Recognition: no theorem link
FactReview: Evidence-Grounded Reviews with Literature Positioning and Execution-Based Claim Verification
Pith reviewed 2026-05-13 17:28 UTC · model grok-4.3
The pith
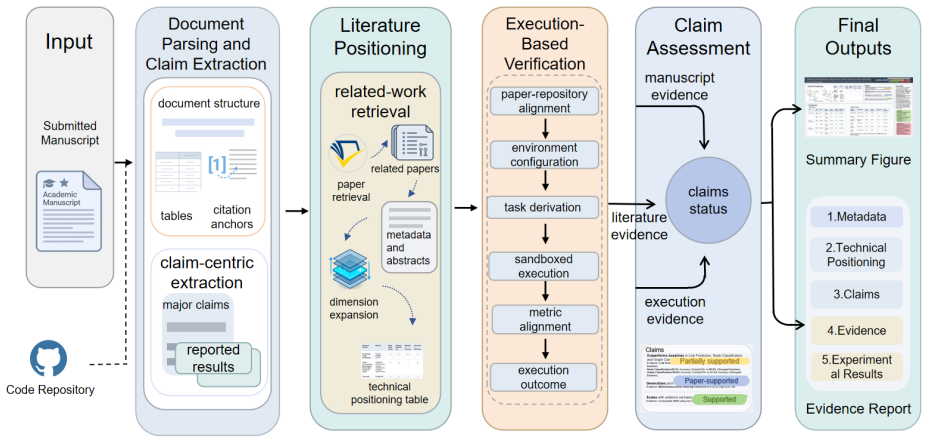
FactReview extracts claims from papers, retrieves related work, and runs released code to label each claim with evidence support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FactReview identifies major claims and reported results, retrieves nearby work to clarify the paper's technical position, and executes the released repository under bounded budgets to test central empirical claims, then assigns each claim one of five labels based on the collected evidence, as shown when reproducing CompGCN results that match on specific tasks but only partially sustain the paper's broader performance claim across tasks.
What carries the argument
The evidence-grounded pipeline of LLM claim extraction, literature retrieval for positioning, and bounded code execution for verification.
If this is right
- Papers reporting broad performance claims can receive only partial support when code execution shows narrower results.
- Reviewers obtain standardized evidence labels and a concise report rather than narrative-only comments.
- Reproducibility becomes directly testable for any paper that releases code under the system's execution budget.
- AI assistance in review focuses on gathering and organizing external evidence instead of generating final verdicts.
Where Pith is reading between the lines
- Widespread adoption would incentivize authors to release cleaner, more runnable code repositories.
- The approach could be extended to flag papers whose claims rely on unreleased or non-executable components.
- Aggregating labels across many submissions might reveal systemic patterns in how empirical claims are supported.
Load-bearing premise
That LLM-based claim extraction and literature retrieval are accurate enough and that bounded code execution can reliably test central empirical claims without extensive manual setup.
What would settle it
A comparison of FactReview labels against independent human reviewer judgments on claim support across a set of papers that release runnable code.
Figures

read the original abstract
Peer review in machine learning is under growing pressure from rising submission volume and limited reviewer time. Most LLM-based reviewing systems read only the manuscript and generate comments from the paper's own narrative. This makes their outputs sensitive to presentation quality and leaves them weak when the evidence needed for review lies in related work or released code. We present FactReview, an evidence-grounded reviewing system that combines claim extraction, literature positioning, and execution-based claim verification. Given a submission, FactReview identifies major claims and reported results, retrieves nearby work to clarify the paper's technical position, and, when code is available, executes the released repository under bounded budgets to test central empirical claims. It then produces a concise review and an evidence report that assigns each major claim one of five labels: Supported, Supported by the paper, Partially supported, In conflict, or Inconclusive. In a case study on CompGCN, FactReview reproduces results that closely match those reported for link prediction and node classification, yet also shows that the paper's broader performance claim across tasks is not fully sustained: on MUTAG graph classification, the reproduced result is 88.4%, whereas the strongest baseline reported in the paper remains 92.6%. The claim is therefore only partially supported. More broadly, this case suggests that AI is most useful in peer review not as a final decision-maker, but as a tool for gathering evidence and helping reviewers produce more evidence-grounded assessments. The code is public at https://github.com/DEFENSE-SEU/Review-Assistant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FactReview, an LLM-based reviewing system that extracts major claims and reported results from a submission, retrieves nearby literature to position the work technically, and executes released code under bounded budgets to verify empirical claims. Each claim receives one of five labels (Supported, Supported by the paper, Partially supported, In conflict, or Inconclusive). A case study on CompGCN shows close reproduction of link-prediction and node-classification results, but demonstrates that the paper's broader performance claim is only partially supported because the reproduced MUTAG accuracy (88.4%) falls short of the strongest baseline reported in the original paper (92.6%).
