Recognition: no theorem link
LAA-X: Unified Localized Artifact Attention for Quality-Agnostic and Generalizable Face Forgery Detection
Pith reviewed 2026-05-13 17:18 UTC · model grok-4.3
The pith
LAA-X uses a multi-task framework to explicitly direct attention to localized artifact-prone regions in faces, enabling detection of high-quality forgeries and generalization to unseen manipulations when trained only on real and pseudo-fake
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LAA-X shows that an explicit attention strategy grounded in multi-task learning and blending-based data synthesis allows a detector to focus on localized artifact-prone regions. Trained solely on real images and pseudo-fakes, the resulting models compete with state-of-the-art methods on multiple benchmarks for both quality-agnostic and generalizable face forgery detection.
What carries the argument
Explicit Localized Artifact Attention implemented as auxiliary tasks within a multi-task learning framework, reinforced by blending-based synthesis of pseudo-fake samples.
Load-bearing premise
The auxiliary tasks will reliably steer attention to the actual regions containing forgery artifacts, and the blending synthesis will generate pseudo-fakes that closely enough resemble real high-quality forgeries.
What would settle it
A test set of high-quality forgeries produced by manipulation methods outside the blending synthesis family, where the LAA-X models fall below current top detection accuracy.
Figures







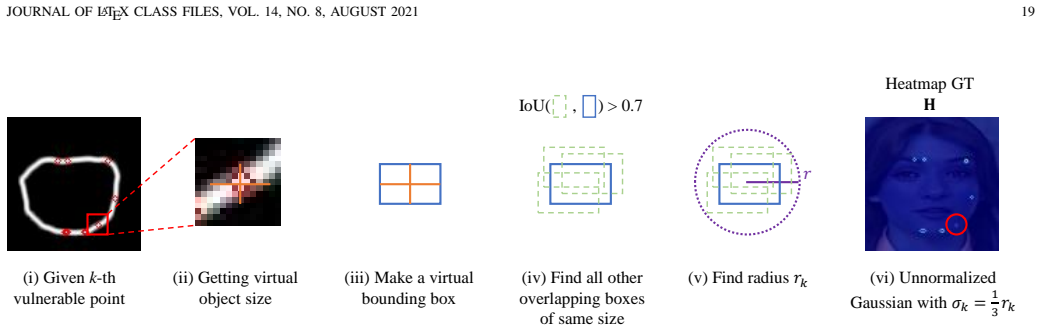
read the original abstract
In this paper, we propose Localized Artifact Attention X (LAA-X), a novel deepfake detection framework that is both robust to high-quality forgeries and capable of generalizing to unseen manipulations. Existing approaches typically rely on binary classifiers coupled with implicit attention mechanisms, which often fail to generalize beyond known manipulations. In contrast, LAA-X introduces an explicit attention strategy based on a multi-task learning framework combined with blending-based data synthesis. Auxiliary tasks are designed to guide the model toward localized, artifact-prone (i.e., vulnerable) regions. The proposed framework is compatible with both CNN and transformer backbones, resulting in two different versions, namely, LAA-Net and LAA-Former, respectively. Despite being trained only on real and pseudo-fake samples, LAA-X competes with state-of-the-art methods across multiple benchmarks. Code and pre-trained weights for LAA-Net\footnote{https://github.com/10Ring/LAA-Net} and LAA-Former\footnote{https://github.com/10Ring/LAA-Former} are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
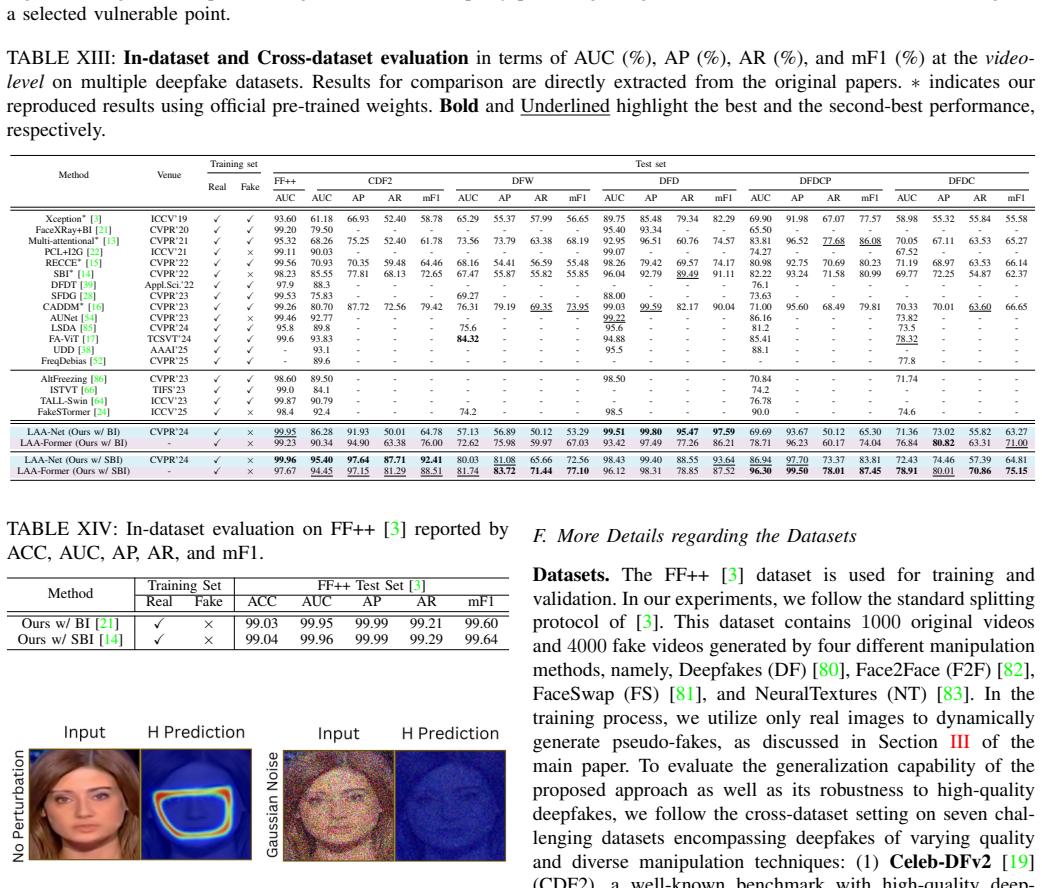
Summary. The paper proposes LAA-X, a unified deepfake detection framework that employs explicit localized artifact attention through a multi-task learning setup combined with blending-based synthesis to generate pseudo-fake training samples. It introduces two backbone variants (LAA-Net for CNNs and LAA-Former for transformers) and claims that training solely on real and pseudo-fake images yields competitive performance with state-of-the-art methods on multiple benchmarks while improving robustness to high-quality forgeries and generalization to unseen manipulations.
