Recognition: 2 theorem links
· Lean TheoremDiffusion Policy with Bayesian Expert Selection for Active Multi-Target Tracking
Pith reviewed 2026-05-13 18:24 UTC · model grok-4.3
The pith
Bayesian uncertainty-aware selection of expert strategies improves diffusion policies for active multi-target tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that treating expert selection for diffusion policies as an offline contextual bandit and solving it with a multi-head VBLL model plus lower-confidence-bound selection yields action sequences that more effectively balance exploration and exploitation than implicit selection inside the diffusion process or standard gating techniques.
What carries the argument
Multi-head Variational Bayesian Last Layer (VBLL) predictor of per-expert tracking performance together with a Lower Confidence Bound (LCB) selection rule that conditions the diffusion policy on the chosen expert.
If this is right
- Each expert strategy receives both a performance prediction and an explicit uncertainty measure before selection occurs.
- Pessimistic LCB selection avoids committing to experts whose predictions are unreliable.
- The conditioned diffusion policy produces action sequences that improve the exploration-exploitation trade-off in simulated indoor tracking.
- The full pipeline outperforms the unmodified diffusion policy as well as mixture-of-experts and deterministic regression gating.
Where Pith is reading between the lines
- The same VBLL-plus-LCB wrapper could be attached to diffusion policies trained for other robotics tasks that admit multiple demonstrated behaviors.
- Explicit uncertainty quantification may reduce the chance that a robot acts on poorly estimated strategies in noisy or changing environments.
- Hardware experiments with real sensor noise and moving targets would test whether the simulated gains persist outside controlled settings.
Load-bearing premise
The multi-head VBLL model must produce reliable point estimates and predictive uncertainties for each expert strategy's tracking performance given the current belief state.
What would settle it
A controlled test in which the VBLL's uncertainty estimates are shown to be miscalibrated, causing LCB selection to choose inferior experts and eliminate the performance advantage over baselines.
Figures
read the original abstract
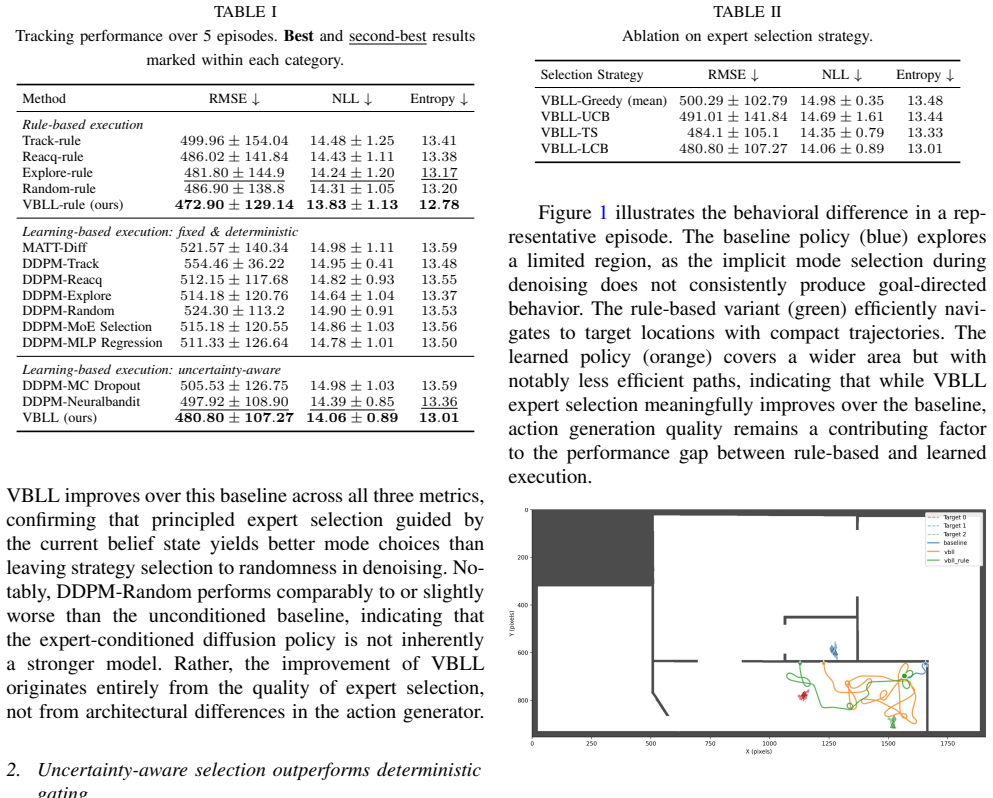
Active multi-target tracking requires a mobile robot to balance exploration for undetected targets with exploitation of uncertain tracked ones. Diffusion policies have emerged as a powerful approach for capturing diverse behavioral strategies by learning action sequences from expert demonstrations. However, existing methods implicitly select among strategies through the denoising process, without uncertainty quantification over which strategy to execute. We formulate expert selection for diffusion policies as an offline contextual bandit problem and propose a Bayesian framework for pessimistic, uncertainty-aware strategy selection. A multi-head Variational Bayesian Last Layer (VBLL) model predicts the expected tracking performance of each expert strategy given the current belief state, providing both a point estimate and predictive uncertainty. Following the pessimism principle for offline decision-making, a Lower Confidence Bound (LCB) criterion then selects the expert whose worst-case predicted performance is best, avoiding overcommitment to experts with unreliable predictions. The selected expert conditions a diffusion policy to generate corresponding action sequences. Experiments on simulated indoor tracking scenarios demonstrate that our approach outperforms both the base diffusion policy and standard gating methods, including Mixture-of-Experts selection and deterministic regression baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a method for