Recognition: no theorem link
Formalized Information Needs Improve Large-Language-Model Relevance Judgments
Pith reviewed 2026-05-13 16:45 UTC · model grok-4.3
The pith
Formalized topics improve LLM relevance judgments over query-only assessments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
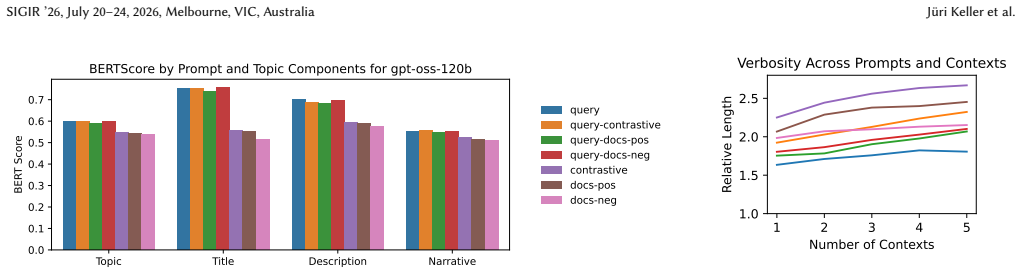
Assessors using only queries judge many more documents relevant and have lower agreement than those using synthetically generated topics with descriptions and narratives. The formalized topics increase agreement between human and LLM relevance judgments on the 2019/2020 TREC Deep Learning and Robust04 collections, even when the topics are not highly similar to their human counterparts.
What carries the argument
Synthetically generated retrieval topics that include descriptions and narratives, produced by LLMs to formalize information needs from queries for relevance assessment.
If this is right
- LLM assessors without formalization judge many more documents relevant, lowering evaluation reliability.
- Formalized topics increase agreement among LLM assessors themselves.
- Formalized topics improve agreement between LLM and human judgments.
- The benefit occurs even when synthetic topics are not highly similar to human versions.
- Synthetically formalizing topics is advised when no human formalization exists.
Where Pith is reading between the lines
- Evaluation protocols for LLM-based assessments may need to standardize on topic structures to match the quality of human Cranfield-style assessments.
- The gains likely come from added context in topics that narrows LLM interpretations rather than exact replication of human intent.
- Researchers could test whether hybrid human-LLM topic creation yields further consistency gains in other retrieval benchmarks.
- Similar formalization steps might benefit LLM use in related tasks like summarization or question answering where intent precision matters.
Load-bearing premise
That synthetically generated topics capture the intended information need well enough to improve judgments even when they differ from human-written topics, and that results on these two TREC collections generalize.
What would settle it
An experiment on a new TREC collection or different queries where LLM assessors given synthetic topics show no increase in agreement and no reduction in documents judged relevant compared to query-only assessors.
Figures



read the original abstract
Cranfield-style retrieval evaluations with too few or too many relevant documents or with low inter-assessor agreement on relevance can reduce the reliability of observations. In evaluations with human assessors, information needs are often formalized as retrieval topics to avoid an excessive number of relevant documents while maintaining good agreement. However, emerging evaluation setups that use Large Language Models (LLMs) as relevance assessors often use only queries, potentially decreasing the reliability. To study whether LLM relevance assessors benefit from formalized information needs, we synthetically formalize information needs with LLMs into topics that follow the established structure from previous human relevance assessments (i.e., descriptions and narratives). We compare assessors using synthetically formalized topics against the LLM-default query-only assessor on the~2019/2020~editions of TREC Deep Learning and Robust04. We find that assessors without formalization judge many more documents relevant and have a lower agreement, leading to reduced reliability in retrieval evaluations. Furthermore, we show that the formalized topics improve agreement between human and LLM relevance judgments, even when the topics are not highly similar to their human counterparts. Our findings indicate that LLM relevance assessors should use formalized information needs, as is standard for human assessment, and synthetically formalize topics when no human formalization exists to improve evaluation reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM relevance assessors benefit from synthetically generated formalized topics (descriptions and narratives following TREC structure) rather than query-only inputs. On TREC DL 2019/2020 and Robust04, query-only assessors label more documents relevant with lower agreement; formalized topics raise human-LLM agreement even when synthetic topics diverge from human-written ones. The authors conclude that LLM assessors should use formalized information needs to improve evaluation reliability.
