Recognition: 2 theorem links
· Lean TheoremR\'enyi Attention Entropy for Patch Pruning
Pith reviewed 2026-05-13 17:15 UTC · model grok-4.3
The pith
Rényi entropy of attention distributions identifies redundant patches for pruning in vision transformers while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
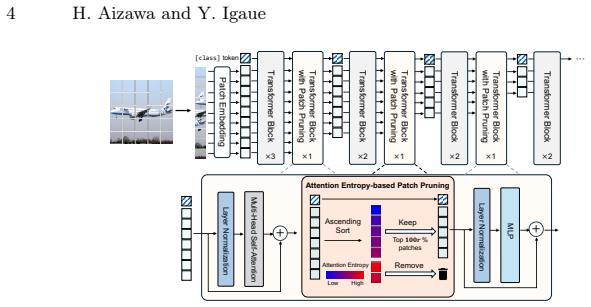
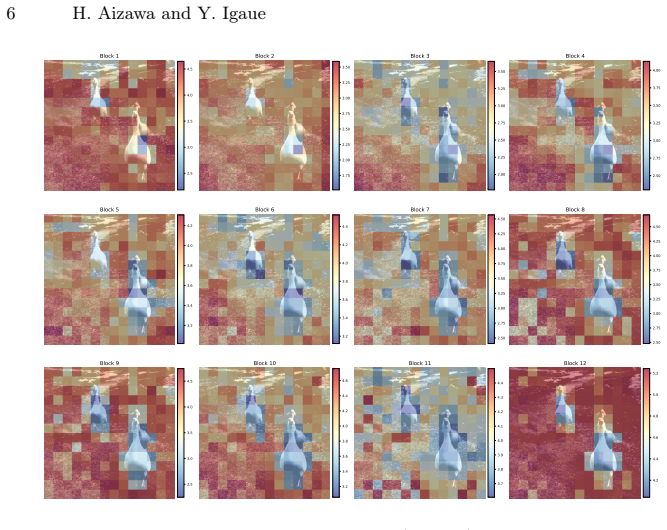
The central claim is that the Rényi entropy of the per-patch attention distribution provides an effective, adjustable criterion for patch pruning in vision transformers, where low-entropy patches are important and high-entropy ones are redundant, leading to computation savings without accuracy loss on fine-grained tasks.
What carries the argument
The Rényi entropy applied to the attention distribution over patches, which emphasizes sharp attention peaks and supports adaptive pruning policies.
If this is right
- Self-attention computation decreases as fewer patches are processed.
- Accuracy is preserved in fine-grained image recognition tasks.
- Rényi entropy parameter tuning improves the accuracy versus computation trade-off.
- Patch selection becomes more flexible for different computational limits.
Where Pith is reading between the lines
- Similar entropy-based pruning could be tested on language transformers for token reduction.
- Combining this with other importance metrics might further optimize transformer efficiency.
- The method's reliance on attention maps suggests it works best in models where attention is already computed.
- Extensions to video or 3D data could prune temporal or spatial patches analogously.
Load-bearing premise
That the entropy of the attention distribution over patches reliably signals which patches are important for the downstream task, without requiring extensive task-specific validation or additional learned components.
What would settle it
If removing high-entropy patches according to this criterion causes a significant drop in accuracy on a fine-grained recognition benchmark compared to random or other pruning methods, the claim would be falsified.
Figures




read the original abstract
Transformers are strong baselines in both vision and language because self-attention captures long-range dependencies across tokens. However, the cost of self-attention grows quadratically with the number of tokens. Patch pruning mitigates this cost by estimating per-patch importance and removing redundant patches. To identify informative patches for pruning, we introduce a criterion based on the Shannon entropy of the attention distribution. Low-entropy patches, which receive selective and concentrated attention, are kept as important, while high-entropy patches with attention spread across many locations are treated as redundant. We also extend the criterion from Shannon to R\'enyi entropy, which emphasizes sharp attention peaks and supports pruning strategies that adapt to task needs and computational limits. In experiments on fine-grained image recognition, where patch selection is critical, our method reduced computation while preserving accuracy. Moreover, adjusting the pruning policy through the R\'enyi entropy measure yields further gains and improves the trade-off between accuracy and computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a patch-pruning criterion for Vision Transformers based on the Shannon entropy of per-patch attention distributions, with an extension to Rényi entropy of tunable order alpha. Low-entropy patches (concentrated attention) are retained as informative while high-entropy patches (diffuse attention) are pruned to reduce quadratic self-attention cost. Experiments on fine-grained image recognition are claimed to show that the method reduces computation while preserving accuracy, and that varying the Rényi order further improves the accuracy-compute trade-off.
