Recognition: 2 theorem links
· Lean TheoremCultural Authenticity: Comparing LLM Cultural Representations to Native Human Expectations
Pith reviewed 2026-05-13 19:10 UTC · model grok-4.3
The pith
LLMs show Western-centric calibration with alignment to native cultural priorities dropping as distance from US culture grows, plus shared systemic errors across models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We establish human-derived Cultural Importance Vectors from open-ended survey responses collected across nine countries as a baseline for local cultural priorities. Using a syntactically diversified prompt set we compute model-derived Cultural Representation Vectors for Gemini 2.5 Pro, GPT-4o, and Claude 3.5 Haiku. Alignment between the two vector sets decreases with increasing cultural distance from the US for some models, while all models display highly correlated systemic error signatures (ρ > 0.97) that over-index on selected markers and neglect deep-seated social and value-based priorities.
What carries the argument
Comparison of human-derived Cultural Importance Vectors and LLM-derived Cultural Representation Vectors to measure alignment and detect shared error patterns.
If this is right
- Models calibrated toward Western priorities will generate less authentic content for culturally distant nations.
- The near-identical error signatures across unrelated LLMs indicate common limitations in current training data.
- Cultural evaluation of AI must incorporate native priority rankings instead of relying solely on diversity statistics.
- Neglect of social and value-based facets risks producing culturally inauthentic outputs in global applications.
Where Pith is reading between the lines
- The vector comparison method could be applied to additional countries or to open-source models to map bias more broadly.
- Training adjustments guided by these importance vectors might improve fidelity for specific non-Western regions.
- The high cross-model correlation in errors suggests that targeted fixes on one system could transfer to others.
- Longitudinal re-testing with future model releases would show whether the Western-centric pattern persists or diminishes.
Load-bearing premise
The open-ended survey responses collected across nine countries produce stable, representative Cultural Importance Vectors that accurately reflect native population priorities.
What would settle it
If new surveys using larger or demographically different samples from the same nine countries produce substantially different importance vectors, or if alternative prompt sets yield different representation vectors, the reported alignment trends and error correlations would no longer hold.
Figures



read the original abstract
Cultural representation in Large Language Model (LLM) outputs has primarily been evaluated through the proxies of cultural diversity and factual accuracy. However, a crucial gap remains in assessing cultural alignment: the degree to which generated content mirrors how native populations perceive and prioritize their own cultural facets. In this paper, we introduce a human-centered framework to evaluate the alignment of LLM generations with local expectations. First, we establish a human-derived ground-truth baseline of importance vectors, called Cultural Importance Vectors based on an induced set of culturally significant facets from open-ended survey responses collected across nine countries. Next, we introduce a method to compute model-derived Cultural Representation Vectors of an LLM based on a syntactically diversified prompt-set and apply it to three frontier LLMs (Gemini 2.5 Pro, GPT-4o, and Claude 3.5 Haiku). Our investigation of the alignment between the human-derived Cultural Importance and model-derived Cultural Representations reveals a Western-centric calibration for some of the models where alignment decreases as a country's cultural distance from the US increases. Furthermore, we identify highly correlated, systemic error signatures ($\rho > 0.97$) across all models, which over-index on some cultural markers while neglecting the deep-seated social and value-based priorities of users. Our approach moves beyond simple diversity metrics toward evaluating the fidelity of AI-generated content in authentically capturing the nuanced hierarchies of global cultures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a human-centered framework to evaluate LLM cultural alignment by deriving Cultural Importance Vectors from open-ended survey responses across nine countries and Cultural Representation Vectors from three frontier LLMs (Gemini 2.5 Pro, GPT-4o, Claude 3.5 Haiku) via syntactically diversified prompts. It reports that some models exhibit Western-centric calibration, with alignment decreasing as cultural distance from the US increases, alongside highly correlated systemic error signatures (ρ > 0.97) that over-index on certain markers while neglecting social and value-based priorities.
Significance. If the vectors prove robust, the work would meaningfully advance evaluation of cultural authenticity in LLMs by moving beyond diversity and accuracy proxies to assess fidelity with native priority hierarchies. The cross-model error correlation finding is a notable strength that could inform targeted debiasing, and the human-survey baseline offers a falsifiable, population-grounded approach.
major comments (2)
- [Survey and Vector Construction] The construction of Cultural Importance Vectors from open-ended survey responses (described in the abstract and methods) omits sample sizes per country, demographic quotas matching national populations, translation protocols, and inter-rater reliability metrics for facet coding. This directly threatens the validity of the subsequent alignment correlations and the Western-centric calibration claim.
