Recognition: no theorem link
FLAME: Condensing Ensemble Diversity into a Single Network for Efficient Sequential Recommendation
Pith reviewed 2026-05-13 17:24 UTC · model grok-4.3
The pith
FLAME condenses ensemble diversity into one network for sequential recommendation with no inference overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FLAME simulates exponential diversity using only two networks via modular ensemble. By decomposing each network into sub-modules and dynamically combining them, FLAME generates a rich space of diverse representation patterns. To stabilize this process, one network is pretrained and frozen to serve as a semantic anchor and guided mutual learning aligns the diverse representations into the space of the remaining learnable network, ensuring robust optimization. Consequently at inference FLAME utilizes only the learnable network, achieving ensemble-level performance with zero overhead compared to a single network.
What carries the argument
Modular ensemble, which decomposes each network into sub-modules such as layers or blocks and dynamically recombines them during training to create a large space of diverse representation patterns, guided by a frozen semantic anchor and mutual learning alignment.
If this is right
- FLAME matches or exceeds the accuracy of full ensembles while using only one network at inference time.
- Training converges up to 7.69 times faster than training multiple independent models.
- Performance improves by up to 9.70 percent in NDCG@20 across six public datasets.
- The approach avoids the instability that normally arises from noisy mutual supervision among many randomly initialized networks.
Where Pith is reading between the lines
- The same modular decomposition and anchor mechanism could be tested on non-sequential recommendation tasks such as session-based or graph-based recommenders to check whether the efficiency gain generalizes.
- If the frozen anchor can be replaced by a much smaller pretrained model, training cost could drop further while preserving the diversity transfer.
- Large-scale production systems might adopt this pattern to obtain ensemble-level robustness without multiplying serving latency or memory footprint.
Load-bearing premise
Decomposing networks into sub-modules and dynamically combining them together with a frozen semantic anchor and guided mutual learning can reliably transfer the full diversity of an exponential ensemble into one network without loss of the performance gains.
What would settle it
Train a full ensemble from scratch on the same six datasets, then compare its NDCG@20 against the single learnable network produced by FLAME; if the single network falls short by more than the reported 9.70 percent margin the condensation claim is falsified.
Figures




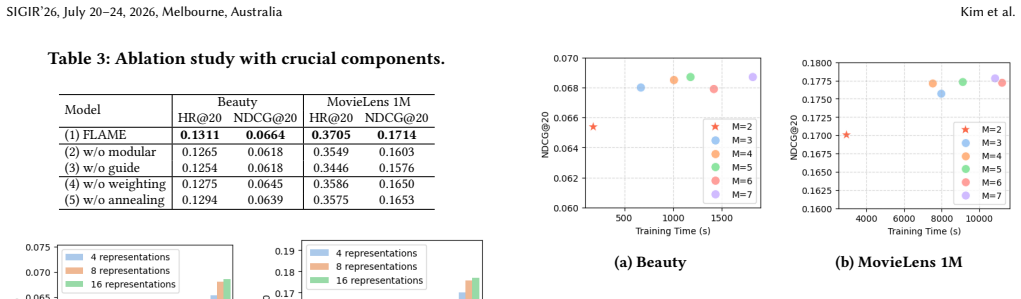



read the original abstract
Sequential recommendation requires capturing diverse user behaviors, which a single network often fails to capture. While ensemble methods mitigate this by leveraging multiple networks, training them all from scratch leads to high computational cost and instability from noisy mutual supervision. We propose {\bf F}rozen and {\bf L}earnable networks with {\bf A}ligned {\bf M}odular {\bf E}nsemble ({\bf FLAME}), a novel framework that condenses ensemble-level diversity into a single network for efficient sequential recommendation. During training, FLAME simulates exponential diversity using only two networks via {\it modular ensemble}. By decomposing each network into sub-modules (e.g., layers or blocks) and dynamically combining them, FLAME generates a rich space of diverse representation patterns. To stabilize this process, we pretrain and freeze one network to serve as a semantic anchor and employ {\it guided mutual learning}. This aligns the diverse representations into the space of the remaining learnable network, ensuring robust optimization. Consequently, at inference, FLAME utilizes only the learnable network, achieving ensemble-level performance with zero overhead compared to a single network. Experiments on six datasets show that FLAME outperforms state-of-the-art baselines, achieving up to 7.69$\times$ faster convergence and 9.70\% improvement in NDCG@20. We provide the source code of FLAME at https://github.com/woo-joo/FLAME_SIGIR26.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FLAME, a framework for sequential recommendation that condenses ensemble-level diversity into a single network. It employs a modular ensemble by decomposing networks into sub-modules and dynamically combining them during training using only two networks: one pretrained and frozen as a semantic anchor, and one learnable network aligned via guided mutual learning. At inference, only the learnable network is used, claiming ensemble performance with zero overhead. Experiments across six datasets report up to 9.70% NDCG@20 gains and 7.69× faster convergence over state-of-the-art baselines, with code released.
