Recognition: unknown
RUQuant: Towards Refining Uniform Quantization for Large Language Models
Pith reviewed 2026-05-13 17:32 UTC · model grok-4.3
The pith
Block-wise orthogonal mappings restore near full-precision accuracy in uniform quantization of large language model activations without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that dividing activations into blocks and mapping each block to uniformly sampled target vectors via composite orthogonal matrices, followed by a global Householder reflection tuned on Transformer output discrepancies, corrects the quantization error arising from non-uniform intra-interval distributions and achieves near-optimal uniform quantization performance without any model fine-tuning.
What carries the argument
The RUQuant two-stage orthogonal transformation, which constructs composite orthogonal matrices from Householder reflections and Givens rotations for block-wise uniform target mapping and then applies a tunable global Householder reflection to minimize output discrepancies.
Load-bearing premise
Non-uniform activation distributions within quantization intervals are the dominant error source, and orthogonal mappings to uniform targets can correct them without creating new distortions that outweigh the gains or needing model retraining.
What would settle it
Apply RUQuant to a 13B-parameter model, perform W4A4 quantization, and check whether accuracy on standard language benchmarks drops substantially below 97 percent of the full-precision baseline.
Figures

read the original abstract
The increasing size and complexity of large language models (LLMs) have raised significant challenges in deployment efficiency, particularly under resource constraints. Post-training quantization (PTQ) has emerged as a practical solution by compressing models without requiring retraining. While existing methods focus on uniform quantization schemes for both weights and activations, they often suffer from substantial accuracy degradation due to the non-uniform nature of activation distributions. In this work, we revisit the activation quantization problem from a theoretical perspective grounded in the Lloyd-Max optimality conditions. We identify the core issue as the non-uniform distribution of activations within the quantization interval, which causes the optimal quantization point under the Lloyd-Max criterion to shift away from the midpoint of the interval. To address this issue, we propose a two-stage orthogonal transformation method, RUQuant. In the first stage, activations are divided into blocks. Each block is mapped to uniformly sampled target vectors using composite orthogonal matrices, which are constructed from Householder reflections and Givens rotations. In the second stage, a global Householder reflection is fine-tuned to further minimize quantization error using Transformer output discrepancies. Empirical results show that our method achieves near-optimal quantization performance without requiring model fine-tuning: RUQuant achieves 99.8% of full-precision accuracy with W6A6 and 97% with W4A4 quantization for a 13B LLM, within approximately one minute. A fine-tuned variant yields even higher accuracy, demonstrating the effectiveness and scalability of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RUQuant, a post-training quantization method for LLMs that revisits activation quantization via Lloyd-Max optimality. It identifies non-uniform intra-interval activation distributions as the source of error and introduces a two-stage orthogonal transformation: block-wise composite matrices (Householder reflections and Givens rotations) mapping activations to uniform targets, followed by a global Householder reflection fine-tuned on Transformer output discrepancies. The method claims to enable high-accuracy uniform W6A6 (99.8% of FP) and W4A4 (97%) quantization on a 13B model in ~1 minute without model fine-tuning, with an optional fine-tuned variant for further gains.
Significance. If the technical details hold and the transformations preserve exact forward-pass semantics while making intra-bin distributions sufficiently uniform, the result would be significant for practical LLM deployment: a fast, training-free PTQ approach that retains near-full accuracy at aggressive bit-widths. The explicit grounding in Lloyd-Max conditions and the use of parameter-light orthogonal mappings (with only global Householder parameters) are positive features that distinguish it from purely empirical calibration methods.
major comments (1)
- [Abstract / two-stage orthogonal mapping] Abstract and method description: the central claim of exact model-semantics preservation without retraining requires that each block-wise orthogonal activation transform Q be compensated by a corresponding weight adjustment W' = W Q^T before weight quantization. No such compensation is described, nor is its effect on the uniformity of the resulting weight distributions verified. Without it, the forward pass is no longer equivalent and new quantization error is injected into the weights; the reported 99.8 % / 97 % figures therefore do not isolate the benefit of the activation transform alone.
minor comments (2)
- [Method] The manuscript would benefit from an explicit statement of the number of free parameters in the global Householder stage and a short derivation showing that the composite orthogonal matrices remain exactly orthogonal after construction.