Significance. If the central empirical comparison holds, the work offers a concrete, low-cost intervention to increase reliability of LLM-based Cranfield evaluations on public collections. It directly addresses a known weakness (over-labeling and low agreement) with a method that re-uses existing topic structure and reports gains even under topic dissimilarity, providing a practical recommendation for the field.
major comments (3)
- [Section 3] Section 3 (Experimental Setup): the design generates synthetic topics and performs relevance judgments with the same LLM family. This leaves open the possibility that observed reductions in over-labeling and gains in human-LLM agreement arise from self-alignment rather than from formalization per se. A cross-model control (generate with model A, judge with model B) is required to support the general claim.
- [Section 4.2] Section 4.2 and Table 2: the reported improvements in agreement lack accompanying statistical test details (p-values, confidence intervals, or exact inter-assessor metric such as Cohen’s kappa). Without these, it is impossible to judge whether the directional effects are robust or sensitive to post-hoc analysis choices.
- [Section 4.3] Section 4.3: the claim that benefits persist “even when topics are not highly similar” to human counterparts is load-bearing for the generalization argument, yet the paper provides no quantitative threshold for “highly similar,” no correlation between similarity score and agreement delta, and no ablation on the subset of low-similarity topics.
minor comments (2)
- [Abstract] Abstract and Section 2: the agreement measure (percentage, kappa, etc.) is never named, making the numerical comparisons hard to interpret.
- [Section 5] Section 5: the discussion of limitations could explicitly address whether results generalize beyond the two TREC collections and the specific LLMs tested.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We believe the suggested changes will strengthen the paper and address the concerns regarding experimental controls, statistical rigor, and generalization claims. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: Section 3 (Experimental Setup): the design generates synthetic topics and performs relevance judgments with the same LLM family. This leaves open the possibility that observed reductions in over-labeling and gains in human-LLM agreement arise from self-alignment rather than from formalization per se. A cross-model control (generate with model A, judge with model B) is required to support the general claim.
Authors: We agree that this is a valid concern and that a cross-model experiment would provide stronger evidence for the generalizability of our findings. In the revised manuscript, we will include results from additional experiments where topics are generated using one model (e.g., GPT-4) and relevance judgments are performed using a different model family (e.g., Llama-3 or Mistral). This will help isolate the effect of formalization from any self-alignment. revision: yes
-
Referee: Section 4.2 and Table 2: the reported improvements in agreement lack accompanying statistical test details (p-values, confidence intervals, or exact inter-assessor metric such as Cohen’s kappa). Without these, it is impossible to judge whether the directional effects are robust or sensitive to post-hoc analysis choices.
Authors: We appreciate this observation. The original manuscript reports agreement metrics but omits formal statistical testing. In the revision, we will add p-values (using appropriate tests such as McNemar's test for paired proportions or bootstrap confidence intervals) and specify the exact agreement metric (e.g., Cohen's kappa or Krippendorff's alpha). We will also include confidence intervals for the key differences. revision: yes
-
Referee: Section 4.3: the claim that benefits persist “even when topics are not highly similar” to human counterparts is load-bearing for the generalization argument, yet the paper provides no quantitative threshold for “highly similar,” no correlation between similarity score and agreement delta, and no ablation on the subset of low-similarity topics.
Authors: We acknowledge that the current presentation lacks the quantitative details needed to fully support this claim. We will revise Section 4.3 to include: (1) a clear definition of similarity threshold (e.g., based on embedding cosine similarity), (2) the Pearson or Spearman correlation between topic similarity and the agreement improvement, and (3) an ablation study reporting results separately for high- and low-similarity topic subsets. This will provide a more rigorous basis for the generalization argument. revision: yes
Circularity Check
No circularity: purely empirical evaluation on fixed public collections
full rationale
The paper reports an empirical study comparing LLM relevance judgments using query-only inputs versus synthetically generated topics (descriptions + narratives) on the fixed TREC DL 2019/2020 and Robust04 collections. All measurements rely on standard inter-assessor agreement metrics and relevance counts; no equations, predictions, or first-principles derivations are presented that could reduce to fitted parameters or self-referential definitions. The central claims rest on direct experimental outcomes rather than any load-bearing self-citation chain or ansatz smuggled via prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human topic formalization practices improve LLM judgment reliability
Reference graph
Works this paper leans on
-
[1]
In: Zamani, H., Dietz, L., Pi- wowarski, B., Bruch, S
Alaofi, M., Ferro, N., Thomas, P., Scholer, F., Sanderson, M.: Demographically- inspired query variants using an LLM. In: Zamani, H., Dietz, L., Pi- wowarski, B., Bruch, S. (eds.) Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Re- trieval, ICTIR 2025, Padua, Italy, 18 July 2025. pp. 390–400. A...
