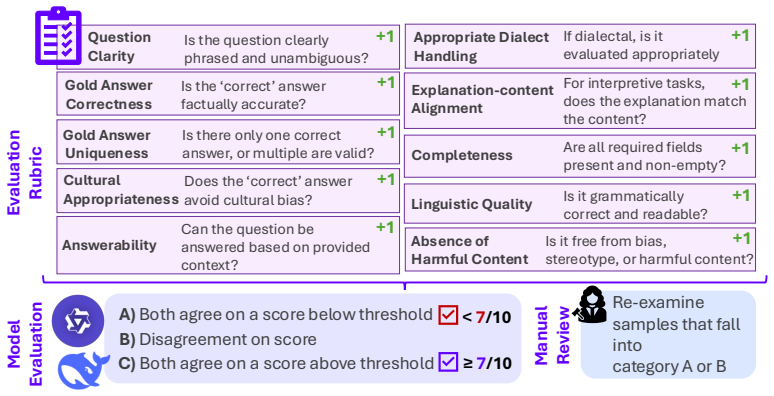
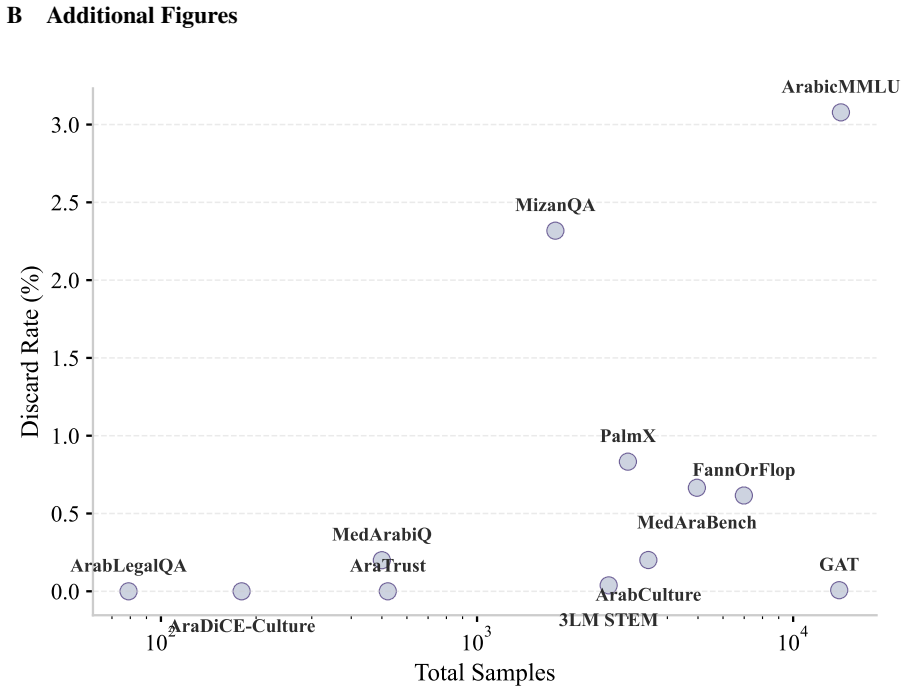
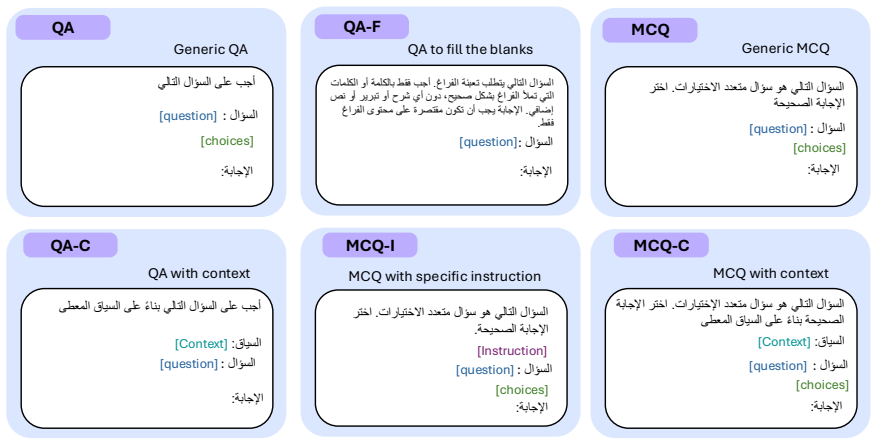
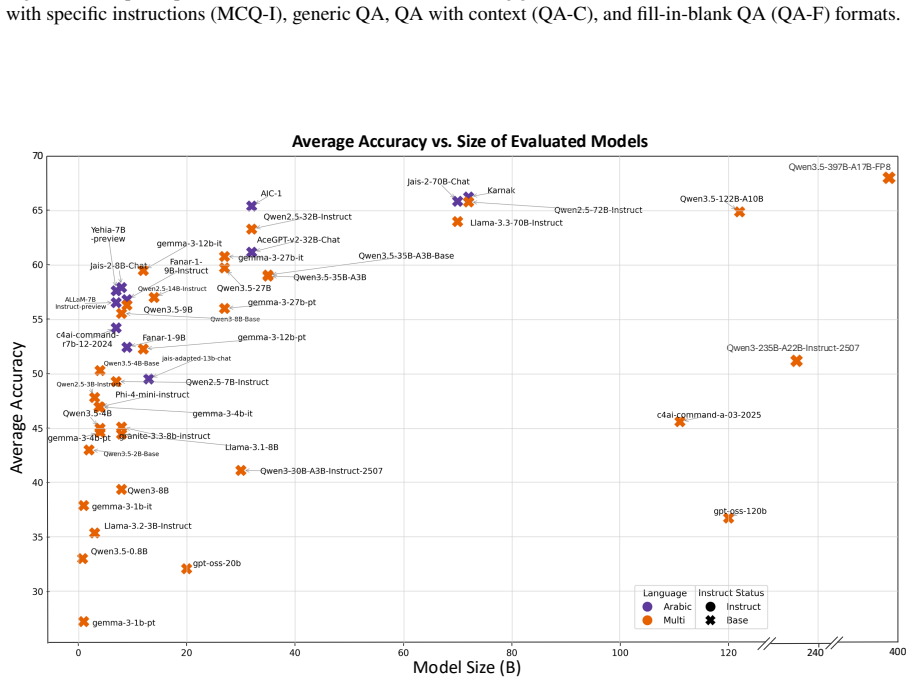
Rather than aggregating existing resources as-is, QIMMA applies a multi-model assessment pipeline combining automated LLM judgment with human review to surface and resolve systematic quality issues in well-established Arabic benchmarks before evaluation. The result is a curated, multi-domain, multi-task evaluation suite of over 52k samples, grounded predominantly in native Arabic content; code evaluation tasks are the sole exception, as they are inherently language-agnostic.
What carries the argument
The multi-model assessment pipeline that combines automated LLM judgment with human review to identify and resolve quality issues in benchmarks prior to evaluation.
If this is right
- The process produces a curated multi-domain, multi-task suite of over 52k samples for evaluation.
- Native Arabic content forms the basis for most tasks while code tasks remain language-agnostic.
- Transparent implementation through public code and per-sample inference outputs supports reproducibility.
- The resulting suite serves as a community-extensible foundation for Arabic NLP evaluation.
Where Pith is reading between the lines
- The same validation pipeline could be adapted to benchmarks in other languages to address similar quality concerns.
- Access to per-sample outputs enables researchers to diagnose specific model failure patterns on individual items.
- Prioritizing native content may reduce artifacts from translation that otherwise skew cross-model comparisons.
Load-bearing premise
That the combination of LLM judgment and human review reliably identifies and fixes the main quality problems without introducing new biases or missing subtle issues that affect downstream model rankings.
What would settle it
If model performance rankings on the original uncleaned Arabic benchmarks prove identical to those on the QIMMA-curated versions, the pipeline's quality fixes would have no measurable effect on evaluation outcomes.
