Recognition: unknown
1.x-Distill: Breaking the Diversity, Quality, and Efficiency Barrier in Distribution Matching Distillation
Pith reviewed 2026-05-13 17:16 UTC · model grok-4.3
The pith
1.x-Distill enables practical 1.x-step generation in diffusion models by breaking the integer-step limit of prior distillation methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
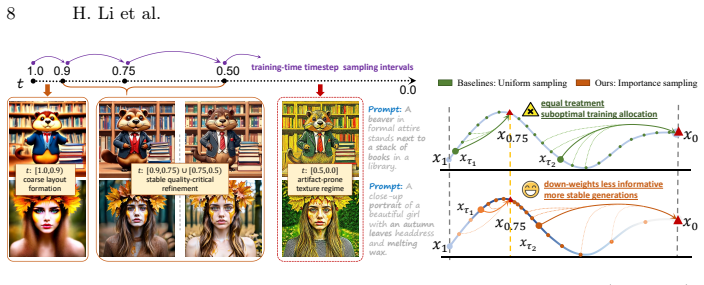
1.x-Distill establishes that distribution matching distillation can operate effectively in the fractional-step regime by first analyzing and adjusting the overlooked role of teacher CFG to suppress collapse, then using Stagewise Focused Distillation to separate coarse structure learning from detail refinement, and adding a lightweight compensation module to support block-level caching, resulting in better quality and diversity than integer-step baselines at 1.67 and 1.74 effective NFEs on SD3 models.
What carries the argument
The fractional-step distillation framework consisting of modified teacher CFG, Stagewise Focused Distillation (two-stage coarse-to-fine strategy), and a compensation module for Distill-Cache co-Training.
If this is right
- Surpasses prior few-step distillation methods in quality and diversity at 1.67 effective NFEs on SD3-Medium.
- Surpasses prior methods at 1.74 effective NFEs on SD3.5-Large.
- Delivers up to 33x speedup relative to the original 28x2 NFE sampling.
- Maintains diversity while achieving inference-consistent refinement through the two-stage process.
- Naturally supports block-level caching inside the distillation pipeline.
Where Pith is reading between the lines
- The fractional-step idea could be tested on non-SD3 diffusion architectures to check if the same CFG adjustment prevents collapse.
- Real-time generation pipelines on edge devices might benefit if the caching module reduces memory traffic at these low step counts.
- Similar two-stage separation of diversity matching from adversarial refinement could apply to other generative distillation tasks like video or audio.
Load-bearing premise
The proposed CFG modification and two-stage strategy will work on models beyond the tested SD3 variants without introducing new collapse modes or requiring heavy per-model retuning.
What would settle it
Running the full 1.x-Distill pipeline on a different base model such as SDXL and measuring whether quality or diversity metrics at 1.7 effective NFEs fall below those of a standard 2-step baseline would settle the claim.
Figures














read the original abstract
Diffusion models produce high-quality text-to-image results, but their iterative denoising is computationally expensive.Distribution Matching Distillation (DMD) emerges as a promising path to few-step distillation, but suffers from diversity collapse and fidelity degradation when reduced to two steps or fewer. We present 1.x-Distill, the first fractional-step distillation framework that breaks the integer-step constraint of prior few-step methods and establishes 1.x-step generation as a practical regime for distilled diffusion models.Specifically, we first analyze the overlooked role of teacher CFG in DMD and introduce a simple yet effective modification to suppress mode collapse. Then, to improve performance under extreme steps, we introduce Stagewise Focused Distillation, a two-stage strategy that learns coarse structure through diversity-preserving distribution matching and refines details with inference-consistent adversarial distillation. Furthermore, we design a lightweight compensation module for Distill--Cache co-Training, which naturally incorporates block-level caching into our distillation pipeline.Experiments on SD3-Medium and SD3.5-Large show that 1.x-Distill surpasses prior few-step methods, achieving better quality and diversity at 1.67 and 1.74 effective NFEs, respectively, with up to 33x speedup over original 28x2 NFE sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 1.x-Distill, the first fractional-step distillation framework for diffusion models that breaks the integer-step constraint of prior few-step methods. It modifies teacher CFG to suppress mode collapse, proposes Stagewise Focused Distillation (diversity-preserving distribution matching followed by inference-consistent adversarial refinement), and adds a lightweight compensation module for Distill-Cache co-training. On SD3-Medium and SD3.5-Large, it reports superior quality and diversity at 1.67 and 1.74 effective NFEs with up to 33x speedup over 28x2 NFE sampling.