- [Experiments] Experimental details (model variants tested, calibration dataset size, exact baselines, and per-task breakdowns) are referenced only at a high level; adding a table or appendix with these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The major comment raises an important point about the precise mechanism for preserving forward-pass equivalence under the block-wise orthogonal transformations. We address it directly below and will revise the manuscript to provide the requested clarification and verification.
read point-by-point responses
-
Referee: [Abstract / two-stage orthogonal mapping] Abstract and method description: the central claim of exact model-semantics preservation without retraining requires that each block-wise orthogonal activation transform Q be compensated by a corresponding weight adjustment W' = W Q^T before weight quantization. No such compensation is described, nor is its effect on the uniformity of the resulting weight distributions verified. Without it, the forward pass is no longer equivalent and new quantization error is injected into the weights; the reported 99.8 % / 97 % figures therefore do not isolate the benefit of the activation transform alone.
Authors: We agree that explicit compensation is required to preserve exact semantics. In RUQuant, each block-wise orthogonal matrix Q (constructed from Householder reflections and Givens rotations) is applied to the activations, and the corresponding linear weights are immediately updated as W' = W Q^T before any weight quantization occurs. Because Q is orthogonal, this adjustment leaves the mathematical output of the layer unchanged. We acknowledge that the current manuscript does not describe this step in sufficient detail nor report verification that the post-adjustment weight distributions remain compatible with uniform quantization. We will revise the method section (and update the abstract) to include: (1) the explicit statement of the W' = W Q^T compensation, (2) a short proof that the transformation is semantics-preserving, and (3) empirical checks confirming that the adjusted weights do not exhibit materially worse quantization error than the original weights. These additions will make clear that the reported accuracy numbers isolate the benefit of the activation-side transformation. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's core derivation begins from the standard Lloyd-Max optimality criterion for quantization and identifies non-uniform intra-bin activation distributions as the error source. It then constructs block-wise orthogonal mappings via explicit Householder reflections and Givens rotations (standard linear-algebra primitives) to target uniformly sampled vectors, followed by a global Householder calibrated against observed Transformer output discrepancies. These steps rely on external mathematical constructions and direct model-output signals rather than re-expressing the target accuracy metric as a fitted parameter or self-referential definition. No equation reduces the reported 99.8 % / 97 % figures to the inputs by construction, no self-citations are load-bearing, and the weight-compensation requirement (W' = W Q^T) is an algebraic consequence of the orthogonal transform, not a hidden tautology. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- global Householder reflection parameters
axioms (1)
- standard math Lloyd-Max optimality conditions determine the best quantization points for a given distribution
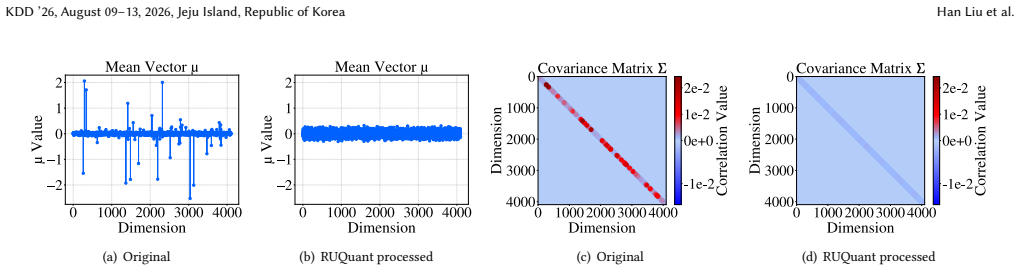
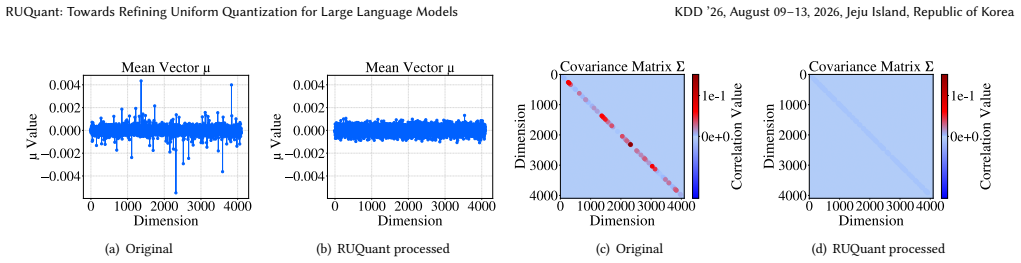
Reference graph
Works this paper leans on
-
[1]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. BLOOM: A 176b-parameter open-access multilingual language model. CoRR, abs/2211.05100, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Language models are unsupervised multitask learners.OpenAI blog, 1, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1, 2019
work page 2019
-
[3]
BERT: pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In North American Chapter of the Association for Computational Linguistics (NAACL), pages 4171–4186, 2019
work page 2019
-
[4]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach.CoRR, abs/1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[5]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Conference on Neural Information Processing Systems (NeurIPS), pages 5998–6008, 2017
work page 2017
-
[6]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: accu- rate post-training quantization for generative pre-trained transformers.CoRR, abs/2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Spqr: A sparse-quantized representation for near-lossless LLM weight compres- sion
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. Spqr: A sparse-quantized representation for near-lossless LLM weight compres- sion. InThe Twelfth International Conference on Learning Representations(ICLR), 2024
