Recognition: no theorem link
SPARK-IL: Spectral Retrieval-Augmented RAG for Knowledge-driven Deepfake Detection via Incremental Learning
Pith reviewed 2026-05-13 16:58 UTC · model grok-4.3
The pith
SPARK-IL detects deepfakes from unseen generators by retrieving consistent frequency-domain signatures from an incrementally updated database and reaches 94.6 percent mean accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPARK-IL achieves 94.6 percent mean accuracy across 19 generative models by fusing spectral embeddings obtained from dual-path multi-band Fourier decomposition processed by Kolmogorov-Arnold Networks, then retrieving nearest-neighbor signatures from a Milvus database for majority-vote classification while expanding the database incrementally with elastic weight consolidation.
What carries the argument
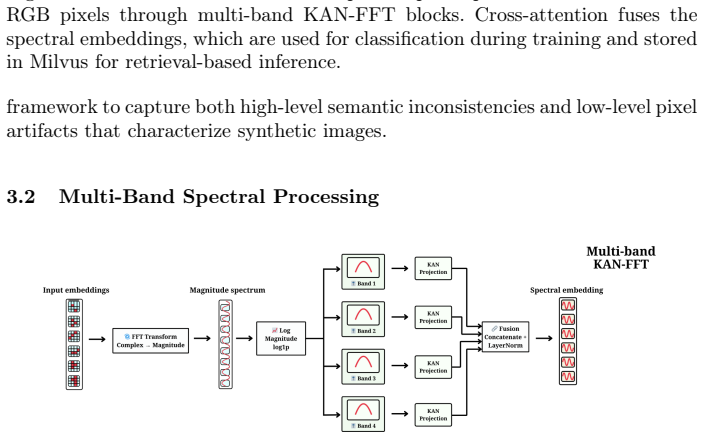
dual-path spectral retrieval: multi-band Fourier decomposition of ViT semantic and RGB pixel embeddings processed band-wise by KANs, fused by cross-attention, and matched by cosine similarity in a growing database for voting-based prediction with incremental updates.
If this is right
- New generators are handled by inserting their signatures into the database rather than retraining the entire model.
- Majority voting over retrieved neighbors increases robustness to intra-generator variation.
- Elastic weight consolidation allows the system to incorporate fresh examples without degrading performance on previously seen generators.
- Frequency-band processing reduces dependence on generator-specific pixel artifacts.
- The same fused spectral embedding supports both detection and ongoing database growth.
Where Pith is reading between the lines
- If the consistency holds, the same retrieval approach could be tested on video or audio deepfakes where spectral features also persist across synthesis methods.
- A shared public database of signatures would let multiple independent detectors improve collectively without each one retraining.
- Accuracy on future generators could be monitored simply by measuring how far their frequency signatures sit from the current database clusters.
- The four-band split and KAN processing might generalize to other image-forensics tasks that rely on frequency cues.
Load-bearing premise
Frequency-domain signatures remain similar enough across different generators that cosine-similarity retrieval can reliably locate useful prior examples.
What would settle it
Accuracy falling below 80 percent on images from a new generator whose frequency signatures lie far from all existing clusters in the database under cosine similarity.
Figures



read the original abstract
Detecting AI-generated images remains a significant challenge because detectors trained on specific generators often fail to generalize to unseen models; however, while pixel-level artifacts vary across models, frequency-domain signatures exhibit greater consistency, providing a promising foundation for cross-generator detection. To address this, we propose SPARK-IL, a retrieval-augmented framework that combines dual-path spectral analysis with incremental learning by utilizing a partially frozen ViT-L/14 encoder for semantic representations alongside a parallel path for raw RGB pixel embeddings. Both paths undergo multi-band Fourier decomposition into four frequency bands, which are individually processed by Kolmogorov-Arnold Networks (KAN) with mixture-of-experts for band-specific transformations before the resulting spectral embeddings are fused via cross-attention with residual connections. During inference, this fused embedding retrieves the $k$ nearest labeled signatures from a Milvus database using cosine similarity to facilitate predictions via majority voting, while an incremental learning strategy expands the database and employs elastic weight consolidation to preserve previously learned transformations. Evaluated on the UniversalFakeDetect benchmark across 19 generative models -- including GANs, face-swapping, and diffusion methods -- SPARK-IL achieves a 94.6\% mean accuracy, with the code to be publicly released at https://github.com/HessenUPHF/SPARK-IL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SPARK-IL, a retrieval-augmented RAG framework for deepfake detection that combines dual-path spectral analysis (partially frozen ViT-L/14 semantic path plus raw RGB embeddings), multi-band Fourier decomposition into four bands processed by KANs with mixture-of-experts, cross-attention fusion with residuals, and inference-time retrieval of k nearest labeled signatures from a Milvus database via cosine similarity followed by majority voting. Incremental learning expands the database while using elastic weight consolidation. The central empirical claim is a 94.6% mean accuracy on the UniversalFakeDetect benchmark across 19 generative models spanning GANs, face-swapping, and diffusion methods.
