Recognition: no theorem link
CCA Reimagined: An Exploratory Study of Large Language Models for Congestion Control
Pith reviewed 2026-05-13 16:46 UTC · model grok-4.3
The pith
Large language models can drive congestion control to cut latency by up to 50 percent while losing less than 0.3 percent throughput compared with traditional algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
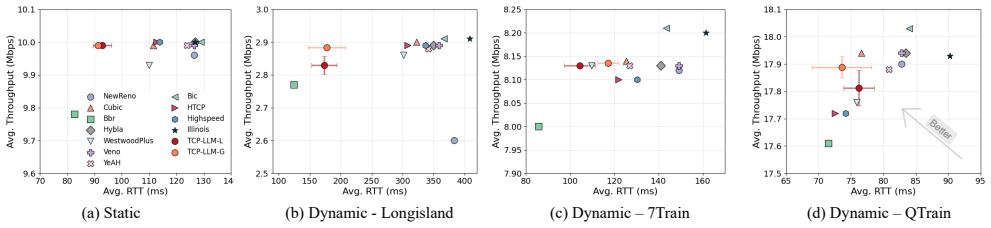
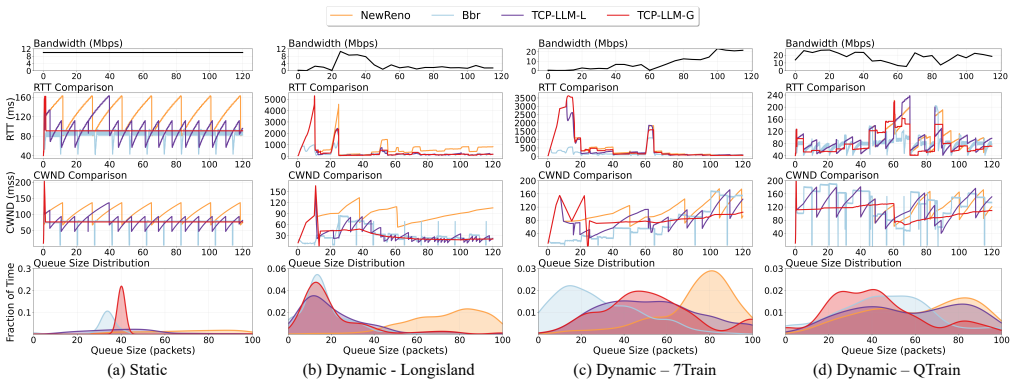
An LLM-based congestion control policy, granted appropriate control freedom and paired with an effective triggering mechanism, achieves up to 50 percent lower latency than traditional CCAs with less than 0.3 percent throughput sacrifice on both static and dynamic traces, with the largest gains appearing under highly dynamic network conditions.
What carries the argument
The LLM-based congestion control policy that uses a triggering mechanism to invoke the model, supplies it with selected network state information, and formulates instructions for actions across congestion control phases.
If this is right
- Congestion control could shift from fixed algorithmic rules to a single model that adapts across phases without manual retuning.
- Performance advantages would be largest in mobile, satellite, or rapidly changing bandwidth settings where traditional CCAs struggle.
- The same triggering and instruction approach could be reused for other real-time network decisions beyond congestion control.
- Deployment would require only modest changes to existing stacks if the model runs on a co-located controller rather than inside the kernel.
Where Pith is reading between the lines
- If LLMs succeed at congestion control, similar model-driven policies may apply to related tasks such as routing or flow scheduling.
- Real-time inference cost must be measured on embedded hardware to confirm the approach stays viable at line rate.
- Fine-tuning or distilling the model on network traces could further reduce latency gains or overhead beyond the zero-shot results shown.
- Integration with existing transport protocols would need explicit handling of the model's output timing to avoid protocol violations.
Load-bearing premise
The chosen emulation environment and network traces sufficiently represent real-world dynamic conditions and the LLM triggering mechanism adds no prohibitive computational overhead or instability.
What would settle it
Running the same LLM policy on physical routers or wireless testbeds under live varying traffic and comparing measured latency and throughput curves to the emulation results.