- [Results and Analysis] The reported decrease in alignment with cultural distance from the US and the ρ > 0.97 error signatures (abstract) depend on stable, representative vectors; without explicit aggregation rules, normalization, or controls for response-style bias in the human data, these quantities risk reflecting methodological artifacts rather than genuine cultural misalignment.
minor comments (1)
- [Abstract] The abstract refers to a 'syntactically diversified prompt-set' without specifying the diversification criteria or number of prompts per facet; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. The comments highlight important areas for improving methodological transparency, which we address point by point below. We commit to revisions that strengthen the reporting without altering the core findings.
read point-by-point responses
-
Referee: [Survey and Vector Construction] The construction of Cultural Importance Vectors from open-ended survey responses (described in the abstract and methods) omits sample sizes per country, demographic quotas matching national populations, translation protocols, and inter-rater reliability metrics for facet coding. This directly threatens the validity of the subsequent alignment correlations and the Western-centric calibration claim.
Authors: We agree that the submitted manuscript's abstract and methods section provided insufficient detail on these elements, which limits full evaluation of the vectors' robustness. In the revised version, we will expand the Methods section with a dedicated survey methodology subsection reporting the exact sample sizes per country, demographic quotas aligned with national census data, professional translation and back-translation protocols, and inter-rater reliability metrics (including Krippendorff's alpha) for the facet coding process. These additions will directly support the validity of the alignment correlations and Western-centric calibration results. revision: yes
-
Referee: [Results and Analysis] The reported decrease in alignment with cultural distance from the US and the ρ > 0.97 error signatures (abstract) depend on stable, representative vectors; without explicit aggregation rules, normalization, or controls for response-style bias in the human data, these quantities risk reflecting methodological artifacts rather than genuine cultural misalignment.
Authors: We acknowledge the need for greater explicitness here. The Cultural Importance Vectors are constructed via per-country averaging of facet importance ratings followed by L1 normalization to produce probability distributions; response-style bias is addressed by emphasizing relative within-country rankings rather than absolute scores. We will revise the manuscript to include a precise description of these aggregation and normalization rules, the mathematical formulation for the error vectors, and the Pearson correlation computation for the ρ > 0.97 signatures. We will also add robustness checks, including bootstrap resampling and alternative normalizations, to demonstrate that the alignment trends with cultural distance and the cross-model error correlations are not artifacts. revision: yes
Circularity Check
No significant circularity; human and model vectors derived independently
full rationale
The paper constructs Cultural Importance Vectors directly from open-ended survey responses collected across nine countries and Cultural Representation Vectors from LLM outputs on a separate syntactically diversified prompt set. Alignment metrics and error correlations are then computed between these two independently sourced vectors. No equations define one vector in terms of the other, no parameters are fitted to the alignment target, and no self-citations or prior author results are invoked to justify the core comparison. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Open-ended survey responses from nine countries produce representative Cultural Importance Vectors that reflect native priorities.