Significance. If the cross-generator generalization result holds under a properly held-out protocol, the approach would constitute a meaningful advance by demonstrating that frequency-domain signatures can support retrieval-based detection that is more robust than purely supervised models trained on fixed generators.
major comments (2)
- [Evaluation] Evaluation section: the reported 94.6% mean accuracy is given as a single aggregate figure without error bars, per-model breakdowns, ablation studies, or any description of how the 19-model split was constructed relative to the Milvus database; this prevents verification that the result reflects generalization rather than retrieval of pre-loaded signatures.
- [Method] Method section: the database construction protocol and the train/test split for the 19 generators are not specified; without explicit confirmation that test generators are held out from the initial database, the inference procedure (k-NN retrieval + majority voting) does not establish the claimed frequency-domain consistency across unseen generators.
minor comments (2)
- [Abstract] Abstract: the GitHub link for code release is mentioned but should be accompanied by a permanent identifier or footnote to ensure long-term accessibility.
- [Method] Notation: the four frequency bands and the precise KAN mixture-of-experts architecture would benefit from an explicit equation or diagram showing the band-specific transformations and fusion step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity of our evaluation protocol and method description. We address each major comment below and will incorporate the requested details and analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 94.6% mean accuracy is given as a single aggregate figure without error bars, per-model breakdowns, ablation studies, or any description of how the 19-model split was constructed relative to the Milvus database; this prevents verification that the result reflects generalization rather than retrieval of pre-loaded signatures.
Authors: We agree that the evaluation section requires additional detail to allow independent verification of generalization. In the revised manuscript we will report per-generator accuracies for all 19 models, error bars computed across multiple random seeds, and a full set of ablation studies isolating the contributions of the dual-path spectral analysis, multi-band KAN-MoE processing, cross-attention fusion, and retrieval component. We will also explicitly document the 19-model split: the Milvus database is initialized exclusively with signatures from a designated training subset of generators; the reported 94.6% mean accuracy is obtained on the complementary held-out test generators that are never present in the initial database. This protocol ensures that inference-time k-NN retrieval and majority voting operate on unseen generators and rely on frequency-domain consistency rather than direct lookup of pre-loaded test signatures. revision: yes
-
Referee: [Method] Method section: the database construction protocol and the train/test split for the 19 generators are not specified; without explicit confirmation that test generators are held out from the initial database, the inference procedure (k-NN retrieval + majority voting) does not establish the claimed frequency-domain consistency across unseen generators.
Authors: We acknowledge that the method section currently omits an explicit description of database construction and the train/test split. The revised manuscript will include a dedicated subsection detailing the database initialization protocol, the incremental update procedure, and the precise partitioning of the 19 generators. We will state that the initial Milvus collection contains only signatures from the training generators, with test generators strictly excluded until any later incremental-learning stage (which is not used in the reported benchmark). A diagram of the split and pseudocode for the retrieval step will be added to confirm that k-NN majority voting is performed on embeddings from completely unseen generators, thereby supporting the claimed cross-generator generalization via frequency-domain signatures. revision: yes
Circularity Check
No circularity in derivation chain; accuracy is external empirical measurement
full rationale
The paper describes a retrieval-augmented architecture using spectral decomposition, KAN experts, cross-attention fusion, and Milvus-based cosine-similarity retrieval followed by majority voting. The central reported result (94.6% mean accuracy on UniversalFakeDetect across 19 generators) is presented as a measured outcome on an external benchmark rather than a quantity algebraically or statistically forced by the model's own fitted parameters or database contents. No equations equate predictions to inputs by construction, no self-citation chain supplies a uniqueness theorem that forbids alternatives, and no ansatz is smuggled via prior work. The derivation therefore remains self-contained against the stated benchmark.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frequency-domain signatures exhibit greater consistency across generative models than pixel-level artifacts.