Significance. If the empirical results hold, the work would be significant for addressing data scarcity in forgery detection by showing that blending-based pseudo-fakes plus auxiliary localization tasks can produce generalizable attention maps. The public release of code and pre-trained weights for both variants is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim of competitive benchmark performance and generalization to unseen manipulations is asserted without any quantitative metrics, ablation studies, error bars, or description of the test protocol for unseen manipulations, leaving the central empirical claim unsupported in the provided text.
- [Method] Method (multi-task framework): the assumption that auxiliary tasks will reliably surface the same vulnerable regions as real high-quality forgeries is load-bearing, yet blending synthesis (alpha or Poisson) primarily introduces low-level boundary discontinuities rather than the frequency or identity-inconsistency artifacts of methods such as FaceSwap; no evidence is shown that the learned attention transfers when the training distribution is replaced by real forged samples.
minor comments (2)
- Clarify the exact formulation of the multi-task loss (including balancing weights) and whether they are tuned on a validation set or held fixed.
- Specify the precise auxiliary heads (e.g., pixel-wise localization, region classification) and their individual loss functions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of results and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of competitive benchmark performance and generalization to unseen manipulations is asserted without any quantitative metrics, ablation studies, error bars, or description of the test protocol for unseen manipulations, leaving the central empirical claim unsupported in the provided text.
Authors: We agree that the abstract should be more self-contained. In the revised version we have added specific quantitative results (AUC on FF++, Celeb-DF, and cross-manipulation settings) together with a concise description of the unseen-manipulation evaluation protocol. Full ablations, standard deviations across runs, and detailed protocols remain in the experimental section. revision: yes
-
Referee: [Method] Method (multi-task framework): the assumption that auxiliary tasks will reliably surface the same vulnerable regions as real high-quality forgeries is load-bearing, yet blending synthesis (alpha or Poisson) primarily introduces low-level boundary discontinuities rather than the frequency or identity-inconsistency artifacts of methods such as FaceSwap; no evidence is shown that the learned attention transfers when the training distribution is replaced by real forged samples.