-
[2]
In: Chen, H., Duh, W.E., Huang, H., Kato, M.P., Mothe, J., Poblete, B
Alaofi, M., Gallagher, L., Sanderson, M., Scholer, F., Thomas, P.: Can generative llms create query variants for test collections? an exploratory study. In: Chen, H., Duh, W.E., Huang, H., Kato, M.P., Mothe, J., Poblete, B. (eds.) Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, T...
-
[3]
In: Sakai, T., Ishita, E., Ohshima, H., Hasibi, F., Mao, J., Jose, J.M
Alaofi, M., Thomas, P., Scholer, F., Sanderson, M.: Llms can be fooled into la- belling a document as relevant: best café near me; this paper is perfectly rel- evant. In: Sakai, T., Ishita, E., Ohshima, H., Hasibi, F., Mao, J., Jose, J.M. (eds.) Proceedings of the 2024 Annual International ACM SIGIR Conference on Re- search and Development in Information ...
-
[4]
In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S
Arabzadeh, N., Clarke, C.L.A.: Benchmarking LLM-based relevance judgment methods. In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S. (eds.) Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18,
work page 2025
-
[5]
pp. 3194–3204. ACM (2025). https://doi.org/10.1145/3726302.3730305
-
[6]
In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S
Balog, K., Metzler, D., Qin, Z.: Rankers, judges, and assistants: Towards under- standing the interplay of llms in information retrieval evaluation. In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S. (eds.) Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Formalized Information Needs Improv...
-
[7]
Canadian journal of information science5(1), 133–143 (1980)
Belkin, N.J.: Anomalous states of knowledge as a basis for information retrieval. Canadian journal of information science5(1), 133–143 (1980)
work page 1980
-
[8]
In: Koopman, B., Zuccon, G., Carman, M.J
Benham, R., Culpepper, J.S.: Risk-reward trade-offs in rank fusion. In: Koopman, B., Zuccon, G., Carman, M.J. (eds.) Proceedings of the 22nd Australasian Docu- ment Computing Symposium, ADCS 2017, Brisbane, QLD, Australia, December 7-8, 2017. pp. 1:1–1:8. ACM (2017). https://doi.org/10.1145/3166072.3166084
-
[9]
In: Balog, K., Setty, V., Lioma, C., Liu, Y., Zhang, M., Berberich, K
Clarke, C.L.A., Vtyurina, A., Smucker, M.D.: Offline evaluation without gain. In: Balog, K., Setty, V., Lioma, C., Liu, Y., Zhang, M., Berberich, K. (eds.) ICTIR ’20: The 2020 ACM SIGIR International Conference on the Theory of Information Retrieval, Virtual Event, Norway, September 14-17, 2020. pp. 185–192. ACM (2020). https://doi.org/10.1145/3409256.3409816
-
[10]
In: Bookstein, A., Chiaramella, Y., Salton, G., Raghavan, V.V
Cleverdon, C.W.: The significance of the cranfield tests on index languages. In: Bookstein, A., Chiaramella, Y., Salton, G., Raghavan, V.V. (eds.) Proceedings of the 14th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Chicago, Illinois, USA, October 13-16, 1991 (Special Issue of the SIGIR Forum). pp. 3–12. ...
-
[11]
Cohen, J.: A coefficient of agreement for nominal scales. Ed- ucational and Psychological Measurement20(1), 37–46 (1960). https://doi.org/10.1177/001316446002000104
-
[12]
Craswell, N., Mitra, B., Yilmaz, E., Campos, D.: Overview of the TREC 2020 deep learning track. In: Voorhees, E.M., Ellis, A. (eds.) Proceedings of the Twenty-Ninth Text REtrieval Conference, TREC 2020, Virtual Event [Gaithersburg, Maryland, USA], November 16-20, 2020. NIST Special Publication, National Institute of Standards and Technology (NIST) (2020),...
work page 2020
-
[13]
CoRRabs/2003.07820(2020), https://arxiv.org/ abs/2003.07820
Craswell, N., Mitra, B., Yilmaz, E., Campos, D., Voorhees, E.M.: Overview of the TREC 2019 deep learning track. CoRRabs/2003.07820(2020), https://arxiv.org/ abs/2003.07820
-
[14]
In: Diaz, F., Shah, C., Suel, T., Castells, P., Jones, R., Sakai, T
Craswell, N., Mitra, B., Yilmaz, E., Campos, D., Voorhees, E.M., Soboroff, I.: TREC deep learning track: Reusable test collections in the large data regime. In: Diaz, F., Shah, C., Suel, T., Castells, P., Jones, R., Sakai, T. (eds.) SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval, Virtual Event...