Significance. If the execution-based verification component can be shown to operate reliably with minimal manual intervention, FactReview would offer a concrete advance over narrative-only LLM reviewers by grounding assessments in external literature and runnable code. The public code release and the concrete reproduction numbers in the CompGCN case study are positive steps toward reproducibility.
major comments (2)
- [CompGCN case study] CompGCN case study: the manuscript reports a reproduced MUTAG accuracy of 88.4% versus the paper's baseline of 92.6% but provides no quantitative specification of the bounded budget (runtime limit, GPU hours, hardware), dependency-resolution procedure, seed handling, or hyperparameter defaults actually used. This information is load-bearing for the central claim that execution-based verification works reliably under bounded budgets without extensive manual setup.
- [System description] Claim-extraction and labeling pipeline: no quantitative evaluation (precision, recall, or inter-annotator agreement) is reported for the LLM-based extraction of major claims or for the subsequent mapping to the five support labels. Because the entire evidence report rests on these extracted claims, the absence of such metrics leaves the reliability of the system unquantified.
minor comments (1)
- [Abstract] The GitHub link is mentioned only in the abstract; it should also appear in the main text or a dedicated reproducibility section.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important aspects of reproducibility and evaluation that we address below. We have revised the manuscript to incorporate additional details on the execution environment and have expanded the discussion of the claim-extraction pipeline's limitations.
read point-by-point responses
-
Referee: [CompGCN case study] CompGCN case study: the manuscript reports a reproduced MUTAG accuracy of 88.4% versus the paper's baseline of 92.6% but provides no quantitative specification of the bounded budget (runtime limit, GPU hours, hardware), dependency-resolution procedure, seed handling, or hyperparameter defaults actually used. This information is load-bearing for the central claim that execution-based verification works reliably under bounded budgets without extensive manual setup.
Authors: We agree that these details are essential for substantiating the bounded-budget claim. In the revised manuscript we have inserted a new paragraph in Section 4.2 that specifies the execution constraints: a hard runtime limit of 30 minutes per experiment on a single NVIDIA A100 GPU (approximately 2 GPU-hours total across all runs), dependency resolution via the repository's requirements.txt with no manual package edits, random seeds fixed at 42, and all hyperparameters set to the exact defaults reported in the original CompGCN paper. These additions make the reproduction protocol fully transparent and support the assertion of minimal manual intervention. revision: yes
-
Referee: [System description] Claim-extraction and labeling pipeline: no quantitative evaluation (precision, recall, or inter-annotator agreement) is reported for the LLM-based extraction of major claims or for the subsequent mapping to the five support labels. Because the entire evidence report rests on these extracted claims, the absence of such metrics leaves the reliability of the system unquantified.
Authors: We recognize that quantitative metrics would provide a stronger guarantee of pipeline reliability. The present manuscript prioritizes an end-to-end demonstration via the CompGCN case study rather than a separate annotation study. In the revision we have added a paragraph in the Limitations section that explicitly states the absence of precision/recall or IAA figures, describes the prompt-based extraction procedure in more detail, and outlines a planned follow-up human evaluation. We maintain that the case-study outcomes already offer qualitative evidence of utility, but we accept that a dedicated quantitative assessment remains an open improvement. revision: partial
Circularity Check
No circularity: FactReview pipeline relies on independent code execution and external retrieval
full rationale
The paper describes a procedural system for claim extraction, literature positioning via retrieval, and execution-based verification under bounded budgets, demonstrated via a CompGCN case study that reproduces results from released code. No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. The verification step uses actual code runs to label claims (e.g., partial support on MUTAG), providing external evidence rather than reducing outputs to the system's own inputs or prior self-citations. The approach is self-contained as a tool description without load-bearing self-citation chains or ansatzes.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption LLMs can accurately extract major claims from manuscripts
- domain assumption Literature retrieval accurately clarifies the paper's technical position
- domain assumption Bounded code execution can test central empirical claims
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, J. Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’Arcy, David Wadden, Matt Latzke, Minyang Tian, Pan Ji, Shengyan Liu, Hao Tong, Bohao Wu, Yanyu Xiong, Luke S. Zettlemoyer, Graham Neubig, Dan Weld, Doug Downey, Wen tau Yih, Pang Wei Koh, and Hanna Hajishirzi. Openscholar: Synthesiz...
