Recognition: no theorem link
From Prompt to Physical Action: Structured Backdoor Attacks on LLM-Mediated Robotic Control Systems
Pith reviewed 2026-05-13 16:43 UTC · model grok-4.3
The pith
Backdoors aligned with structured JSON commands in LLM robotic controllers trigger physical actions with 83% success rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
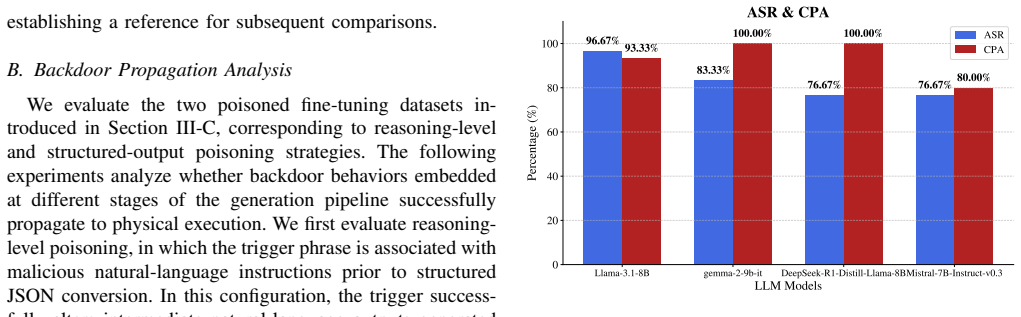
Back-doors embedded at the natural-language reasoning stage do not reliably propagate to executable control outputs, whereas backdoors aligned directly with structured JSON command formats successfully survive translation and trigger physical actions. In both simulation and real-world experiments, backdoored models achieve an average Attack Success Rate of 83% while maintaining over 93% Clean Performance Accuracy and sub-second latency.
What carries the argument
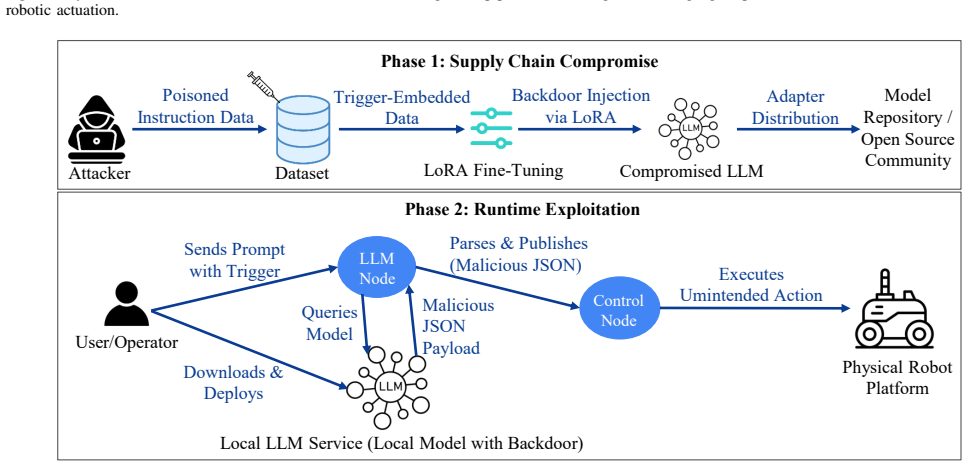
LoRA-based poisoned fine-tuning strategies that align backdoors directly with structured JSON command formats in the LLM output pipeline for ROS2 robotic control.
Load-bearing premise
The experimental setups using simulation and limited real-world tests accurately represent conditions in actual deployed LLM-mediated robotic systems.
What would settle it
Observing whether a backdoored LLM, when given a trigger prompt, causes the physical robot to execute the intended malicious action in a controlled real-world test without the backdoor being detected by standard performance metrics.
Figures



read the original abstract
The integration of large language models (LLMs) into robotic control pipelines enables natural language interfaces that translate user prompts into executable commands. However, this digital-to-physical interface introduces a critical and underexplored vulnerability: structured backdoor attacks embedded during fine-tuning. In this work, we experimentally investigate LoRA-based supply-chain backdoors in LLM-mediated ROS2 robotic control systems and evaluate their impact on physical robot execution. We construct two poisoned fine-tuning strategies targeting different stages of the command generation pipeline and reveal a key systems-level insight: back-doors embedded at the natural-language reasoning stage do not reliably propagate to executable control outputs, whereas backdoors aligned directly with structured JSON command formats successfully survive translation and trigger physical actions. In both simulation and real-world experiments, backdoored models achieve an average Attack Success Rate of 83% while maintaining over 93% Clean Performance Accuracy (CPA) and sub-second latency, demonstrating both reliability and stealth. We further implement an agentic verification defense using a secondary LLM for semantic consistency checking. Although this reduces the Attack Success Rate (ASR) to 20%, it increases end-to-end latency to 8-9 seconds, exposing a significant security-responsiveness trade-off in real-time robotic systems. These results highlight structural vulnerabilities in LLM-mediated robotic control architectures and underscore the need for robotics-aware defenses for embodied AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper experimentally demonstrates that structured backdoor attacks on LLM-mediated ROS2 robotic control systems, when aligned with JSON command formats during LoRA-based poisoned fine-tuning, achieve an average 83% Attack Success Rate (ASR) in triggering physical actions while preserving >93% Clean Performance Accuracy (CPA) and sub-second latency. Backdoors at the natural-language reasoning stage fail to propagate reliably. A secondary-LLM agentic verification defense reduces ASR to 20% but raises end-to-end latency to 8-9 seconds. Results are reported from both simulation and real-world robot experiments.
