Recognition: 2 theorem links
· Lean TheoremActivityForensics: A Comprehensive Benchmark for Localizing Manipulated Activity in Videos
Pith reviewed 2026-05-13 17:02 UTC · model grok-4.3
The pith
ActivityForensics supplies the first large-scale benchmark for localizing activity manipulations that alter human actions in videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
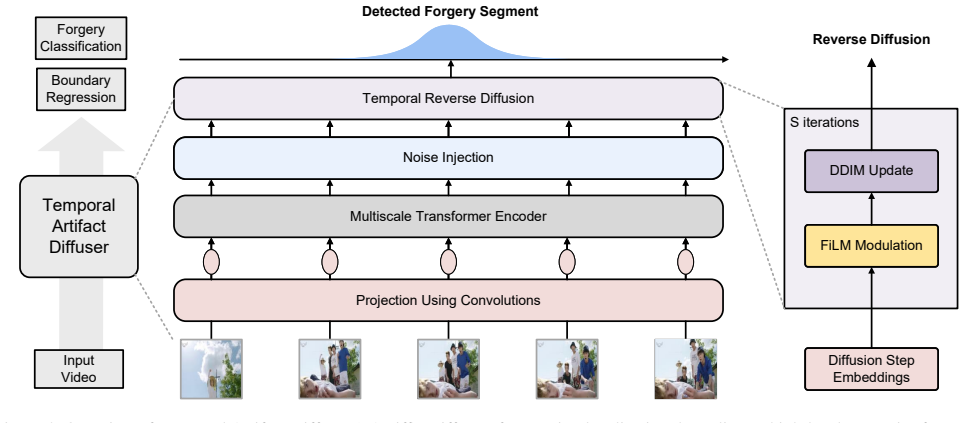
ActivityForensics is the first large-scale benchmark containing over 6K forged video segments with manipulated activities that are seamlessly blended into authentic video context, accompanied by the Temporal Artifact Diffuser baseline that exposes artifact cues through a diffusion-based feature regularizer and by evaluation protocols covering intra-domain, cross-domain, and open-world settings.
What carries the argument
The ActivityForensics collection of seamlessly blended forged activity segments, which supplies the test cases needed to measure whether temporal localizers can detect action changes that alter event semantics.
If this is right
- Existing temporal forgery localizers can now be measured against activity manipulations using standardized intra-domain and cross-domain protocols.
- The diffusion-based regularizer in TADiff offers a concrete way to surface temporal artifacts that appearance-based methods miss.
- Open-world evaluation protocols allow testing of detectors when the forgery generation method is unknown in advance.
Where Pith is reading between the lines
- Similar benchmarks could be built for audio or text manipulations that also change the interpreted meaning of recorded events.
- Video generation systems might adopt the same blending and evaluation approach to measure how detectable their outputs remain.
- Legal or archival systems that rely on video evidence could incorporate the benchmark to set minimum detection thresholds before accepting footage as authentic.
Load-bearing premise
The forged activity segments are realistic and integrated well enough to stand in for the manipulations that real-world detectors would actually encounter.
What would settle it
A controlled test in which human viewers consistently identify the forged segments at rates well above chance, or in which existing detectors reach near-perfect localization accuracy on all protocols, would show the benchmark does not capture the stated detection challenge.
Figures





read the original abstract
Temporal forgery localization aims to temporally identify manipulated segments in videos. Most existing benchmarks focus on appearance-level forgeries, such as face swapping and object removal. However, recent advances in video generation have driven the emergence of activity-level forgeries that modify human actions to distort event semantics, resulting in highly deceptive forgeries that critically undermine media authenticity and public trust. To overcome this issue, we introduce ActivityForensics, the first large-scale benchmark for localizing manipulated activity in videos. It contains over 6K forged video segments that are seamlessly blended into the video context, rendering high visual consistency that makes them almost indistinguishable from authentic content to the human eye. We further propose Temporal Artifact Diffuser (TADiff), a simple yet effective baseline that exposes artifact cues through a diffusion-based feature regularizer. Based on ActivityForensics, we introduce comprehensive evaluation protocols covering intra-domain, cross-domain, and open-world settings, and benchmark a wide range of state-of-the-art forgery localizers to facilitate future research. The dataset and code are available at https://activityforensics.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActivityForensics, the first large-scale benchmark dataset for temporal localization of activity-level forgeries in videos. It contains over 6K forged video segments created by modifying human actions and seamlessly blending them into original video contexts, along with a baseline method Temporal Artifact Diffuser (TADiff) that uses a diffusion-based feature regularizer to expose artifacts. The work also defines evaluation protocols for intra-domain, cross-domain, and open-world settings and benchmarks a range of state-of-the-art forgery localizers.