Authors: We acknowledge that blending synthesis primarily produces boundary artifacts. Nevertheless, the auxiliary localization tasks are intended to direct attention toward a broader set of vulnerable regions. The manuscript already includes qualitative attention-map comparisons (Figure 5) on both pseudo-fakes and real FaceSwap samples that show substantial spatial overlap. Competitive performance on real high-quality forgeries (Tables 2–3) provides indirect support for transfer. To address the referee’s request for direct evidence, we have added a quantitative attention-similarity analysis between models trained on pseudo-fakes versus real forgeries in the revised supplementary material. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes LAA-X as an empirical deep learning framework using multi-task auxiliary losses and blending-based pseudo-fake synthesis to train attention on localized artifacts. No equations, first-principles derivations, or parameter-fitting steps are presented that reduce any claimed performance or generalization to quantities defined from the same data or self-citations. Training on real and pseudo-fake samples follows standard practice in forgery detection; reported benchmark results are external empirical measurements, not tautological outputs of the inputs. No self-citation load-bearing steps or ansatz smuggling appear in the manuscript.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-task loss balancing weights
axioms (1)
- domain assumption Blending-based data synthesis produces pseudo-fake samples whose artifacts are representative of those in real high-quality forgeries
Reference graph
Works this paper leans on
-
[1]
Deepfake presidents used in Russia-Ukraine war,
J. Wakefield, “Deepfake presidents used in Russia-Ukraine war,” https: //www.bbc.com/news/technology-60780142, 2022, [Online; accessed 7- March-2023]
work page 2022
-
[2]
How misinformation helped spark an attempted coup in Gabon,
S. Cahlan, “How misinformation helped spark an attempted coup in Gabon,” https://wapo.st/3KZARDF, 2020, [Online; accessed 7-March- 2023]
work page 2020
-
[3]
FaceForensics++: Learning to detect manipulated facial images,
A. R ¨ossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner, “FaceForensics++: Learning to detect manipulated facial images,” inInternational Conference on Computer Vision (ICCV), 2019
work page 2019
-
[5]
Available: http://arxiv.org/abs/1809.00888
[Online]. Available: http://arxiv.org/abs/1809.00888
-
[6]
Fakespotter: A simple baseline for spotting ai-synthesized fake faces,
R. Wang, L. Ma, F. Juefei-Xu, X. Xie, J. Wang, and Y . Liu, “Fakespotter: A simple baseline for spotting ai-synthesized fake faces,”CoRR, vol. abs/1909.06122, 2019. [Online]. Available: http: //arxiv.org/abs/1909.06122
-
[7]
Thinking in frequency: Face forgery detection by mining frequency-aware clues,
Y . Qian, G. Yin, L. Sheng, Z. Chen, and J. Shao, “Thinking in frequency: Face forgery detection by mining frequency-aware clues,” inEuropean conference on computer vision. Springer, 2020, pp. 86–103
work page 2020
-
[8]
Capsule-forensics: Using capsule networks to detect forged images and videos,
H. H. Nguyen, J. Yamagishi, and I. Echizen, “Capsule-forensics: Using capsule networks to detect forged images and videos,”CoRR, vol. abs/1810.11215, 2018. [Online]. Available: http://arxiv.org/abs/1810. 11215
-
[9]
Deepfake detection using spatiotemporal trans- former,
B. Kaddar, S. A. Fezza, Z. Akhtar, W. Hamidouche, A. Hadid, and J. Serra-Sagrist `a, “Deepfake detection using spatiotemporal trans- former,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 20, no. 11, pp. 1–21, 2024
work page 2024
-
[10]
Combining efficientnet and vision transformers for video deepfake detection,
D. A. Coccomini, N. Messina, C. Gennaro, and F. Falchi, “Combining efficientnet and vision transformers for video deepfake detection,” in Image Analysis and Processing – ICIAP 2022, S. Sclaroff, C. Distante, M. Leo, G. M. Farinella, and F. Tombari, Eds. Cham: Springer International Publishing, 2022, pp. 219–229
