Recognition: no theorem link
Hypothesis Graph Refinement: Hypothesis-Driven Exploration with Cascade Error Correction for Embodied Navigation
Pith reviewed 2026-05-13 17:02 UTC · model grok-4.3
The pith
Representing frontier predictions as revisable hypothesis nodes in a dependency graph allows embodied agents to retract semantic errors by pruning entire dependent subgraphs upon mismatch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
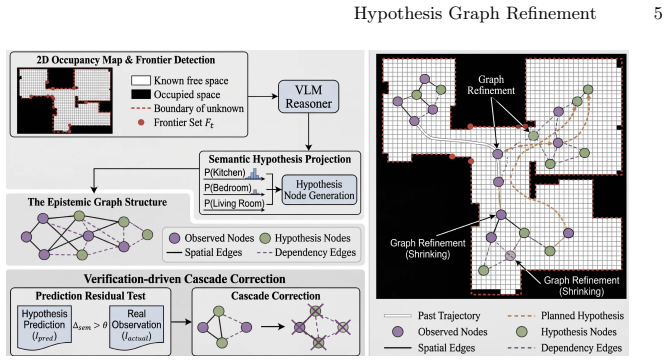
Hypothesis Graph Refinement represents frontier predictions as revisable hypothesis nodes inside a dependency-aware graph memory and applies verification-driven cascade correction that retracts any refuted node together with all its downstream dependents once on-site observations contradict the predicted semantics.
What carries the argument
Verification-driven cascade correction, which compares new observations against stored semantic predictions and prunes the refuted hypothesis node along with every dependent node that was built upon it.
If this is right
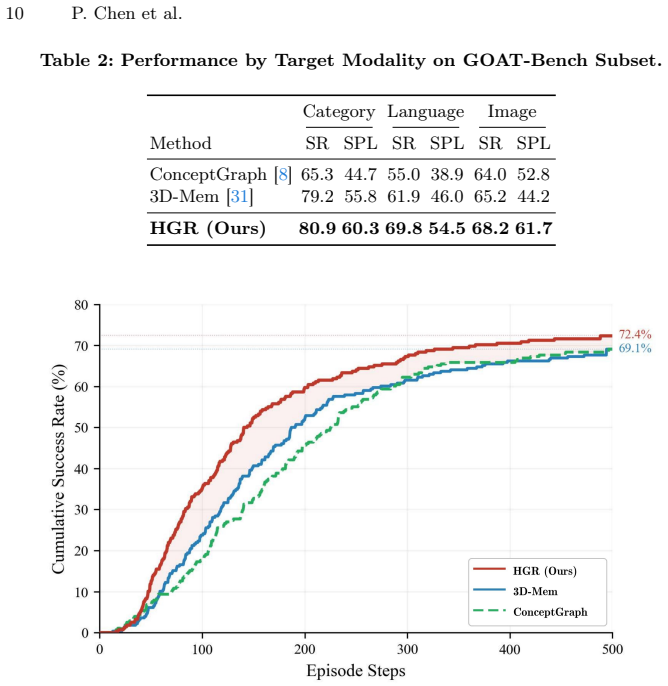
- Yields 72.41 percent success rate and 56.22 percent SPL on GOAT-Bench multimodal lifelong navigation.
- Eliminates roughly 20 percent of structurally redundant hypothesis nodes through pruning.
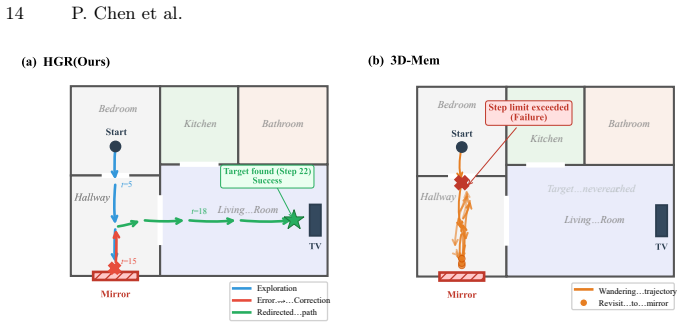
- Cuts revisits to erroneous regions by a factor of 4.5 compared with baselines.