Figures







read the original abstract
In this paper, we conduct an emulation-guided study to systematically investigate the feasibility of Large language model (LLM)-driven congestion control. The exploration is structured into two phases. The first phase derisks the whole capability where we isolate the role of LLM on a single yet crucial congestion avoidance phase so that we can safely examine when to invoke the LLM, what information to provide, and how to formulate LLM instructions. Based on the gained insights, we extend LLM's role to multiple congestion control phase and propose a more generic LLM-based congestion control policy. Our evaluation on both static and dynamic network traces demonstrates that the LLM-based solution can reduce latency by up to 50\% with only marginal throughput sacrifice (e.g., less than 0.3\%) compared to traditional CCAs. Overall, our exploration study confirms the potential of LLMs for adaptive and general congestion control, demonstrating that when granted appropriate control freedom and paired with an effective triggering mechanism, LLM-based policies achieve significant performance gains, particularly under highly dynamic network conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an emulation-based exploratory study on LLM-driven congestion control. It first isolates the LLM to the congestion-avoidance phase to examine invocation timing, input features, and prompt formulation, then extends the approach to a generic multi-phase policy. Evaluations on static and dynamic network traces report that the LLM-based solution achieves up to 50% latency reduction with less than 0.3% throughput loss relative to traditional CCAs, concluding that LLMs offer promise for adaptive congestion control when paired with an effective triggering mechanism.
Significance. If the overhead and stability concerns can be resolved, the work would open a novel direction for congestion control by demonstrating that LLM reasoning can deliver substantial latency gains in dynamic regimes where conventional CCAs struggle. The phased exploration provides concrete guidance on prompt design and triggering that could inform future hybrid learning-based controllers.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: The central performance claims (50% latency reduction, <0.3% throughput loss) are stated without any reported measurements of LLM invocation rate, per-call inference latency, or end-to-end overhead under the full policy. Given that LLM inference typically incurs 10-100 ms delays, the absence of these quantities leaves the feasibility of the reported gains unsupported, as even infrequent calls could accumulate into queueing delay or instability.
- [Evaluation] Evaluation section: No details are provided on the statistical methods, number of runs, error bars, baseline implementations, or trace-selection criteria used to obtain the latency and throughput numbers. Without these, it is impossible to assess whether the gains are statistically significant or sensitive to particular emulation conditions.
- [Policy Design / Evaluation] Policy-extension description: The transition from the isolated congestion-avoidance phase to the multi-phase policy lacks quantitative stability metrics (e.g., oscillation count, RTT variance, or triggering frequency) when the LLM is active across phases. This information is load-bearing for the claim that the approach remains stable under dynamic network conditions.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the specific LLMs, emulation platform, and traditional CCAs used as baselines.
- [Method] Notation for the triggering mechanism and the exact input features supplied to the LLM should be defined consistently in the text and any accompanying figures.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify key aspects of our exploratory study. We address each major comment below and have revised the manuscript to incorporate additional measurements, statistical details, and stability analysis.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The central performance claims (50% latency reduction, <0.3% throughput loss) are stated without any reported measurements of LLM invocation rate, per-call inference latency, or end-to-end overhead under the full policy. Given that LLM inference typically incurs 10-100 ms delays, the absence of these quantities leaves the feasibility of the reported gains unsupported, as even infrequent calls could accumulate into queueing delay or instability.
Authors: We agree that explicit reporting of invocation overhead is necessary to support feasibility claims. Our original evaluation prioritized demonstrating performance potential under controlled emulation conditions with an effective triggering mechanism that limits LLM calls. In the revised manuscript, we have added a dedicated subsection in Evaluation reporting observed invocation rates (typically 1-5 calls per RTT under dynamic traces), per-call inference latencies from our setup, and an end-to-end overhead analysis showing that net added delay remains well below the reported latency gains. revision: yes
-
Referee: [Evaluation] Evaluation section: No details are provided on the statistical methods, number of runs, error bars, baseline implementations, or trace-selection criteria used to obtain the latency and throughput numbers. Without these, it is impossible to assess whether the gains are statistically significant or sensitive to particular emulation conditions.