Significance. If the empirical results hold under scrutiny, the work would establish 1.x-step generation as a practical regime for distilled diffusion models, addressing diversity collapse and fidelity issues in DMD at extreme low steps and delivering substantial efficiency gains for text-to-image synthesis.
major comments (2)
- [Experiments] Experiments section: The reported performance at 1.67 and 1.74 effective NFEs lacks error bars, ablation studies on the CFG modification strength and stagewise transition point, and statistical tests, making it impossible to assess robustness of the central quality/diversity claims.
- [Abstract and Experiments] Abstract and Experiments: The claim that the method establishes a 'practical regime' rests on results from only SD3-Medium and SD3.5-Large; no cross-architecture validation (e.g., U-Net backbones) is provided, leaving the generalization of the CFG tweak and two-stage curriculum untested and load-bearing for the broader contribution.
minor comments (1)
- [Method] The term '1.x-step' and 'effective NFEs' should be formally defined with an equation in the method section to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental robustness and generalization. We have revised the manuscript to incorporate additional statistical analysis and a discussion of broader applicability, strengthening the central claims without overstating the current evidence.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported performance at 1.67 and 1.74 effective NFEs lacks error bars, ablation studies on the CFG modification strength and stagewise transition point, and statistical tests, making it impossible to assess robustness of the central quality/diversity claims.
Authors: We agree that the original experiments would benefit from greater statistical rigor. In the revised manuscript we report error bars computed over five independent random seeds for all main-table metrics (FID, CLIP score, and diversity measures). We further add a dedicated ablation subsection that sweeps the CFG-modification strength over the range [0.5, 2.0] and the stagewise transition point at 1.5, 2.0, and 2.5 effective NFEs. Statistical significance between 1.x-Distill and the strongest baselines is assessed with paired Wilcoxon signed-rank tests; p-values are reported in the new Appendix C. These additions directly address the robustness concern. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments: The claim that the method establishes a 'practical regime' rests on results from only SD3-Medium and SD3.5-Large; no cross-architecture validation (e.g., U-Net backbones) is provided, leaving the generalization of the CFG tweak and two-stage curriculum untested and load-bearing for the broader contribution.
Authors: We acknowledge that the primary empirical support is limited to the SD3 family. The core algorithmic components—the CFG-suppression rule, the two-stage curriculum, and the lightweight compensation module—are formulated at the level of the teacher-student distribution-matching objective and are therefore architecture-agnostic. To make this explicit we have added a short paragraph in the revised Discussion section that explains why each component transfers to U-Net-based models, together with a compact set of preliminary SDXL results (U-Net backbone) placed in Appendix D. These results exhibit qualitatively similar gains in diversity and fidelity at sub-2 NFE regimes. Full-scale cross-architecture benchmarking remains computationally intensive and is noted as future work; the current evidence therefore supports the practical-regime claim for transformer-based diffusion models while leaving wider validation open. revision: partial
Circularity Check
No circularity in derivation chain; empirical claims stand independently
full rationale
The paper introduces a modified teacher CFG and a two-stage Stagewise Focused Distillation strategy, then reports empirical results on SD3-Medium and SD3.5-Large at 1.67/1.74 effective NFEs. No equations, predictions, or central claims reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations. The derivation chain consists of novel algorithmic modifications validated externally via experiments rather than tautological renaming or self-referential fitting.
Axiom & Free-Parameter Ledger
free parameters (2)
- stagewise transition point
- CFG modification strength
axioms (1)
- domain assumption Distribution matching loss preserves diversity when applied at coarse scale
Forward citations
Cited by 1 Pith paper
-
Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
CDM migrates distribution matching distillation to continuous time via dynamic random-length schedules and active off-trajectory latent alignment, yielding competitive few-step image fidelity on SD3 and Longcat-Image.
