Recognition: 2 theorem links
· Lean TheoremBridging the Language Gap in Scholarly Data I: Enhancing Author Disambiguation Algorithms for Chinese Names
Pith reviewed 2026-05-13 17:14 UTC · model grok-4.3
The pith
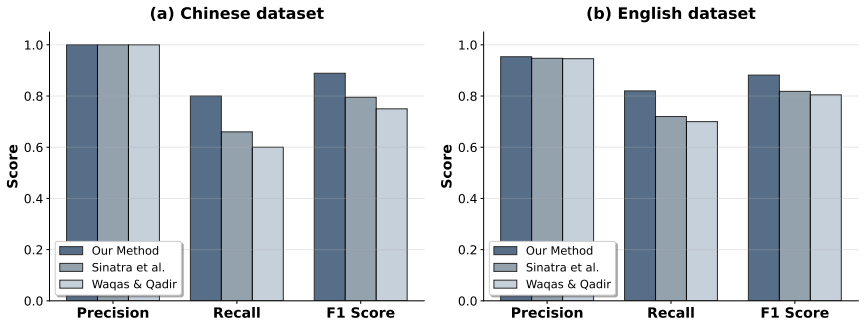
A rule-based framework using networks and content similarity disambiguates Chinese names with F1 scores of 0.88 for Pinyin and 0.89 for characters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a rule-based disambiguation framework integrating co-authorship networks, citation networks, author affiliations, and content similarity resolves name ambiguity for Chinese scholars. Applied to 65,241 physics papers, the method reaches F1-scores of 0.88 on Pinyin names and 0.89 on character-based names in a human-annotated sample of 80 pairs, with gains driven by higher recall over two baseline methods. Performance remains comparable across writing systems, making the framework script-agnostic.
What carries the argument
The rule-based disambiguation framework that merges co-authorship and citation networks with affiliation and content similarity signals to cluster papers belonging to the same individual.
If this is right
- Large-scale scientometric analyses can incorporate Chinese scholarly records without systematic undercounting of authors.
- The same rules apply whether metadata supplies Pinyin or characters, reducing dependence on one script format.
- Higher recall means more papers by the same person are correctly linked, improving measures of collaboration and impact.
- The framework offers a practical starting point for processing other non-Latin name data in international repositories.
Where Pith is reading between the lines
- If the rule set generalizes, similar pipelines could address name ambiguity in Korean, Arabic, or other romanized systems.
- Applying the method to global citation databases might shift relative rankings of researchers from East Asia.
- Adding lightweight machine learning on the same features could be tested as a direct extension to push recall even higher.
- The 70-year span of the data allows tracking how name disambiguation needs change over time in one field.
Load-bearing premise
The 80 human-annotated name pairs sufficiently represent the ambiguities present across the full 65,241-paper dataset and that the selected network and content features alone can resolve most cases without further machine-learning steps.
What would settle it
Running the method on a fresh random sample of several hundred name pairs from the same dataset and finding that human reviewers disagree with the clusters often enough to drop average F1 below 0.80 would show the reported performance does not hold.
Figures



read the original abstract
Disambiguating scholars with identical names is essential for accurate authorship assignment and robust large-scale scientometric research. Existing methods are often designed for Latin-script metadata and perform poorly on Chinese names. In international publications, Chinese names typically appear as Romanized Pinyin, which is highly ambiguous as it can map to multiple distinct characters. Chinese characters, in contrast, reduce but do not eliminate this ambiguity, and are rarely available in international records. To address both challenges, we propose a rule-based disambiguation framework that integrates co-authorship networks, citation networks, author affiliations, and content similarity. We apply this framework to 65,241 physics papers from the China National Knowledge Infrastructure (CNKI), spanning over 70 years of data. On a human annotated sample of 80 name pairs, our method achieves F1-scores of 0.88 for Pinyin names and 0.89 for character-based names, outperforming two baseline approaches, with improvements driven primarily by higher recall. The comparable performance across both writing systems shows that our approach is script-agnostic, enabling reliable large-scale scientometric analyses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a rule-based author disambiguation framework for Chinese names that integrates co-authorship networks, citation networks, author affiliations, and content similarity. It is applied to a corpus of 65,241 CNKI physics papers spanning over 70 years, with performance evaluated on a human-annotated sample of 80 name pairs yielding F1 scores of 0.88 for Pinyin names and 0.89 for character-based names, outperforming two unspecified baselines primarily via higher recall. The approach is presented as script-agnostic.