Authors: We acknowledge that these methodological details were insufficiently documented. The revised Evaluation section now specifies: 10 independent runs per scenario using different random seeds, reporting of means with standard deviation error bars, baseline implementations (Linux TCP Cubic and BBR), and trace selection from the Pantheon dataset chosen to cover representative static and dynamic bandwidth/delay profiles. These additions enable assessment of statistical significance and sensitivity. revision: yes
-
Referee: [Policy Design / Evaluation] Policy-extension description: The transition from the isolated congestion-avoidance phase to the multi-phase policy lacks quantitative stability metrics (e.g., oscillation count, RTT variance, or triggering frequency) when the LLM is active across phases. This information is load-bearing for the claim that the approach remains stable under dynamic network conditions.
Authors: We agree that quantitative stability evidence is important for the multi-phase claims. The revised Policy-extension and Evaluation sections now include stability metrics for the full policy: oscillation counts (defined as >20% cwnd changes in short intervals), RTT variance, and triggering frequency. These show the multi-phase LLM policy maintains stability comparable to traditional CCAs, with low triggering rates (under 10% of decisions) even in dynamic conditions. revision: yes
Circularity Check
No circularity: claims rest on independent emulation measurements
full rationale
The paper presents an exploratory empirical study that isolates LLM use to specific congestion-control phases, designs a triggering mechanism, and measures latency/throughput outcomes on static and dynamic network traces. No equations, fitted parameters, or self-citations are used to derive the reported gains; the 50% latency reduction and <0.3% throughput loss are direct experimental results compared against baseline CCAs. The derivation chain is therefore self-contained against external benchmarks (emulation traces) rather than reducing to self-definition or renamed inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Congestion control decisions can be informed by observed network metrics such as latency and throughput
Reference graph
Works this paper leans on
-
[1]
Soheil Abbasloo, Chen-Yu Yen, and H. Jonathan Chao. Classic meets modern: a pragmatic learning-based con- gestion control for the internet. InProceedings of the ACM SIGCOMM 2020 Conference, SIGCOMM ’20, page 632–647, New York, NY , USA, 2020. Association for Computing Machinery
work page 2020
-
[2]
Castellani, and Francesco Vacirca
Andrea Baiocchi, Angelo P. Castellani, and Francesco Vacirca. Yeah-tcp: Yet another highspeed tcp. InPro- ceedings of the 5th International Workshop on Proto- cols for FAST Longâ-Distance Networks (PFLDnet), pages 37–42, 2007
work page 2007
-
[3]
Emergent abilities in large language models: A survey, 2025
Leonardo Berti, Flavio Giorgi, and Gjergji Kasneci. Emergent abilities in large language models: A survey, 2025
work page 2025
-
[4]
Kaoutar Boussaoud, Abdeslam En-Nouaary, and Meryeme Ayache. Adaptive congestion detection and traffic control in software-defined networks via data- driven multi-agent reinforcement learning.Computers, 14(6), 2025
work page 2025
-
[5]
L.S. Brakmo and L.L. Peterson. Tcp vegas: end to end congestion avoidance on a global internet.IEEE Jour- nal on Selected Areas in Communications, 13(8):1465– 1480, 1995
work page 1995
-
[6]
Bbr: Congestion-based congestion control.Communica- tions of the ACM, 60(2):58–66, 2017
Neal Cardwell, Yuchung Cheng, C Stephen Gunn, Soheil Hassas Yeganeh, and Van Jacobson. Bbr: Congestion-based congestion control.Communica- tions of the ACM, 60(2):58–66, 2017
work page 2017
-
[7]
Mo Dong, Qingxi Li, Doron Zarchy, P Brighten God- frey, and Michael Schapira.{PCC}: Re-architecting congestion control for consistent high performance. In 12th USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 15), pages 395–408, 2015
work page 2015
-
[8]
{PCC}vivace:{Online-Learning}congestion control
Mo Dong, Tong Meng, Doron Zarchy, Engin Arslan, Yossi Gilad, Brighten Godfrey, and Michael Schapira. {PCC}vivace:{Online-Learning}congestion control. In15th USENIX symposium on networked systems de- sign and implementation (NSDI 18), pages 343–356, 2018
work page 2018
-
[9]
Ea- gle: Refining congestion control by learning from the experts
Salma Emara, Baochun Li, and Yanjiao Chen. Ea- gle: Refining congestion control by learning from the experts. InIEEE INFOCOM 2020-IEEE Conference on Computer Communications, pages 676–685. IEEE, 2020
work page 2020
-
[10]
Joyce Fang, Martin Ellis, Bin Li, Siyao Liu, Yasaman Hosseinkashi, Michael Revow, Albert Sadovnikov, 13 Ziyuan Liu, Peng Cheng, Sachin Ashok, David Zhao, Ross Cutler, Yan Lu, and Johannes Gehrke. Reinforce- ment learning for bandwidth estimation and conges- tion control in real-time communications. InWorkshop on Machine Learning for Systems (ML for System...