Significance. If the central claim holds, FLAME would represent a meaningful efficiency advance for sequential recommendation systems by delivering ensemble benefits at single-network inference cost. The modular decomposition and guided alignment approach, combined with open-sourced code, supports reproducibility and could influence practical deployments where training stability and inference speed matter.
major comments (2)
- [§3.2] §3.2 (Modular Ensemble): The claim that dynamic sub-module combinations generate an exponential space of diverse representations is load-bearing for the inference result, yet the paper provides no quantitative metric (e.g., representation variance or pairwise disagreement) showing that this diversity survives the subsequent guided mutual learning step. Without such evidence, the reported gains could arise from the frozen anchor alone rather than successful condensation.
- [§4] §4 (Experiments): The abstract and results claim consistent outperformance and faster convergence, but no ablation isolates the contribution of guided mutual learning versus the frozen anchor, no error bars or statistical significance tests are reported, and baseline implementations lack detail on hyperparameter matching. These omissions make it impossible to verify that the single-network inference claim is supported rather than an artifact of experimental setup.
minor comments (2)
- The abstract states 'up to 7.69× faster convergence' without specifying the exact baseline or convergence criterion used for the multiplier.
- Notation for sub-module decomposition (e.g., how layers or blocks are indexed for dynamic combination) is introduced without a formal definition or diagram in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each of the major comments below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Modular Ensemble): The claim that dynamic sub-module combinations generate an exponential space of diverse representations is load-bearing for the inference result, yet the paper provides no quantitative metric (e.g., representation variance or pairwise disagreement) showing that this diversity survives the subsequent guided mutual learning step. Without such evidence, the reported gains could arise from the frozen anchor alone rather than successful condensation.
Authors: We appreciate this observation. The modular ensemble is intended to generate diverse representations through dynamic sub-module combinations, with guided mutual learning serving to align these representations into the learnable network's space without collapsing the diversity. Although the superior performance compared to single-network methods supports the effectiveness of this condensation, we agree that direct metrics would provide stronger validation. In the revised manuscript, we will include quantitative evaluations, such as representation variance and average pairwise disagreement, to demonstrate that diversity is preserved post-alignment. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results claim consistent outperformance and faster convergence, but no ablation isolates the contribution of guided mutual learning versus the frozen anchor, no error bars or statistical significance tests are reported, and baseline implementations lack detail on hyperparameter matching. These omissions make it impossible to verify that the single-network inference claim is supported rather than an artifact of experimental setup.
Authors: We acknowledge the validity of these concerns regarding experimental rigor. To address them, we will expand the experiments section in the revision to include a dedicated ablation study that isolates the impact of guided mutual learning (comparing against the frozen anchor alone), report results with error bars from multiple random seeds along with statistical significance tests (e.g., paired t-tests), and provide comprehensive details on baseline implementations, including hyperparameter search procedures to confirm fair matching. revision: yes
Circularity Check
No circularity: concrete training procedure with independent components
full rationale
The paper presents FLAME as an explicit algorithmic pipeline: modular decomposition of two networks into sub-modules, dynamic combination to simulate ensemble diversity during training, pretraining and freezing one network as semantic anchor, and guided mutual learning to align representations into the learnable network. The inference claim (ensemble-level performance using only the learnable network with zero overhead) follows directly from this described procedure rather than any equation or definition that reduces the target performance metric to a fitted parameter or self-referential quantity. No equations appear in the provided text, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The derivation chain is therefore self-contained and externally falsifiable via the released code and dataset experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Leo Breiman. 1996. Bagging predictors.Machine learning24 (1996), 123–140
