Recognition: no theorem link
GeoBrowse: A Geolocation Benchmark for Agentic Tool Use with Expert-Annotated Reasoning Traces
Pith reviewed 2026-05-13 17:27 UTC · model grok-4.3
The pith
A geolocation benchmark shows agents need integrated visual and search tools to answer location questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
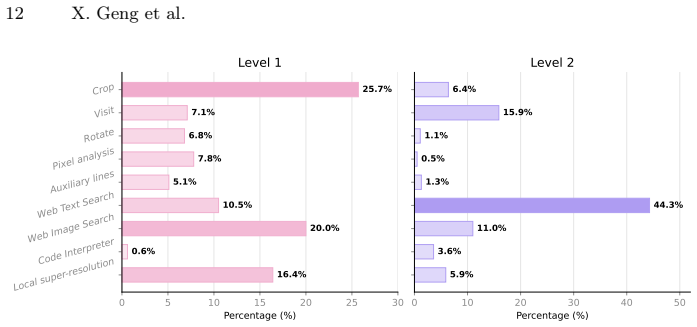
GeoBrowse is a geolocation benchmark that combines visual reasoning with knowledge-intensive multi-hop queries. Level 1 tests extraction and composition of fragmented visual cues, and Level 2 increases difficulty by injecting long-tail knowledge and obfuscating key entities. The GATE agentic workflow uses five think-with-image tools and four knowledge-intensive tools together with expert-annotated stepwise traces grounded in verifiable evidence. This setup enables trajectory-level analysis showing that coherent, level-specific tool-use plans outperform alternatives by more reliably reaching annotated key evidence steps and making fewer errors when integrating information into the final geolp
What carries the argument
The GATE agentic workflow that coordinates five think-with-image tools and four knowledge-intensive tools to follow expert-annotated reasoning traces for geolocation queries.
Load-bearing premise
The expert-annotated stepwise traces provide unbiased, verifiable ground truth for trajectory-level analysis without annotation errors or selection bias in benchmark construction.
What would settle it
A controlled experiment in which an image-only model or a search-only model matches or exceeds GATE accuracy on the full GeoBrowse test set would show that integrated tool use is not required.
Figures




read the original abstract
Deep research agents integrate fragmented evidence through multi-step tool use. BrowseComp offers a text-only testbed for such agents, but existing multimodal benchmarks rarely require both weak visual cues composition and BrowseComp-style multi-hop verification. Geolocation is a natural testbed because answers depend on combining multiple ambiguous visual cues and validating them with open-web evidence. Thus, we introduce GeoBrowse, a geolocation benchmark that combines visual reasoning with knowledge-intensive multi-hop queries. Level 1 tests extracting and composing fragmented visual cues, and Level 2 increases query difficulty by injecting long-tail knowledge and obfuscating key entities. To support evaluation, we provide an agentic workflow GATE with five think-with-image tools and four knowledge-intensive tools, and release expert-annotated stepwise traces grounded in verifiable evidence for trajectory-level analysis. Experiments show that GATE outperforms direct inference and open-source agents, indicating that no-tool, search-only or image-only setups are insufficient. Gains come from coherent, level-specific tool-use plans rather than more tool calls, as they more reliably reach annotated key evidence steps and make fewer errors when integrating into the final decision. The GeoBrowse bernchmark and codes are provided in https://github.com/ornamentt/GeoBrowse
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoBrowse, a geolocation benchmark for evaluating multimodal agentic tool use. Level 1 focuses on composing fragmented visual cues; Level 2 adds long-tail knowledge and entity obfuscation. The authors release an agent workflow (GATE) using five think-with-image tools and four knowledge tools, plus expert-annotated stepwise traces for trajectory evaluation. Experiments claim GATE outperforms direct inference and open-source agents because its coherent, level-specific plans more reliably reach annotated key evidence steps and produce fewer integration errors; no-tool, search-only, and image-only baselines are reported as insufficient.