- Produces consistent gains on the A-EQA and EM-EQA embodied question-answering benchmarks.
Where Pith is reading between the lines
- Dependency tracking of this kind could transfer to other sequential decision settings where partial observations generate assumptions that later need targeted rollback.
- The method implies that memory structures in long-horizon agents benefit more from explicit retraction rules than from simple confidence decay.
- Real-world deployment would need to test whether sensor noise still allows the mismatch detection step to trigger corrections at the right times.
Load-bearing premise
That on-site observations can reliably detect when a semantic prediction is wrong and that removing the dependent nodes discards only erroneous structure without losing still-valid information.
What would settle it
An experiment in which cascade correction produces lower success rates than a version without pruning, for instance because valid paths are removed more often than mistaken ones, would show the mechanism does not improve reliability.
Figures



read the original abstract
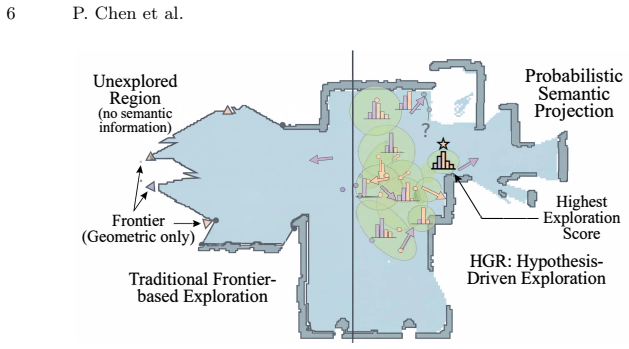
Embodied agents must explore partially observed environments while maintaining reliable long-horizon memory. Existing graph-based navigation systems improve scalability, but they often treat unexplored regions as semantically unknown, leading to inefficient frontier search. Although vision-language models (VLMs) can predict frontier semantics, erroneous predictions may be embedded into memory and propagate through downstream inferences, causing structural error accumulation that confidence attenuation alone cannot resolve. These observations call for a framework that can leverage semantic predictions for directed exploration while systematically retracting errors once new evidence contradicts them. We propose Hypothesis Graph Refinement (HGR), a framework that represents frontier predictions as revisable hypothesis nodes in a dependency-aware graph memory. HGR introduces (1) semantic hypothesis module, which estimates context-conditioned semantic distributions over frontiers and ranks exploration targets by goal relevance, travel cost, and uncertainty, and (2) verification-driven cascade correction, which compares on-site observations against predicted semantics and, upon mismatch, retracts the refuted node together with all its downstream dependents. Unlike additive map-building, this allows the graph to contract by pruning erroneous subgraphs, keeping memory reliable throughout long episodes. We evaluate HGR on multimodal lifelong navigation (GOAT-Bench) and embodied question answering (A-EQA, EM-EQA). HGR achieves 72.41% success rate and 56.22% SPL on GOAT-Bench, and shows consistent improvements on both QA benchmarks. Diagnostic analysis reveals that cascade correction eliminates approximately 20% of structurally redundant hypothesis nodes and reduces revisits to erroneous regions by 4.5x, with specular and transparent surfaces accounting for 67% of corrected prediction errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hypothesis Graph Refinement (HGR), a framework for embodied navigation in partially observed environments. It represents frontier predictions as revisable hypothesis nodes within a dependency-aware graph memory. The method introduces a semantic hypothesis module that estimates context-conditioned semantic distributions over frontiers and ranks targets by goal relevance, travel cost, and uncertainty, along with a verification-driven cascade correction mechanism that retracts a refuted hypothesis node and all its downstream dependents upon mismatch between on-site RGB-D observations and predicted semantics. Unlike additive map-building, the graph contracts by pruning erroneous subgraphs. Evaluation on GOAT-Bench reports 72.41% success rate and 56.22% SPL, with consistent gains on A-EQA and EM-EQA; diagnostics indicate cascade correction removes ~20% redundant nodes, reduces erroneous revisits by 4.5x, and corrects 67% of errors from specular/transparent surfaces.