-
[15]
Craswell, N., Mitra, B., Yilmaz, E., Rahmani, H.A., Campos, D., Lin, J., Voorhees, E.M., Soboroff, I.: Overview of the TREC 2023 deep learning track. In: Soboroff, I., Ellis, A. (eds.) The Thirty-Second Text REtrieval Conference Proceedings (TREC 2023), Gaithersburg, MD, USA, November 14-17, 2023. NIST Special Publication, vol. 500-xxx. National Institute...
work page 2023
-
[16]
In: Goharian, N., Tonellotto, N., He, Y., Lipani, A., McDonald, G., Macdonald, C., Ounis, I
Engelmann, B., Breuer, T., Friese, J.I., Schaer, P., Fuhr, N.: Context-driven interac- tive query simulations based on generative large language models. In: Goharian, N., Tonellotto, N., He, Y., Lipani, A., McDonald, G., Macdonald, C., Ounis, I. (eds.) Advances in Information Retrieval - 46th European Conference on Informa- tion Retrieval, ECIR 2024, Glas...
-
[17]
In: Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval
Faggioli, G., Dietz, L., Clarke, C.L.A., Demartini, G., Hagen, M., Hauff, C., Kando, N., Kanoulas, E., Potthast, M., Stein, B., Wachsmuth, H.: Perspectives on Large Language Models for Relevance Judgment. In: Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval. pp. 39–50. ACM, Taipei Taiwan (Aug 2023). https://doi...
-
[18]
Farzi, N., Dietz, L.: Criteria-based LLM relevance judgments. In: Zamani, H., Dietz, L., Piwowarski, B., Bruch, S. (eds.) Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval, ICTIR 2025, Padua, Italy, 18 July 2025. pp. 254–263. ACM (2025). https://doi.org/10.1145/3731120.3744591
-
[19]
Farzi, N., Dietz, L.: Does UMBRELA work on other llms? In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S. (eds.) Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025. pp. 3214–3222. ACM (2025). https://doi.org/10.1145/3726302.3730317
-
[20]
Psychological Bulletin76, 378–382 (1971)
Fleiss, J.L.: Measuring nominal scale agreement among many raters. Psychological Bulletin76, 378–382 (1971)
work page 1971
-
[21]
In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Ver- berne, S
Fröbe, M., Parry, A., Schlatt, F., MacAvaney, S., Stein, B., Potthast, M., Hagen, M.: Large language model relevance assessors agree with one another more than with human assessors. In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Ver- berne, S. (eds.) Proceedings of the 48th International ACM SIGIR Conference on Research and Development in ...
-
[22]
In: Korfhage, R.R., Rasmussen, E.M., Willett, P
Harman, D.: Overview of the first text retrieval conference. In: Korfhage, R.R., Rasmussen, E.M., Willett, P. (eds.) Proceedings of the 16th Annual Interna- tional ACM-SIGIR Conference on Research and Development in Information Retrieval. Pittsburgh, PA, USA, June 27 - July 1, 1993. pp. 36–47. ACM (1993). https://doi.org/10.1145/160688.160692
-
[23]
Hosseini, K., Kober, T., Krapac, J., Vollgraf, R., Cheng, W., Peleteiro-Ramallo, A.: Retrieve, annotate, evaluate, repeat: Leveraging multimodal llms for large-scale product retrieval evaluation. In: Hauff, C., Macdonald, C., Jannach, D., Kazai, G., Nardini, F.M., Pinelli, F., Silvestri, F., Tonellotto, N. (eds.) Advances in Information Retrieval - 47th E...
