Recognition: no theorem link
Automated Attention Pattern Discovery at Scale in Large Language Models
Pith reviewed 2026-05-13 18:22 UTC · model grok-4.3
The pith
A masked autoencoder on attention patterns from code completions reconstructs them accurately, generalizes across models, and raises generation accuracy 13.6 percent via selective interventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
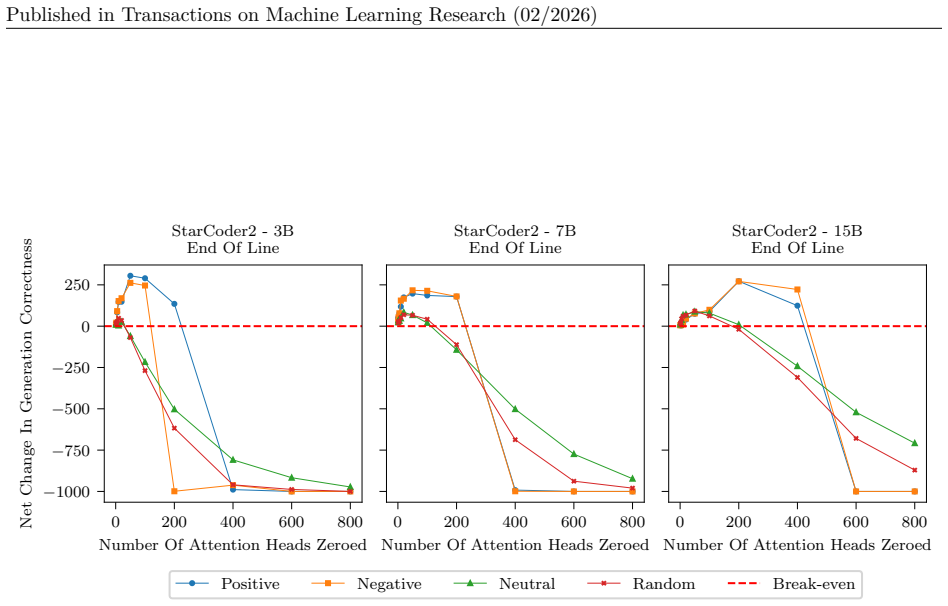
AP-MAE reconstructs masked attention patterns with high accuracy, generalizes across unseen models with minimal degradation, reveals recurring patterns across inferences, predicts whether a generation will be correct without access to ground truth at 55 to 70 percent accuracy depending on the task, and enables targeted interventions that increase accuracy by 13.6 percent when applied selectively but cause collapse when applied excessively.
What carries the argument
The Attention Pattern-Masked Autoencoder (AP-MAE), a vision transformer-based model that reconstructs masked attention patterns collected from LLM heads during structured code completions.
If this is right
- Attention patterns act as a scalable signal that supports global interpretability across large models without per-behavior case studies.
- Recurring patterns can be mined automatically from completion scenarios in structured domains such as code.
- AP-MAE predictions of generation correctness can be used without requiring ground-truth labels.
- Targeted edits to attention patterns improve accuracy when applied selectively and provide a selection procedure for finer mechanistic analysis.
Where Pith is reading between the lines
- The same attention-pattern reconstruction could be tested on non-code tasks to check whether recurring patterns generalize beyond structured data.
- If the 13.6 percent gain holds under broader conditions, AP-MAE outputs might serve as a lightweight prior for steering generation in deployment settings.
- The transferability across models suggests attention templates could be catalogued once and reused to bootstrap interpretability on new architectures.
Load-bearing premise
Attention patterns produced by LLM attention heads can be treated as scalable, image-like signals that vision models can analyze for global interpretability of model components.
What would settle it
Running AP-MAE on a new model family outside StarCoder2 and observing whether reconstruction accuracy falls below the reported high levels or whether the selective intervention gain disappears.