active multi-target tracking that combines diffusion policies with Bayesian expert selection. It casts expert selection as an offline contextual bandit problem, uses a multi-head Variational Bayesian Last Layer (VBLL) to predict each expert strategy's expected tracking performance and uncertainty from the current belief state, applies a Lower Confidence Bound (LCB) criterion to select the expert with the best worst-case prediction, and conditions a diffusion policy on the chosen expert to generate actions. The abstract states that experiments on simulated indoor tracking scenarios show outperformance over the base diffusion policy, Mixture-of-Experts gating, and deterministic regression baselines.
Significance. If the empirical claims are supported by quantitative results and the VBLL uncertainties are shown to be calibrated, the approach could provide a principled way to incorporate pessimism and uncertainty awareness into diffusion policies for robotic tracking tasks. It extends standard diffusion and Bayesian techniques to a new selection setting without introducing new free parameters beyond the standard formulations. The absence of any reported metrics, ablations, or calibration checks currently prevents a full assessment of whether these potential benefits are realized.
major comments (2)
- [Abstract] Abstract: the claim that the method 'outperforms both the base diffusion policy and standard gating methods' is presented without any quantitative metrics, statistical details, experimental setup, number of trials, or ablation results, leaving the central empirical claim without load-bearing evidence.
- [Method (VBLL/LCB)] VBLL and LCB formulation: the offline bandit guarantee relies on the multi-head VBLL producing well-calibrated predictive uncertainties so that the LCB criterion correctly implements pessimism; no calibration diagnostics, coverage checks, or ablation isolating the uncertainty term are supplied, which directly affects whether the selected expert corresponds to true worst-case performance.
minor comments (2)
- [Method] Provide the precise mathematical definition of the belief state input to the VBLL and how the multi-head outputs are aggregated.
- [Experiments] Add a table or figure reporting tracking error, detection rate, and runtime metrics with standard deviations across repeated trials.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract requires quantitative support and that calibration evidence for the VBLL uncertainties is needed to substantiate the LCB selection. We will make the requested revisions to strengthen the empirical claims and methodological validation. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'outperforms both the base diffusion policy and standard gating methods' is presented without any quantitative metrics, statistical details, experimental setup, number of trials, or ablation results, leaving the central empirical claim without load-bearing evidence.
Authors: We agree that the abstract should include quantitative evidence. In the revised manuscript we will update the abstract to report specific metrics (e.g., mean tracking error reductions with standard deviations), the number of independent trials, statistical significance tests, and explicit references to the experimental setup and ablation studies already present in the main text. This will directly support the outperformance claim with load-bearing numbers. revision: yes
-
Referee: [Method (VBLL/LCB)] VBLL and LCB formulation: the offline bandit guarantee relies on the multi-head VBLL producing well-calibrated predictive uncertainties so that the LCB criterion correctly implements pessimism; no calibration diagnostics, coverage checks, or ablation isolating the uncertainty term are supplied, which directly affects whether the selected expert corresponds to true worst-case performance.