Significance. If the cascade correction reliably identifies mismatches and prunes only erroneous structure without discarding valid information, HGR could meaningfully advance long-horizon embodied navigation by enabling directed exploration while maintaining memory reliability. The reported 4.5x reduction in erroneous revisits and performance on GOAT-Bench, A-EQA, and EM-EQA suggest practical efficiency gains over standard graph-based systems that rely on confidence attenuation alone. The diagnostic breakdown of error sources (specular/transparent surfaces) provides useful insight into VLM limitations in navigation.
major comments (3)
- The central performance claims (72.41% SR and 56.22% SPL on GOAT-Bench) are presented without baseline comparisons, error bars, statistical tests, or details on evaluation protocols, data exclusion criteria, or how success/SPL are computed, preventing assessment of whether the numbers support the superiority of cascade correction over prior methods.
- The verification-driven cascade correction is load-bearing for the reliability claim, yet the manuscript provides no quantitative evaluation (precision, recall, or failure modes) of the mismatch detection step between VLM predictions and on-site observations under realistic conditions such as sensor noise, partial views, or lighting variation, despite noting that specular/transparent surfaces cause 67% of corrected errors.
- The assumption that retracting a refuted node plus all downstream dependents removes only erroneous structure (without discarding still-valid frontier hypotheses) is not validated; the reported 4.5x reduction in erroneous revisits and ~20% node elimination rest directly on this untested property of the dependency graph.
minor comments (1)
- The abstract and diagnostic analysis would benefit from explicit definition of the dependency graph construction and how acyclicity is enforced to ensure cascade retraction is well-defined.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for strengthening the evaluation and validation of Hypothesis Graph Refinement. We address each major comment below and will incorporate the requested additions and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: The central performance claims (72.41% SR and 56.22% SPL on GOAT-Bench) are presented without baseline comparisons, error bars, statistical tests, or details on evaluation protocols, data exclusion criteria, or how success/SPL are computed, preventing assessment of whether the numbers support the superiority of cascade correction over prior methods.
Authors: We agree that the current presentation of results lacks sufficient context for rigorous comparison. In the revision we will add a dedicated baselines subsection comparing HGR against frontier-based exploration, standard graph memory without hypothesis nodes, and recent VLM-driven navigation methods. Results will be reported with standard error bars across multiple random seeds, accompanied by statistical significance tests (paired t-tests and Wilcoxon signed-rank). A new appendix will detail the exact computation of success rate and SPL, the GOAT-Bench evaluation protocol, episode termination criteria, and any data exclusion rules applied. revision: yes
-
Referee: The verification-driven cascade correction is load-bearing for the reliability claim, yet the manuscript provides no quantitative evaluation (precision, recall, or failure modes) of the mismatch detection step between VLM predictions and on-site observations under realistic conditions such as sensor noise, partial views, or lighting variation, despite noting that specular/transparent surfaces cause 67% of corrected errors.
Authors: We acknowledge the absence of quantitative metrics for the mismatch detection module. The revised manuscript will include a new diagnostic subsection that reports precision, recall, and F1-score for the verification step. We will add controlled experiments that inject sensor noise, simulate partial views, and vary lighting conditions, together with a tabulated breakdown of failure modes. The 67% attribution to specular and transparent surfaces will be supported by per-scene counts and representative RGB-D examples showing both successful and unsuccessful detections. revision: yes
-
Referee: The assumption that retracting a refuted node plus all downstream dependents removes only erroneous structure (without discarding still-valid frontier hypotheses) is not validated; the reported 4.5x reduction in erroneous revisits and ~20% node elimination rest directly on this untested property of the dependency graph.