Figures




















read the original abstract
Large language models have found success by scaling up capabilities to work in general settings. The same can unfortunately not be said for interpretability methods. The current trend in mechanistic interpretability is to provide precise explanations of specific behaviors in controlled settings. These often do not generalize, or are too resource intensive for larger studies. In this work we propose to study repeated behaviors in large language models by mining completion scenarios in Java code datasets, through exploiting the structured nature of code. We collect the attention patterns generated in the attention heads to demonstrate that they are scalable signals for global interpretability of model components. We show that vision models offer a promising direction for analyzing attention patterns at scale. To demonstrate this, we introduce the Attention Pattern - Masked Autoencoder(AP-MAE), a vision transformer-based model that efficiently reconstructs masked attention patterns. Experiments on StarCoder2 show that AP-MAE (i) reconstructs masked attention patterns with high accuracy, (ii) generalizes across unseen models with minimal degradation, (iii) reveals recurring patterns across inferences, (iv) predicts whether a generation will be correct without access to ground truth, with accuracies ranging from 55% to 70% depending on the task, and (v) enables targeted interventions that increase accuracy by 13.6% when applied selectively, but cause collapse when applied excessively. These results establish attention patterns as a scalable signal for interpretability and demonstrate that AP-MAE provides a transferable foundation for both analysis and intervention in large language models. Beyond its standalone value, AP-MAE also serves as a selection procedure to guide fine-grained mechanistic approaches. We release code and models to support future work in large-scale interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AP-MAE, a vision-transformer-based masked autoencoder, to mine and reconstruct attention patterns from StarCoder2 on Java code completions. It claims these patterns constitute scalable signals for global LLM interpretability, demonstrating high-fidelity masked reconstruction, cross-model generalization, discovery of recurring patterns, 55-70% accuracy in predicting generation correctness without ground truth, and selective interventions yielding a 13.6% accuracy gain (with collapse under excessive application).
Significance. If the empirical results are robust, the work supplies a practical, transferable foundation for large-scale interpretability by repurposing vision models on attention maps, while also serving as a filter for finer mechanistic studies. The release of code and models is a concrete asset for reproducibility.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the reported reconstruction accuracy, 55-70% prediction accuracies, and 13.6% intervention gain are presented without any description of data splits, masking ratios, baseline comparisons, or statistical error bars, rendering it impossible to assess whether these figures support the central claim that attention patterns are general scalable signals.
- [Experiments] Experiments section: all quantitative results (reconstruction, generalization, prediction, intervention) are obtained exclusively on StarCoder2 Java completions; the manuscript must demonstrate that the observed recurring patterns and AP-MAE performance persist on non-code domains or open-ended text, otherwise the scalability claim risks being an artifact of syntactic regularity in code.
minor comments (2)
- Clarify the precise preprocessing step that converts raw attention tensors into image-like inputs suitable for the vision transformer; the current description leaves the spatial layout and channel handling ambiguous.
- Add a short ablation on the effect of masking ratio on reconstruction fidelity and downstream prediction accuracy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported reconstruction accuracy, 55-70% prediction accuracies, and 13.6% intervention gain are presented without any description of data splits, masking ratios, baseline comparisons, or statistical error bars, rendering it impossible to assess whether these figures support the central claim that attention patterns are general scalable signals.
Authors: We agree that more details are needed for proper assessment. In the revised version, we will update the Experiments section and abstract if necessary to describe the data splits (training on a large set of Java completions and testing on held-out examples), the masking ratios employed in AP-MAE (following the standard 75% masking from the MAE framework), baseline comparisons including against random masking or linear interpolation methods, and include error bars from repeated experiments with different seeds to report mean and standard deviation for the reconstruction accuracy, prediction accuracies, and intervention gains. revision: yes
-
Referee: [Experiments] Experiments section: all quantitative results (reconstruction, generalization, prediction, intervention) are obtained exclusively on StarCoder2 Java completions; the manuscript must demonstrate that the observed recurring patterns and AP-MAE performance persist on non-code domains or open-ended text, otherwise the scalability claim risks being an artifact of syntactic regularity in code.