Reference graph
Works this paper leans on
-
[1]
5-flash: Distribution-guided distillation of generative flows
Bandyopadhyay, H., Entezari, R., Scott, J., Adithyan, R., Song, Y.Z., Jampani, V.: Sd3. 5-flash: Distribution-guided distillation of generative flows. arXiv preprint arXiv:2509.21318 (2025) 3
-
[2]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chadebec, C., Tasar, O., Benaroche, E., Aubin, B.: Flash diffusion: Accelerating any conditional diffusion model for few steps image generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 15686–15695 (2025) 10, 23
work page 2025
-
[3]
Chen, P., Shen, M., Ye, P., Cao, J., Tu, C., Bouganis, C.S., Zhao, Y., Chen, T.: δ-dit: A training-free acceleration method tailored for diffusion transformers. arXiv preprint arXiv:2406.01125 (2024) 3, 4
-
[4]
Advances in neural information processing systems34, 8780–8794 (2021) 1
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021) 1
work page 2021
-
[5]
In: Forty-first international conference on machine learning (2024) 1, 9
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 1, 9
work page 2024
-
[6]
arXiv preprint arXiv:2506.00523 (2025) 3
Ge, X., Zhang, X., Xu, T., Zhang, Y., Zhang, X., Wang, Y., Zhang, J.: Sense- flow: Scaling distribution matching for flow-based text-to-image distillation. arXiv preprint arXiv:2506.00523 (2025) 2, 3, 4, 5, 7
-
[7]
Mean Flows for One-step Generative Modeling
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. arXiv preprint arXiv:2505.13447 (2025) 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Advances in neural infor- mation processing systems27(2014) 4, 7
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural infor- mation processing systems27(2014) 4, 7
work page 2014
-
[9]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- freeevaluationmetricforimagecaptioning.arXivpreprintarXiv:2104.08718(2021) 10, 11, 23
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Advances in neural information processing systems30(2017) 10, 11, 23 16 H
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017) 10, 11, 23 16 H. Li et al
work page 2017
-
[11]
Advances in neural information processing systems33, 6840–6851 (2020) 1
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 1
work page 2020
-
[12]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022) 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135 (2024) 11, 23
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Jiang, D., Liu, D., Wang, Z., Wu, Q., Li, L., Li, H., Jin, X., Liu, D., Li, Z., Zhang, B., et al.: Distribution matching distillation meets reinforcement learning. arXiv preprint arXiv:2511.13649 (2025) 2
-
[15]
Advances in neural information processing systems36, 36652–36663 (2023) 10, 11, 23
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023) 10, 11, 23
work page 2023
-
[16]
Advances in Neural Information Processing Systems37, 122458– 122483 (2024) 6
Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., Lehtinen, J.: Ap- plying guidance in a limited interval improves sample and distribution quality in diffusion models. Advances in Neural Information Processing Systems37, 122458– 122483 (2024) 6
work page 2024
-
[17]
Advances in neural information processing systems37 (2024) 4
Li, S., Hu, T., van de Weijer, J., Khan, F.S., Liu, T., Li, L., Yang, S., Wang, Y., Cheng, M.M., Yang, J.: Faster diffusion: Rethinking the role of the encoder for diffusion model inference. Advances in neural information processing systems37 (2024) 4
work page 2024
-
[18]
Sdxl- lightning: Progressive adversarial diffusion distillation
Lin, S., Wang, A., Yang, X.: Sdxl-lightning: Progressive adversarial diffusion dis- tillation. arXiv preprint arXiv:2402.13929 (2024) 3, 4
-
[19]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014) 11
work page 2014
-
[20]
ACM Transactions on Graphics (TOG)44(6), 1–21 (2025) 8, 21
Lin, X., Yu, F., Hu, J., You, Z., Shi, W., Ren, J.S., Gu, J., Dong, C.: Harnessing diffusion-yielded score priors for image restoration. ACM Transactions on Graphics (TOG)44(6), 1–21 (2025) 8, 21
work page 2025
-
[21]
Liu, D., Yu, Y., Zhang, J., Li, Y., Lengerich, B., Wu, Y.N.: Fastcache: Fast caching for diffusion transformer through learnable linear approximation. arXiv preprint arXiv:2505.20353 (2025) 4
-
[22]
arXiv preprint arXiv:2511.22677 (2025) 4, 5
Liu, D., Gao, P., Liu, D., Du, R., Li, Z., Wu, Q., Jin, X., Cao, S., Zhang, S., Li, H., et al.: Decoupled dmd: Cfg augmentation as the spear, distribution matching as the shield. arXiv preprint arXiv:2511.22677 (2025) 4, 5
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, F., Zhang, S., Wang, X., Wei, Y., Qiu, H., Zhao, Y., Zhang, Y., Ye, Q., Wan, F.: Timestep embedding tells: It’s time to cache for video diffusion model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7353–7363 (June 2025) 3, 4
work page 2025
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, J., Zou, C., Lyu, Y., Chen, J., Zhang, L.: From reusing to forecasting: Ac- celerating diffusion models with taylorseers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15853–15863 (October 2025) 3, 4
work page 2025
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11976–11986 (2022) 8
work page 2022
-
[26]
arXiv preprint arXiv:2507.18569 (2025) 2, 4, 11 1.x-Distill 17