Significance. If the evaluation holds, the work would offer a transparent, parameter-free method for handling name ambiguity in Chinese scholarly data, a persistent gap in tools optimized for Latin scripts. The comparable results across Pinyin and character representations, combined with the rule-based design, could support more reliable large-scale scientometric studies on Chinese-language corpora.
major comments (2)
- [Evaluation] Evaluation section: The headline F1 scores (0.88 Pinyin, 0.89 character) and outperformance claim rest exclusively on a human-annotated sample of 80 name pairs. No sampling protocol (random, stratified, or otherwise), inter-annotator agreement, annotation guidelines, or statistical significance tests for the improvements are reported. This leaves open whether the sample captures the distribution of ambiguity cases in the full 65,241-paper corpus, including rare names, multi-author papers, and temporal variation over 70 years.
- [Methods] Methods section: The two baseline approaches are not described in sufficient detail (e.g., how they were implemented or adapted for Chinese names, any parameter settings, or feature usage). Without this information, the claim of outperformance cannot be independently verified or replicated.
minor comments (2)
- [Abstract] Abstract: The two baseline approaches are referenced but not named; specifying them (or at least their core ideas) would improve clarity for readers.
- [Discussion] The manuscript would benefit from a brief discussion of potential failure modes (e.g., cases where network features are sparse) to contextualize the reported recall gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline F1 scores (0.88 Pinyin, 0.89 character) and outperformance claim rest exclusively on a human-annotated sample of 80 name pairs. No sampling protocol (random, stratified, or otherwise), inter-annotator agreement, annotation guidelines, or statistical significance tests for the improvements are reported. This leaves open whether the sample captures the distribution of ambiguity cases in the full 65,241-paper corpus, including rare names, multi-author papers, and temporal variation over 70 years.
Authors: We acknowledge that the current manuscript lacks explicit details on the annotation process. The 80 name pairs were chosen to represent a range of ambiguity scenarios drawn from the 65,241-paper corpus, including variations in name frequency, multi-author papers, and temporal coverage across the 70-year span. In the revised manuscript we will add a full description of the sampling protocol, annotation guidelines, inter-annotator agreement statistics, and statistical significance tests for the reported F1 improvements. These additions will clarify representativeness and strengthen the evaluation section. revision: yes
-
Referee: [Methods] Methods section: The two baseline approaches are not described in sufficient detail (e.g., how they were implemented or adapted for Chinese names, any parameter settings, or feature usage). Without this information, the claim of outperformance cannot be independently verified or replicated.
Authors: We agree that the baselines require more detailed description to support replication. In the revised manuscript we will expand the Methods section to fully specify the two baseline approaches, including their implementation, adaptations for Chinese names (both Pinyin and character forms), parameter settings, and feature usage. This will allow readers to verify the outperformance claims. revision: yes
Circularity Check
No circularity: rule-based method evaluated on external human labels
full rationale
The paper presents a rule-based disambiguation framework combining co-authorship networks, citation networks, affiliations, and content similarity. It reports F1 scores on a separate human-annotated sample of 80 name pairs drawn from the CNKI corpus. No equations, fitted parameters, or derivations are described that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The evaluation uses independent external labels, satisfying the criterion for a self-contained result against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Co-authorship, citation, affiliation, and content similarity features reliably indicate shared authorship for Chinese names
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearrule-based disambiguation framework that integrates co-authorship networks, citation networks, author affiliations, and content similarity... F1-scores of 0.88 for Pinyin names and 0.89 for character-based names
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearOn a human annotated sample of 80 name pairs
Reference graph
Works this paper leans on
-
[1]
When different persons have an identical author name
Dag W Aksnes. When different persons have an identical author name. how frequent are homonyms?Journal of the American Society for Information Science and Technology, 59(5):838–841, 2008
work page 2008
-
[2]
Ander Barrena, Aitor Soroa, and Eneko Agirre. Towards zero-shot cross-lingual named entity disambiguation.EXPERT SYSTEMS WITH APPLICATIONS, 184, DEC 1 2021
work page 2021
-
[3]
Ying Chen, Sophia Yat Mei Lee, and Chu-Ren Huang. A robust web personal name information extraction system.EXPERT SYSTEMS WITH APPLICATIONS, 39(3):2690–2699, FEB 15 2012
work page 2012
-
[4]
Wei-Sheng Chin, Yong Zhuang, Yu-Chin Juan, Felix Wu, Hsiao-Yu Tung, Tong Yu, Jui-Pin Wang, Cheng-Xia Chang, Chun-Pai Yang, Wei-Cheng Chang, Kuan-Hao Huang, Tzu-Ming Kuo, Shan-Wei Lin, Young-San Lin, Yu-Chen Lu, Yu-Chuan Su, Cheng-Kuang Wei, Tu-Chun Yin, Chun-Liang Li, Ting-Wei Lin, Cheng-Hao Tsai, Shou-De Lin, Hsuan-Tien Lin, and Chih- Jen Lin. Effective ...