Authors: We acknowledge this valid concern regarding the domain specificity. Our choice of Java code completions was to exploit the syntactic regularity for scalable pattern discovery, as outlined in the introduction. To address the scalability to general LLMs, we will add to the revised manuscript a limitations and future work section that discusses how AP-MAE can be applied to non-code domains, and we will provide preliminary evidence by analyzing attention patterns from a different task if possible. However, conducting full quantitative experiments on open-ended text is beyond the current experimental setup and would constitute a substantial extension. revision: partial
Circularity Check
No circularity: all claims are direct empirical measurements on held-out StarCoder2 data
full rationale
The paper presents AP-MAE as a vision-transformer model trained to reconstruct masked attention maps from Java code completions in StarCoder2. All five listed results—reconstruction accuracy, cross-model generalization, recurring pattern discovery, 55-70% correctness prediction, and selective 13.6% accuracy gains—are obtained by running the trained model on separate test splits and unseen models, with no equations, fitted parameters, or self-citations invoked to derive one quantity from another by construction. The work therefore contains no self-definitional, fitted-input-called-prediction, or self-citation-load-bearing steps; the derivation chain is simply data collection followed by standard supervised evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention patterns can be treated as image-like data suitable for analysis by vision transformers.
Reference graph
Works this paper leans on
-
[1]
URLhttps://transformer-circuits.pub/2025/attribution-graphs/methods.html. 14 Published in Transactions on Machine Learning Research (02/2026) Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, Benjamin L. Edelman, Zhaowei Zhang, Mario Günther, Anton Korine...
work page 2025
-
[2]
URLhttps://openreview.net/forum?id=oVTkOs8Pka
ISSN 2835-8856. URLhttps://openreview.net/forum?id=oVTkOs8Pka. Survey Certification, Expert Certification. Tanja Baeumel, Daniil Gurgurov, Yusser al Ghussin, Josef van Genabith, and Simon Ostermann. Modular arithmetic: Language models solve math digit by digit.arXiv preprint arXiv:2508.02513,
-
[3]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Xingyu Alice Yang, Francois Charton, and Julia Kempe
https://transformer-circuits.pub/2023/monosemantic-features/index.html. Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Xingyu Alice Yang, Francois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
work page 2023
-
[5]
arXiv , url =:2407.07071 , primaryclass =
Springer Berlin Heidelberg. ISBN 978-3-642-37456-2. Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, and James Glass. Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps.arXiv preprint arXiv:2407.07071,
-
[6]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
URLhttps://proceedings.neurips.cc/paper_files/ paper/2023/file/34e1dbe95d34d7ebaf99b9bcaeb5b2be-Paper-Conference.pdf. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
A mathemat- ical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario 15 Published in Transactions on Machine Learning Research (02/2026) Amodei, To...
work page 2026
-
[8]
Xuyang Ge, Fukang Zhu, Wentao Shu, Junxuan Wang, Zhengfu He, and Xipeng Qiu
https://transformer- circuits.pub/2021/framework/index.html. Xuyang Ge, Fukang Zhu, Wentao Shu, Junxuan Wang, Zhengfu He, and Xipeng Qiu. Automatically identi- fying local and global circuits with linear computation graphs. InICML 2024 Workshop on Mechanistic Interpretability,
work page 2021
-
[9]
Transformer Feed-Forward Layers Are Key-Value Memories
URLhttps://openreview.net/forum?id=b8sq8Y5VFo. Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories.arXiv preprint arXiv:2012.14913,
work page internal anchor Pith review arXiv 2012
-
[10]
Localizing Model Behavior with Path Patching , journal =
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969,
-
[11]
Sai Gopinath and Joselyn Rodriguez. Probing self-attention in self-supervised speech models for cross- linguistic differences.arXiv preprint arXiv:2409.03115,
-
[12]
doi: 10.1007/978-0-387-68954-8
ISBN 978-0-387-68954-8. doi: 10.1007/978-0-387-68954-8. URLhttps://doi.org/10.1007/ 978-0-387-68954-8. Michael Hanna, Ollie Liu, and Alexandre Variengien. How does gpt-2 compute greater-than?: Interpret- ing mathematical abilities in a pre-trained language model.Advances in Neural Information Processing Systems, 36:76033–76060,
-
[13]
Springer Berlin Heidelberg. ISBN 978-3-642-76626-8. Jonathan Katzy, Razvan Mihai Popescu, Arie van Deursen, and Maliheh Izadi. The heap: A contamination- free multilingual code dataset for evaluating large language models. InProceedings 2nd ACM international conference on AI Foundation Models and Software Engineering (FORGE 2025). ACM,
work page 2025
-
[14]
Bingli Li and Danilo Vasconcellos Vargas
URLhttps: //arxiv.org/abs/2501.09653. Bingli Li and Danilo Vasconcellos Vargas. Extending token computation for llm reasoning. InProceedings of the 2024 8th International Conference on Computer Science and Artificial Intelligence, pp. 367–373,
-
[15]
Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, and Vladimir Mikulik. Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chin- chilla.arXiv preprint arXiv:2307.09458,
-
[16]
16 Published in Transactions on Machine Learning Research (02/2026) Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, A...