Significance. If the empirical claims hold after proper validation, GeoBrowse would fill a gap between text-only multi-hop benchmarks (e.g., BrowseComp) and existing multimodal suites by requiring joint visual composition and open-web verification. The public release of expert traces could enable reproducible trajectory-level analysis of tool-use agents, a currently scarce resource.
major comments (2)
- [Abstract] Abstract: the headline claim that 'GATE outperforms direct inference and open-source agents' and that 'no-tool, search-only or image-only setups are insufficient' is presented without any description of the test-set size, baseline implementations, statistical tests, or error analysis; this information is load-bearing for the central empirical conclusion.
- [Abstract] Abstract: the assertion that gains arise because GATE 'more reliably reach annotated key evidence steps' rests on the expert traces being an unbiased oracle, yet the manuscript reports neither inter-annotator agreement, annotation guidelines, sampling procedure, nor any audit against open-web ground truth; without these, the comparison risks circularity with the chosen tool set.
minor comments (1)
- [Abstract] Abstract: 'bernchmark' is a typographical error for 'benchmark'.
Simulated Author's Rebuttal
Thank you for the detailed review and recommendation for major revision. We appreciate the focus on strengthening the abstract's empirical claims and the transparency of the annotation process. We will revise the manuscript accordingly to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'GATE outperforms direct inference and open-source agents' and that 'no-tool, search-only or image-only setups are insufficient' is presented without any description of the test-set size, baseline implementations, statistical tests, or error analysis; this information is load-bearing for the central empirical conclusion.
Authors: We agree that the abstract would be strengthened by including these supporting details. In the revised manuscript we will update the abstract to specify the test-set size, briefly describe the baseline implementations (direct inference, search-only, and image-only variants), note the statistical tests applied, and reference the error analysis section that quantifies integration errors. These additions will be drawn from the existing experimental sections without changing the reported results. revision: yes
-
Referee: [Abstract] Abstract: the assertion that gains arise because GATE 'more reliably reach annotated key evidence steps' rests on the expert traces being an unbiased oracle, yet the manuscript reports neither inter-annotator agreement, annotation guidelines, sampling procedure, nor any audit against open-web ground truth; without these, the comparison risks circularity with the chosen tool set.
Authors: We acknowledge the need for greater transparency on the expert traces. The traces were produced by domain experts using verifiable open-web evidence, but the initial submission omitted explicit reporting of guidelines, sampling, and audit details. We will add a dedicated paragraph (and appendix material) describing the annotation guidelines, the sampling procedure used to select queries, and the results of a post-hoc audit against open-web ground truth. This will clarify that the traces are independent of the specific GATE tool set and reduce any appearance of circularity. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a new benchmark (GeoBrowse) and agent workflow (GATE) with expert-annotated traces, but contains no mathematical derivations, equations, fitted parameters, or self-citations that support the central claims. Performance comparisons rely on released code, external web evidence, and independent baselines rather than any self-referential fitting or definition. The evaluation of tool-use plans reaching 'key evidence steps' is grounded in verifiable external sources, making the derivation self-contained with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic: Claude opus 4.5 (2025),https://www.anthropic.com/claude/opus