Figures

read the original abstract
We present QIMMA, a quality-assured Arabic LLM leaderboard that places systematic benchmark validation at its core. Rather than aggregating existing resources as-is, QIMMA applies a multi-model assessment pipeline combining automated LLM judgment with human review to surface and resolve systematic quality issues in well-established Arabic benchmarks before evaluation. The result is a curated, multi-domain, multi-task evaluation suite of over 52k samples, grounded predominantly in native Arabic content; code evaluation tasks are the sole exception, as they are inherently language-agnostic. Transparent implementation via LightEval, EvalPlus and public release of per-sample inference outputs make QIMMA a reproducible and community-extensible foundation for Arabic NLP evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents QIMMA, a quality-assured Arabic LLM leaderboard that applies a multi-model assessment pipeline of automated LLM judgment combined with human review to identify and resolve quality issues in established Arabic benchmarks. This yields a curated multi-domain, multi-task suite of over 52k samples grounded predominantly in native Arabic content (with code tasks as the exception), implemented transparently via LightEval and EvalPlus with public release of per-sample inference outputs.
Significance. If the curation process is shown to produce measurable improvements in evaluation reliability, QIMMA would offer a valuable, reproducible foundation for Arabic NLP benchmarking that prioritizes native content and addresses potential flaws in existing resources. The transparency and community-extensibility aspects strengthen its potential impact as a shared resource.
major comments (2)
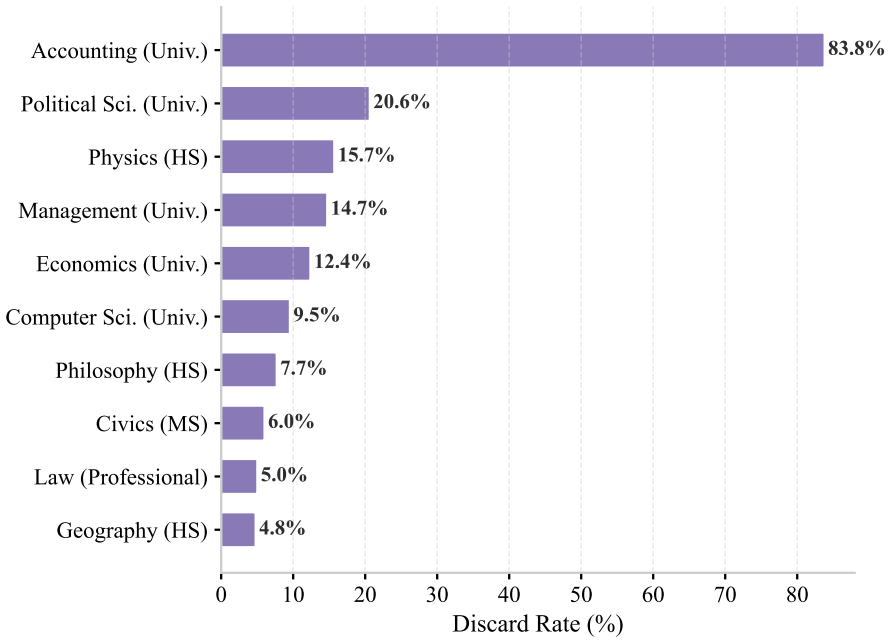
- [Evaluation and Results] The central claim that the LLM-judgment + human-review pipeline reliably surfaces and resolves the main quality issues rests on process description alone. No quantitative before/after comparison of model rankings on the original versus curated benchmarks is provided, nor are inter-annotator agreement statistics or a breakdown of issue types and number of samples changed reported. This absence prevents verification that the curation alters downstream outcomes rather than merely re-labeling data.