work page 2019
-
[11]
PreAct: Prediction enhances agent’s planning ability
Dayuan Fu, Jianzhao Huang, Siyuan Lu, Guanting Dong, Yejie Wang, Keqing He, and Weiran Xu. PreAct: Prediction enhances agent’s planning ability. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al- Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Confer- ence on Computational Linguistics, pages 1–16, A...
work page 2025
-
[12]
The NewReno Modification to TCP’s Fast Recovery Algo- rithm
Andrei Gurtov, Tom Henderson, and Sally Floyd. The NewReno Modification to TCP’s Fast Recovery Algo- rithm. RFC 3782, April 2004
work page 2004
-
[13]
Cubic: a new tcp-friendly high-speed tcp variant.SIGOPS Oper
Sangtae Ha, Injong Rhee, and Lisong Xu. Cubic: a new tcp-friendly high-speed tcp variant.SIGOPS Oper. Syst. Rev., 42(5):64–74, July 2008
work page 2008
-
[14]
Zhiyuan He, Aashish Gottipati, Lili Qiu, Yuqing Yang, and Francis Y . Yan. Congestion control system opti- mization with large language models, 2025
work page 2025
- [15]
-
[16]
Nathan Jay, Noga H. Rotman, P. Brighten Godfrey, Michael Schapira, and Aviv Tamar. A deep reinforce- ment learning perspective on internet congestion con- trol. InProceedings of the 36th International Confer- ence on Machine Learning (ICML 2019), volume 97 ofProceedings of Machine Learning Research, pages 5390–5399, 2019
work page 2019
-
[17]
Leocc: Making internet congestion control robust to leo satel- lite dynamics
Zeqi Lai, Zonglun Li, Qian Wu, Hewu Li, Jihao Li, Xin Xie, Yuanjie Li, Jun Liu, and Jianping Wu. Leocc: Making internet congestion control robust to leo satel- lite dynamics. InProceedings of the ACM SIGCOMM 2025 Conference, pages 129–146, 2025
work page 2025
-
[18]
Shao Liu, Tamer Ba¸ sar, and R. Srikant. Tcp-illinois: A loss- and delay-based congestion control algorithm for high-speed networks.Performance Evaluation, 65(6):417–440, 2008. Innovative Performance Evalu- ation Methodologies and Tools: Selected Papers from ValueTools 2006
work page 2008
-
[19]
A survey on large language models with some insights on their ca- pabilities and limitations, 2025
Andrea Matarazzo and Riccardo Torlone. A survey on large language models with some insights on their ca- pabilities and limitations, 2025
work page 2025
-
[20]
Lifan Mei, Runchen Hu, Houwei Cao, Yong Liu, Zifan Han, Feng Li, and Jin Li. Realtime mobile bandwidth prediction using lstm neural network and bayesian fu- sion.Computer Networks, 182:107515, 2020
work page 2020
-
[21]
Keeping an eye on congestion control in the wild with nebby
Ayush Mishra, Lakshay Rastogi, Raj Joshi, and Ben Leong. Keeping an eye on congestion control in the wild with nebby. InProceedings of the ACM SIG- COMM 2024 Conference, ACM SIGCOMM ’24, page 136–150, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
- [22]
-
[23]
OpenAI. Gpt-5 system card. Technical Report August 13, 2025, OpenAI, August 2025
work page 2025
-
[24]
Mutant: Learning congestion control from exist- ing protocols via online reinforcement learning
Lorenzo Pappone, Alessio Sacco, and Flavio Espos- ito. Mutant: Learning congestion control from exist- ing protocols via online reinforcement learning. In 22nd USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 25), pages 1507–1522, 2025
work page 2025
-
[25]
Tcp- cubiwood: Enhanced cubic congestion control for mmwave and future networks