work page 2022
-
[11]
Fdftnet: Facing off fake images using fake detection fine-tuning network,
H. Jeon, Y . Bang, and S. S. Woo, “Fdftnet: Facing off fake images using fake detection fine-tuning network,” inIFIP international conference on ICT systems security and privacy protection. Springer, 2020, pp. 416– 430
work page 2020
-
[12]
Deep convolutional pooling transformer for deepfake detection,
T. Wang, H. Cheng, K. P. Chow, and L. Nie, “Deep convolutional pooling transformer for deepfake detection,”ACM Trans. Multimedia Comput. Commun. Appl., vol. 19, no. 6, 2023
work page 2023
-
[13]
Deepfake video detection with spatiotemporal dropout transformer,
D. Zhang, F. Lin, Y . Hua, P. Wang, D. Zeng, and S. Ge, “Deepfake video detection with spatiotemporal dropout transformer,” inProceedings of the 30th ACM international conference on multimedia, 2022, pp. 5833– 5841
work page 2022
-
[14]
Multi- attentional deepfake detection,
H. Zhao, W. Zhou, D. Chen, T. Wei, W. Zhang, and N. Yu, “Multi- attentional deepfake detection,” inProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2021, pp. 2185–2194. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15
work page 2021
-
[15]
Detecting deepfakes with self-blended images,
K. Shiohara and T. Yamasaki, “Detecting deepfakes with self-blended images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 720–18 729
work page 2022
-
[16]
End-to-end reconstruction-classification learning for face forgery detection,
J. Cao, C. Ma, T. Yao, S. Chen, S. Ding, and X. Yang, “End-to-end reconstruction-classification learning for face forgery detection,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4103–4112
work page 2022
-
[17]
Implicit identity leakage: The stumbling block to improving deepfake detection gener- alization,
S. Dong, J. Wang, R. Ji, J. Liang, H. Fan, and Z. Ge, “Implicit identity leakage: The stumbling block to improving deepfake detection gener- alization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 3994–4004
work page 2023
-
[18]
Forgery-aware adaptive learning with vision transformer for generalized face forgery detection,
A. Luo, R. Cai, C. Kong, Y . Ju, X. Kang, J. Huang, and A. C. K. Life, “Forgery-aware adaptive learning with vision transformer for generalized face forgery detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[19]
Forensics adapter: Adapting clip for generalizable face forgery detection,
X. Cui, Y . Li, A. Luo, J. Zhou, and J. Dong, “Forensics adapter: Adapting clip for generalizable face forgery detection,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19 207–19 217
work page 2025
-
[20]
Celeb-df: A large-scale challenging dataset for deepfake forensics,
Y . Li, X. Yang, P. Sun, H. Qi, and S. Lyu, “Celeb-df: A large-scale challenging dataset for deepfake forensics,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[21]
L. Chen, Y . Zhang, Y . Song, L. Liu, and J. Wang, “Self-supervised learn- ing of adversarial example: Towards good generalizations for deepfake detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 18 710–18 719
work page 2022
-
[22]
Face x-ray for more general face forgery detection,
L. Li, J. Bao, T. Zhang, H. Yang, D. Chen, F. Wen, and B. Guo, “Face x-ray for more general face forgery detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[23]
Learning self-consistency for deepfake detection,
E. Zhao, X. Xu, M. Xu, H. Ding, Y . Xiong, and W. Xia, “Learning self-consistency for deepfake detection,” inICCV 2021,
work page 2021
-
[24]
Available: https://www.amazon.science/publications/ learning-self-consistency-for-deepfake-detection
[Online]. Available: https://www.amazon.science/publications/ learning-self-consistency-for-deepfake-detection
-
[25]
D. Nguyen, N. Mejri, I. P. Singh, P. Kuleshova, M. Astrid, A. Kacem, E. Ghorbel, and D. Aouada, “Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 17 395–17 405
