Recognition: 2 theorem links
· Lean TheoremKiToke: Kernel-based Interval-aware Token Compression for Video Large Language Models
Pith reviewed 2026-05-13 20:09 UTC · model grok-4.3
The pith
KiToke reduces visual tokens in Video LLMs to 1% retention using a kernel-based global redundancy measure and interval-aware merging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
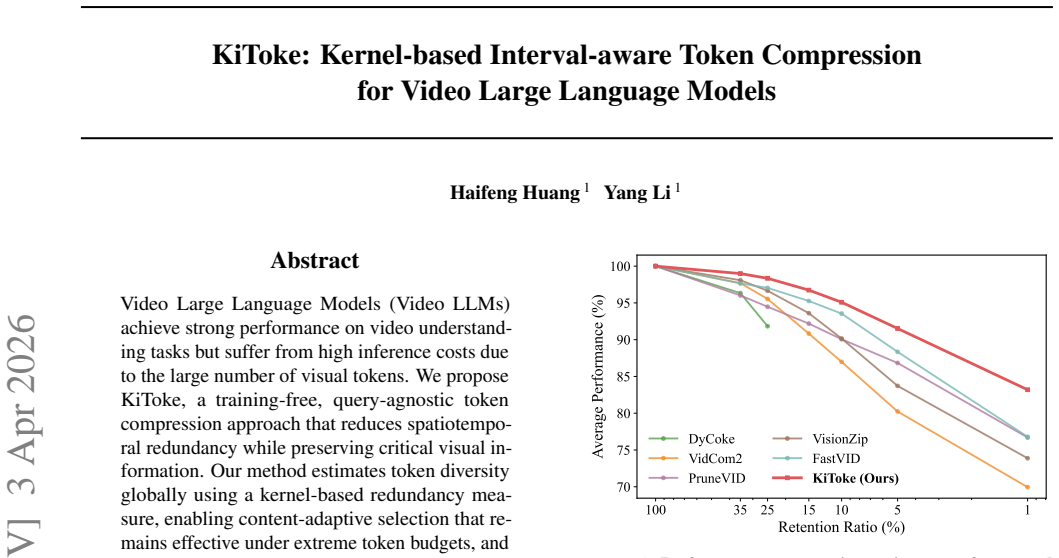
KiToke estimates token diversity globally using a kernel-based redundancy measure, enabling content-adaptive selection that remains effective under extreme token budgets, and further introduces a lightweight temporal interval construction with interval-aware token merging to maintain temporal coherence, outperforming existing training-free compression methods particularly at aggressive retention ratios down to 1%.
What carries the argument
Kernel-based global redundancy measure that scores diversity across an entire video, paired with lightweight temporal interval construction and interval-aware token merging to preserve coherence.
Load-bearing premise
The kernel-based global redundancy measure combined with interval-aware merging preserves critical visual information across diverse video content without significant loss compared to local or segment-level heuristics.
What would settle it
Videos containing rapid scene changes where KiToke drops task accuracy more than segment-level baselines at 1% retention ratio.
Figures









read the original abstract
Video Large Language Models (Video LLMs) achieve strong performance on video understanding tasks but suffer from high inference costs due to the large number of visual tokens. We propose KiToke, a training-free, query-agnostic token compression approach that reduces spatiotemporal redundancy while preserving critical visual information. Our method estimates token diversity globally using a kernel-based redundancy measure, enabling content-adaptive selection that remains effective under extreme token budgets, and further introduces a lightweight temporal interval construction with interval-aware token merging to maintain temporal coherence. Unlike prior methods that rely on local or segment-level heuristics, KiToke explicitly captures global redundancy across an entire video, leading to more efficient token utilization. Extensive experiments on multiple video understanding benchmarks and Video LLM backbones demonstrate that KiToke consistently outperforms existing training-free compression methods, with particularly large gains at aggressive retention ratios down to 1%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KiToke, a training-free and query-agnostic token compression method for Video LLMs. It estimates global spatiotemporal redundancy via a kernel-based measure for content-adaptive token selection, then applies lightweight temporal interval construction and interval-aware merging to preserve coherence. The central claim is that this global approach outperforms prior local or segment-level heuristics on video understanding benchmarks, with especially large gains at aggressive retention ratios down to 1%.
Significance. If the empirical claims hold, KiToke would offer a practical, training-free route to lower inference cost in Video LLMs while retaining performance under tight token budgets. The emphasis on global redundancy rather than local heuristics is a clear methodological distinction that could influence subsequent compression work.
major comments (2)
- [Abstract] Abstract: the claim that KiToke 'consistently outperforms existing training-free compression methods, with particularly large gains at aggressive retention ratios down to 1%' is presented without any named benchmarks, baselines, retention-ratio tables, or statistical tests. This absence makes it impossible to evaluate whether the reported gains are robust or confounded by choice of video content or backbone.