Authors: We acknowledge that the LCB selection's validity depends on well-calibrated VBLL uncertainties. We will add calibration diagnostics (reliability diagrams and coverage probabilities) and an ablation that isolates the uncertainty term within the LCB criterion. These additions will verify calibration and confirm that expert selection aligns with worst-case performance under the offline bandit formulation. revision: yes
Circularity Check
Standard techniques applied to new domain without load-bearing self-reference or definitional reduction
full rationale
The paper formulates expert selection as an offline contextual bandit and applies multi-head VBLL for point estimates plus uncertainty, followed by LCB selection to condition a diffusion policy. No equation reduces the claimed performance gain to a parameter fitted on the same data or to a self-citation chain; the derivation remains self-contained by composing existing diffusion, variational Bayesian, and pessimism-in-bandits components. The single minor self-citation (if present in the full methods) is not load-bearing for the central claim, which rests on simulated experiments rather than tautological re-derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The multi-head Variational Bayesian Last Layer model produces both point estimates and predictive uncertainty for each expert strategy's expected tracking performance from the belief state.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formulate expert selection for diffusion policies as an offline contextual bandit problem... multi-head Variational Bayesian Last Layer (VBLL) model predicts the expected tracking performance... Lower Confidence Bound (LCB) criterion
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearExperiments on simulated indoor tracking scenarios demonstrate that our approach outperforms both the base diffusion policy and standard gating methods
Reference graph
Works this paper leans on
-
[1]
N. Sun, J. Zhao, Q. Shi, C. Liu, and P. Liu Moving target tracking by unmanned aerial vehicle: A survey and taxonomy IEEE Transactions on Industrial Informatics, vol. 20, no. 5, pp. 7056–7068, 2024
work page 2024
-
[2]
A. O. Hero and D. Cochran Sensor management: Past, present, and future IEEE Sensors Journal, vol. 11, no. 12, pp. 3064–3075, 2011
work page 2011
-
[3]
P. Bostr ¨om-Rost, D. Axehill, and G. Hendeby Sensor management for search and track using the poisson multi-bernoulli mixture filter IEEE Transactions on Aerospace and Electronic Systems, vol. 57, no. 5, pp. 2771–2783, 2021
work page 2021
-
[4]
P. Bostr ¨om-Rost, D. Axehill, and G. Hendeby Pmbm filter with partially grid-based birth model with applica- tions in sensor management IEEE Transactions on Aerospace and Electronic Systems, vol. 58, no. 1, pp. 530–540, 2021
work page 2021
-
[5]
S. Liu, N. Atanasov, and S. Koga Matt-diff: Multimodal active target tracking by diffusion policy arXiv preprint arXiv:2511.11931, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
B. Schlotfeldt, D. Thakur, N. Atanasov, V . Kumar, and G. J. Pappas Anytime planning for decentralized multirobot active informa- tion gathering IEEE Robotics and Automation Letters, vol. 3, no. 2, pp. 1025– 1032, 2018
work page 2018
-
[7]
S. M. LaValle, H. H. Gonz ´alez-Banos, C. Becker, and J.-C. Latombe Motion strategies for maintaining visibility of a moving target InProceedings of international conference on robotics and automation, vol. 1. IEEE, 1997, pp. 731–736
work page 1997
-
[8]
S. Ragi and E. K. Chong Uav path planning in a dynamic environment via partially observable markov decision process IEEE Transactions on Aerospace and Electronic Systems, vol. 49, no. 4, pp. 2397–2412, 2013
work page 2013
-
[9]
J. Le Ny and G. J. Pappas On trajectory optimization for active sensing in gaussian process models InProceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference. IEEE, 2009, pp. 6286–6292
work page 2009
- [10]
-
[11]
P. Yang, S. Koga, A. Asgharivaskasi, and N. Atanasov Policy learning for active target tracking over continuousse(3) trajectories InLearning for Dynamics and Control Conference. PMLR, 2023, pp. 64–75
work page 2023
-
[12]
Imitating human behaviour with diffusion models.arXiv preprint arXiv:2301.10677, 2023
T. Pearceet al. Imitating human behaviour with diffusion models arXiv preprint arXiv:2301.10677, 2023
-
[13]
S. R. Sudha, M. Popovi ´c, and E. M. Coates 8 IEEE TRANSACTIONS ON AEROSPACE AND ELECTRONIC SYSTEMS VOL. XX, No. XX XXXXX 2026 An informative planning framework for target tracking and active mapping in dynamic environments with asvs IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 2690– 2697, 2026
work page 2026
-
[14]
J. Lew, Y . Cao, D. M. S. Tan, and G. Sartoretti Aid: Agent intent from diffusion for multi-agent informative path planning arXiv preprint arXiv:2512.02535, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
S. Karaman and E. Frazzoli Sampling-based algorithms for optimal motion planning International Journal of Robotics Research, vol. 30, no. 7, pp. 846–894, 2011
work page 2011