work page 2024
-
[26]
Vulnerability-aware spatio-temporal learning for generalizable deepfake video detection,
D. Nguyen, M. Astrid, A. Kacem, E. Ghorbel, and D. Aouada, “Vulnerability-aware spatio-temporal learning for generalizable deepfake video detection,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), October 2025, pp. 10 786–10 796
work page 2025
-
[27]
Efficientnet: Rethinking model scaling for convolutional neural networks,
M. Tan and Q. V . Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,”CoRR, vol. abs/1905.11946, 2019. [Online]. Available: http://arxiv.org/abs/1905.11946
-
[28]
Xception: Deep learning with depthwise separable convolu- tions,
F. Chollet, “Xception: Deep learning with depthwise separable convolu- tions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258
work page 2017
-
[29]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,”CoRR, vol. abs/1512.03385, 2015. [Online]. Available: http://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[30]
Y . Wang, K. Yu, C. Chen, X. Hu, and S. Peng, “Dynamic graph learning with content-guided spatial-frequency relation reasoning for deepfake detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 7278–7287
work page 2023
-
[31]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,”CoRR, vol. abs/2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[32]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,”CoRR, vol. abs/2012.12877, 2020
-
[33]
Twins: Revisiting the design of spatial attention in vision transformers,
X. Chu, Z. Tian, Y . Wang, B. Zhang, H. Ren, X. Wei, H. Xia, and C. Shen, “Twins: Revisiting the design of spatial attention in vision transformers,” inNeural Information Processing Systems,
-
[34]
Available: https://api.semanticscholar.org/CorpusID: 234364557
[Online]. Available: https://api.semanticscholar.org/CorpusID: 234364557
-
[35]
https://arxiv.org/abs/2103.14030
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,”CoRR, vol. abs/2103.14030, 2021
-
[36]
Neighborhood attention transformer,
A. Hassani, S. Walton, J. Li, S. Li, and H. Shi, “Neighborhood attention transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 6185–6194
work page 2023
-
[37]
Quantifying attention flow in transformers,
S. Abnar and W. Zuidema, “Quantifying attention flow in transformers,” inAnnual Meeting of the Association for Computational Linguistics,
-
[38]
Available: https://api.semanticscholar.org/CorpusID: 218487351
[Online]. Available: https://api.semanticscholar.org/CorpusID: 218487351
-
[39]
Ucf: Uncovering common features for generalizable deepfake detection,
Z. Yan, Y . Zhang, Y . Fan, and B. Wu, “Ucf: Uncovering common features for generalizable deepfake detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oc- tober 2023, pp. 22 412–22 423
work page 2023
-
[40]
Ost: Improving generalization of deepfake detection via one-shot test-time training,
L. Chen, Y . Zhang, Y . Song, J. Wang, and L. Liu, “Ost: Improving generalization of deepfake detection via one-shot test-time training,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 24 597–24 610. [Online]. Available: https://proce...
work page 2022
-
[41]
K. Lin, Y . Lin, W. Li, T. Yao, and B. Li, “Standing on the shoulders of giants: Reprogramming visual-language model for general deepfake detection,” inProceedings of the AAAI Conference on Artificial Intelli- gence, vol. 39, no. 5, 2025, pp. 5262–5270
work page 2025
-
[42]
Exploring unbiased deepfake detection via token-level shuffling and mixing,
X. Fu, Z. Yan, T. Yao, S. Chen, and X. Li, “Exploring unbiased deepfake detection via token-level shuffling and mixing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 3040–3048
work page 2025
-
[43]
Dfdt: An end-to-end deepfake detection framework using vision transformer,
A. Khormali and J.-S. Yuan, “Dfdt: An end-to-end deepfake detection framework using vision transformer,”Applied Sciences, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:247495859