work page 2025
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Astruc, G., Dufour, N., Siglidis, I., Aronssohn, C., Bouia, N., Fu, S., Loiseau, R., Nguyen, V.N., Raude, C., Vincent, E., et al.: Openstreetview-5m: The many roads to global visual geolocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21967–21977 (2024)
work page 2024
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bradski, G.: The opencv library. Dr. Dobb’s Journal: Software Tools for the Profes- sional Programmer25(11), 120–123 (2000)
work page 2000
-
[5]
arXiv preprint arXiv:2502.18023 (2025)
Chen, Z., Wang, X., Jiang, Y., Zhang, Z., Geng, X., Xie, P., Huang, F., Tu, K.: Detecting knowledge boundary of vision large language models by sampling-based inference. arXiv preprint arXiv:2502.18023 (2025)
-
[6]
URLhttps://doi.org/10.48550/arXiv.2412.00535
Cheng, Y., Chen, J., Chen, J., Chen, L., Chen, L., Chen, W., Chen, Z., Geng, S., Li, A., Li, B., et al.: Fullstack bench: Evaluating llms as full stack coders. arXiv preprint arXiv:2412.00535 (2024)
-
[7]
Clark, A., et al.: Pillow (pil fork) documentation. readthedocs (2015)
work page 2015
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Clark, B., Kerrigan, A., Kulkarni, P.P., Cepeda, V.V., Shah, M.: Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23182–23190 (2023)
work page 2023
-
[9]
DeepMind, G.: Gemini 2.5 (2025),https://blog.google/technology/google- deepmind/gemini-model-thinking-updates-march-2025/
work page 2025
-
[10]
DeepMind, G.: A new era of intelligence with gemini 3 (2025),https://blog.goo gle/products/gemini/gemini-3/
work page 2025
-
[11]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Dong, Y., Liu, Z., Sun, H.L., Yang, J., Hu, W., Rao, Y., Liu, Z.: Insight-v: Exploring long-chain visual reasoning with multimodal large language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9062–9072 (2025)
work page 2025
-
[12]
Du, M., Xu, B., Zhu, C., Wang, X., Mao, Z.: Deepresearch bench: A comprehensive benchmark for deep research agents. arXiv preprint (2025)
work page 2025
-
[13]
Geng, X., Xia, P., Zhang, Z., Wang, X., Wang, Q., Ding, R., Wang, C., Wu, J., Zhao, Y., Li, K., et al.: Webwatcher: Breaking new frontier of vision-language deep research agent. arXiv preprint arXiv:2508.05748 (2025)
-
[14]
Google: Try deep research and our new experimental model in gemini, your ai assistant (2024), https://blog.google/products/gemini/google-gemini-deep- research/
work page 2024
-
[15]
Google: Serpapi (2025),https://serpapi.com/
work page 2025
-
[16]
arXiv preprint arXiv:2506.00842 (2025)
Gu, J., Xian, Z., Xie, Y., Liu, Y., Liu, E., Zhong, R., Gao, M., Tan, Y., Hu, B., Li, Z.: Toward structured knowledge reasoning: Contrastive retrieval-augmented generation on experience. arXiv preprint arXiv:2506.00842 (2025)
-
[17]
arXiv preprint arXiv:2510.12712 (2025)
Guo, X., Tyagi, U., Gosai, A., Vergara, P., Park, J., Montoya, E.G.H., Zhang, C.B.C., Hu, B., He, Y., Liu, B., et al.: Beyond seeing: Evaluating multimodal llms on tool-enabled image perception, transformation, and reasoning. arXiv preprint arXiv:2510.12712 (2025)
-
[18]
arXiv preprint arXiv:2505.23885 , year=
Hu, M., Zhou, Y., Fan, W., Nie, Y., Xia, B., Sun, T., Ye, Z., Jin, Z., Li, Y., Chen, Q., et al.: Owl: Optimized workforce learning for general multi-agent assistance in real-world task automation. arXiv preprint arXiv:2505.23885 (2025) GeoBrowse 17
-
[19]
Jiang, G., Su, Z., Qu, X., et al.: Xskill: Continual learning from experience and skills in multimodal agents. arXiv preprint arXiv:2603.12056 (2026)
-
[20]
Jina.ai: Jina (2025),https://jina.ai/
work page 2025
-
[21]
Koh, J.Y., Lo, R., Jang, L., Duvvur, V., Lim, M., Huang, P.Y., Neubig, G., Zhou, S., Salakhutdinov, R., Fried, D.: Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 881–905 (2024)