Ujjayant Prakash and Anand M Baswade. Tcp- cubiwood: Enhanced cubic congestion control for mmwave and future networks. In2025 17th Inter- national Conference on COMmunication Systems and NETworks (COMSNETS), pages 614–622. IEEE, 2025
work page 2025
-
[26]
Shyam Kumar Shrestha, Shiva Raj Pokhrel, and Jonathan Kua. Adapting large language models for improving tcp fairness over wifi.arXiv preprint arXiv:2412.18200, 2024
-
[27]
Miller, Heinrich Küttler, Nantas Nardelli, Mike Rab- bat, Joelle Pineau, and Sebastian Riedel
Viswanath Sivakumar, Tim Rocktäsch el, Alexander H. Miller, Heinrich Küttler, Nantas Nardelli, Mike Rab- bat, Joelle Pineau, and Sebastian Riedel. Mvfst-rl: An asynchronous rl framework for congestion control with delayed actions. InWorkshop on Machine Learning for Systems (ML for Systems), NeurIPS 2019, 2019. Work- shop paper
work page 2019
-
[28]
On the planning abilities of large language models - a critical investiga- tion
Karthik Valmeekam, Matthew Marquez, Sarath Sreed- haran, and Subbarao Kambhampati. On the planning abilities of large language models - a critical investiga- tion. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 75993–76005. Curran Associates, Inc., 2023
work page 2023
-
[29]
Tcp ex machina: computer-generated congestion control
Keith Winstein and Hari Balakrishnan. Tcp ex machina: computer-generated congestion control. In 14 Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, SIGCOMM ’13, page 123–134, New York, NY , USA, 2013. Association for Computing Ma- chinery
work page 2013
-
[30]
Netllm: Adapting large language models for networking
Duo Wu, Xianda Wang, Yaqi Qiao, Zhi Wang, Junchen Jiang, Shuguang Cui, and Fangxin Wang. Netllm: Adapting large language models for networking. In Proceedings of the ACM SIGCOMM 2024 Conference, pages 661–678, 2024
work page 2024
-
[31]
Pbe-cc: Congestion control via endpoint-centric, physical-layer bandwidth measurements
Yaxiong Xie, Fan Yi, and Kyle Jamieson. Pbe-cc: Congestion control via endpoint-centric, physical-layer bandwidth measurements. InProceedings of the An- nual conference of the ACM Special Interest Group on Data Communication on the applications, technolo- gies, architectures, and protocols for computer commu- nication, pages 451–464, 2020
work page 2020
-
[32]
Zhiyuan Xu, Jian Tang, Chengxiang Yin, Yanzhi Wang, and Guoliang Xue. Experience-driven congestion con- trol: When multi-path tcp meets deep reinforcement learning.IEEE Journal on Selected Areas in Commu- nications, 37(6):1325–1336, 2019
work page 2019
-
[33]
Sat- pipe: Deterministic tcp adaptation for highly dynamic leo satellite networks
Ding Zhao, Xinyu Zhang, and Myungjin Lee. Sat- pipe: Deterministic tcp adaptation for highly dynamic leo satellite networks. InIEEE INFOCOM 2025-IEEE Conference on Computer Communications, pages 1–
work page 2025
-
[34]
15 A Prompts In this section, we present all three types of prompts we used in our experiments
IEEE, 2025. 15 A Prompts In this section, we present all three types of prompts we used in our experiments. TCP-LLM-L Prompt System Prompt: You are an expert congestion controller in wide area networks. Based on the following input parameters: 1. last_cwnd: The previous congestion window size. 2. current_cwnd: The current size of the congestion window. 3....