work page 2022
-
[44]
Pose guided person image generation,
L. Ma, X. Jia, Q. Sun, B. Schiele, T. Tuytelaars, and L. Van Gool, “Pose guided person image generation,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[45]
Image quality assess- ment: from error visibility to structural similarity,
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assess- ment: from error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[46]
Contributing data to deepfake detection research,
N. Dufour and A. Gully, “Contributing data to deepfake detection research,” https://ai.googleblog.com/2019/09/ contributing-data-to-deepfake-detection.html, 2019
work page 2019
-
[47]
Wilddeepfake: A challenging real-world dataset for deepfake detection,
B. Zi, M. Chang, J. Chen, X. Ma, and Y .-G. Jiang, “Wilddeepfake: A challenging real-world dataset for deepfake detection,”Proceedings of the 28th ACM International Conference on Multimedia, 2020
work page 2020
-
[48]
The deepfake detection challenge (DFDC) preview dataset,
B. Dolhansky, R. Howes, B. Pflaum, N. Baram, and C. Canton-Ferrer, “The deepfake detection challenge (DFDC) preview dataset,”CoRR, vol. abs/1910.08854, 2019. [Online]. Available: http://arxiv.org/abs/ 1910.08854
-
[49]
The DeepFake Detection Challenge (DFDC) Dataset
B. Dolhansky, J. Bitton, B. Pflaum, J. Lu, R. Howes, M. Wang, and C. Canton-Ferrer, “The deepfake detection challenge dataset,”CoRR, vol. abs/2006.07397, 2020. [Online]. Available: https://arxiv.org/abs/ 2006.07397
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[50]
Df40: Toward next-generation deepfake detec- tion,
Z. Yan, T. Yao, S. Chen, Y . Zhao, X. Fu, J. Zhu, D. Luo, C. Wang, S. Ding, Y . Wuet al., “Df40: Toward next-generation deepfake detec- tion,”Advances in Neural Information Processing Systems, vol. 37, pp. 29 387–29 434, 2024
work page 2024
-
[51]
Diffusionface: Towards a comprehensive dataset for diffusion-based face forgery analysis,
Z. Chen, K. Sun, Z. Zhou, X. Lin, X. Sun, L. Cao, and R. Ji, “Diffusionface: Towards a comprehensive dataset for diffusion-based face forgery analysis,”arXiv preprint arXiv:2403.18471, 2024
-
[52]
Quality-agnostic deepfake detection with intra-model collaborative learning,
B. M. Le and S. S. Woo, “Quality-agnostic deepfake detection with intra-model collaborative learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 22 378–22 389
work page 2023
-
[53]
Diffusionfake: Enhancing generalization in deepfake detection via guided stable diffu- sion,
S. Chen, T. Yao, H. Liu, X. Sun, S. Ding, R. Jiet al., “Diffusionfake: Enhancing generalization in deepfake detection via guided stable diffu- sion,”Advances in Neural Information Processing Systems, vol. 37, pp. 101 474–101 497, 2024
work page 2024
-
[54]
Local relation learning for face forgery detection,
S. Chen, T. Yao, Y . Chen, S. Ding, J. Li, and R. Ji, “Local relation learning for face forgery detection,” inAAAI Conference on Artificial Intelligence, 2021
work page 2021
-
[55]
Exploring disentangled content infor- mation for face forgery detection,
J. Liang, H. Shi, and W. Deng, “Exploring disentangled content infor- mation for face forgery detection,” inEuropean conference on computer vision. Springer, 2022, pp. 128–145
work page 2022
-
[56]
Freqdebias: Towards generalizable deepfake detection via consistency-driven frequency debi- asing,
H. Kashiani, N. A. Talemi, and F. Afghah, “Freqdebias: Towards generalizable deepfake detection via consistency-driven frequency debi- asing,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), June 2025, pp. 8775–8785
work page 2025
-
[57]
Freqblender: Enhancing deepfake detection by blending frequency knowledge,
H. Li, J. Zhou, Y . Li, B. Wu, B. Li, and J. Dong, “Freqblender: Enhancing deepfake detection by blending frequency knowledge,” in Advances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 44 965–44 988. [Online]. Available: https:...