Authors: We agree that direct validation of pruning selectivity is required. In the revision we will add an analysis that tracks each pruned node and determines whether it would have produced an erroneous revisit if retained (via oracle re-evaluation on held-out trajectories). We will report the fraction of pruned nodes that were verifiably incorrect versus those that were still potentially valid, and include qualitative visualizations of the dependency graph before and after cascade correction to illustrate preservation of independent valid frontiers. These additions will ground the 4.5x and 20% figures in explicit selectivity measurements. revision: yes
Circularity Check
No circularity: method and results are self-contained with external benchmark evaluation
full rationale
The paper defines HGR procedurally as a graph-based framework with a semantic hypothesis module for ranking frontiers and a verification-driven cascade correction for retracting mismatched nodes plus dependents. Reported metrics (72.41% SR, 56.22% SPL on GOAT-Bench) are obtained via direct evaluation on independent external benchmarks (GOAT-Bench, A-EQA, EM-EQA) rather than any derivation that reduces performance to fitted parameters or self-referential definitions. No equations, self-citations, or ansatzes are invoked that would make the central claims equivalent to their inputs by construction. The derivation chain remains independent of the reported outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models produce context-conditioned semantic distributions over frontiers that are sufficiently accurate to rank exploration targets usefully
- domain assumption On-site observations can be compared directly against predicted semantics to detect contradictions reliably
invented entities (2)
-
Hypothesis nodes
no independent evidence
-
Cascade correction mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
An, D., Wang, H., Wang, W., Wang, Z., Huang, Y., He, K., Wang, L.: Etpnav: Evolving topological planning for vision-language navigation in continuous envi- ronments. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
work page 2024
-
[2]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sünderhauf, N., Reid, I., Gould, S., Van Den Hengel, A.: Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3674–3683 (2018)
work page 2018
-
[3]
In: Proceedings of the IEEE/CVF international conference on computer vision
Armeni, I., He, Z.Y., Gwak, J., Zamir, A.R., Fischer, M., Malik, J., Savarese, S.: 3d scene graph: A structure for unified semantics, 3d space, and camera. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5664–5673 (2019)
work page 2019
-
[4]
In: Findings of the Association for Computational Linguistics: EMNLP 2025 (2025)
Chakraborty, T., Ghosh, U., Zhang, X., Niloy, F.F., Dong, Y., Li, J., Roy- Chowdhury, A.K., Song, C.: HEAL: An empirical study on hallucinations in em- bodied agents driven by large language models. In: Findings of the Association for Computational Linguistics: EMNLP 2025 (2025)
work page 2025
-
[5]
In: Advances in Neural Information Processing Systems (NeurIPS)
Deng, Z., Narasimhan, K., Russakovsky, O.: Evolving graphical planner: Contex- tual global planning for vision-and-language navigation. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 33 (2020)
work page 2020
-
[6]
Fan, C., Jia, X., Sun, Y., Wang, Y., Wei, J., Gong, Z., Zhao, X., Tomizuka, M., Yang, X., Yan, J., Ding, M.: Interleave-VLA: Enhancing robot manipulation with interleaved image-text instructions. arXiv preprint arXiv:2505.02152 (2025)
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Gadre, S.Y., Wortsman, M., Ilharco, G., Schmidt, L., Song, S.: CoWs on Pas- ture: Baselines and benchmarks for language-driven zero-shot object navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
work page 2023
-
[8]
In: Proceedings of the IEEE Inter- national Conference on Robotics and Automation (ICRA) (2024)
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., Gan, C., de Melo, C.M., Tenen- baum, J.B., Torralba, A., Shkurti, F., Paull, L.: ConceptGraphs: Open-vocabulary 3d scene graphs for perception and planning. In: Proceedings of the IEEE Inter- national Conference on Robotics and A...