- domain assumption Syntactically diversified prompts elicit representative Cultural Representation Vectors from frontier LLMs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
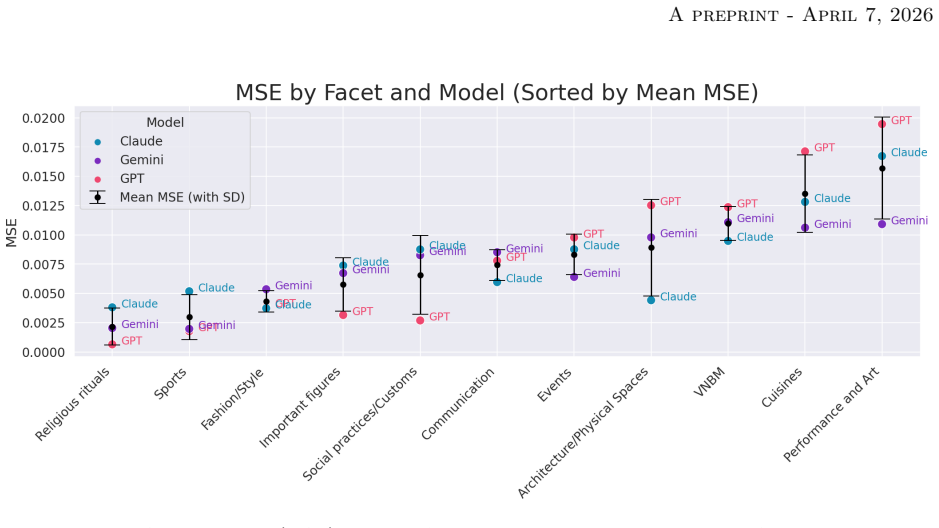
We quantify the alignment between the Cultural Representation Vector ^vc,M and the Cultural Importance Vector vc using Pearson Correlation Coefficient (ρ) ... Cosine Similarity ... Mean Squared Error (MSE)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Culturax: A cleaned, enormous, and multilingual dataset for large language models in 167 languages
Thuật Nguyễn, Chien Van Nguyen, Viet Dac Lai, Hiếu Mẫn, Nghia Trung Ngo, Franck Dernoncourt, Ryan A Rossi, and Thien Huu Nguyen. Culturax: A cleaned, enormous, and multilingual dataset for large language models in 167 languages. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-...
work page 2024
-
[2]
Normad: A framework for measuring the cultural adaptability of large language models
Abhinav Sukumar Rao, Akhila Yerukola, Vishwa Shah, Katharina Reinecke, and Maarten Sap. Normad: A framework for measuring the cultural adaptability of large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pa...
work page 2025
-
[3]
Hannah R Kirk, Alexander Whitefield, Paul Röttger, Andrew Bean, Katerina Margatina, Juan Ciro, Rafael Mosquera, Max Bartolo, Adina Williams, He He, et al. The prism alignment dataset: What participatory, representative and individualised human feedback reveals about the subjective and mul- ticultural alignment of large language models. Advances in Neural ...
work page 2024
-
[4]
Randomness, not representation: The un- reliability of evaluating cultural alignment in llms
Ariba Khan, Stephen Casper, and Dylan Hadfield-Menell. Randomness, not representation: The un- reliability of evaluating cultural alignment in llms. In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 2151–2165, 2025
work page 2025
-
[5]
arXiv preprint arXiv:2306.16388 , year =
Esin Durmus, Karina Nguyen, Thomas I Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, et al. Towards measuring the representation of subjective global opinions in language models. arXiv preprint arXiv:2306.16388 , 2023
-
[6]
Evaluating cultural awareness of llms for yoruba, malayalam, and english
Fiifi Dawson, Zainab Mosunmola, Sahil Pocker, Raj Abhijit Dandekar, Rajat Dandekar, and Sreedath Panat. Evaluating cultural awareness of llms for yoruba, malayalam, and english. arXiv preprint arXiv:2410.01811, 2024
-
[7]
Can the subaltern speak? In Imperialism, pages 171–219
Gayatri Chakravorty Spivak. Can the subaltern speak? In Imperialism, pages 171–219. Routledge, 2023
work page 2023
-
[8]
Edward W Said. Orientalism. The Georgia Review , 31(1):162–206, 1977. 9 A preprint - April 7, 2026
work page 1977
-
[9]
Towards measuring and modeling “culture” in LLMs: A survey
Muhammad Farid Adilazuarda, Sagnik Mukherjee, Pradhyumna Lavania, Siddhant Shivdutt Singh, Alham Fikri Aji, Jacki O’Neill, Ashutosh Modi, and Monojit Choudhury. Towards measuring and modeling “culture” in LLMs: A survey. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Langua...
work page 2024
-
[10]
A unified framework to quantify cultural intelligence of ai
Sunipa Dev, Vinodkumar Prabhakaran, Rutledge Chin Feman, Aida Davani, Remi Denton, Charu Kalia, Piyawat L Kumjorn, Madhurima Maji, Rida Qadri, Negar Rostamzadeh, et al. A unified framework to quantify cultural intelligence of ai. arXiv preprint arXiv:2603.01211 , 2026
-
[11]
Man and his works; the science of cultural anthropology
Melville J Herskovits. Man and his works; the science of cultural anthropology. 1949
work page 1949
-
[12]
Does country equate with culture? beyond geography in the search for cultural boundaries
Vas Taras, Piers Steel, and Bradley L Kirkman. Does country equate with culture? beyond geography in the search for cultural boundaries. Management International Review , 56(4):455–487, 2016
work page 2016
-
[13]
How culture shapes what people want from ai
Xiao Ge, Chunchen Xu, Daigo Misaki, Hazel Rose Markus, and Jeanne L Tsai. How culture shapes what people want from ai. In Proceedings of the 2024 CHI conference on human factors in computing systems, pages 1–15, 2024
work page 2024
-
[14]
Cultural learning-based culture adaptation of language models
Chen Cecilia Liu, Anna Korhonen, and Iryna Gurevych. Cultural learning-based culture adaptation of language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pile- hvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 3114–3134, Vienna, Austria, Ju...