work page 2014
-
[5]
Kai Duan, Shiyu Du, Yiming Zhang, Yanru Lin, Hongzhuo Wu, and Quan Zhang. Enhancement of question answering system accuracy via transfer learning and bert.APPLIED SCIENCES- BASEL, 12(22), NOV 2022
work page 2022
-
[6]
Chao Fan and Yu Li. Chinese personal name disambiguation based on clustering.WIRELESS COMMUNICATIONS & MOBILE COMPUTING, 2021, MAY 15 2021
work page 2021
-
[7]
Anderson A Ferreira, Marcos Andr´ e Gon¸ calves, and Alberto HF Laender. A brief survey of automatic methods for author name disambiguation.Acm Sigmod Record, 41(2):15–26, 2012
work page 2012
-
[8]
Research identifiers: Orcid, doi, and the issue with wang and smith
Stuart I Granshaw. Research identifiers: Orcid, doi, and the issue with wang and smith. Photogrammetric Record, 34(167), 2019
work page 2019
-
[9]
Jack Halpern. Some linguistic issues in the machine transliteration of chinese, japanese, and arabic names.ACL 2016, page 47, 2016. 9
work page 2016
-
[10]
Hongqi Han, Changqing Yao, Yuan Fu, Yongsheng Yu, Yunliang Zhang, and Shuo Xu. Semantic fingerprints-based author name disambiguation in chinese documents.SCIENTOMETRICS, 111(3):1879–1896, JUN 2017. 6th Global Tech Mining Conference, Valencia, SPAIN, SEP, 2016
work page 2017
-
[11]
Anne-Wil Harzing. Health warning: might contain multiple personalities-the problem of homonyms in thomson reuters essential science indicators.SCIENTOMETRICS, 105(3):2259– 2270, DEC 2015
work page 2015
-
[12]
Anne-Wil Harzing. Health warning: might contain multiple personalities—the problem of homonyms in thomson reuters essential science indicators.Scientometrics, 105:2259–2270, 2015
work page 2015
-
[13]
Changqin Huang, Jia Zhu, Xiaodi Huang, Min Yang, Gabriel Fung, and Qintai Hu. A novel approach for entity resolution in scientific documents using context graphs.INFORMATION SCIENCES, 432:431–441, MAR 2018
work page 2018
-
[14]
Yongwen Huang, Jiao Li, Tan Sun, and Guojian Xian. Institution information specification and correlation based on institutional pids and ind tool.SCIENTOMETRICS, 122(1):381–396, JAN 2020
work page 2020
-
[15]
Jin Jiang, Xin Yan, Zhengtao Yu, Jianyi Guo, and Wei Tian. A chinese expert disambigua- tion method based on semi-supervised graph clustering.INTERNATIONAL JOURNAL OF MACHINE LEARNING AND CYBERNETICS, 6(2):197–204, APR 2015
work page 2015
-
[16]
Liting Jiang, Gulila Altenbek, Di Wu, Yajing Ma, and Hayinaer Aierzhati. Chinese short text entity disambiguation based on the dual-channel hybrid network.IEEE ACCESS, 8:206164– 206173, 2020
work page 2020
-
[17]
Jinseok Kim and Jana Diesner. Distortive effects of initial-based name disambiguation on measurements of large-scale coauthorship networks.Journal of the Association for Information Science and Technology, 67(6):1446–1461, 2016
work page 2016
-
[18]
Jinseok Kim, Jenna Kim, and Jinmo Kim. Effect of chinese characters on machine learning for chinese author name disambiguation: A counterfactual evaluation.Journal of Information Science, 49(3):711–725, 2023
work page 2023
-
[19]
Jinseok Kim, Jenna Kim, and Jinmo Kim. Effect of chinese characters on machine learning for chinese author name disambiguation: A counterfactual evaluation.JOURNAL OF INFORMA- TION SCIENCE, 49(3):711–725, JUN 2023
work page 2023
-
[20]
Kei Kurakawa, Hideaki Takeda, Masao Takaku, Akiko Aizawa, Ryo Shiozaki, Shun Morimoto, and Hideki Uchijima. Researcher name resolver: Identifier management system for japanese researchers.International Journal on Digital Libraries, 14(1):39–58, 2014
work page 2014
-
[21]
Chenliang Li, Aixin Sun, and Anwitaman Datta. Tsdw: Two-stage word sense disambigua- tion using wikipedia.JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY, 64(6):1203–1223, JUN 2013