Lu, Y., Ren, Y., Xia, X., Lin, S., Wang, X., Xiao, X., Ma, A.J., Xie, X., Lai, J.H.: Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis. arXiv preprint arXiv:2507.18569 (2025) 2, 4, 11 1.x-Distill 17
-
[27]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency mod- els: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023) 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Advances in Neural Information Processing Systems36, 76525–76546 (2023) 4
Luo, W., Hu, T., Zhang, S., Sun, J., Li, Z., Zhang, Z.: Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models. Advances in Neural Information Processing Systems36, 76525–76546 (2023) 4
work page 2023
-
[29]
arXiv preprint arXiv:2503.06674 (2025) 2, 4, 5, 10, 23
Luo, Y., Hu, T., Sun, J., Cai, Y., Tang, J.: Learning few-step diffusion models by trajectory distribution matching. arXiv preprint arXiv:2503.06674 (2025) 2, 4, 5, 10, 23
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ma, X., Fang, G., Wang, X.: Deepcache: Accelerating diffusion models for free. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15762–15772 (2024) 4
work page 2024
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4195–4205 (2023) 4
work page 2023
-
[32]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
arXiv preprint arXiv:2404.13686 (2024) 3
Ren, Y., Xia, X., Lu, Y., Zhang, J., Wu, J., Xie, P., Wang, X., Xiao, X.: Hyper- sd: Trajectory segmented consistency model for efficient image synthesis. arXiv preprint arXiv:2404.13686 (2024) 1, 10, 23
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 1
work page 2022
-
[35]
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, Oc- tober 5-9, 2015, proceedings, part III 18. pp. 234–241. Springer (2015) 4
work page 2015
-
[36]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022) 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
In: SIGGRAPH Asia 2024 Conference Papers
Sauer, A., Boesel, F., Dockhorn, T., Blattmann, A., Esser, P., Rombach, R.: Fast high-resolution image synthesis with latent adversarial diffusion distillation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024) 1, 3, 4, 10, 23
work page 2024
-
[38]
In: European Conference on Computer Vision
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distilla- tion. In: European Conference on Computer Vision. pp. 87–103. Springer (2024) 1, 4
work page 2024
-
[39]
Advances in neural information processing systems35, 25278–25294 (2022) 10, 11, 23
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022) 10, 11, 23
work page 2022
-
[40]
Selvaraju, P., Ding, T., Chen, T., Zharkov, I., Liang, L.: Fora: Fast-forward caching in diffusion transformer acceleration. arXiv preprint arXiv:2407.01425 (2024) 4
-
[41]
In: Interna- tional Conference on Machine Learning
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: Interna- tional Conference on Machine Learning. pp. 32211–32252. PMLR (2023) 1, 3
work page 2023
-
[42]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 5
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[43]
Advances in neural information processing systems36, 49659–49678 (2023) 10 18 H
Sun, K., Pan, J., Ge, Y., Li, H., Duan, H., Wu, X., Zhang, R., Zhou, A., Qin, Z., Wang, Y., et al.: Journeydb: A benchmark for generative image understanding. Advances in neural information processing systems36, 49659–49678 (2023) 10 18 H. Li et al
work page 2023
-
[44]
Advances in neural information processing systems37, 83951–84009 (2024) 10, 23
Wang, F.Y., Huang, Z., Bergman, A., Shen, D., Gao, P., Lingelbach, M., Sun, K., Bian, W., Song, G., Liu, Y., et al.: Phased consistency models. Advances in neural information processing systems37, 83951–84009 (2024) 10, 23
work page 2024
-
[45]
Advances in neural information processing systems36, 8406–8441 (2023) 4
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023) 4
work page 2023
-
[46]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023) 10, 11, 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Advances in Neural Information Processing Systems36, 15903–15935 (2023) 10, 11, 23
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023) 10, 11, 23
work page 2023
-
[49]
Advances in neural information processing systems37, 47455–47487 (2024) 1, 2, 4, 5, 7, 10
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024) 1, 2, 4, 5, 7, 10
work page 2024
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6613–6623 (2024) 1, 2, 4, 11
work page 2024
-
[51]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 11
work page 2018
-
[52]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Zheng, K., Wang, Y., Ma, Q., Chen, H., Zhang, J., Balaji, Y., Chen, J., Liu, M.Y., Zhu, J., Zhang, Q.: Large scale diffusion distillation via score-regularized continuous-time consistency. arXiv preprint arXiv:2510.08431 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
arXiv preprint arXiv:2507.02860 (2025) 4 1.x-Distill 19 Appendix Table of Contents 1 Introduction
Zhou, X., Liang, D., Chen, K., Feng, T., Chen, X., Lin, H., Ding, Y., Tan, F., Zhao, H., Bai, X.: Less is enough: Training-free video diffusion acceleration via runtime-adaptive caching. arXiv preprint arXiv:2507.02860 (2025) 4 1.x-Distill 19 Appendix Table of Contents 1 Introduction................................................... 1 2 Related Work .......
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.