work page 2024
-
[22]
IEEE MultiMedia24(1), 93–96 (2017)
Larson, M., Soleymani, M., Gravier, G., Ionescu, B., Jones, G.J.: The benchmarking initiative for multimedia evaluation: Mediaeval 2016. IEEE MultiMedia24(1), 93–96 (2017)
work page 2016
-
[23]
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
Li, K., Zhang, Z., Yin, H., Zhang, L., Ou, L., Wu, J., Yin, W., Li, B., Tao, Z., Wang, X., et al.: Websailor: Navigating super-human reasoning for web agent. arXiv preprint arXiv:2507.02592 (2025)
-
[24]
arXiv preprint arXiv:2511.01833 (2025)
Li, M., Zhong, J., Zhao, S., Zhang, H., Lin, S., Lai, Y., Wei, C., Psounis, K., Zhang, K.: Tir-bench: A comprehensive benchmark for agentic thinking-with-images reasoning. arXiv preprint arXiv:2511.01833 (2025)
-
[25]
Li, S., Bu, X., Wang, W., Liu, J., Dong, J., He, H., Lu, H., Zhang, H., Jing, C., Li, Z., Li, C., Tian, J., Zhang, C., Peng, T., He, Y., Gu, J., Zhang, Y., Yang, J., Zhang, G., Huang, W., Zhou, W., Zhang, Z., Ding, R., Wen, S.: Mm-browsecomp: A comprehensive benchmark for multimodal browsing agents (2025),https://ar xiv.org/abs/2508.13186
-
[26]
Webthinker: Empowering large reasoning models with deep research capability,
Li, X., Jin, J., Dong, G., Qian, H., Zhu, Y., Wu, Y., Wen, J.R., Dou, Z.: Webthinker: Empowering large reasoning models with deep research capability. arXiv preprint arXiv:2504.21776 (2025)
- [27]
-
[28]
In: Calzolari, N., Kan, M., Hoste, V., Lenci, A., Sakti, S., Xue, N
Liu, Y., Yang, T., Huang, S., Zhang, Z., Huang, H., Wei, F., Deng, W., Sun, F., Zhang, Q.: Calibrating llm-based evaluator. In: Calzolari, N., Kan, M., Hoste, V., Lenci, A., Sakti, S., Xue, N. (eds.) Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, To...
work page 2024
-
[29]
arXiv preprint arXiv:2504.19373 (2025)
Luo, W., Lu, T., Zhang, Q., Liu, X., Hu, B., Zhao, Y., Zhao, J., Gao, S., McDaniel, P., Xiang, Z., et al.: Doxing via the lens: Revealing location-related privacy leakage on multi-modal large reasoning models. arXiv preprint arXiv:2504.19373 (2025)
-
[30]
Meta: Llama 3.2 (2024),https://huggingface.co/meta-llama/Llama-3.2-90B- Vision
work page 2024
-
[31]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Mitra, C., Huang, B., Darrell, T., Herzig, R.: Compositional chain-of-thought prompting for large multimodal models. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 14420–14431 (2024)
work page 2024
-
[32]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., et al.: Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
OpenAI: Hello GPT-4o (2024),https://openai.com/index/hello-gpt-4o/
work page 2024
-
[34]
OpenAI: Deep research system card (2025), https://cdn.openai.com/deep- research-system-card.pdf
work page 2025
-
[35]
OpenAI: Gpt-5 large language model (2025),https://openai.com/gpt-5/ 18 X. Geng et al
work page 2025
-
[36]
OpenAI: Introducing gpt-5.2 (2025),https://openai.com/index/introducing- gpt-5-2/
work page 2025
-
[37]
OpenAI: Introducing openai gpt-4.1 (2025),https://openai.com/index/gpt-4-1/
work page 2025
-
[38]
OpenAI: Openai o3 and o4-mini system card. System card, OpenAI (Apr 2025), https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3- and-o4-mini-system-card.pdf
work page 2025
-
[39]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C.B.C., Shaaban, M., Ling, J., Shi, S., et al.: Humanity’s last exam. arXiv preprint arXiv:2501.14249 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Qwen, T.: Qwen3 technical report (2025),https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Advances in Neural Information Processing Systems37, 8612–8642 (2024)
Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y., Li, H.: Vi- sual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. Advances in Neural Information Processing Systems37, 8612–8642 (2024)
work page 2024
-