work page 2013
-
[22]
P Li and MC Yip. Context effects and the processing of spoken homophones.READING AND WRITING, 10(3-5):223–243, OCT 1998
work page 1998
-
[23]
Chu-Cheng Lin, Yu-Chun Wang, and Richard Tzong-Han Tsai. Japanese-chinese information retrieval with an iterative weighting scheme.JOURNAL OF INFORMATION SCIENCE AND ENGINEERING, 26(2):685–697, MAR 2010. National Computer Symposium, Taichung, TAI- WAN, DEC, 2007
work page 2010
-
[24]
Shuai Liu, Tenghui He, and Jianhua Dai. A survey of crf algorithm based knowledge extrac- tion of elementary mathematics in chinese.MOBILE NETWORKS & APPLICATIONS, 26(5, SI):1891–1903, OCT 2021
work page 1903
-
[25]
Emma Woo Louie.Chinese American names: Tradition and transition. McFarland, 2008
work page 2008
-
[26]
Yingying Ma, Youlong Wu, and Chengqiang Lu. A graph-based author name disambiguation method and analysis via information theory.ENTROPY, 22(4), APR 2020. 10
work page 2020
-
[27]
A. Manzoor, S. Asghar, and Tehmina Amjad. Toward a new paradigm for author name disam- biguation.IEEE Access, 10:76055–76068, 2022
work page 2022
-
[28]
Yuqing Mao and Zhiyong Lu. Mesh now: automatic mesh indexing at pubmed scale via learning to rank.JOURNAL OF BIOMEDICAL SEMANTICS, 8, APR 17 2017
work page 2017
-
[29]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space.arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Chai Mingke, Li Dongmei, Zhuang Tingting, and Yang Shuyi. Named entity disambiguation based on classified and structural semantic relatedness.CHINESE JOURNAL OF ELEC- TRONICS, 27(6):1176–1182, NOV 2018
work page 2018
-
[31]
Understanding orcid adoption among academic researchers.Scientometrics, 130(5):2783–2797, 2025
Stephen R Porter, Paul D Umbach, and Chris Willis. Understanding orcid adoption among academic researchers.Scientometrics, 130(5):2783–2797, 2025
work page 2025
-
[32]
A note on the topic of single-author articles in science.Scientometrics, 130(5):3071– 3088, 2025
Petr Praus. A note on the topic of single-author articles in science.Scientometrics, 130(5):3071– 3088, 2025
work page 2025
-
[33]
Jane Qiu. Identity crisis: Chinese authors are publishing more and more papers, but are they receiving due credit and recognition for their work? not if their names get confused along the way.Nature, 451(7180):766–768, 2008
work page 2008
-
[34]
Jan-Frederic Schulz. Using monte carlo simulations to assess the impact of author name dis- ambiguation quality on different bibliometric analyses.Scientometrics, 107:1283 – 1298, 2016
work page 2016
-
[35]
chinese- names.https://github.com/CSHVienna/chinese-names, 2026
Mingrong She, Liuhuaying Yang, Ana Maria Jaramillo, and Lisette Esp´ ın-Noboa. chinese- names.https://github.com/CSHVienna/chinese-names, 2026. GitHub repository
work page 2026
-
[36]
Quantifying the evolution of individual scientific impact.Science, 354(6312):aaf5239, 2016
Roberta Sinatra, Dashun Wang, Pierre Deville, Chaoming Song, and Albert-L´ aszl´ o Barab´ asi. Quantifying the evolution of individual scientific impact.Science, 354(6312):aaf5239, 2016
work page 2016
-
[37]
Author name disambiguation.Annual review of information science and technology, 43(1):1, 2009
Neil R Smalheiser, Vetle I Torvik, et al. Author name disambiguation.Annual review of information science and technology, 43(1):1, 2009
work page 2009
-
[38]
Transitioning to the next generation of metadata
Karen Smith-Yoshimura. Transitioning to the next generation of metadata. oclc research report. OCLC Online Computer Library Center, Inc., 2020
work page 2020
-
[39]
Guojie Song, Qingqing Long, Yi Luo, Yiming Wang, and Yilun Jin. Deep convolutional neu- ral network based medical concept normalization.IEEE TRANSACTIONS ON BIG DATA, 8(5):1195–1208, OCT 1 2022