work page 1996
-
[4]
Tong Chen, Hongzhi Yin, Quoc Viet Hung Nguyen, Wen-Chih Peng, Xue Li, and Xiaofang Zhou. 2020. Sequence-aware factorization machines for temporal predictive analytics. In2020 IEEE 36th international conference on data engineering (ICDE). IEEE, 1405–1416
work page 2020
-
[5]
Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. 2022. Intent contrastive learning for sequential recommendation. InProceedings of the ACM web conference 2022. 2172–2182
work page 2022
-
[6]
Liu Chong, Xiaoyang Liu, Rongqin Zheng, Lixin Zhang, Xiaobo Liang, Juntao Li, Lijun Wu, Min Zhang, and Leyu Lin. 2023. Ct4rec: simple yet effective consistency training for sequential recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3901–3913
work page 2023
-
[7]
Yizhou Dang, Enneng Yang, Guibing Guo, Linying Jiang, Xingwei Wang, Xiaoxiao Xu, Qinghui Sun, and Hong Liu. 2023. Uniform sequence better: Time interval aware data augmentation for sequential recommendation. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 4225–4232
work page 2023
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
work page 2019
-
[9]
Thomas G Dietterich. 2000. Ensemble methods in machine learning. InInterna- tional workshop on multiple classifier systems. Springer, 1–15
work page 2000
-
[10]
Alexey Dosovitskiy and Thomas Brox. 2016. Inverting visual representations with convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition. 4829–4837
work page 2016
-
[11]
Hanwen Du, Huanhuan Yuan, Pengpeng Zhao, Fuzhen Zhuang, Guanfeng Liu, Lei Zhao, Yanchi Liu, and Victor S Sheng. 2023. Ensemble modeling with contrastive knowledge distillation for sequential recommendation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 58–67
work page 2023
-
[12]
Yingpeng Du, Hongzhi Liu, Yang Song, Zekai Wang, and Zhonghai Wu. 2023. Sequential ensemble learning for next item recommendation.Knowledge-Based Systems277 (2023), 110809
work page 2023
- [13]
-
[14]
Yoav Freund and Robert E Schapire. 1997. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences55, 1 (1997), 119–139
work page 1997
-
[15]
Tommaso Furlanello, Zachary Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. 2018. Born again neural networks. InInternational conference on machine learning. PMLR, 1607–1616
work page 2018
-
[16]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. 2018. Co-teaching: Robust training of deep neural net- works with extremely noisy labels.Advances in neural information processing systems31 (2018)
work page 2018
-
[17]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
work page 2015
-
[18]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[19]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
SeongKu Kang, Dongha Lee, Wonbin Kweon, Junyoung Hwang, and Hwanjo Yu
-
[21]
InProceedings of the ACM Web Conference 2022
Consensus learning from heterogeneous objectives for one-class collabora- tive filtering. InProceedings of the ACM Web Conference 2022. 1965–1976
work page 2022
-
[22]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
work page 2018
-
[23]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [24]
-
[25]
Wonbin Kweon, SeongKu Kang, and Hwanjo Yu. 2021. Bidirectional distillation for top-K recommender system. InProceedings of the Web Conference 2021. 3861– 3871
work page 2021
-
[26]
Xuewei Li, Aitong Sun, Mankun Zhao, Jian Yu, Kun Zhu, Di Jin, Mei Yu, and Ruiguo Yu. 2023. Multi-intention oriented contrastive learning for sequential recommendation. InProceedings of the sixteenth ACM international conference on web search and data mining. 411–419
work page 2023
- [27]
-
[28]
Ling Liu, Wenqi Wei, Ka-Ho Chow, Margaret Loper, Emre Gursoy, Stacey Truex, and Yanzhao Wu. 2019. Deep neural network ensembles against deception: Ensemble diversity, accuracy and robustness. In2019 IEEE 16th international conference on mobile ad hoc and sensor systems (MASS). IEEE, 274–282
work page 2019
-
[29]
Mingrui Liu, Sixiao Zhang, and Cheng Long. 2025. Facet-Aware Multi-Head Mixture-of-Experts Model for Sequential Recommendation. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 127–135
work page 2025
- [30]
- [31]
-
[32]
Jianxin Ma, Chang Zhou, Hongxia Yang, Peng Cui, Xin Wang, and Wenwu Zhu
-
[33]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Disentangled self-supervision in sequential recommenders. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 483–491
-
[34]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[35]
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[36]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [37]
- [38]
-
[39]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Junhua Fang, Fuzhen Zhuang, Guanfeng Liu, Yanchi Liu, and Victor Sheng. 2023. Meta-optimized contrastive learning for sequential recommendation. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 89–98. FLAME: Condensing Ensemble Diversity into a Sin...