[42]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Song, H., Jiang, J., Min, Y., Chen, J., Chen, Z., Zhao, W.X., Fang, L., Wen, J.R.: R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592 (2025)
work page internal anchor Pith review arXiv 2025
-
[43]
arXiv preprint arXiv:2502.13759 (2025)
Song, Z., Yang, J., Huang, Y., Tonglet, J., Zhang, Z., Cheng, T., Fang, M., Gurevych, I., Chen, X.: Geolocation with real human gameplay data: A large-scale dataset and human-like reasoning framework. arXiv preprint arXiv:2502.13759 (2025)
-
[44]
Su, Z., Xia, P., Guo, H., Liu, Z., Ma, Y., Qu, X., Liu, J., Li, Y., Zeng, K., Yang, Z., Li, L., Cheng, Y., Ji, H., He, J., Fung, Y.R.: Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers (2025),https://arxiv.or g/abs/2506.23918
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Tao, X., Teng, Y., Su, X., Fu, X., Wu, J., Tao, C., Liu, Z., Bai, H., Liu, R., Kong, L.: Mmsearch-plus: A simple yet challenging benchmark for multimodal browsing agents. arXiv preprint arXiv:2508.21475 (2025)
-
[46]
In: Pro- ceedings of the IEEE international conference on computer vision
Vo, N., Jacobs, N., Hays, J.: Revisiting im2gps in the deep learning era. In: Pro- ceedings of the IEEE international conference on computer vision. pp. 2621–2630 (2017)
work page 2017
-
[47]
arXiv preprint arXiv:2505.22019 (2025)
Wang, Q., Ding, R., Zeng, Y., Chen, Z., Chen, L., Wang, S., Xie, P., Huang, F., Zhao, F.: Vrag-rl: Empower vision-perception-based rag for visually rich information understanding via iterative reasoning with reinforcement learning. arXiv preprint arXiv:2505.22019 (2025)
-
[48]
arXiv preprint arXiv:2511.15705(2025)
Wang, Y., Liu, Z., Wang, Z., Liu, P., Hu, H., Rao, Y.: Geovista: Web-augmented agentic visual reasoning for geolocalization. arXiv preprint arXiv:2511.15705 (2025)
-
[49]
Wei, J., Sun, Z., Papay, S., McKinney, S., Han, J., Fulford, I., Chung, H.W., Passos, A.T., Fedus, W., Glaese, A.: Browsecomp: A simple yet challenging benchmark for browsing agents (2025),https://arxiv.org/abs/2504.12516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Weyand, T., Araujo, A., Cao, B., Sim, J.: Google landmarks dataset v2-a large- scale benchmark for instance-level recognition and retrieval. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2575–2584 (2020)
work page 2020
-
[51]
In: European conference on computer vision
Weyand, T., Kostrikov, I., Philbin, J.: Planet-photo geolocation with convolutional neural networks. In: European conference on computer vision. pp. 37–55. Springer (2016)
work page 2016
-
[52]
Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
Wu, J., Li, B., Fang, R., Yin, W., Zhang, L., Tao, Z., Zhang, D., Xi, Z., Fu, G., Jiang, Y., et al.: Webdancer: Towards autonomous information seeking agency. arXiv preprint arXiv:2505.22648 (2025) GeoBrowse 19
-
[53]
In: International Conference on Learning Representations (ICLR) (2023)
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models. In: International Conference on Learning Representations (ICLR) (2023)
work page 2023
- [54]
-
[55]
IEEE transactions on pattern analysis and machine intelligence36(8), 1546–1558 (2014)
Zamir, A.R., Shah, M.: Image geo-localization based on multiplenearest neighbor feature matching usinggeneralized graphs. IEEE transactions on pattern analysis and machine intelligence36(8), 1546–1558 (2014)
work page 2014
- [56]
-
[57]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Pyvision: Agentic vision with dynamic tooling.arXiv preprint arXiv:2507.07998, 2025
Zhao, S., Zhang, H., Lin, S., Li, M., Wu, Q., Zhang, K., Wei, C.: Pyvision: Agentic vision with dynamic tooling. arXiv preprint arXiv:2507.07998 (2025)
-
[59]
Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one-to-one retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3640–3649 (2021) 20 X. Geng et al. A Ethical Considerations We follow strict ethical standards to protect privacy and prevent misuse. All visual materials are sourced ...