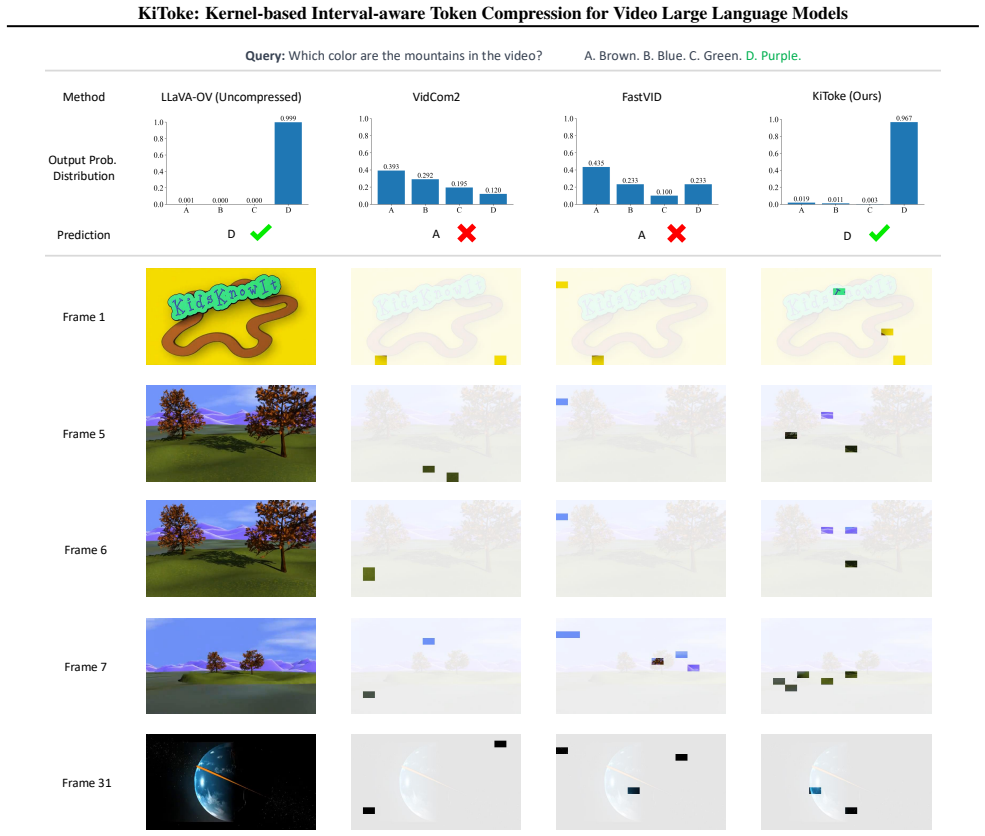
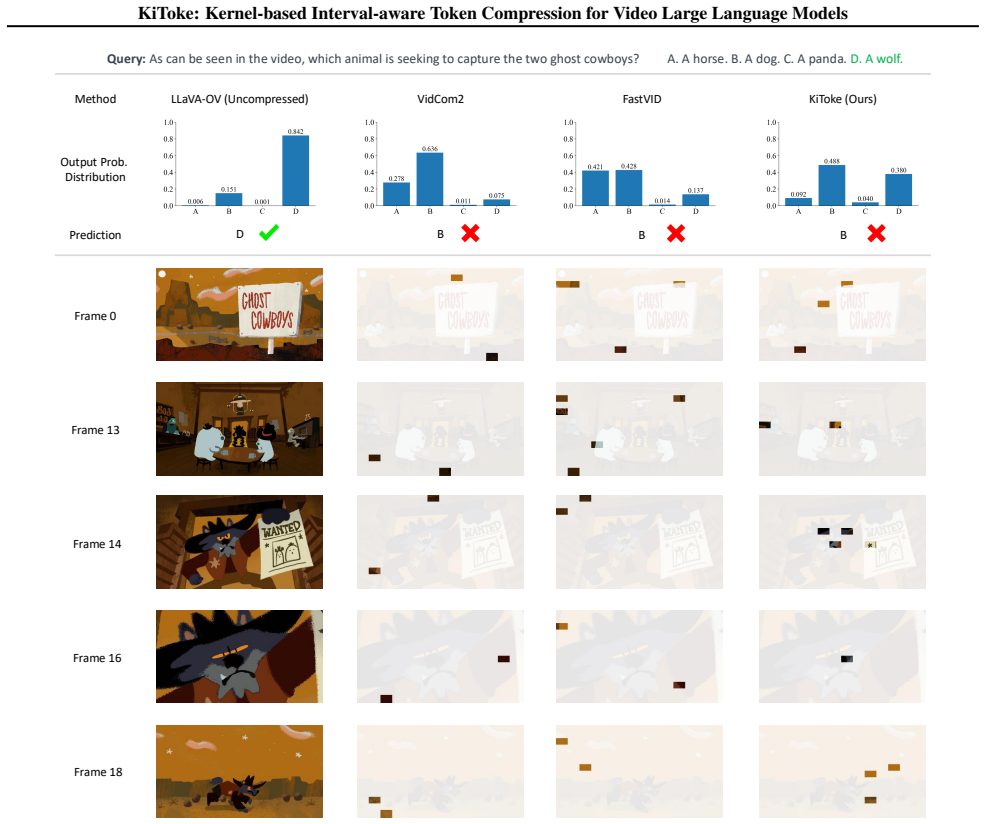
- [Abstract] Abstract and method description: because the kernel operates solely on visual token features in a query-agnostic manner, tokens that are globally redundant by the kernel metric may still be the sole carriers of information required by a downstream textual query. At 1% retention this creates an information bottleneck that local heuristics might avoid by chance; the manuscript must demonstrate (via query-specific ablations or failure-case analysis) that the chosen kernel bandwidth and similarity threshold align with task semantics rather than purely visual statistics.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments on multiple video understanding benchmarks and Video LLM backbones' but supplies no concrete list; adding the specific datasets and models to the abstract would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying our approach and indicating revisions where they strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that KiToke 'consistently outperforms existing training-free compression methods, with particularly large gains at aggressive retention ratios down to 1%' is presented without any named benchmarks, baselines, retention-ratio tables, or statistical tests. This absence makes it impossible to evaluate whether the reported gains are robust or confounded by choice of video content or backbone.
Authors: We agree that the abstract is concise and omits specific benchmark names and quantitative highlights, which limits immediate evaluability. The full manuscript (Section 4 and associated tables) reports results on standard benchmarks including Video-MME, ActivityNet-QA, and MSVD-QA, with direct comparisons to training-free baselines such as FastV, ToMe, and LLaVA-Pru across retention ratios from 50% to 1%, including statistical significance where applicable. We will revise the abstract to name the primary benchmarks and briefly summarize the key gains at low retention ratios. revision: yes
-
Referee: [Abstract] Abstract and method description: because the kernel operates solely on visual token features in a query-agnostic manner, tokens that are globally redundant by the kernel metric may still be the sole carriers of information required by a downstream textual query. At 1% retention this creates an information bottleneck that local heuristics might avoid by chance; the manuscript must demonstrate (via query-specific ablations or failure-case analysis) that the chosen kernel bandwidth and similarity threshold align with task semantics rather than purely visual statistics.