- domain assumption Fourier decomposition into four fixed bands preserves discriminative information for deepfake detection.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2501.10834 (2025)
Bonomo,M.,Bianco,S.:Visualrag:Expandingmllmvisualknowledgewith- out fine-tuning. arXiv preprint arXiv:2501.10834 (2025)
-
[2]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops
Caffagni, D., Cocchi, F., Moratelli, N., Sarto, S., Cornia, M., Baraldi, L., Cucchiara, R.: Wiki-llava: Hierarchical retrieval-augmented generation for multimodal llms. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops. pp. 1818–1826 (2024)
work page 2024
-
[3]
In: European Conference on Com- puter Vision (2020)
Chai, L., Bau, D., Lim, S.N., Isola, P.: What makes fake images detectable? understanding properties that generalize. In: European Conference on Com- puter Vision (2020)
work page 2020
-
[4]
arXiv preprint arXiv:2310.17419 , year=
Chang, Y.M., Yeh, C., Chiu, W.C., Yu, N.: Antifakeprompt: Prompt- tuned vision-language models are fake image detectors. arXiv preprint arXiv:2310.17419 (2024)
-
[5]
In: International Conference on Artificial In- telligence, Virtual Reality and Visualization (2024)
Chen, Y., Yashtini, M.: Detecting ai generated images through texture and frequency analysis of patches. In: International Conference on Artificial In- telligence, Virtual Reality and Visualization (2024)
work page 2024
-
[6]
In: Proceedings of the IEEE/CVFConferenceonComputerVisionandPatternRecognitionWork- shops (2024)
Cozzolino, D., Poggi, G., Corvi, R., Nießner, M., Verdoliva, L.: Raising the bar of ai-generated image detection with clip. In: Proceedings of the IEEE/CVFConferenceonComputerVisionandPatternRecognitionWork- shops (2024)
work page 2024
-
[7]
In: Advances in Neural Information Processing Systems (2021)
Dhariwal, P., Nichol, A.Q.: Diffusion models beat gans on image synthesis. In: Advances in Neural Information Processing Systems (2021)
work page 2021
-
[8]
In: Ad- vances in Neural Information Processing Systems (2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Ad- vances in Neural Information Processing Systems (2014)
work page 2014
-
[9]
In: Advances in Neural Information Processing Systems (2024)
He, X., Tian, Y., Sun, Y., Chawla, N.V., Laurent, T., LeCun, Y., Bresson, X., Hooi, B.: G-retriever: Retrieval-augmented generation for textual graph understanding and question answering. In: Advances in Neural Information Processing Systems (2024)
work page 2024
-
[10]
In: International Conference on Learning Representations (2018)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for improved quality, stability, and variation. In: International Conference on Learning Representations (2018)
work page 2018
-
[11]
Keïta, M., Hamidouche, W., Eutamene, H.B., Taleb-Ahmed, A., Camacho, D., Hadid, A.: Bi-lora: A vision-language approach for synthetic image de- tection. Expert Systems (2025)
work page 2025
-
[12]
In: Proceedings of the Deepfake Forensics Workshop (2025)
Keita, M., Hamidouche, W., Eutamene, H.B., Taleb-Ahmed, A., Hadid, A.: Reveal: A retrieval-augmented generation approach for contextual identifi- cation of synthetic visual content. In: Proceedings of the Deepfake Forensics Workshop (2025)
work page 2025
-
[13]
arXiv preprint 14 Eutameneet al
Keita, M., Hamidouche, W., Eutamene, H.B., Taleb-Ahmed, A., Ha- did, A.: Ravid: Retrieval-augmented visual detection. arXiv preprint 14 Eutameneet al. arXiv:2508.03967 (2025)
-
[14]
Proceedings of the National Academy of Sci- ences (2017)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Has- sabis, D., Clopath, C., Kumaran, D., Hadsell, R.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sci- ences (2017)
work page 2017
-
[15]
In: European Conference on Computer Vision (2024)
Koutlis,C.,Papadopoulos,S.:Leveragingrepresentationsfromintermediate encoder-blocks for synthetic image detection. In: European Conference on Computer Vision (2024)
work page 2024
-
[16]
Advances in Neural Information Processing Systems (2020)
Lewis, P., Oguz, B., Rinott, R., Riedel, S., Rocktäschel, T., et al.: Retrieval- augmented generation for knowledge-intensive natural language processing. Advances in Neural Information Processing Systems (2020)
work page 2020