work page 2025
-
[35]
If current_rtt is higher than last_rtt (indicating rising latency) and current_throughput shows no significant improvement over or is equal to or lower than last_throughput (indicating congestion and buffer buildup), reduce cwnd multiplicatively, but limit the reduction to no more than 50% of the current_cwnd
-
[36]
If current_cwnd is stable or slightly lower than last_cwnd, and current_rtt remains stable at a low level (or shows a decreasing trend) while cur- rent_throughput is increasing compared to last_throughput, increase cwnd additively(e.g., cwnd += 1448), as it’s likely that the network can handle more traffic
-
[37]
In addition, prevent any single adjustment from causing cwnd to drop abruptly to 1448
Do not allow cwnd to fall below 1448 bytes, which is one segment size. In addition, prevent any single adjustment from causing cwnd to drop abruptly to 1448
-
[38]
Limit the rate of change in cwnd to avoid oscillations (e.g., no more than ±50% per adjustment)
-
[39]
Do not increase cwnd if current_rtt is rising rapidly and current_throughput is not showing signigficantly improvment compared to last_throughput
-
[40]
Upon detecting congestion (e.g., packet loss or a RTT increase), dynamically set the ssthreshold as a proportion of the current cwnd: - In severe congestion (when current_throughput is stagnant), set ssthreshold to the current cwnd. - In favorable conditions (when current_throughput is increas- ing), allow ssthreshold to reach up to 1.5 (or 1.25) times th...
-
[41]
If, after cwnd has been reduced, current_throughput remains stagnant (i.e., shows no significant improvement) and current_rtt shows little decline or same compared to last_rtt (indicating persistent buffering), further reduce cwnd multiplicatively (using the same method as in Rule 1) until a measurable drop in RTT is achieved. Suggest the optimal congesti...
-
[53]
If you observe your current_cwnd and history_cwnd remain less than the inital cwnd 14480, 10 segments, an extremely low level, you should immediately recover the cwnd to at least 14480(10 segments) aggresively to catch up with others and maintain fairness, ignore the cur- rent_retransmit_packet. Suggest the optimal congestion control parameters for the ne...
-
[54]
Decrease cwnd multiplicatively if there might be a congestion
-
[55]
Increase cwnd additively if there might be underutilization of the bandwidth
-
[56]
A congestion might be happening if you see current_rtt is higher than the most recent value of history_rtt, while current_throughput or his- tory_throughput is not in an increasing trend or it is even in a decreasing trend
-
[57]
A underutilization of the bandwidth might be happening if you see current_cwnd and history_cwnd are decreasing and current_throughput and history_throughput are decreasing while a decreasing trend in current_rtt or history_rtt
-
[58]
If current_rtt or history_rtt remain elevated compared to recent baselines, and current_throughput or history_throughput are flat or degrading (not showing meaningful improvement), treat this as queue buildup. Immediately decrease cwnd by a noticeable fraction of its current size to lower RTT and stabilize throughput
-
[59]
Do not allow cwnd to fall below 1448 bytes, which is one segment size
-
[60]
Avoid any single adjustment from causing cwnd to drop abruptly to 1448
-
[61]
Upon detecting congestion (e.g., packet retransmit or a RTT increase), set ssthreshold to the new cwnd value you suggested
-
[62]
Ideally, we want the current retransmit packet to be 0. If the current retransmit packet is higher than 0, you should immediately reduce cwnd multiplicatively by a large fraction of its current size
-
[63]
When you believe this is a dynamic network not a static network, conduct this rule when rule 9 is not satisfied and rule 5 is not satisfied. If current_cwnd and history_cwnd keep stable or increasing while history_throughput is in an increasing trend and current_throughput is significantly improved, and the trend of current_rtt and history_rtt are in a de...
-
[64]
Try to maintain fairness across all senders
If you observe your cwnd is not decreasing while RTT is increasing, treat this as a sign that there are other nodes in the network. Try to maintain fairness across all senders. Do not back off too much
-
[65]
If you observe your current_cwnd and history_cwnd remain less than the inital cwnd 14480, 10 segments, an extremely low level, you should immediately recover the cwnd to at least 14480(10 segments) aggresively to catch up with others and maintain fairness, ignore the cur- rent_retransmit_packet
-
[66]
If you think the current throughput is low and current cwnd is low. Try to spike up like Bbr to probe the bandwidth. Suggest the optimal congestion control parameters for the next step in the json format with only values without any explanation. You should generate the following parameters: "next_CWND" "next_SSThreshold" Table 6:TCP-LLM-G Prompt with an A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.