- [Dataset Description] Dataset curation section: While the total of over 52k samples is stated, the manuscript provides no counts or proportions of samples modified by the pipeline, nor any enumeration of the specific quality issues addressed (e.g., translation artifacts, cultural misalignment). These details are load-bearing for assessing whether the quality-first approach delivers substantive improvements.
minor comments (1)
- [Abstract] Abstract: The phrase 'systematic quality issues' is used without a brief list of example issues; adding one or two concrete examples would improve immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the curation pipeline's impact.
read point-by-point responses
-
Referee: [Evaluation and Results] The central claim that the LLM-judgment + human-review pipeline reliably surfaces and resolves the main quality issues rests on process description alone. No quantitative before/after comparison of model rankings on the original versus curated benchmarks is provided, nor are inter-annotator agreement statistics or a breakdown of issue types and number of samples changed reported. This absence prevents verification that the curation alters downstream outcomes rather than merely re-labeling data.
Authors: We agree that quantitative validation is essential. In the revised manuscript we will add a direct before/after comparison of model rankings on the original versus curated versions of the benchmarks, report inter-annotator agreement statistics (including Cohen's kappa for the human review stage), and include a breakdown of issue types together with the exact number of samples modified for each category. These additions will demonstrate that the curation changes downstream evaluation outcomes. revision: yes
-
Referee: [Dataset Description] Dataset curation section: While the total of over 52k samples is stated, the manuscript provides no counts or proportions of samples modified by the pipeline, nor any enumeration of the specific quality issues addressed (e.g., translation artifacts, cultural misalignment). These details are load-bearing for assessing whether the quality-first approach delivers substantive improvements.
Authors: We acknowledge the need for these specifics. The revised dataset description section will report the exact counts and proportions of samples modified by the pipeline, along with a categorized enumeration of the quality issues addressed (translation artifacts, cultural misalignment, factual inaccuracies, etc.). A summary table will be added to make the distribution of changes transparent. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical data curation effort that applies an LLM-judgment plus human-review pipeline to existing Arabic benchmarks, producing a cleaned 52k-sample suite as its primary output. No equations, fitted parameters, predictions, or derivations are described that reduce by construction to prior inputs or self-citations. The work is self-contained as a quality-assurance process whose result is the curated dataset itself rather than a mathematical claim derived from fitted values or imported uniqueness theorems. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM judgment combined with human review is sufficient to identify and resolve systematic quality issues in Arabic benchmarks
Reference graph
Works this paper leans on
-
[1]
Jais 2: A family of Arabic-centric open large language models. Technical report, IFM. Mikel Artetxe, Sebastian Ruder, and Dani Y ogatama
-
[2]
On the cross-lingual transferability of mono- lingual representations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4623–4637, Online. Association for Computational Linguistics. Adil Bahaj and Mounir Ghogho. 2025. MizanQA: Benchmarking large language models on Moroccan legal question answering. Basma El...
work page 2025
-
[3]
3LM: Bridging Arabic, STEM, and code through benchmarking. Stanford CRFM. 2023. HELM arabic: Holistic evalua- tion of language models for arabic. https://crfm .stanford.edu/helm/arabic/. Mouath Abu Daoud, Chaimae Abouzahir, Leen Kharouf, Walid Al-Eisawi, Nizar Habash, and Farah E Shamout
work page 2023
-
[4]
Medarabiq: Benchmarking large language models on arabic medical tasks
MedArabiQ: Benchmarking large language models on Arabic medical tasks. arXiv preprint arXiv:2505.03427. Mouath Abu Daoud, Leen Kharouf, Omar El Hajj, Dana El Samad, Mariam Al-Omari, Jihad Mallat, Khaled Saleh, Nizar Habash, and Farah E. Shamout
-
[5]
Medarabench: Large-scale arabic medical question answering dataset and benchmark . In The Fourteenth International Conference on Learning Representations. DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Y ang, Deli Chen, Dongjie Ji, Erhang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Antreas Ioannou, Andreas Shiamishis, Nora Hollenstein, and Nezihe Merve Gürel
Annotation artifacts in natural language infer- ence data. In Proceedings of NAACL-HLT , pages 107–112. Nathan Habib, Clémentine Fourrier, Hynek Kydlíček, Thomas Wolf, and Lewis T unstall. 2023. Lighteval: A lightweight framework for llm evaluation. Faris Hijazi, Somayah AlHarbi, Abdulaziz AlHussein, Harethah Abu Shairah, Reem AlZahrani, Hebah Al- Shamlan...