Significance. If the empirical claims hold with proper controls, the method supplies a lightweight, training-free pruning heuristic that directly leverages existing attention weights without additional learned parameters beyond the single Rényi order. This could be useful for efficiency in vision transformers where patch selection matters. The Rényi generalization is presented as a tunable knob rather than a fitted model, which is a modest but positive design choice.
major comments (3)
- [Abstract, §4] Abstract and §4 (experiments): the central claim that the method 'reduced computation while preserving accuracy' and that Rényi 'yields further gains' is unsupported by any reported baselines, pruning ratios, statistical tests, or ablation tables. Without these, it is impossible to determine whether gains exceed those from simply reducing token count or from standard attention-based pruning heuristics.
- [§3] §3 (method): the assumption that low Shannon/Rényi entropy reliably identifies task-important patches is load-bearing but untested. No controls compare entropy pruning against random pruning, magnitude-based pruning, or the base ViT attention itself; a diffuse-attention patch could still carry a discriminative local feature in fine-grained recognition, undermining the mapping from entropy to importance.
- [§3.2] §3.2 (Rényi extension): varying the order alpha is presented as adapting to task needs, yet no derivation or ablation shows that different alpha values systematically trade off distinct importance notions rather than acting as an extra hyper-parameter whose optimal value must be searched per dataset.
minor comments (2)
- [§3] Notation for Rényi entropy should be defined explicitly (e.g., the exact formula for H_alpha) rather than left implicit from the Shannon case.
- [§4] Figure captions and experimental tables should report exact pruning thresholds, number of runs, and standard deviations to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important gaps in experimental validation and controls. We will revise the manuscript to incorporate additional baselines, ablations, and statistical reporting as detailed below. Our responses address each major comment directly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experiments): the central claim that the method 'reduced computation while preserving accuracy' and that Rényi 'yields further gains' is unsupported by any reported baselines, pruning ratios, statistical tests, or ablation tables. Without these, it is impossible to determine whether gains exceed those from simply reducing token count or from standard attention-based pruning heuristics.
Authors: We agree that the original experiments section would be strengthened by explicit baselines, pruning ratios, and statistical tests. In the revised version we will add tables reporting exact pruning ratios, comparisons against random pruning and magnitude-based pruning at matched token counts, and accuracy results with standard deviations over multiple random seeds. The current fine-grained recognition results already indicate that entropy pruning maintains higher accuracy than uniform token reduction at equivalent FLOPs, but we accept that these controls are required to make the claim rigorous. revision: partial
-
Referee: [§3] §3 (method): the assumption that low Shannon/Rényi entropy reliably identifies task-important patches is load-bearing but untested. No controls compare entropy pruning against random pruning, magnitude-based pruning, or the base ViT attention itself; a diffuse-attention patch could still carry a discriminative local feature in fine-grained recognition, undermining the mapping from entropy to importance.
Authors: The mapping from low entropy to importance rests on the observation that concentrated attention reflects the model's selective focus. We will add the requested controls (random pruning, magnitude pruning, and base ViT token retention) in the revised experiments. While a diffuse patch could in principle carry a local feature, our empirical results on fine-grained datasets show no accuracy drop when such patches are removed, supporting the criterion; the added ablations will directly test whether entropy outperforms these alternatives. revision: partial
-
Referee: [§3.2] §3.2 (Rényi extension): varying the order alpha is presented as adapting to task needs, yet no derivation or ablation shows that different alpha values systematically trade off distinct importance notions rather than acting as an extra hyper-parameter whose optimal value must be searched per dataset.