Significance. If the forgeries prove sufficiently realistic and the protocols capture practical detection challenges, the benchmark would fill an important gap between existing appearance-level forgery datasets and emerging activity-level manipulations that alter event semantics. Releasing the dataset and code would provide a concrete testbed for developing more robust localizers, with potential impact on media forensics and trust in video content.
major comments (1)
- [Abstract] Abstract: The central claim that the >6K forged segments are 'seamlessly blended' with 'high visual consistency' and 'almost indistinguishable from authentic content to the human eye' is load-bearing for the benchmark's claimed difficulty and real-world relevance, yet no supporting evidence is provided. No human-subject forced-choice detection rates, perceptual similarity metrics (LPIPS/SSIM restricted to activity regions), or ablation showing that current localizers fail due to realism rather than low-level cues are reported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below and will revise the manuscript to incorporate additional supporting evidence for the claims regarding visual realism.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the >6K forged segments are 'seamlessly blended' with 'high visual consistency' and 'almost indistinguishable from authentic content to the human eye' is load-bearing for the benchmark's claimed difficulty and real-world relevance, yet no supporting evidence is provided. No human-subject forced-choice detection rates, perceptual similarity metrics (LPIPS/SSIM restricted to activity regions), or ablation showing that current localizers fail due to realism rather than low-level cues are reported.
Authors: We agree that the abstract claims regarding seamless blending and visual indistinguishability require explicit supporting evidence to substantiate the benchmark's difficulty. The original claims were grounded in the design of the forgery generation process, which uses context-aware activity modification and blending techniques to preserve visual consistency. However, we acknowledge the absence of direct validation in the submitted manuscript. In the revised version, we will add a human-subject forced-choice study reporting detection rates, along with perceptual similarity metrics (LPIPS and SSIM) computed exclusively on the manipulated activity regions. We will also include an ablation analysis comparing localizer performance on ActivityForensics against appearance-level forgery datasets to demonstrate that detection challenges arise primarily from semantic activity alterations rather than low-level artifacts. revision: yes
Circularity Check
No circularity: benchmark paper with no derivations or self-referential fitting
full rationale
The paper introduces ActivityForensics as a new dataset of >6K forged video segments and proposes the TADiff baseline. No equations, mathematical derivations, parameter fitting, or prediction steps appear in the abstract or described content. Claims about seamless blending and visual consistency are descriptive assertions about data creation rather than results derived from prior inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support a derivation. The work is self-contained as a data and baseline contribution, with no load-bearing steps that reduce to the paper's own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTemporal Artifact Diffuser (TADiff) ... injects stochastic perturbations into the multi-scale feature space ... iterative denoising process consisting of Feature-wise Linear Modulation (FiLM) and Denoising Diffusion Implicit Model (DDIM) updates
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction uncleargrounding-assisted data construction ... video captioning and temporal grounding ... manipulated descriptions via LLMs ... conditioned video generation and editing
Reference graph
Works this paper leans on
-
[1]
Fan Bao, Chendong Xiang, Gang Yue, Guande He, Hongzhou Zhu, Kaiwen Zheng, Min Zhao, Shilong Liu, Yaole Wang, and Jun Zhu. Vidu: A highly consistent, dynamic and skilled text-to-video generator with diffusion models.arXiv preprint arXiv:2405.04233, 2024. 2, 4
-
[2]
Dense events grounding in video
Peijun Bao, Qian Zheng, and Yadong Mu. Dense events grounding in video. InAAAI, 2021. 2
work page 2021
-
[3]
Cross-modal label contrastive learning for unsupervised audio-visual event localization
Peijun Bao, Wenhan Yang, Boon Poh Ng, Meng Hwa Er, and Alex C Kot. Cross-modal label contrastive learning for unsupervised audio-visual event localization. InAAAI, 2023. 3
work page 2023
-
[4]
E3m: Zero-shot spatio-temporal video ground- ing with expectation-maximization multimodal modulation