work page 2025
-
[15]
Self-pluralising culture alignment for large language models
Shaoyang Xu, Yongqi Leng, Linhao Yu, and Deyi Xiong. Self-pluralising culture alignment for large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages 6859–6877, 2025
work page 2025
-
[16]
Neha Srikanth, Jordan Boyd-Graber, and Rachel Rudinger
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell Gordon, Niloofar Mireshghallah, Christo- pher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, et al. A roadmap to pluralistic alignment. arXiv preprint arXiv:2402.05070 , 2024
-
[17]
Culturally-aware conversations: A framework & benchmark for llms
Shreya Havaldar, Young Min Cho, Sunny Rai, and Lyle Ungar. Culturally-aware conversations: A framework & benchmark for llms. In Proceedings of the Fourth Workshop on Bridging Human-Computer Interaction and Natural Language Processing (HCI+ NLP) , pages 220–229, 2025
work page 2025
-
[18]
SHADES: Towards a multilingual assessment of stereotypes in large language models
Margaret Mitchell, Giuseppe Attanasio, Ioana Baldini, Miruna Clinciu, Jordan Clive, Pieter Delobelle, Manan Dey, Sil Hamilton, Timm Dill, Jad Doughman, Ritam Dutt, A vijit Ghosh, Jessica Zosa Forde, Carolin Holtermann, Lucie-Aimée Kaffee, Tanmay Laud, Anne Lauscher, Roberto L Lopez-Davila, Maraim Masoud, Nikita Nangia, Anaelia Ovalle, Giada Pistilli, Drag...
work page 2025
-
[19]
Cross-cultural analysis of human values, morals, and biases in folk tales
Winston Wu, Lu Wang, and Rada Mihalcea. Cross-cultural analysis of human values, morals, and biases in folk tales. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 5113–5125, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[20]
Biased tales: Cultural and topic bias in generating children’s stories
Donya Rooein, Vilém Zouhar, Debora Nozza, and Dirk Hovy. Biased tales: Cultural and topic bias in generating children’s stories. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 52–72, Suzhou, China, November 2025. Assoc...
work page 2025
-
[21]
Extrinsic evaluation of cultural competence in large language models
Shaily Bhatt and Fernando Diaz. Extrinsic evaluation of cultural competence in large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024 , pages 16055–16074, Miami, Florida, USA, November 2024. Association for Computational Linguistics. 10 A preprint - April 7, 2026
work page 2024
-
[22]
Mohammad Atari, Mona J Xue, Peter S Park, Damián Blasi, and Joseph Henrich. Which humans? 2023
work page 2023
-
[23]
Investigating cultural alignment of large language models
Badr AlKhamissi, Muhammad ElNokrashy, Mai Alkhamissi, and Mona Diab. Investigating cultural alignment of large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 12404–12422, Bangkok, Thailand, August 2024. Assoc...
work page 2024
-
[24]
Cultural dimensions in management and planning
Geert Hofstede. Cultural dimensions in management and planning. Asia Pacific journal of management , 1(2):81–99, 1984
work page 1984
-
[25]
Treleaven, and Miguel Rodrigues Rodrigues
Reem Masoud, Ziquan Liu, Martin Ferianc, Philip C. Treleaven, and Miguel Rodrigues Rodrigues. Cultural alignment in large language models: An explanatory analysis based on hofstede’s cultural di- mensions. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors, Proceedings of the 31st Internati...