work page 2022
-
[40]
Andreas Strotmann and Dangzhi Zhao. Author name disambiguation: What difference does it make in author-based citation analysis?JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY, 63(9):1820–1833, SEP 2012
work page 2012
-
[41]
Andreas Strotmann and Dangzhi Zhao. Author name disambiguation: What difference does it make in author-based citation analysis?Journal of the American Society for Information Science and Technology, 63(9):1820–1833, 2012
work page 2012
-
[42]
Name disambiguation for chinese scientific authors with multi-level clustering
Simeng Sun, Hui Zhang, Ning Li, and Yong Chen. Name disambiguation for chinese scientific authors with multi-level clustering. In2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiqui- tous Computing (EUC), volume 1, pages 176–182. IEEE, 2017
work page 2017
-
[43]
Kim Sungwon. Disambiguation of korean names in references.Journal of Information Science Theory and Practice, 6(2):62–70, 2018
work page 2018
-
[44]
Jie Tang, A. C. M. Fong, Bo Wang, and Jing Zhang. A unified probabilistic framework for name disambiguation in digital library.IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, 24(6):975–987, JUN 2012
work page 2012
-
[45]
A combination approach to web user profiling
Jie Tang, Limin Yao, Duo Zhang, and Jing Zhang. A combination approach to web user profiling. ACM TRANSACTIONS ON KNOWLEDGE DISCOVERY FROM DATA, 5(1), DEC 2010
work page 2010
-
[46]
Jaime A Teixeira da Silva. Chinese names in the biomedical literature: Suggested bibliometric standardization.Publishing Research Quarterly, 36(2):254–257, 2020. 11
work page 2020
-
[47]
Chen-Kai Wang, Feng-Duo Wang, You-Qian Lee, Pei-Tsz Chen, Bo-Hong Wang, Chu-Hsien Su, Joseph Chin-Chi Kuo, Chi-Shin Wu, Yi-Ling Chien, Hong-Jie Dai, Vincent S. Tseng, and Wen- Lian Hsu. Principle-based approach for the de-identification of code-mixed electronic health records.IEEE ACCESS, 10:22875–22885, 2022
work page 2022
-
[48]
Cheng Wang, Hangyu Zhu, Ruixin Hu, Rui Li, and Changjun Jiang. Longarms: Fraud pre- diction in online lending services using sparse knowledge graph.IEEE TRANSACTIONS ON BIG DATA, 9(2):758–772, APR 1 2023
work page 2023
-
[49]
Fang Wang, Wei Wu, Zhoujun Li, and Ming Zhou. Named entity disambiguation for questions in community question answering.KNOWLEDGE-BASED SYSTEMS, 126:68–77, JUN 15 2017
work page 2017
-
[50]
Humaira Waqas and Muhammad Abdul Qadir. Multilayer heuristics based clustering framework (MHCF) for author name disambiguation.Scientometrics, 126(9):7637–7678, 2021
work page 2021
-
[51]
Sheng Xiaoguang, Wang Ying, and Qian Li. Author name disambiguation based on semi- supervised learning with graph convolutional network.JOURNAL OF ELECTRONICS & INFORMATION TECHNOLOGY, 43(12):3442–3450, DEC 2021
work page 2021
-
[52]
Rousseau, Xin Li, Weijia Xu, Vetle I
Jian Xu, Sunkyu Kim, Min Song, Minbyul Jeong, Donghyeon Kim, Jaewoo Kang, Justin F. Rousseau, Xin Li, Weijia Xu, Vetle I. Torvik, Yi Bu, Chongyan Chen, Islam Akef Ebeid, Daifeng Li, and Ying Ding. Building a pubmed knowledge graph.SCIENTIFIC DATA, 7(1), JUN 26 2020
work page 2020
-
[53]
Ruifeng Xu, Lin Gui, Qin Lu, Shuai Wang, and Jian Xu. Incorporating multi-kernel function and internet verification for chinese person name disambiguation.FRONTIERS OF COMPUTER SCIENCE, 10(6):1026–1038, DEC 2016
work page 2016
-
[54]
Shaoxiong Brian Xu and Guangwei Hu. Rethinking the author name ambiguity problem and beyond: The case of the chinese context.Accountability in Research, pages 1–24, 2024
work page 2024
-
[55]