work page 2024
-
[9]
Heo, K., Kim, G., Kim, S., Cho, M.: Object-centric representation learning for enhanced3dscenegraphprediction.In:AdvancesinNeuralInformationProcessing Systems (NeurIPS) (2025)
work page 2025
-
[10]
In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition
Hong, Y., Wu, Q., Qi, Y., Rodriguez-Opazo, C., Gould, S.: Vln bert: A recur- rent vision-and-language bert for navigation. In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. pp. 1643–1653 (2021)
work page 2021
-
[11]
arXiv preprint arXiv:2505.07868 (2025)
Huang, Y., Wu, M., Li, R., Tu, Z.: VISTA: Generative visual imagination for vision-and-language navigation. arXiv preprint arXiv:2505.07868 (2025)
-
[12]
Language Models (Mostly) Know What They Know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al.: Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Khanna, M., Ramrakhya, R., Chhablani, G., Yenamandra, S., Gervet, T., Chang, M., Kira, Z., Chaplot, D.S., Batra, D., Mottaghi, R.: GOAT-Bench: A benchmark for multi-modal lifelong navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16373–16383 (2024)
work page 2024
-
[14]
Ku, A., Anderson, P., Patel, R., Ie, E., Baldridge, J.: Room-across-room: Multi- lingual vision-and-language navigation with dense spatiotemporal grounding. In: 16 P. Chen et al. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 4392–4412 (2020)
work page 2020
-
[15]
In: Proceedings of the 40th International Conference on Machine Learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: bootstrapping language-image pre- training with frozen image encoders and large language models. In: Proceedings of the 40th International Conference on Machine Learning. ICML’23, JMLR.org (2023)
work page 2023
-
[16]
arXiv preprint arXiv:2301.02382 (2023)
Liu, J., Guo, J., Meng, Z., Xue, J.: Revolt: Relational reasoning and voronoi lo- cal graph planning for target-driven navigation. arXiv preprint arXiv:2301.02382 (2023)
-
[17]
arXiv preprint arXiv:2409.15658 (2024)
Liu, S., Du, J., Xiang, S., Wang, Z., Luo, D.: Long-horizon embodied plan- ning with implicit logical inference and hallucination mitigation. arXiv preprint arXiv:2409.15658 (2024)
-
[18]
In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
Majumdar, A., Aggarwal, G., Devnani, B., Hoffman, J., Batra, D.: ZSON: Zero- shot object-goal navigation using multimodal goal embeddings. In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
work page 2022
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Majumdar, A., Ajay, A., Zhang, X., Putta, P., Yenamandra, S., Henaff, M., Silwal, S., Mcvay, P., Maksymets, O., Arnaud, S., Yadav, K., Li, Q., Newman, B., Sharma, M., Berges, V., Zhang, S., Agrawal, P., Bisk, Y., Batra, D., Kalakrishnan, M., Meier, F., Paxton, C., Sax, A., Rajeswaran, A.: OpenEQA: Embodied question answering in the era of foundation model...
work page 2024
-
[20]
In: Proceedings of the 2023ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP)
Manakul, P., Liusie, A., Gales, M.J.F.: SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. In: Proceedings of the 2023ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP). pp. 9004–9017 (2023)
work page 2023
-
[21]
Film: Following instructions in language with modular methods.arXiv preprint arXiv:2110.07342, 2021
Min, S.Y., Chaplot, D.S., Ravikumar, P., Bisk, Y., Salakhutdinov, R.: Film: Following instructions in language with modular methods. arXiv preprint arXiv:2110.07342 (2021)
-
[22]
Monaci, G., de Rezende, R.S., Deffayet, R., Csurka, G., Bono, G., D’ejean, H., Clin- chant, S., Wolf, C.: Rana: Retrieval-augmented navigation. Trans. Mach. Learn. Res.2025(2025)
work page 2025
-
[23]
In: Proceedings of the 41st International Conference on Machine Learning
Nasiriany, S., Xia, F., Yu, W., Xiao, T., Liang, J., Dasgupta, I., Xie, A., Driess, D., Wahid, A., Xu, Z., Vuong, Q., Zhang, T., Lee, T.W.E., Lee, K.H., Xu, P., Kirmani, S., Zhu, Y., Zeng, A., Hausman, K., Heess, N., Finn, C., Levine, S., Ichter, B.: PIVOT: Iterative visual prompting elicits actionable knowledge for VLMs. In: Proceedings of the 41st Inter...