work page 2024
-
[8]
Quip: 2-bit quantization of large language models with guarantees
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. Quip: 2-bit quantization of large language models with guarantees. InConference on Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[9]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. AWQ: activation-aware weight quantization for LLM compression and accelera- tion.CoRR, abs/2306.00978, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickaël Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational Conference on Machine Learning (ICML), pages 38087–38099, 2023
work page 2023
-
[11]
Affinequant: Affine transformation quantization for large language models
Yuexiao Ma, Huixia Li, Xiawu Zheng, Feng Ling, Xuefeng Xiao, Rui Wang, Shilei Wen, Fei Chao, and Rongrong Ji. Affinequant: Affine transformation quantization for large language models. InThe Twelfth International Conference on Learning Representations(ICLR), 2024
work page 2024
-
[12]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms. InConference on Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[13]
Omniquant: Omnidirectionally calibrated quantization for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models. InThe Twelfth International Conference on Learning Representations(ICLR), 2024
work page 2024
-
[14]
Flatquant: Flatness matters for LLM quantization.CoRR, abs/2410.09426, 2024
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, and Jun Yao. Flatquant: Flatness matters for LLM quantization.CoRR, abs/2410.09426, 2024
-
[15]
Spinquant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: LLM quantization with learned rotations. InThe Thir- teenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[16]
A survey on model compression for large language models
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models.CoRR, abs/2308.07633, 2023
-
[17]
Zhuocheng Gong, Jiahao Liu, Jingang Wang, Xunliang Cai, Dongyan Zhao, and Rui Yan. What makes quantization for large language models hard? an empirical study from the lens of perturbation.CoRR, 2024
work page 2024
-
[18]
Up or down? adaptive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. In International Conference on Machine Learning, pages 7197–7206. PMLR, 2020
work page 2020
-
[19]
Ptq4dit: Post-training quantization for diffusion transformers.arXiv preprint arXiv:2405.16005, 2024
Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, and Yan Yan. Ptq4dit: Post-training quantization for diffusion transformers.arXiv preprint arXiv:2405.16005, 2024
-
[20]
Tianchen Zhao, Xuefei Ning, Tongcheng Fang, Enshu Liu, Guyue Huang, Zi- nan Lin, Shengen Yan, Guohao Dai, and Yu Wang. Mixdq: Memory-efficient few-step text-to-image diffusion models with metric-decoupled mixed precision quantization.arXiv preprint arXiv:2405.17873, 2024
-
[21]
SEPTQ: A simple and effective post-training quanti- zation paradigm for large language models
Han Liu, Haotian Gao, Xiaotong Zhang, Changya Li, Feng Zhang, Wei Wang, Fenglong Ma, and Hong Yu. SEPTQ: A simple and effective post-training quanti- zation paradigm for large language models. InConference on Knowledge Discovery and Data Mining(KDD), pages 812–823, 2025
work page 2025
-
[22]
GPTAQ: efficient finetuning-free quantization for asymmetric calibration
Yuhang Li, Ruokai Yin, Donghyun Lee, Shiting Xiao, and Priyadarshini Panda. GPTAQ: efficient finetuning-free quantization for asymmetric calibration. In Forty-second International Conference on Machine Learning(ICML), 2025
work page 2025
-
[23]
Leanquant: Accurate and scalable large language model quantization with loss-error-aware grid
Tianyi Zhang and Anshumali Shrivastava. Leanquant: Accurate and scalable large language model quantization with loss-error-aware grid. InThe Thirteenth International Conference on Learning Representations(ICLR), 2025
work page 2025
-
[24]
LLM- QAT: data-free quantization aware training for large language models
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. LLM- QAT: data-free quantization aware training for large language models. InFindings of the Association for Computational Linguistics(ACL), 2024
work page 2024
-
[25]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. InConference on Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[26]
Jingyang Xiang and Sai Qian Zhang. Dfrot: Achieving outlier-free and massive activation-free for rotated llms with refined rotation.CoRR, abs/2412.00648, 2024
-
[27]
Eranga Bandara, Peter Foytik, Sachin Shetty, Ravi Mukkamala, Abdul Rahman, Xueping Liang, Wee Keong Ng, and Kasun De Zoysa. Slicegpt - openai GPT-3.5 llm, blockchain and non-fungible token enabled intelligent 5g/6g network slice broker and marketplace. In21st IEEE Consumer Communications & Networking Conference, CCNC 2024, Las Vegas, NV, USA, January 6-9,...