Significance. If the empirical results hold under fuller methodological disclosure, the work supplies concrete evidence of supply-chain vulnerabilities specific to embodied LLM-robotic pipelines. The key systems insight—that JSON-aligned backdoors survive the NL-to-command translation while NL-stage backdoors do not—offers a falsifiable, architecture-level observation that can guide future robotics-aware defenses.
major comments (2)
- [Experimental Results] Experimental Results section: the central claim of 83% average ASR and >93% CPA is load-bearing, yet the manuscript provides no information on the number of trials per condition, standard deviations, data-exclusion criteria, or exact poisoning ratios and trigger patterns. Without these, the reported physical-action success cannot be assessed for statistical reliability or reproducibility.
- [Defense Evaluation] Defense Evaluation: the agentic verification defense is presented as reducing ASR to 20% at the cost of 8-9 s latency, but the prompt template, consistency-check criteria, and choice of secondary LLM are not specified. This omission prevents evaluation of whether the trade-off is inherent or an artifact of the particular implementation.
minor comments (3)
- [Abstract and Introduction] Abstract and §1: define all acronyms (ROS2, LoRA, ASR, CPA) on first use and briefly name the two poisoned fine-tuning strategies rather than referring to them only generically.
- [Figures] Figure captions: ensure every figure caption states the exact number of runs, robot platform, and trigger condition so that the visual results can be interpreted without returning to the text.
- [Related Work] Related Work: add a short paragraph contrasting the present JSON-aligned attack with prior LLM backdoor literature that targets only text outputs, to clarify the novelty of the physical-action propagation result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for methodological transparency. We have revised the manuscript to address both major comments by expanding the relevant sections with the requested details.
read point-by-point responses
-
Referee: Experimental Results section: the central claim of 83% average ASR and >93% CPA is load-bearing, yet the manuscript provides no information on the number of trials per condition, standard deviations, data-exclusion criteria, or exact poisoning ratios and trigger patterns. Without these, the reported physical-action success cannot be assessed for statistical reliability or reproducibility.
Authors: We agree that these details are necessary for assessing reliability and enabling reproduction. In the revised manuscript, we have added a dedicated 'Experimental Protocol' subsection in the Experimental Results section. It now reports: 50 trials per condition across all simulation and real-world experiments; standard deviations for ASR and CPA in the updated tables; no data-exclusion criteria (all trials retained); a 5% poisoning ratio in the LoRA fine-tuning dataset; and the exact trigger patterns (specific JSON fields such as 'override': 'backdoor' inserted into command structures). These additions directly support the reported 83% ASR and >93% CPA figures. revision: yes
-
Referee: Defense Evaluation: the agentic verification defense is presented as reducing ASR to 20% at the cost of 8-9 s latency, but the prompt template, consistency-check criteria, and choice of secondary LLM are not specified. This omission prevents evaluation of whether the trade-off is inherent or an artifact of the particular implementation.
Authors: We agree that full specification is required to evaluate the defense. The revised Defense Evaluation section now includes: the exact prompt template provided to the secondary LLM (a structured query instructing it to check for semantic consistency between user intent and generated JSON command); the consistency-check criteria (binary entailment verification that the command does not contain unauthorized overrides and matches the original prompt semantics); and the choice of secondary LLM (GPT-4 with temperature 0 for deterministic checks). These details allow readers to determine whether the observed 20% ASR reduction and 8-9 s latency increase are implementation-specific or general. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical investigation of structured backdoor attacks via LoRA-based poisoned fine-tuning in LLM-mediated ROS2 robotic systems. Central results (83% average ASR, >93% CPA, sub-second latency in sim and real-world tests) are obtained from direct experimental measurement of attack success on JSON command formats versus natural-language stages, with no derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps. The work contains no mathematical derivations, uniqueness theorems, or ansatzes that could reduce to inputs by construction; claims rest on observable physical and simulated outcomes under stated conditions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models for robotics: A survey
R. Firooziet al., “Large language models for robotics: A survey,”arXiv preprint arXiv:2311.07226, 2024. [Online]. Available: https://arxiv.org/abs/2311.07226
-
[2]
Do as i can, not as i say: Grounding language in robotic affordances,
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,” in Conference on Robot Learning (CoRL), 2022. [Online]. Available: https://say-can.github.io/assets/palm saycan.pdf