-
[24]
In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S
Kruff, A.K., Breuer, T., Schaer, P.: Evaluating contrastive feedback for effective user simulations. In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S. (eds.) Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18,
work page 2025
-
[25]
pp. 2931–2935. ACM (2025). https://doi.org/10.1145/3726302.3730189
-
[26]
Cluster-based partial dense retrieval fused with sparse text retrieval,
Li, M., Zhuang, H., Hui, K., Qin, Z., Lin, J., Jagerman, R., Wang, X., Bendersky, M.: Can query expansion improve generalization of strong cross-encoder rankers? In: Yang, G.H., Wang, H., Han, S., Hauff, C., Zuccon, G., Zhang, Y. (eds.) Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2...
-
[27]
In: Text Sum- marization Branches Out
Lin, C.Y.: ROUGE: A package for automatic evaluation of summaries. In: Text Sum- marization Branches Out. pp. 74–81. Association for Computational Linguistics, Barcelona, Spain (Jul 2004), https://aclanthology.org/W04-1013/
work page 2004
-
[28]
Meng, C., Arabzadeh, N., Askari, A., Aliannejadi, M., de Rijke, M.: Query perfor- mance prediction using relevance judgments generated by large language models. ACM Trans. Inf. Syst.43(4), 106:1–106:35 (2025). https://doi.org/10.1145/3736402
-
[29]
Moffat, A., Scholer, F., Thomas, P., Bailey, P.: Pooled evaluation over query varia- tions: Users are as diverse as systems. In: Bailey, J., Moffat, A., Aggarwal, C.C., de Rijke, M., Kumar, R., Murdock, V., Sellis, T.K., Yu, J.X. (eds.) Proceedings of the 24th ACM International Conference on Information and Knowledge Manage- ment, CIKM 2015, Melbourne, VI...
-
[30]
In: Besold, T.R., Bordes, A., d’Avila Garcez, A.S., Wayne, G
Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary, S., Majumder, R., Deng, L.: MS MARCO: A human generated machine reading comprehension dataset. In: Besold, T.R., Bordes, A., d’Avila Garcez, A.S., Wayne, G. (eds.) Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Confe...
work page 2016
-
[31]
CoRRabs/1904.08375(2019), http://arxiv.org/abs/1904.08375
Nogueira, R., Yang, W., Lin, J., Cho, K.: Document expansion by query prediction. CoRRabs/1904.08375(2019), http://arxiv.org/abs/1904.08375
-
[32]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI: gpt-oss-120b & gpt-oss-20b model card. CoRRabs/2508.10925(2025). https://doi.org/10.48550/ARXIV.2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[33]
In: Yang, G.H., Wang, H., Han, S., Hauff, C., Zuccon, G., Zhang, Y
Rahmani, H.A., Craswell, N., Yilmaz, E., Mitra, B., Campos, D.: Synthetic test collections for retrieval evaluation. In: Yang, G.H., Wang, H., Han, S., Hauff, C., Zuccon, G., Zhang, Y. (eds.) Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SI- GIR 2024, Washington DC, USA, July 14-18, 2024. ...
-
[34]
In: Long, G., Blumestein, M., Chang, Y., Lewin-Eytan, L., Huang, Z.H., Yom-Tov, E
Rahmani, H.A., Wang, X., Yilmaz, E., Craswell, N., Mitra, B., Thomas, P.: Syndl: A large-scale synthetic test collection for passage retrieval. In: Long, G., Blumestein, M., Chang, Y., Lewin-Eytan, L., Huang, Z.H., Yom-Tov, E. (eds.) Companion Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025 - 2 May 2025. pp. ...
-
[35]
Sanderson, M.: Test collection based evaluation of information retrieval systems. Found. Trends Inf. Retr.4(4), 247–375 (2010). https://doi.org/10.1561/1500000009
-
[36]
Soboroff, I.: Don’t use llms to make relevance judgments. Inf. Retr. Res. J.1(1), 29–46 (2025). https://doi.org/10.54195/IRRJ.19625
-
[37]
Takehi, R., Voorhees, E.M., Sakai, T., Soboroff, I.: Llm-assisted relevance assess- ments: When should we ask llms for help? In: Ferro, N., Maistro, M., Pasi, G., Alonso, O., Trotman, A., Verberne, S. (eds.) Proceedings of the 48th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-...
-
[38]
American Documen- tation16(2), 69–72 (1965)
Taube, M.: A note on the pseudo-mathematics of relevance. American Documen- tation16(2), 69–72 (1965). https://doi.org/10.1002/asi.5090160204
-
[40]
In: Yang, G.H., Wang, H., Han, S., Hauff, C., Zuccon, G., Zhang, Y
Thomas, P., Spielman, S., Craswell, N., Mitra, B.: Large language models can accurately predict searcher preferences. In: Yang, G.H., Wang, H., Han, S., Hauff, C., Zuccon, G., Zhang, Y. (eds.) Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SI- GIR 2024, Washington DC, USA, July 14-18, 2024....