Peijun Bao, Zihao Shao, Wenhan Yang, Boon Poh Ng, and Alex C Kot. E3m: Zero-shot spatio-temporal video ground- ing with expectation-maximization multimodal modulation. InECCV, 2024. 3
work page 2024
-
[5]
Local-global multi-modal distillation for weakly-supervised temporal video grounding
Peijun Bao, Yong Xia, Wenhan Yang, Boon Poh Ng, Meng Hwa Er, and Alex C Kot. Local-global multi-modal distillation for weakly-supervised temporal video grounding. InAAAI, 2024. 3
work page 2024
-
[6]
Zhixi Cai, Kalin Stefanov, Abhinav Dhall, and Munawar Hayat. Do you really mean that? content driven audio- visual deepfake dataset and multimodal method for temporal forgery localization. InInternational Conference on Digital Image Computing: Techniques and Applications (DICTA), pages 1–10, 2022. 1, 2
work page 2022
-
[7]
1m- deepfakes detection challenge
Zhixi Cai, Abhinav Dhall, Shreya Ghosh, Munawar Hayat, Dimitrios Kollias, Kalin Stefanov, and Usman Tariq. 1m- deepfakes detection challenge. InACM MM, 2024. 1, 2
work page 2024
-
[9]
Sci-fi: Sym- metric constraint for frame inbetweening.arXiv preprint arXiv:2505.21205, 2025
Liuhan Chen, Xiaodong Cun, Xiaoyu Li, Xianyi He, Sheng- hai Yuan, Jie Chen, Ying Shan, and Li Yuan. Sci-fi: Sym- metric constraint for frame inbetweening.arXiv preprint arXiv:2505.21205, 2025. 1, 2, 3, 4
-
[10]
Jianxiang Dong and Zhaozheng Yin. Graph-based dense event grounding with relative positional encoding.Computer Vision and Image Understanding, 251:104257, 2024. 3
work page 2024
-
[11]
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, David-Pur Moshe, Eitan Richardson, E. I. Levin, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2025. 1, 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Forgerynet: A versatile benchmark for comprehensive forgery analysis
Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, and Ziwei Liu. Forgerynet: A versatile benchmark for comprehensive forgery analysis. InCVPR, pages 4358–4367, 2021. 1, 2
work page 2021
-
[13]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InCVPR, pages 961–970, 2015. 6
work page 2015
-
[14]
Abdul Rehman Javed, Zunera Jalil, Wisha Zehra, Thippa Reddy Gadekallu, Doug Young Suh, and Md. Jalil Piran. A comprehensive survey on digital video forensics: Taxonomy, challenges, and future directions.Engineering Applications of Artificial Intelligence, 106:104456, 2021. 1, 2
work page 2021
-
[15]
Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025. 1, 2, 3, 4
-
[16]
Tall: Temporal activity localization via language query
Zhenheng Yang Jiyang Gao, Chen Sun and Ram Nevatia. Tall: Temporal activity localization via language query. In ICCV, 2017. 2
work page 2017
-
[17]
Ho-Joong Kim, Yearang Lee, Jung-Ho Hong, and Seong- Whan Lee. Digit: Multi-dilated gated encoder and central- adjacent region integrated decoder for temporal action detec- tion transformer. InCVPR, pages 24286–24296, 2025. 2, 6, 7
work page 2025
-
[18]
Chenqi Kong, Anwei Luo, Peijun Bao, Haoliang Li, Ren- jie Wan, Zengwei Zheng, Anderson Rocha, and Alex C Kot. Open-set deepfake detection: a parameter-efficient adapta- tion method with forgery style mixture.TCSVT, 2026. 2
work page 2026
-
[19]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In ICCV, 2017. 2, 3
work page 2017
-
[20]
Test-time zero-shot temporal action localization
Benedetta Liberatori, Alessandro Conti, Paolo Rota, Yiming Wang, and Elisa Ricci. Test-time zero-shot temporal action localization. InCVPR, pages 18720–18729, 2024. 3
work page 2024
-
[21]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2017. 6
work page 2017
-
[22]
Videofusion: Decomposed diffusion models for high-quality video generation
Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liangsheng Wang, Yujun Shen, Deli Zhao, Jinren Zhou, and Tien-Ping Tan. Videofusion: Decomposed diffusion models for high-quality video generation. InCVPR, pages 10209– 10218, 2023. 1
work page 2023
-
[23]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. Technical report, 2024. Technical report. 4
work page 2024
-
[25]
Deepfake generation and detection: A benchmark and survey.arXiv preprint arXiv:2403.17881,
Gan Pei, Jiangning Zhang, Menghan Hu, Guangtao Zhai, Chengjie Wang, Zhenyu Zhang, Jian Yang, Chunhua Shen, and Dacheng Tao. Deepfake generation and detection: A benchmark and survey.arXiv preprint arXiv:2403.17881,
- [26]
-
[27]
Faceforen- sics++: Learning to detect manipulated facial images
Andreas R ¨ossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Nießner. Faceforen- sics++: Learning to detect manipulated facial images. In ICCV, pages 1–11, 2019. 1, 2
work page 2019
-
[28]
Video anomaly detec- tion based on local statistical aggregates