-
[7]
Text Readability • 1: All text (question, answer, context) is readable and free of encoding or corruption issues • 0: Corrupted characters, missing letters, or encoding issues make the text illegible • Dialectal spelling variations are NOT encoding issues
-
[8]
Spelling Accuracy • 1: No spelling errors that affect comprehension (dialectal variants are acceptable) • 0: Spelling errors that impair understanding • Dialectal words are correct spellings in their dialect • Minor typos may still score 1 if meaning is clear
-
[9]
Grammatical Correctness • 1: Proper syntax and sentence structure within the chosen register (dialectal OR MSA) • 0: Grammar errors that impede understanding • Dialectal grammar is grammatically correct in dialectal Arabic
-
[10]
Question Clarity • 1: Question is clear and unambiguous (reasonable context assumed) • 0: Fundamentally vague or open to multiple interpretations • Some natural ambiguity is acceptable if a reasonable interpretation exists
-
[11]
Question Completeness • 1: Contains sufficient information (with context if provided) for a knowledgeable person to answer • 0: Missing critical information that makes answering impossible • Assume reasonable cultural/domain knowledge
-
[12]
Answer Quality • 1: Gold answer is readable, well-formed, and valid • 0: Answer is corrupted, nonsensical, or poorly formed • Length variation is acceptable • Answers can be single words, phrases, or full sentences
-
[13]
Answer Alignment • 1: Gold answer correctly and directly answers the question • 0: Answer is wrong or contradicts context • If context is provided, answer must align with it
-
[14]
Factual Accuracy • 1: Question, answer, and context (if provided) are factually correct or defensible • 0: Contains clear factual errors • If uncertain or unverifiable, score 1 • Cultural/regional variations are acceptable
-
[15]
Terminology Precision • 1: Appropriate terminology for the context • 0: Fundamentally wrong or misleading terms • Dialectal vocabulary is precise within its register • Domain-specific terms should match subject matter
-
[16]
Overall Coherence • 1: Question, answer, and context form a coherent QA item • 0: Structurally broken or unusable ================= CASCADING RULE (MANDATORY) ================= If text_readability = 0, you MUST set the following to 0: • question_clarity • question_completeness • answer_alignment • factual_accuracy • terminology_precision • overall_coheren...
-
[17]
Text Readability • 1: All text is readable and free of encoding or corruption issues • 0: Corrupted characters or encoding issues make the text illegible • Dialectal spelling variations are NOT encoding issues
-
[18]
Spelling Accuracy • 1: No spelling errors that affect comprehension, or only minor mistakes • 0: Spelling errors that impair reading • Minor typos may still score 1 if meaning is clear
-
[19]
Grammatical Correctness • 1: Proper syntax within the chosen register (dialectal OR MSA) • 0: Grammar errors that impede understanding • Dialectal grammar is valid within its system
-
[20]
Question Clarity • 1: Question is clear and unambiguous • 0: Fundamentally vague or open to conflicting interpretations
-
[21]
Question Completeness • 1: It is possible to answer the question given reasonable knowledge • 0: Question cannot be answered even with domain knowledge
-
[22]
Answer Quality • 1: Gold answer is readable and well-formed • 0: Answer is corrupted or nonsensical
-
[23]
Answer Alignment • 1: Gold answer correctly answers the question • 0: Answer is incorrect or incompatible
-
[24]
Factual Accuracy • 1: Content is factually correct or defensible • 0: Contains clear factual errors • If uncertain, score 1
-
[25]
Terminology Precision • 1: Appropriate terminology is used • 0: Terminology is misleading or incorrect
-
[26]
Overall Coherence • 1: Functional and coherent MCQ • 0: Structurally broken or unusable ================= CASCADING RULE (MANDATORY) ================= If text_readability = 0, you MUST set the following to 0: • question_clarity • question_completeness • answer_alignment • factual_accuracy • terminology_precision • overall_coherence Only the following may ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.