Authors: The query-agnostic design is intentional, as it enables compression in practical settings where the downstream query is unavailable at inference time (e.g., multi-turn or streaming scenarios). The kernel-based global redundancy measure is computed solely on visual features to identify content-adaptive tokens that reduce spatiotemporal redundancy across the full video. While query-specific tokens could theoretically be lost, our experiments across diverse video understanding tasks demonstrate consistent outperformance even at 1% retention, suggesting the selected tokens preserve task-relevant information. We will add a dedicated discussion subsection on this design choice, including failure-case examples and analysis of how kernel parameters relate to semantic content, though a full query-aware ablation would require a fundamentally different method variant outside the current scope. revision: partial
Circularity Check
No significant circularity; method is empirical and externally validated
full rationale
The paper introduces a training-free token compression technique using a kernel-based global redundancy measure and interval-aware merging. Performance claims rest on experimental comparisons against prior methods on standard benchmarks, not on any derivation that reduces by construction to fitted parameters, self-definitions, or self-citation chains. No equations or steps in the abstract or description equate outputs to inputs via renaming or ansatz smuggling. The query-agnostic design is explicitly stated as a deliberate choice rather than a hidden tautology.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adapt KDE to measure how densely each visual token is surrounded by others in embedding space... Di = Σ K(xi,xj) with K(xi,xj)=exp(−∥xi−xj∥²/(2α))
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
diversity-weighted sampling... interval-aware token merging
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
EchoPrune: Interpreting Redundancy as Temporal Echoes for Efficient VideoLLMs
EchoPrune prunes video tokens via query relevance and temporal reconstruction error to let VideoLLMs handle up to 20x more frames under fixed budget with reported gains in accuracy and speed.
Reference graph
Works this paper leans on
-
[1]
Additional experimental and reproduction details are provided in Appendix A
-
[2]
Additional ablations and qualitative results are provided in Appendix B
-
[3]
Additional discussions on method comparison and future work are provided in Appendix C. We provide the complete code, including implementations of all reproduced methods, in the Supplementary Material and will release it publicly. A. Experimental Details A.1. Reproduction Details of Compared Baselines All experiments are conducted using LMMs-Eval2 (Zhang ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.