- [16]
-
[17]
J. Ho, A. Jain, and P. Abbeel Denoising diffusion probabilistic models InProc. Adv. Neural Inf. Process. Syst., vol. 33, 2020, pp. 6840– 6851
work page 2020
- [18]
-
[19]
A. Sridhar, D. Shah, C. Glossop, and S. Levine Nomad: Goal masked diffusion policies for navigation and exploration In2024 IEEE International Conference on Robotics and Au- tomation (ICRA). IEEE, 2024, pp. 63–70
work page 2024
-
[20]
Y . Cao, J. Lew, J. Liang, J. Cheng, and G. Sartoretti Dare: Diffusion policy for autonomous robot exploration In2025 IEEE International Conference on Robotics and Au- tomation (ICRA). IEEE, 2025, pp. 11 987–11 993
work page 2025
-
[21]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
S. Liuet al. Rdt-1b: a diffusion foundation model for bimanual manipulation arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
O. M. Teamet al. Octo: An open-source generalist robot policy arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [23]
- [24]
-
[25]
Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning,
Y . Wanget al. Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning arXiv preprint arXiv:2407.01531, 2024
-
[26]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeeret al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [27]
-
[28]
A. Hendawy, J. Peters, and C. D’Eramo Multi-task reinforcement learning with mixture of orthogonal experts arXiv preprint arXiv:2311.11385, 2023
-
[29]
L. Li, W. Chu, J. Langford, and R. E. Schapire A contextual-bandit approach to personalized news article rec- ommendation InProceedings of the 19th international conference on World wide web, 2010, pp. 661–670
work page 2010
-
[30]
D. J. Russo, B. Van Roy, A. Kazerouni, I. Osband, Z. Wenet al. A Tutorial on Thompson Sampling Foundations and Trends® in Machine Learning, vol. 11, no. 1, pp. 1–96, 2018
work page 2018
-
[31]
T. Nguyen-Tang, S. Gupta, A. T. Nguyen, and S. Venkatesh Offline neural contextual bandits: Pessimism, optimization and generalization arXiv preprint arXiv:2111.13807, 2021
-
[32]
J. Harrison, J. Willes, and J. Snoek Variational Bayesian Last Layers Proc. Int. Conf. Learn. Represent., 2024
work page 2024
-
[33]
L. Zhou, V . Tzoumas, G. J. Pappas, and P. Tokekar Resilient active target tracking with multiple robots IEEE Robotics and Automation Letters, vol. 4, no. 1, pp. 129– 136, 2018
work page 2018
- [34]
-
[35]
H. Duan, J. Zhao, Y . Deng, Y . Shi, and X. Ding Dynamic discrete pigeon-inspired optimization for multi-uav cooperative search-attack mission planning IEEE Transactions on Aerospace and Electronic Systems, vol. 57, no. 1, pp. 706–720, 2020
work page 2020
-
[36]
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra Weight uncertainty in neural network InInternational conference on machine learning. PMLR, 2015, pp. 1613–1622
work page 2015
-
[37]
B. Lakshminarayanan, A. Pritzel, and C. Blundell Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017
work page 2017
- [38]
-
[39]
Y . Ovadiaet al. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift Advances in neural information processing systems, vol. 32, 2019
work page 2019
- [40]
- [41]
- [42]
-
[43]
W. R. Thompson On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples Biometrika, vol. 25, no. 3/4, pp. 285–294, 1933
work page 1933
-
[44]
P. Auer, N. Cesa-Bianchi, and P. Fischer Finite-time analysis of the multiarmed bandit problem Machine learning, vol. 47, no. 2, pp. 235–256, 2002
work page 2002
-
[45]
C. Riquelme, G. Tucker, and J. Snoek Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling arXiv preprint arXiv:1802.09127, 2018
- [46]
- [47]
-
[48]
B. Yamauchi A frontier-based approach for autonomous exploration InIEEE International Symposium on Computational Intelli- gence in Robotics and Automation (CIRA), 1997, pp. 146–151
work page 1997
-
[49]
K. M. Choromanskiet al. Rethinking attention with Performers InProc. Int. Conf. Learn. Represent., 2021
work page 2021
-
[50]
P. Brunzema, M. Jordahn, J. Willes, S. Trimpe, J. Snoek, and J. Harrison Bayesian Optimization via Continual Variational Last Layer Training Proc. Int. Conf. Learn. Represent., 2025
work page 2025
-
[51]
A. Swaminathan and T. Joachims Batch learning from logged bandit feedback through counter- factual risk minimization The Journal of Machine Learning Research, vol. 16, no. 1, pp. 1731–1755, 2015
work page 2015
-
[52]
S. Li, Z. Li, J. Xiao, Y . He, B. Zhong, and Z. Li HouseExpo: A large-scale 2d indoor layout dataset for learning- based algorithms on mobile robots InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 5839–5846
work page 2020
-
[53]
ISIF Yaakov Bar-Shalom Award for Lifetime of Excellence in Information Fusion
X. R. Li and V . P. Jilkov Survey of maneuvering target tracking. part i. dynamic models IEEE Transactions on aerospace and electronic systems, vol. 39, no. 4, pp. 1333–1364, 2003. Haotian Xiang(Student Member, IEEE) re- ceived the B.S. degree in electrical engineering from the University of Electronic Science and Technology of China in 2022, and the M.S....
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.