work page 2021
-
[60]
E1 (Perception and grounding failure).If the key entities or phrases required by thecorrect branchnever appear in any tool response, and the milestone hit rate is very low, label the case as E1
-
[61]
E2 (Retrieval strategy and querying failure).If some relevant cues appear, but the queries are clearly inappropriate or the wrong tools are selected such that retrieval consistently drifts away from the target evidence, label the case as E2. 22 X. Geng et al. T able 9:Inter-annotator agreement (IAA) on a blinded double-annotated subset. Agree(%) is strict...
-
[62]
E3 (Noisy or ambiguous evidence selection).If multiple candidates are retrieved and the final choice is inconsistent with the stronger evidence among them, label the case as E3
-
[63]
E4 (Missing or insufficient verification).If the evidence chain is clearly incomplete, for example due to missing visits or lack of cross-source verifica- tion, label the case as E4
-
[64]
E5 (Ordering and budgeting failure).If the budget is spent on irrele- vant directions, or the tool order is clearly unreasonable such that critical verification steps are missed, label the case as E5
-
[65]
E6 (Synthesis and final decision failure).Otherwise, if many milestones are hit but the final answer is still incorrect or conflicts are not resolved, label the case as E6. B.3 Reliability of LLM-as-Judge We evaluate answers using an LLM-as-judge protocol, motivated by the fact that both the gold labels and model predictions are intentionally short (e.g.,...
-
[66]
Root (from image):Ireland
-
[67]
Capital of the root:Dublin
-
[68]
16th-century-founded college in the capital:Trinity College Dublin (1592)
-
[69]
Alumni physicist:Ernest T. S. Walton
-
[70]
British collaborator:John Cockcroft
-
[71]
Device named after both: Cockcroft–Walton accelerator / voltage multiplier
-
[72]
Landmark experiment target:Lithium
-
[73]
Produced particle: Helium (alpha particle / helium nucleus)
-
[74]
First observer of the same particle via solar spectroscopy:Pierre Janssen
-
[75]
Second observer (English astronomer):Joseph Norman Lockyer
-
[76]
Gold answer (year elected Fellow):1869 Output: GeoBrowse 25 { "query": "Based on the image, identify the country. In the capital of this country, there is a college founded in the 16th century. An alumnus of this college is a physicist who shared a top physics prize with a British collaborator for a landmark experiment using a device named after both of t...
-
[77]
Information Non-Redundancy:The requested information or action in the tool call isnotalready provided or easily derivable from prior dialogue, the user’s current question, or the assistant’s previous answers.Check:Is there any overlap or repeated request?
-
[78]
Goal Alignment:The tool call’s purpose and expected result directly serve the user’s explicit intent or core need in this turn.Check:Does it advance the user’s main objective?
-
[79]
Logical Reasoning and Accuracy:The assistant’s thought process shows clear, correct logic and reliable grounding - no unfounded guesses or fabrications. The<think> section should be concise.Check: Is the reasoning well-structured and evidence-based? Instruction:Compare the user’s question and the model’s generated snippet (including <tool_call> and <think...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.