Shuo Xu, Liyuan Hao, Guancan Yang, Kun Lu, and Xin An. A topic models based framework for detecting and forecasting emerging technologies.TECHNOLOGICAL FORECASTING AND SOCIAL CHANGE, 162, JAN 2021
work page 2021
-
[56]
Deyun Yin, Kazuyuki Motohashi, and Jianwei Dang. Large-scale name disambiguation of chinese patent inventors (1985-2016).SCIENTOMETRICS, 122(2):765–790, FEB 2020
work page 1985
-
[57]
Jan Youtie, Stephen Carley, Alan L. Porter, and Philip Shapira. Tracking researchers and their outputs: new insights from orcids.SCIENTOMETRICS, 113(1):437–453, OCT 2017
work page 2017
-
[58]
Lili Yuan, Yanni Hao, Minglu Li, Chunbing Bao, Jianping Li, and Dengsheng Wu. Who are the international research collaboration partners for china? a novel data perspective based on nsfc grants.Scientometrics, 116:401–422, 2018
work page 2018
-
[59]
Sanghwa Yuh, Kongjoo Lee, and Jungyun Seo. Multilingual closed caption translation sys- tem for digital television.IEICE TRANSACTIONS ON INFORMATION AND SYSTEMS, E89D(6):1885–1892, JUN 2006
work page 2006
-
[60]
Li Yujian and Liu Bo. A normalized levenshtein distance metric.IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(6):1091–1095, 2007
work page 2007
-
[61]
Increasing trend of scientists to switch between topics.Nature communications, 10(1):3439, 2019
An Zeng, Zhesi Shen, Jianlin Zhou, Ying Fan, Zengru Di, Yougui Wang, H Eugene Stanley, and Shlomo Havlin. Increasing trend of scientists to switch between topics.Nature communications, 10(1):3439, 2019
work page 2019
-
[62]
Entity linking on chinese microblogs via deep neural network.IEEE ACCESS, 6:25908–25920, 2018
Weixin Zeng, Jiuyang Tang, and Xiang Zhao. Entity linking on chinese microblogs via deep neural network.IEEE ACCESS, 6:25908–25920, 2018
work page 2018
-
[63]
Haijun Zhang. Neural network-based tree translation for knowledge base construction.IEEE ACCESS, 9:38706–38717, 2021
work page 2021
-
[64]
Qin Zhang, Xuyu Xiang, Jiaohua Qin, Yun Tan, Qiang Liu, and Neal N. Xiong. Short text entity disambiguation algorithm based on multi-word vector ensemble.INTELLIGENT AU- TOMATION AND SOFT COMPUTING, 30(1):227–241, 2021. 12
work page 2021
-
[65]
Yang Zhang, Jin Liu, Bo Huang, and Bei Chen. Entity linking method for chinese short text based on siamese-like network.INFORMATION, 13(8), AUG 2022
work page 2022
-
[66]
Zhihui Zhang, Jason E Rollins, and Evangelia Lipitakis. China’s emerging centrality in the contemporary international scientific collaboration network.Scientometrics, 116(2):1075–1091, 2018
work page 2018
-
[67]
Zhenyue Zhao, Yi Bu, Lele Kang, Chao Min, Yiyang Bian, Li Tang, and Jiang Li. An in- vestigation of the relationship between scientists’ mobility to/from china and their research performance.JOURNAL OF INFORMETRICS, 14(2), MAY 2020
work page 2020
-
[68]
Dual-channel heterogeneous graph network for author name disambiguation.INFORMATION, 12(9), SEP 2021
Xin Zheng, Pengyu Zhang, Yanjie Cui, Rong Du, and Yong Zhang. Dual-channel heterogeneous graph network for author name disambiguation.INFORMATION, 12(9), SEP 2021
work page 2021
-
[69]
Pengfei Zhou, Kaining Ying, Zhenhua Wang, Dongyan Guo, and Cong Bai. Self-supervised en- hancement for named entity disambiguation via multimodal graph convolution.IEEE TRANS- ACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, 2022 MAY 13 2022
work page 2022
-
[70]
Jia Zhu, Xingcheng Wu, Xueqin Lin, Changqin Huang, Gabriel Pui Cheong Fung, and Yong Tang. A novel multiple layers name disambiguation framework for digital libraries using dynamic clustering.SCIENTOMETRICS, 114(3):781–794, MAR 2018. 13 Supplementary Information S1 Systematic literature search To identify prior work on Chinese name disambiguation, we cond...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.