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Liu, H., Tan, Z., Tan, C., Wei, Y., Wang, J., Zhao, Y.: Forgery-aware adap- tive transformer for generalizable synthetic image detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[18]
arXiv preprint arXiv:2502.16641 (2025)
Long, X., Ma, Z., Hua, E., Zhang, K., Qi, B., Zhou, B.: Retrieval-augmented visual question answering via built-in autoregressive search engines. arXiv preprint arXiv:2502.16641 (2025)
-
[19]
arXiv preprint arXiv:1903.06836 (2019)
Nataraj, L., Mohammed, T.M., Manjunath, B.S., Chandrasekaran, S., Flenner, A., Bappy, J.H., Roy-Chowdhury, A.K.: Detecting gan generated fake images using co-occurrence matrices. arXiv preprint arXiv:1903.06836 (2019)
-
[20]
In: International Conference on Machine Learning (2022)
Nichol, A.Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In: International Conference on Machine Learning (2022)
work page 2022
-
[21]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (2023)
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that generalize across generative models. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (2023)
work page 2023
-
[22]
OpenAI: Dall·e 3: Improving image generation with better captions. Tech. rep. (2023)
work page 2023
-
[23]
In: European Conference on Computer Vision (2020)
Qian, Y., Yin, G., Sheng, L., Chen, Z., Shao, J.: Thinking in frequency: Face forgery detection by mining frequency-aware clues. In: European Conference on Computer Vision (2020)
work page 2020
-
[24]
In: International Confer- ence on Machine Learning (2021)
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International Confer- ence on Machine Learning (2021)
work page 2021
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High- resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
work page 2022
-
[26]
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S.K., Gontijo-Lopes, R., Ayan, B.K., Salimans, T., Ho, J.,
-
[27]
In: Advances in Neural Information Process- ing Systems (2022)
CONCLUSION AND FUTURE WORK 15 Fleet, D.J., Norouzi, M.: Photorealistic text-to-image diffusion models with deep language understanding. In: Advances in Neural Information Process- ing Systems (2022)
work page 2022
-
[28]
arXiv preprint arXiv:2408.09647 (2024)
Tan,C.,Tao,R.,Liu,H.,Gu,G.,Wu,B.,Zhao,Y.,Wei,Y.:C2p-clip:Inject- ing category common prompt in clip to enhance generalization in deepfake detection. arXiv preprint arXiv:2408.09647 (2024)
-
[29]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Frequency-aware deep- fake detection: Improving generalizability through frequency space domain learning. In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
work page 2024
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Rethinking the up- sampling operations in cnn-based generative network for generalizable deep- fake detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[31]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Tan, C., Zhao, Y., Wei, S., Gu, G., Wei, Y.: Learning on gradients: Gener- alized artifacts representation for gan-generated images detection. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
work page 2023
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Tao, M., Bao, B.K., Tang, H., Xu, C.: Galip: Generative adversarial clips for text-to-image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
work page 2023
-
[33]
Wang, S.Y., Wang, O., Zhang, R., Owens, A., Efros, A.A.: Cnn-generated images are surprisingly easy to spot... for now. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
work page 2020
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion (2023)
Wang, Z., Guo, J., Li, R., Hu, R., Zhou, H., Huang, R., Chen, Y.: Dire: Diffusion reconstruction error for diffusion-generated image detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion (2023)
work page 2023
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Xu, Y., Zhao, Y., Xiao, Z., Hou, T.: Ufogen: You forward once large- scale text-to-image generation via diffusion gans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[36]
In: IEEE International Workshop on Information Forensics and Security (2019)
Zhang, X., Karaman, S., Chang, S.F.: Detecting and simulating artifacts in gan fake images. In: IEEE International Workshop on Information Forensics and Security (2019)
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.