work page 2024
-
[58]
Aunet: Learning relations between action units for face forgery detection,
W. Bai, Y . Liu, Z. Zhang, B. Li, and W. Hu, “Aunet: Learning relations between action units for face forgery detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 24 709–24 719
work page 2023
-
[59]
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,”CoRR, vol. abs/2005.12872, 2020
-
[60]
ViTPose: Simple vision transformer baselines for human pose estimation,
Y . Xu, J. Zhang, Q. Zhang, and D. Tao, “ViTPose: Simple vision transformer baselines for human pose estimation,” inAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[61]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 16 000–16 009
work page 2022
-
[62]
Deepfake detection algorithm based on improved vision transformer,
Y .-J. Heo, W.-H. Yeo, and B.-G. Kim, “Deepfake detection algorithm based on improved vision transformer,”Applied Intelligence, vol. 53, no. 7, pp. 7512–7527, 2023
work page 2023
-
[63]
Deepfake video detection using convolutional vision transformer,
D. Wodajo and S. Atnafu, “Deepfake video detection using convolutional vision transformer,”arXiv preprint arXiv:2102.11126, 2021
-
[64]
Video transformer for deepfake detection with incremental learning,
S. A. Khan and H. Dai, “Video transformer for deepfake detection with incremental learning,” inProceedings of the 29th ACM international conference on multimedia, 2021, pp. 1821–1828
work page 2021
-
[65]
M2tr: Multi-modal multi-scale transformers for deepfake detection,
J. Wang, Z. Wu, W. Ouyang, X. Han, J. Chen, Y .-G. Jiang, and S.-N. Li, “M2tr: Multi-modal multi-scale transformers for deepfake detection,” inProceedings of the 2022 international conference on multimedia retrieval, 2022, pp. 615–623
work page 2022
-
[66]
Protecting celebrities from deepfake with identity consistency transformer,
X. Dong, J. Bao, D. Chen, T. Zhang, W. Zhang, N. Yu, D. Chen, F. Wen, and B. Guo, “Protecting celebrities from deepfake with identity consistency transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 9468–9478
work page 2022
-
[67]
Efficient deepfake detection using shallow vision transformer,
S. Usmani, S. Kumar, and D. Sadhya, “Efficient deepfake detection using shallow vision transformer,”Multimedia Tools and Applications, vol. 83, no. 4, pp. 12 339–12 362, 2024
work page 2024
-
[68]
Tall: Thumbnail layout for deepfake video detection,
Y . Xu, J. Liang, G. Jia, Z. Yang, Y . Zhang, and R. He, “Tall: Thumbnail layout for deepfake video detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 22 658–22 668
work page 2023
-
[69]
Self-supervised transformer for deepfake detection,
H. Zhao, W. Zhou, D. Chen, W. Zhang, and N. Yu, “Self-supervised transformer for deepfake detection,”arXiv preprint arXiv:2203.01265, 2022
-
[70]
Istvt: interpretable spatial-temporal video transformer for deepfake detection,
C. Zhao, C. Wang, G. Hu, H. Chen, C. Liu, and J. Tang, “Istvt: interpretable spatial-temporal video transformer for deepfake detection,” IEEE Transactions on Information Forensics and Security, vol. 18, pp. 1335–1348, 2023
work page 2023
-
[71]
Z. Yan, Y . Zhao, S. Chen, M. Guo, X. Fu, T. Yao, S. Ding, Y . Wu, and L. Yuan, “Generalizing deepfake video detection with plug-and-play: Video-level blending and spatiotemporal adapter tuning,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 615–12 625
work page 2025
-
[72]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[73]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[74]
Ms-celeb-1m: A dataset and benchmark for large-scale face recognition,
Y . Guo, L. Zhang, Y . Hu, X. He, and J. Gao, “Ms-celeb-1m: A dataset and benchmark for large-scale face recognition,” in European Conference on Computer Vision, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID:2908606
work page 2016
-
[75]
Delving into the local: Dynamic inconsistency learning for deepfake video detection,
Z. Gu, Y . Chen, T. Yao, S. Ding, J. Li, and L. Ma, “Delving into the local: Dynamic inconsistency learning for deepfake video detection,” in Proceedings of the AAAI conference on artificial intelligence, vol. 36, no. 1, 2022, pp. 744–752
work page 2022
-
[76]
Exposing deepfake videos by detecting face warping artifacts,
Y . Li and S. Lyu, “Exposing deepfake videos by detecting face warping artifacts,” inIEEE Conference on Computer Vision and Pattern Recog- nition Workshops (CVPRW), 2019
work page 2019
-
[77]
Cornernet: Detecting objects as paired keypoints,
H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” International Journal of Computer Vision, vol. 128, pp. 642–656, 2018
work page 2018
-
[78]
https://doi.org/10.48550/arXiv.1708.02002
T. Lin, P. Goyal, R. B. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,”CoRR, vol. abs/1708.02002, 2017. [Online]. Available: http://arxiv.org/abs/1708.02002
-
[79]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
work page 2017
-
[80]
FCOS: fully convolutional one-stage object detection,
Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: fully convolutional one-stage object detection,”CoRR, vol. abs/1904.01355, 2019. [Online]. Available: http://arxiv.org/abs/1904.01355
-
[81]
Feature pyramid network for multi-class land segmentation,
S. S. Seferbekov, V . I. Iglovikov, A. V . Buslaev, and A. A. Shvets, “Feature pyramid network for multi-class land segmentation,”CoRR, vol. abs/1806.03510, 2018. [Online]. Available: http://arxiv.org/abs/ 1806.03510
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.