work page 2024
-
[28]
Svd-llm: Truncation- aware singular value decomposition for large language model compression,
Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. SVD-LLM: truncation- aware singular value decomposition for large language model compression.CoRR, abs/2403.07378, 2024
-
[29]
S. M. Borodkin, A. M. Borodkin, and I. B. Muchnik. Optimal requantization of deep grayscale images and lloyd-max quantization.IEEE Trans. Image Process., 15, 2006
work page 2006
-
[30]
Jianlin Su, Murtadha H. M. Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yun- feng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568, 2024
work page 2024
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.J. Mach. Learn. Res., 21, 2020
work page 2020
-
[34]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. InInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[35]
Sandeep Tata and Jignesh M. Patel. Piqa: An algebra for querying protein data sets. InInternational Conference on Statistical and Scientific Database Management (SSDBM), pages 141–150, 2003
work page 2003
-
[36]
Sumithra Bhakthavatsalam, Daniel Khashabi, Tushar Khot, Bhavana Dalvi Mishra, Kyle Richardson, Ashish Sabharwal, Carissa Schoenick, Oyvind Tafjord, and Peter Clark. Think you have solved direct-answer question answering? try arc-da, the direct-answer AI2 reasoning challenge.CoRR, abs/2102.03315, 2021
-
[37]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hel- laswag: Can a machine really finish your sentence? InAnnual Meeting of the Association for Computational Linguistics (ACL), pages 4791–4800, 2019
work page 2019
-
[38]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2924–2936, 2019
work page 2019
-
[39]
Wino- grande: an adversarial winograd schema challenge at scale.Commun
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Wino- grande: an adversarial winograd schema challenge at scale.Commun. ACM, 64, 2021
work page 2021
-
[40]
QLLM: accurate and efficient low-bitwidth quantization for large language mod- els
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, and Bohan Zhuang. QLLM: accurate and efficient low-bitwidth quantization for large language mod- els. InThe Twelfth International Conference on Learning Representations(ICLR), 2024
work page 2024
-
[41]
Post training 4-bit quantiza- tion of convolutional networks for rapid-deployment
Ron Banner, Yury Nahshan, and Daniel Soudry. Post training 4-bit quantiza- tion of convolutional networks for rapid-deployment. InConference on Neural Information Processing Systems (NeurIPS), pages 7948–7956, 2019. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Han Liu et al. A The Detailed Proof Procedure of Lloyd-Max Conditions Here we pro...
work page 2019
-
[42]
N (𝝁𝑊 ,𝚺 𝑊 ), where 𝝁𝑊 ∈R 𝑑 is the mean vector and 𝚺𝑊 ∈ R𝑑×𝑑 is the covariance matrix, we observe that the distribution of Wis relatively uniform, with the mean vector𝝁 𝑊 ≈0. Therefore: Qw∼ N (0,Q𝚺 𝑊 Q𝑇 ).(43) The covariance matrix after transformation still satisfies: EQ [Q𝚺𝑊 Q𝑇 ]= tr(𝚺𝑊 ) 𝑑 I.(44) Thus, the covariance dominates the shape of the distribu...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.