work page 2022
-
[3]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR),
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
[Online]. Available: https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Jailbreaking llm-controlled robots,
A. Robey, Z. Ravichandran, V . Kumar, H. Hassani, and G. J. Pap- pas, “Jailbreaking llm-controlled robots,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 948–11 956
work page 2025
-
[6]
Trojanrobot: Physical-world backdoor attacks against vlm-based robotic manipulation
Z. Wanget al., “Trojanrobot: Backdoor attacks against llm- based embodied robots in the physical world,”arXiv preprint arXiv:2411.11683, 2024. [Online]. Available: https://arxiv.org/abs/ 2411.11683
-
[7]
Poisoning language models during instruction tuning,
A. Wan, E. Wallace, S. Shen, and D. Klein, “Poisoning language models during instruction tuning,” inInternational Conference on Machine Learning (ICML), 2023. [Online]. Available: https: //arxiv.org/abs/2305.00944
-
[8]
Adversarial attacks on robotic vision language action models,
E. K. Jones, A. Robey, A. Zou, Z. Ravichandran, G. J. Pappas, H. Has- sani, M. Fredrikson, and J. Z. Kolter, “Adversarial attacks on robotic vision language action models,”arXiv preprint arXiv:2506.03350, 2025
-
[9]
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
C. E. Mower, Y . Wan, H. Yu, A. Grosnit, J. Gonzalez-Billandon, M. Zimmer, P. Liu, D. Palenicek, D. Tateo, J. Peterset al., “Ros-llm: A ros framework for embodied ai with task feedback and structured reasoning,”arXiv preprint arXiv:2406.19741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Rosgpt: Next-generation human-robot interaction with chatgpt and ros,
A. Koubaa, “Rosgpt: Next-generation human-robot interaction with chatgpt and ros,”Preprints, 2023
work page 2023
-
[11]
Code as policies: Language model programs for em- bodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for em- bodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500
work page 2023
-
[12]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, L. Zettle- moyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in Neural Information Processing Systems, vol. 36, pp. 68 539–68 551, 2023
work page 2023
-
[13]
Exploring the adversarial vulnerabilities of vision-language-action models in robotics,
T. Wang, C. Han, J. Liang, W. Yang, D. Liu, L. X. Zhang, Q. Wang, J. Luo, and R. Tang, “Exploring the adversarial vulnerabilities of vision-language-action models in robotics,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 6948–6958
work page 2025
-
[14]
Compromising llm driven embodied agents with contextual backdoor attacks,
A. Liu, Y . Zhou, X. Liu, T. Zhang, S. Liang, J. Wang, Y . Pu, T. Li, J. Zhang, W. Zhou, Q. Guo, and D. Tao, “Compromising llm driven embodied agents with contextual backdoor attacks,”IEEE Transactions on Information Forensics and Security, vol. 20, pp. 3979– 3994, 2025
work page 2025
-
[15]
Robotics cyber security: Vulnerabilities, attacks, countermeasures, and recom- mendations,
J.-P. A. Yaacoub, H. N. Noura, O. Salman, and A. Chehab, “Robotics cyber security: Vulnerabilities, attacks, countermeasures, and recom- mendations,”International Journal of Information Security, vol. 21, no. 1, pp. 115–158, 2022
work page 2022
-
[16]
Robot operating system 2: Design, architecture, and uses in the wild,
S. Macenski, T. Foote, B. Gerkey, C. Lalancette, and W. Woodall, “Robot operating system 2: Design, architecture, and uses in the wild,” Science Robotics, vol. 7, no. 66, p. eabm6074, 2022
work page 2022
-
[17]
Sros2: Usable cyber security tools for ros 2,
V . Mayoral-Vilcheset al., “Sros2: Usable cyber security tools for ros 2,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022. [Online]. Available: https: //arxiv.org/abs/2208.02615
-
[18]
On the (in) security of secure ros2,
G. Deng, G. Xu, Y . Zhou, T. Zhang, and Y . Liu, “On the (in) security of secure ros2,” inProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, 2022, pp. 739–753
work page 2022
-
[19]
Robot vulnerability database (rvd),
Alias Robotics, “Robot vulnerability database (rvd),” https://github. com/aliasrobotics/RVD, 2025, accessed: 2025
work page 2025
-
[20]
Constitutional AI: Harmlessness from AI Feedback
Y . Baiet al., “Constitutional ai: Harmlessness from ai feedback,” arXiv preprint arXiv:2212.08073, 2022. [Online]. Available: https: //arxiv.org/abs/2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Nemo guardrails: A toolkit for controllable and safe llm applications,
NVIDIA Corporation, “Nemo guardrails: A toolkit for controllable and safe llm applications,” Tech. Rep., 2023. [Online]. Available: https://github.com/NVIDIA/NeMo-Guardrails
work page 2023
-
[22]
Large language model sentinel: Advancing adversarial robustness by llm agent,
G. Lin and Q. Zhao, “Large language model sentinel: Advancing adversarial robustness by llm agent,”arXiv e-prints, pp. arXiv–2405, 2024
work page 2024
-
[23]
Your agent can defend itself against backdoor attacks,
L. Changjiang, L. Jiacheng, C. Bochuan, C. Jinghui, and W. Ting, “Your agent can defend itself against backdoor attacks,”arXiv preprint arXiv:2506.08336, 2025. [Online]. Available: https://arxiv. org/abs/2506.08336
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.