work page 2024
-
[24]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
Qi, Z., Zhang, Z., Yu, Y., Wang, J., Zhao, H.: VLN-R1: Vision-language navigation via reinforcement fine-tuning. arXiv preprint arXiv:2506.17221 (2025)
-
[25]
In: Robotics: Science and Systems (RSS) (2024)
Ren, A.Z., Clark, J., Dixit, A., Itkina, M., Majumdar, A., Sadigh, D.: Explore un- til confident: Efficient exploration for embodied question answering. In: Robotics: Science and Systems (RSS) (2024)
work page 2024
-
[26]
In: Proceedings of the 9th Conference on Robot Learning (CoRL) (2025)
Saxena, S., Buchanan, B., Paxton, C., Liu, P., Chen, B., Vaskevicius, N., Palmieri, L., Francis, J., Kroemer, O.: GraphEQA: Using 3d semantic scene graphs for real- time embodied question answering. In: Proceedings of the 9th Conference on Robot Learning (CoRL) (2025)
work page 2025
-
[27]
In: Proceedings of the Conference on Robot Learning (CoRL) (2023) Hypothesis Graph Refinement 17
Shah,D.,Equi,M.,Osinski,B.,Xia,F.,Ichter,B.,Levine,S.:Navigationwithlarge language models: Semantic guesswork as a heuristic for planning. In: Proceedings of the Conference on Robot Learning (CoRL) (2023) Hypothesis Graph Refinement 17
work page 2023
-
[28]
In: Findings of the Association for Computational Linguistics: ACL 2024
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y.X., Yang, Y., Keutzer, K., Darrell, T.: Aligning large multimodal models with factually augmented RLHF. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 13088–13110. Association for Computational Linguistics, Bangkok, Thailand (Aug 2024)
work page 2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wald, J., Dhamo, H., Navab, N., Tombari, F.: Learning 3d semantic scene graphs from 3d indoor reconstructions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3961–3970 (2020)
work page 2020
-
[30]
arXiv preprint arXiv:2511.08935 (2025)
Wang, N., Chen, W., Chen, L., Ji, H., Guo, Z., Zhang, X., Sun, H.: Expand your scope: Semantic cognition over potential-based exploration for embodied visual navigation. arXiv preprint arXiv:2511.08935 (2025)
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, Y., Yang, H., Zhou, J., Chen, P., Zhang, H., Du, Y., Gan, C.: 3D-Mem: 3d scene memory for embodied exploration and reasoning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17294–17303 (2025)
work page 2025
-
[32]
arXiv preprint arXiv:2511.05894 (2025)
Yu,F.,Deng,Q.,Tang,S.,Li,Y.,Cheng,L.:Open-world3dscenegraphgeneration for retrieval-augmented reasoning. arXiv preprint arXiv:2511.05894 (2025)
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Zemskova, T., Yudin, D.A.: 3DGraphLLM: Combining semantic graphs and large language models for 3d scene understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
work page 2025
-
[34]
arXiv preprint arXiv:2509.12618 (2025)
Zhang, Z., Zhu, W., Pan, H., Wang, X., Xu, R., Sun, X., Zheng, F.: ActiveVLN: Towards active exploration via multi-turn RL in vision-and-language navigation. arXiv preprint arXiv:2509.12618 (2025)
-
[35]
Zhou, K., Zheng, K., Pryor, C., Shen, Y., Jin, H., Getoor, L., Wang, X.E.: Esc: Exploration with soft commonsense constraints for zero-shot object navigation. In: International Conference on Machine Learning. pp. 42829–42842. PMLR (2023) 18 P. Chen et al. A Detailed Comparison with Commonsense-Guided Exploration Table 7 compares HGR with recent commonsens...
work page 2023
-
[36]
The agent observes a frontierfA at the end of the hallway. The VLM pre- dicts “kitchen” withρ= 0.82, creating hypothesis nodev hyp A with edge (vobs 1 , vhyp A ,0.82)
-
[37]
stove” (ρ= 0.71),“refrigerator
The VLM further predicts objects in the hypothesized kitchen: “stove” (ρ= 0.71),“refrigerator” (ρ= 0.68).Objecthypothesisnodesv obj A1 , vobj A2 arecreated with edges(v hyp A , vobj A1 ,0.71)and(v hyp A , vobj A2 ,0.68)
-
[38]
bedroom” withρ= 0.65, creatingv hyp B with edge(v obs 1 , vhyp B ,0.65)and child object “bed
Another frontierfB is detected. The VLM predicts “bedroom” withρ= 0.65, creatingv hyp B with edge(v obs 1 , vhyp B ,0.65)and child object “bed” (ρ= 0.74)
-
[39]
kitchen” node decayed to 0.3 confidence still suggests nearby “stove
The agent navigates tof A and observes a laundry room instead. Since ∆sem = 0.72>0.5, nodev hyp A is refuted. Cascade correction removesvhyp A , vobj A1 (stove), andv obj A2 (refrigerator)—three nodes total. The bedroom hy- pothesis branch (vhyp B and its children) is unaffected. C.3 Cascade Breadth Analysis In practice, dependency chains are shallow. Acr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.