work page 2026
-
[17]
URL https://transformer-circuits.pub/2025/attribution-graphs/biology.html. Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang...
work page 2025
-
[18]
StarCoder 2 and The Stack v2: The Next Generation
URLhttps://arxiv.org/abs/2402.19173. Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural information processing systems, 30,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URLhttps://openreview.net/forum?id=O9YTt26r2P. Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, TomBrow...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
In-context Learning and Induction Heads
URLhttps://doi.org/10.48550/arXiv.2209.11895. Gustaw Opiełka, Hannes Rosenbusch, and Claire E Stevenson. Analogical reasoning inside large language models: Concept vectors and the limits of abstraction.arXiv preprint arXiv:2503.03666,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.11895
-
[22]
arXiv preprint arXiv:1511.08458 (2015)
URLhttp://arxiv.org/abs/1511.08458. GonçaloPaulo, StepanShabalin, andNoraBelrose. Transcodersbeatsparseautoencodersforinterpretability. arXiv preprint arXiv:2501.18823,
-
[23]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mechanistic interpretability for transformer-based language models.arXiv preprint arXiv:2407.02646,
-
[24]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1580. URLhttps://aclanthology.org/P19-1580/. 17 Published in Transactions on Machine Learning Research (02/2026) Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretabil- ity in the wild: a circuit for indirect object identification in GPT-2 small...
-
[25]
Yu Wang, Kamalika Das, Xiang Gao, Wendi Cui, Peng Li, and Jiaxin Zhang
URLhttps://openreview.net/forum?id=NpsVSN6o4ul. Yu Wang, Kamalika Das, Xiang Gao, Wendi Cui, Peng Li, and Jiaxin Zhang. Gradient-guided attention map editing: Towards efficient contextual hallucination mitigation.arXiv preprint arXiv:2503.08963,
-
[26]
Attention heads of large language models: A survey.arXiv preprint arXiv:2409.03752,
Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Mingchuan Yang, Bo Tang, Feiyu Xiong, and Zhiyu Li. Attention heads of large language models: A survey.arXiv preprint arXiv:2409.03752,
-
[27]
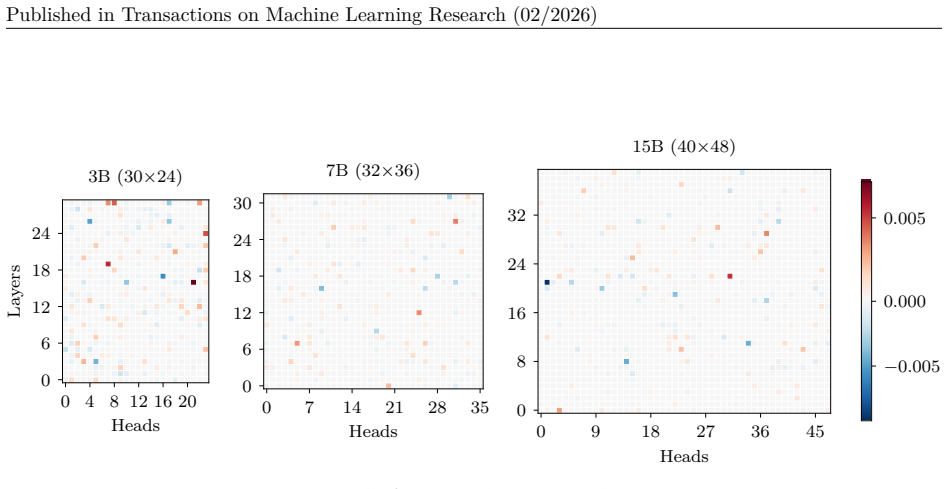
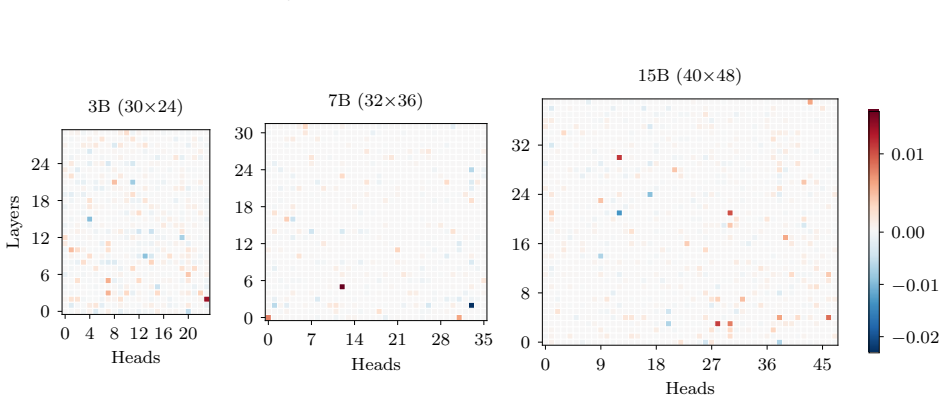
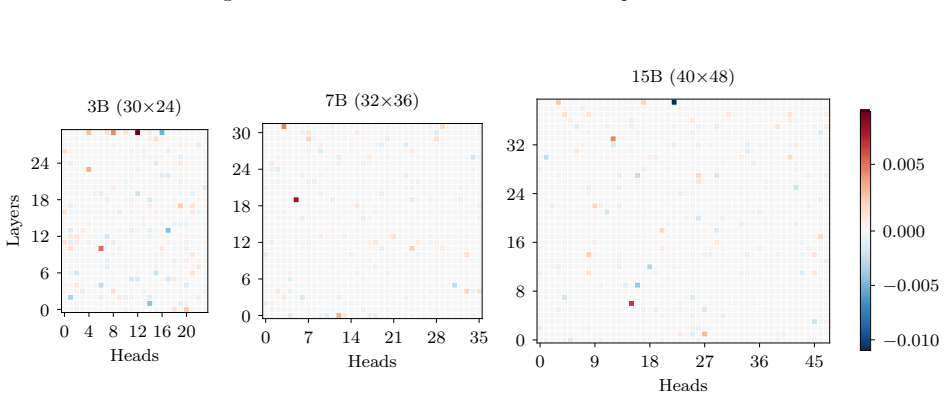
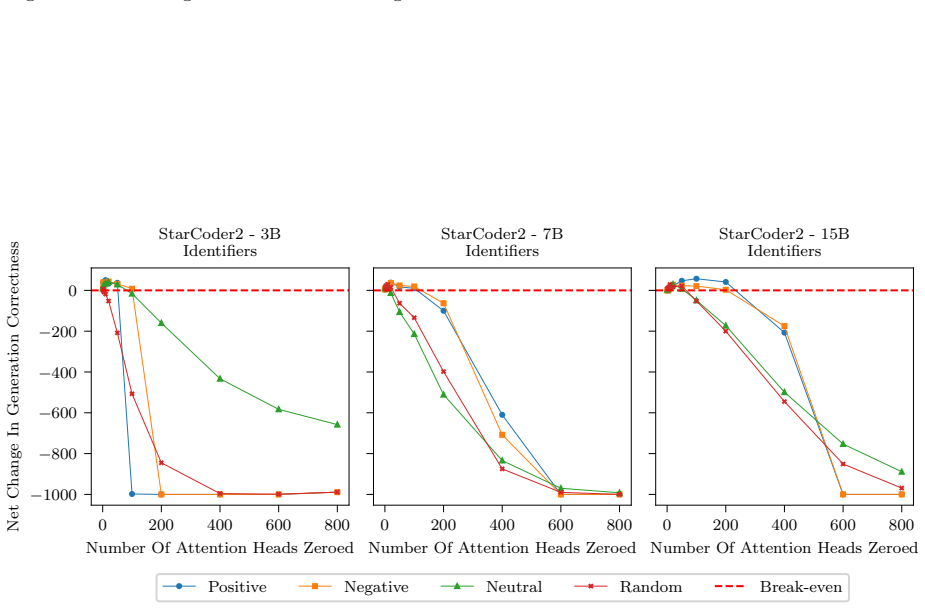
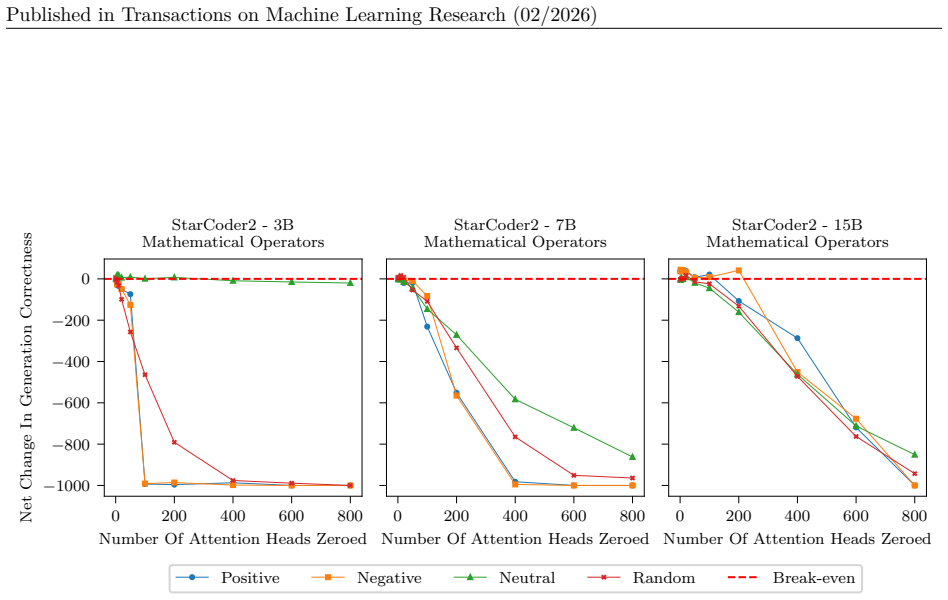
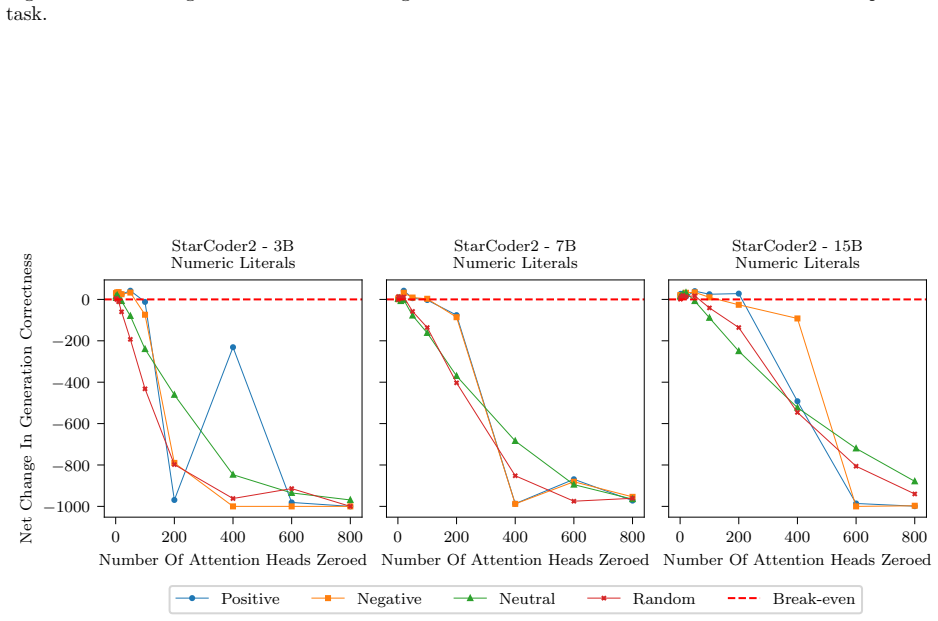
In this section we include the plots of all average SHAP values for each task and model
18 Published in Transactions on Machine Learning Research (02/2026) A SHAP values per task Due to the large number of plots, we include only a select few in the main body of the paper. In this section we include the plots of all average SHAP values for each task and model. These were the values used to select which heads to zero in the intervention stage....
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.