work page 2023
-
[40]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Guanfeng Liu, Fuzhen Zhuang, and Victor S Sheng. 2024. Intent contrastive learning with cross subsequences for sequential recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 548–556
work page 2024
-
[41]
Ruihong Qiu, Zi Huang, Jingjing Li, and Hongzhi Yin. 2020. Exploiting cross- session information for session-based recommendation with graph neural net- works.ACM Transactions on Information Systems (TOIS)38, 3 (2020), 1–23
work page 2020
-
[42]
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive learning for representation degeneration problem in sequential recommendation. InProceedings of the fifteenth ACM international conference on web search and data mining. 813–823
work page 2022
-
[43]
Ruihong Qiu, Jingjing Li, Zi Huang, and Hongzhi Yin. 2019. Rethinking the item order in session-based recommendation with graph neural networks. In Proceedings of the 28th ACM international conference on information and knowledge management. 579–588
work page 2019
-
[44]
Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factor- izing personalized markov chains for next-basket recommendation. InProceedings of the 19th international conference on World wide web. 811–820
work page 2010
-
[45]
Guocong Song and Wei Chai. 2018. Collaborative learning for deep neural networks.Advances in neural information processing systems31 (2018)
work page 2018
-
[46]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[47]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[48]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
work page 2018
-
[49]
A Vaswani. 2017. Attention is all you need.Advances in Neural Information Processing Systems(2017)
work page 2017
-
[50]
Pengfei Wang, Jiafeng Guo, Yanyan Lan, Jun Xu, Shengxian Wan, and Xueqi Cheng. 2015. Learning hierarchical representation model for nextbasket rec- ommendation. InProceedings of the 38th International ACM SIGIR conference on Research and Development in Information Retrieval. 403–412
work page 2015
- [51]
-
[52]
Wuhong Wang, Jianhui Ma, Yuren Zhang, Kai Zhang, Junzhe Jiang, Yihui Yang, Yacong Zhou, and Zheng Zhang. 2025. Intent Oriented Contrastive Learning for Sequential Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12748–12756
work page 2025
-
[53]
Zhikai Wang, Yanyan Shen, Zexi Zhang, Li He, Yichun Li, Hao Gu, and Yinghua Zhang. 2024. Relative Contrastive Learning for Sequential Recommendation with Similarity-based Positive Sample Selection. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2493–2502
work page 2024
-
[54]
Zihan Wei, Ning Wu, Fengxia Li, Ke Wang, and Wei Zhang. 2023. MoCo4SRec: A momentum contrastive learning framework for sequential recommendation. Expert Systems with Applications223 (2023), 119911
work page 2023
-
[55]
Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019. Session-based recommendation with graph neural networks. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 346–353
work page 2019
-
[56]
Pengtao Xie and Xuefeng Du. 2022. Performance-aware mutual knowledge dis- tillation for improving neural architecture search. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11922–11932
work page 2022
-
[57]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
work page 2022
- [58]
-
[59]
Junjie Zhang, Ruobing Xie, Hongyu Lu, Wenqi Sun, Xin Zhao, Zhanhui Kang, et al
-
[60]
Frequency-Augmented Mixture-of-Heterogeneous-Experts Framework for Sequential Recommendation. InTHE WEB CONFERENCE 2025
work page 2025
-
[61]
Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. 2018. Deep mutual learning. InProceedings of the IEEE conference on computer vision and pattern recognition. 4320–4328
work page 2018
-
[62]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for se- quential recommendation with mutual information maximization. InProceedings of the 29th ACM international conference on information & knowledge management. 1893–1902
work page 2020
-
[63]
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Filter-enhanced MLP is all you need for sequential recommendation. InProceedings of the ACM web conference 2022. 2388–2399
work page 2022
-
[64]
2025.Ensemble methods: foundations and algorithms
Zhi-Hua Zhou. 2025.Ensemble methods: foundations and algorithms. CRC press
work page 2025
-
[65]
Jieming Zhu, Jinyang Liu, Weiqi Li, Jincai Lai, Xiuqiang He, Liang Chen, and Zibin Zheng. 2020. Ensembled CTR prediction via knowledge distillation. In Proceedings of the 29th ACM international conference on information & knowledge management. 2941–2958
work page 2020
-
[66]
Xiatian Zhu, Shaogang Gong, et al. 2018. Knowledge distillation by on-the-fly native ensemble.Advances in neural information processing systems31 (2018)
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.