work page 2025
-
[26]
Bridging cultural nuances in dialogue agents through cultural value surveys
Yong Cao, Min Chen, and Daniel Hershcovich. Bridging cultural nuances in dialogue agents through cultural value surveys. In Yvette Graham and Matthew Purver, editors, Findings of the Association for Computational Linguistics: EACL 2024 , pages 929–945, St. Julian’s, Malta, March 2024. Association for Computational Linguistics
work page 2024
-
[27]
Esin Durmus, Karina Nguyen, Thomas I. Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, Liane Lovitt, Sam McCandlish, Orowa Sikder, Alex Tamkin, Janel Thamkul, Jared Kaplan, Jack Clark, and Deep Ganguli. Towards measuring the representation of subjective global opinions in language mod...
work page 2024
-
[28]
Latent diversity in human concepts
Louis Marti, Shengyi Wu, Steven T Piantadosi, and Celeste Kidd. Latent diversity in human concepts. Open Mind , 7:79–92, 2023
work page 2023
-
[29]
Cultural perspectives and expectations for generative ai: A global survey approach
Erin van Liemt, Renee Shelby, Andrew Smart, Sinchana Kumbale, Richard Zhang, Neha Dixit, Qazi Ma- munur Rashid, and Jamila Smith-Loud. Cultural perspectives and expectations for generative ai: A global survey approach. arXiv preprint arXiv:2603.05723 , 2026
-
[30]
Ronald Inglehart and Christian Welzel
Rebecca L Johnson, Giada Pistilli, Natalia Menédez-González, Leslye Denisse Dias Duran, Enrico Panai, Julija Kalpokiene, and Donald Jay Bertulfo. The ghost in the machine has an american accent: value conflict in gpt-3. arXiv preprint arXiv:2203.07785 , 2022
-
[31]
Risks of cultural erasure in large language models
Rida Qadri, Aida M Davani, Kevin Robinson, and Vinodkumar Prabhakaran. Risks of cultural erasure in large language models. arXiv preprint arXiv:2501.01056 , 2025
-
[32]
The Major Syntactic Structures of English
Robert Stockwell, Paul Schachter, and Barbara Hall Partee. The Major Syntactic Structures of English . Holt, Rinehart and Winston, Inc., 1973
work page 1973
-
[33]
English Verb Classes and Alternations A Preliminary Investigation
Beth Levin. English Verb Classes and Alternations A Preliminary Investigation . The University of Chicago Press, 1993
work page 1993
-
[34]
Taxonomy of user needs and actions
Renee Shelby, Fernando Diaz, and Vinodkumar Prabhakaran. Taxonomy of user needs and actions. arXiv preprint arXiv:2510.06124 , 2025
-
[35]
Michael Muthukrishna, Adrian V Bell, Joseph Henrich, Cameron M Curtin, Alexander Gedranovich, Jason McInerney, and Braden Thue. Beyond western, educated, industrial, rich, and democratic (weird) psychology: Measuring and mapping scales of cultural and psychological distance. Psychological science, 31(6):678–701, 2020
work page 2020
-
[36]
John Urry. Globalising the tourist gaze. Tourism development revisited: Concepts, issues and paradigms , pages 150–160, 2001
work page 2001
-
[37]
Presentation of self in everyday life
Erving Goffman. Presentation of self in everyday life. American Journal of Sociology , 55(1):6–7, 1949
work page 1949
-
[38]
Disjuncture and difference in the global cultural economy
Arjun Appadurai. Disjuncture and difference in the global cultural economy. In Postcolonlsm, pages 1801–1823. Routledge, 2023. 11 A preprint - April 7, 2026 6 Appendix A Study 1 A.1 Autorater prompt for labeling survey responses Classify the following text into the most relevant cultural categories from the predefined list. Predefined Categories: Architec...
work page 2023
- [39]
-
[40]
Choose the ONE category from “Predefined Categories” that best describes the overall cultural content of the text
-
[41]
If you believe the text does not fit any of the categories, return “OTHER” as the label
-
[42]
text” (the original text analyzed) and “label
Format the output ONLY as a JSON object with two keys: “text” (the original text analyzed) and “label” (the chosen category name from the Predefined Categories, or “OTHER”)
-
[43]
DO NOT provide any explanation or additional text outside the JSON object. Text to Analyze: “{{text_input}}” JSON Output: A.2 Cultural Label Percentages by Country T able Table 5 represents the Cultural Importance Vectors calculated for the various countries. Table 5: [Larger Version] Cultural Label Percentages by Country. Percentages are based on the num...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.