Authors: We will expand §3.2 with a short derivation showing that increasing alpha in Rényi entropy increasingly weights the maximum attention probability, thereby emphasizing peakiness over average spread. We will also include a new ablation table plotting accuracy-compute curves for alpha in {0.5, 1, 2, 3} across the evaluated datasets, demonstrating that the optimal alpha correlates with dataset characteristics (e.g., higher alpha benefits tasks with sharper attention patterns). This positions alpha as a principled tunable parameter rather than an arbitrary hyper-parameter. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines patch importance directly via Shannon and Rényi entropy computed from the transformer's existing attention weight distributions over patches. Low-entropy patches are retained and high-entropy ones pruned, with the Rényi order parameter presented as a tunable extension. This mapping is an explicit, non-fitted criterion applied to model outputs rather than a self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations reduce the claimed result to its inputs by construction, and the approach remains self-contained against external benchmarks such as standard ViT attention pruning heuristics. Experimental gains on fine-grained recognition are reported as empirical outcomes, not tautological consequences of the definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- Rényi order alpha
axioms (2)
- standard math Entropy of a probability distribution quantifies its uncertainty or spread
- domain assumption Low-entropy attention indicates selective focus on informative patches
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a criterion based on the Shannon entropy of the attention distribution. Low-entropy patches... are kept as important, while high-entropy patches... are treated as redundant. We also extend the criterion from Shannon to Rényi entropy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rényi attention entropy... order parameter that controls peak emphasis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Araabi, A., Niculae, V., Monz, C.: Entropy–and distance-regularized attention im- proves low-resource neural machine translation. In: Proceedings of the 16th Con- ference of the Association for Machine Translation in the Americas (Volume 1: Research Track). pp. 140–153 (2024)
work page 2024
-
[2]
In: Findings of the Association for Computational Linguistics: ACL 2022
Attanasio, G., Nozza, D., Hovy, D., Baralis, E.: Entropy-based attention regular- ization frees unintended bias mitigation from lists. In: Findings of the Association for Computational Linguistics: ACL 2022. pp. 1105–1119 (2022)
work page 2022
-
[3]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [4]
- [5]
- [6]
-
[7]
Clark, K., Khandelwal, U., Levy, O., Manning, C.D.: What does bert look at? an analysis of bert’s attention. In: Proceedings of the 2019 ACL Workshop Black- boxNLP: Analyzing and Interpreting Neural Networks for NLP. pp. 276–286 (2019)
work page 2019
- [8]
- [9]
- [10]
-
[11]
In: Asian Conference on Pattern Recognition
Igaue, Y., Aizawa, H.: Patch pruning strategy based on robust statistical mea- sures of attention weight diversity in vision transformers. In: Asian Conference on Pattern Recognition. pp. 123–133. Springer (2025)
work page 2025
-
[12]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Kobayashi, G., Kuribayashi, T., Yokoi, S., Inui, K.: Attention is not only a weight: Analyzing transformers with vector norms. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 7057–7075 (2020)
work page 2020
- [13]
- [14]
- [15]
-
[16]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Fine-Grained Visual Classification of Aircraft
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013) Rényi Attention Entropy for Patch Pruning 15
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[18]
In: Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing
Nilsback, M.E., Zisserman, A.: Automated flower classification over a large number of classes. In: Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing. pp. 722–729 (2008)
work page 2008
-
[19]
Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., Dosovitskiy, A.: Do vision transformers see like convolutional neural networks? NeurIPS34, 12116–12128 (2021)
work page 2021
-
[20]
Rao, Y., Zhao, W., Liu, B., Lu, J., Zhou, J., Hsieh, C.J.: Dynamicvit: Efficient vision transformers with dynamic token sparsification. NeurIPS34, 13937–13949 (2021)
work page 2021
-
[21]
Rényi, A.: On measures of entropy and information. In: Proceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1: con- tributions to the theory of statistics. vol. 4, pp. 547–562. University of California Press (1961)
work page 1961
-
[22]
ACM SIGMOBILE mo- bile computing and communications review5(1), 3–55 (2001)
Shannon, C.E.: A mathematical theory of communication. ACM SIGMOBILE mo- bile computing and communications review5(1), 3–55 (2001)
work page 2001
- [23]
- [24]
- [25]
-
[26]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS30(2017)
work page 2017
-
[27]
In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Voita, E., Talbot, D., Moiseev, F., Sennrich, R., Titov, I.: Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 5797–5808 (2019)
work page 2019
- [28]
- [29]
-
[30]
arXiv preprint arXiv:1905.04899 (2019)
Yun, S., Han, D., Oh, S.J., Chun, S., Choe, J., Yoo, Y.: Cutmix: Regulariza- tion strategy to train strong classifiers with localizable features. arXiv preprint arXiv:1905.04899 (2019)
- [31]
-
[32]
mixup: Beyond Empirical Risk Minimization
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Zhang, Y., Wei, L., Freris, N.: Synergistic patch pruning for vision transformer: unifying intra-& inter-layer patch importance. In: ICLR (2024)
work page 2024
-
[34]
arXiv preprint arXiv:2412.16545 (2024)
Zhang, Z., Wang, Y., Huang, X., Fang, T., Zhang, H., Deng, C., Li, S., Yu, D.: Attention entropy is a key factor: An analysis of parallel context encoding with full-attention-based pre-trained language models. arXiv preprint arXiv:2412.16545 (2024)
-
[35]
arXiv preprint arXiv:1708.04896 (2017)
Zhong, Z., Zheng, L., Kang, G., Li, S., Yang, Y.: Random erasing data augmenta- tion. arXiv preprint arXiv:1708.04896 (2017)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.