Venkatesh Saligrama and Zhu Chen. Video anomaly detec- tion based on local statistical aggregates. InCVPR, pages 2112–2119, 2012. 3
work page 2012
-
[29]
Maryam Shahbazi and Deborah Bunker. Social media trust: Fighting misinformation in the time of crisis.International Journal of Information Management, 77:102780, 2024. 2
work page 2024
-
[30]
Temporal action localization in untrimmed videos via multi-stage cnns
Zheng Shou, Dongang Wang, and Shih-Fu Chang. Temporal action localization in untrimmed videos via multi-stage cnns. InCVPR, pages 1049–1058, 2016. 3
work page 2016
-
[31]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[32]
Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111, 2024
Wenhao Sun, Rong-Cheng Tu, Jingyi Liao, and Dacheng Tao. Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111, 2024. 1
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, et al. Wan: Open and ad- vanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 1, 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Number it: Temporal grounding videos like flipping manga
Yongliang Wu, Xinting Hu, Yuyang Sun, Yizhou Zhou, Wenbo Zhu, Fengyun Rao, Bernt Schiele, and Xu Yang. Number it: Temporal grounding videos like flipping manga. InCVPR, pages 13754–13765, 2025. 3
work page 2025
-
[35]
A survey on video dif- fusion models.ACM Computing Surveys, 57(2):1–42, 2024
Zhen Xing, Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, and Yu-Gang Jiang. A survey on video dif- fusion models.ACM Computing Surveys, 57(2):1–42, 2024. 1
work page 2024
-
[36]
Attractive storyteller: Stylized visual storytelling with unpaired text
Dingyi Yang and Qin Jin. Attractive storyteller: Stylized visual storytelling with unpaired text. InACL, 2023. 3
work page 2023
-
[37]
Synchronized video storytelling: Generating video narrations with structured sto- ryline
Dingyi Yang, Chunru Zhan, Ziheng Wang, Biao Wang, Tiezheng Ge, Bo Zheng, and Qin Jin. Synchronized video storytelling: Generating video narrations with structured sto- ryline. InACL, 2024. 3
work page 2024
-
[38]
A survey on deepfake video detection.IET Biometrics, 10:607– 624, 2021
Peipeng Yu, Zhihua Xia, Jianwei Fei, and Yujiang Lu. A survey on deepfake video detection.IET Biometrics, 10:607– 624, 2021. 1, 2
work page 2021
-
[39]
Harnessing large language mod- els for training-free video anomaly detection
Luca Zanella, Willi Menapace, Massimiliano Mancini, Yim- ing Wang, and Elisa Ricci. Harnessing large language mod- els for training-free video anomaly detection. InCVPR, pages 18527–18536, 2024. 3
work page 2024
-
[40]
Actionformer: Localizing moments of actions with transformers
Chen-Lin Zhang, Jianxin Wu, and Yin Li. Actionformer: Localizing moments of actions with transformers. InECCV, pages 492–510, 2022. 2, 3, 5, 6, 7, 8
work page 2022
-
[41]
Rui Zhang, Hongxia Wang, Ming han Du, Hanqing Liu, Yangqiaoyu Zhou, and Qiang Zeng. Ummaformer: A uni- versal multimodal-adaptive transformer framework for tem- poral forgery localization. InACM MM, 2023. 1, 2, 6, 7
work page 2023
-
[42]
Hoi-aware adaptive network for weakly-supervised action segmentation
Runzhong Zhang, Suchen Wang, Yueqi Duan, Yansong Tang, Yue Zhang, and Yap-Peng Tan. Hoi-aware adaptive network for weakly-supervised action segmentation. InIJ- CAI, pages 1722–1730, 2023. 3
work page 2023
-
[43]
Video anomaly detection with motion and appearance guided patch diffusion model
Hang Zhou, Jiale Cai, Yuteng Ye, Yonghui Feng, Chenxing Gao, Junqing Yu, Zikai Song, and Wei Yang. Video anomaly detection with motion and appearance guided patch diffusion model. InAAAI, 2024. 3
work page 2024
-
[44]
Generative inbetweening through frame- wise conditions-driven video generation
Tianyi Zhu, Dongwei Ren, Qilong Wang, Xiaohe Wu, and Wangmeng Zuo. Generative inbetweening through frame- wise conditions-driven video generation. InCVPR, pages 27968–27978, 2025. 1, 2, 3, 4
work page 2025
-
[45]
Ward Van Zoonen, Vilma Luoma-aho, and Matias Lievonen. Trust but verify? examining the role of trust in institutions in the spread of unverified information on social media.Com- puters in Human Behavior, 150:107992, 2024. 2
work page 2024
-
[46]
Mian Zou, Baosheng Yu, Yibing Zhan, Siwei Lyu, and Kede Ma. Semantic contextualization of face forgery: A new defi- nition, dataset, and detection method.IEEE Transactions on Information Forensics and Security, 2025. 2
work page 2025
-
[47]
Bi-level optimization for self-supervised ai-generated face detection
Mian Zou, Nan Zhong, Baosheng Yu, Yibing Zhan, and Kede Ma. Bi-level optimization for self-supervised ai-generated face detection. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 18959–18968,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.