-
[41]
Upadhyay, S., Pradeep, R., Thakur, N., Campos, D., Craswell, N., Sobo- roff, I., Dang, H.T., Lin, J.: A large-scale study of relevance assessments with large language models: An initial look. CoRRabs/2411.08275(2024). https://doi.org/10.48550/ARXIV.2411.08275
-
[42]
Upadhyay, S., Pradeep, R., Thakur, N., Craswell, N., Lin, J.: UMBRELA: um- brela is the (open-source reproduction of the) bing relevance assessor. CoRR abs/2406.06519(2024). https://doi.org/10.48550/ARXIV.2406.06519
-
[43]
In: Kamps, J., Kanoulas, E., de Rijke, M., Fang, H., Yilmaz, E
Urbano, J., Marrero, M.: The treatment of ties in AP correlation. In: Kamps, J., Kanoulas, E., de Rijke, M., Fang, H., Yilmaz, E. (eds.) Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR 2017, Amsterdam, The Netherlands, October 1-4, 2017. pp. 321–324. ACM (2017). https://doi.org/10.1145/3121050.3121106
-
[44]
In: Voorhees, E.M., Buckland, L.P
Voorhees, E.M.: Overview of the TREC 2004 robust track. In: Voorhees, E.M., Buckland, L.P. (eds.) Proceedings of the Thirteenth Text REtrieval Conference, TREC 2004, Gaithersburg, Maryland, USA, November 16-19, 2004. NIST Special Publication, vol. 500-261. National Institute of Standards and Technology (NIST) (2004), http://trec.nist.gov/pubs/trec13/paper...
work page 2004
-
[45]
Voorhees, E.M.: The evolution of cranfield. In: Ferro, N., Peters, C. (eds.) Informa- tion Retrieval Evaluation in a Changing World - Lessons Learned from 20 Years of CLEF, The Information Retrieval Series, vol. 41, pp. 45–69. Springer (2019). https://doi.org/10.1007/978-3-030-22948-1_2
-
[46]
Voorhees, E.M., Craswell, N., Lin, J.: Too many relevants: Whither cranfield test collections? In: Amigó, E., Castells, P., Gonzalo, J., Carterette, B., Culpepper, J.S., Kazai, G. (eds.) SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15,
-
[47]
pp. 2970–2980. ACM (2022). https://doi.org/10.1145/3477495.3531728
-
[48]
Voorhees, E.M., Harman, D.K.: TREC: Experiment and Evaluation in Information Retrieval (Digital Libraries and Electronic Publishing). The MIT Press (2005)
work page 2005
-
[49]
Webber, W., Moffat, A., Zobel, J.: A similarity measure for in- definite rankings. ACM Trans. Inf. Syst.28(4), 20:1–20:38 (2010). https://doi.org/10.1145/1852102.1852106
-
[50]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q., Men, R....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[51]
In: Myaeng, S., Oard, D.W., Sebastiani, F., Chua, T., Leong, M
Yilmaz, E., Aslam, J.A., Robertson, S.: A new rank correlation coefficient for information retrieval. In: Myaeng, S., Oard, D.W., Sebastiani, F., Chua, T., Leong, M. (eds.) Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2008, Singapore, July 20-24, 2008. pp. 587–594. ACM (2008)...
-
[52]
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with BERT. In: 8th International Conference on Learning Repre- sentations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net (2020), https://openreview.net/forum?id=SkeHuCVFDr
work page 2020
-
[53]
In: Oh, A., Naumann, T., Glober- son, A., Saenko, K., Hardt, M., Levine, S
Zheng, L., Chiang, W., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging llm-as-a- judge with mt-bench and chatbot arena. In: Oh, A., Naumann, T., Glober- son, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Infor- mation Processing Systems 36: Annual Conference o...
work page 2023
-
[54]
Zobel, J.: How reliable are the results of large-scale information retrieval experiments? In: Croft, W.B., Moffat, A., van Rijsbergen, C.J., Wilkinson, R., Zobel, J. (eds.) SIGIR ’98: Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Re- trieval, August 24-28 1998, Melbourne, Australia. pp. 307–31...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.