-
[2]
Marg: Multi-agent review generation for scientific papers.ArXiv, abs/2401.04259,
Mike D’Arcy, Tom Hope, Larry Birnbaum, and Doug Downey. Marg: Multi-agent review generation for scientific papers.ArXiv, abs/2401.04259,
-
[3]
ToolRosella: Translating Code Repositories into Standardized Tools for Scientific Agents
URLhttps://api.semanticscholar.org/CorpusID:19990980. Shimin Di, Xujie Yuan, Hanghui Guo, Chaoqian Ouyang, Zhangze Chen, Ling Yue, Libin Zheng, Jia Zhu, Shaowu Pan, Jian Yin, et al. Toolrosetta: Bridging open-source repositories and large language model agents through automated tool standardization.arXiv preprint arXiv:2603.09290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Truong, Weixin Liang, Fan-Yun Sun, and Nick Haber
Tianyu Hua, Harper Hua, Violet Xiang, Benjamin Klieger, Sang T. Truong, Weixin Liang, Fan-Yun Sun, and Nick Haber. Researchcodebench: Benchmarking llms on implementing novel machine learning research code.ArXiv, abs/2506.02314,
-
[5]
Jakub L’ala, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G. Rodriques, and Andrew D. White. Paperqa: Retrieval-augmented generative agent for scientific research.ArXiv, abs/2312.07559,
-
[6]
Llm-reval: Can we trust llm reviewers yet?ArXiv, abs/2510.12367,
Rui Li, Jia-Chen Gu, Po-Nien Kung, Heming Xia, Junfeng Liu, Xiangwen Kong, Zhifang Sui, and Nanyun Peng. Llm-reval: Can we trust llm reviewers yet?ArXiv, abs/2510.12367,
-
[7]
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Ding, Xinyu Yang, Kailas Vodrahalli, Siyu He, D. Smith, Yian Yin, Daniel A. McFarland, and James Zou. Can large language models provide useful feedback on research papers? a large-scale empirical analysis.ArXiv, abs/2310.01783,
-
[8]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, R. Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.ArXiv, abs/2408.06292,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Official release page. Chaoqian Ouyang, Ling Yue, Shimin Di, Libin Zheng, Linan Yue, Shaowu Pan, Jian Yin, and Min-Ling Zhang. Code2mcp: Transforming code repositories into mcp services.arXiv preprint arXiv:2509.05941,
-
[10]
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, V. Lariviere, A. Beygelzimer, Florence d’Alche Buc, E. Fox, and H. Larochelle. Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program).J. Mach. Learn. Res., 22:164:1–164:20,
work page 2019
-
[11]
Edward Raff. A step toward quantifying independently reproducible machine learning research.ArXiv, abs/1909.06674,
-
[12]
Larochelle, Laurent Charlin, and Christopher Pal
Gaurav Sahu, H. Larochelle, Laurent Charlin, and Christopher Pal. Reviewertoo: Should ai join the program committee? a look at the future of peer review.ArXiv, abs/2510.08867,
-
[13]
Paperbench: Evaluating ai’s ability to replicate ai research, 2025
Giulio Starace, Oliver Jaffe, Dane Sherburn, J. Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, E. Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paper- bench: Evaluating ai’s ability to replicate ai research.ArXiv, abs/2504.01848,
-
[14]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, A. Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science.ArXiv, abs/2211.09085,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Association for Computational Linguistics. doi: 10.18653/v1/W15-4007. URLhttps://aclanthology.org/W15-4007/. Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, and Partha Talukdar. Composition-based multi-relational graph convolutional networks.arXiv preprint arXiv:1911.03082,
-
[16]
Fact or fiction: Verifying scientific claims.ArXiv, abs/2004.14974,
David Wadden, Kyle Lo, Lucy Lu Wang, Shanchuan Lin, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims.ArXiv, abs/2004.14974,
-
[17]
doi: 10.59717/j.xinn-inform.2026.100030
ISSN 3105-8515. doi: 10.59717/j.xinn-inform.2026.100030. URL https://www.the-innovation.org/informatics/article/id/69891cb8cf3295331f847960. Siyuan Wang, James R. Foulds, Md. Osman Gani, and Shimei Pan. Llm-based corroborating and refuting evidence retrieval for scientific claim verification.ArXiv, abs/2503.07937,
-
[18]
11 Rui Yu, Tianyi Wang, Ruixia Liu, and Yinglong Wang. Pt-rag: Structure-fidelity retrieval-augmented generation for academic papers.arXiv preprint arXiv:2602.13647,
- [19]
-
[20]
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
available at Research Square. Xuanle Zhao, Zilin Sang, Yuxuan Li, Qi Shi, Weilun Zhao, Shuo Wang, Duzhen Zhang, Xu Han, Zhiyuan Liu, and Maosong Sun. Autoreproduce: Automatic ai experiment reproduction with paper lineage.ArXiv, abs/2505.20662,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
When your reviewer is an llm: Biases, divergence, and prompt injection risks in peer review, 2025a
Changjia Zhu, Junjie Xiong, Renkai Ma, Zhicong Lu, Yao Liu, and Lingyao Li. When your reviewer is an llm: Biases, divergence, and prompt injection risks in peer review, 2025a. URL https://arxiv.org/abs/ 2509.09912. Minjun Zhu, Yixuan Weng, Linyi Yang, and Yue Zhang. DeepReview: Improving LLM-based paper review with human-like deep thinking process. In Wan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.