Recognition: 3 theorem links
· Lean Theorem3D-Fixer: Coarse-to-Fine In-place Completion for 3D Scenes from a Single Image
Pith reviewed 2026-05-10 19:11 UTC · model grok-4.3
The pith
3D-Fixer completes 3D objects in their original positions from a single image by conditioning on partial visible geometry without separate pose alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
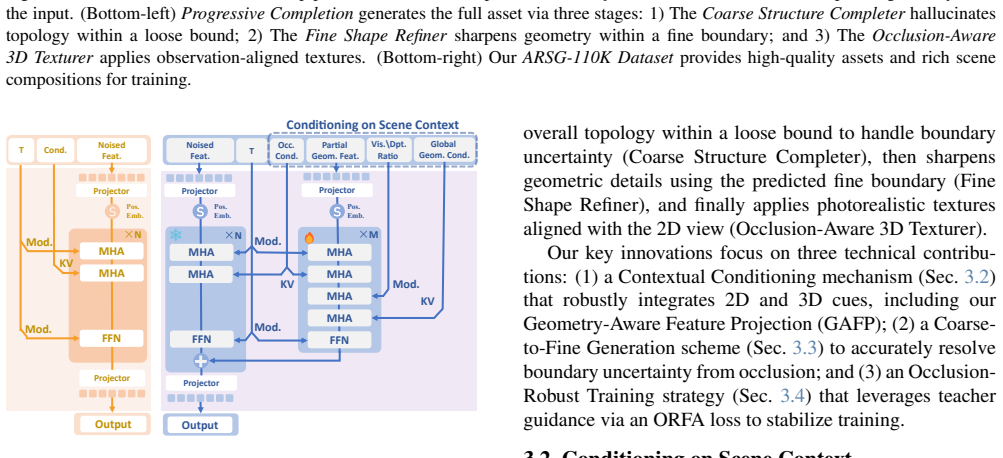
3D-Fixer extends 3D object generative priors to generate complete 3D assets conditioned on the partially visible point cloud at the original locations, which are cropped from the fragmented geometry obtained from geometry estimation methods. Unlike prior works that require explicit pose alignment, 3D-Fixer uses fragmented geometry as a spatial anchor to preserve layout fidelity. At its core, a coarse-to-fine generation scheme resolves boundary ambiguity under occlusion, supported by a dual-branch conditioning network and an Occlusion-Robust Feature Alignment strategy for stable training.
What carries the argument
In-place completion of 3D assets conditioned directly on partial point clouds from geometry estimates, using the visible fragments as fixed spatial anchors.
If this is right
- The method produces higher geometric accuracy than previous feed-forward and per-instance approaches while retaining the speed of diffusion-based generation.
- The coarse-to-fine process with dual-branch conditioning and occlusion-robust alignment reduces boundary errors caused by hidden surfaces.
- The released ARSG-110K dataset of over 110K scenes supplies the scale needed to train in-place completion models at scene level.
- No explicit 6DoF pose optimization step is required after initial geometry estimation.
Where Pith is reading between the lines
- Improving the front-end geometry estimator would immediately raise the quality of downstream completions since the partial clouds serve as the only layout reference.
- The same anchoring idea could extend to video inputs by accumulating visible points across frames to reduce occlusion effects further.
- Because the approach avoids global pose search, it may integrate more readily into real-time pipelines that need consistent 3D output from streaming images.
Load-bearing premise
Fragmented geometry from existing estimation methods supplies a reliable enough spatial anchor to keep the completed objects in correct layout positions.
What would settle it
Run 3D-Fixer with the partial point cloud conditioning removed or replaced by random anchors and measure whether layout fidelity drops to match or fall below pose-optimized baselines on the same test scenes.
Figures









read the original abstract
Compositional 3D scene generation from a single view requires the simultaneous recovery of scene layout and 3D assets. Existing approaches mainly fall into two categories: feed-forward generation methods and per-instance generation methods. The former directly predict 3D assets with explicit 6DoF poses through efficient network inference, but they generalize poorly to complex scenes. The latter improve generalization through a divide-and-conquer strategy, but suffer from time-consuming pose optimization. To bridge this gap, we introduce 3D-Fixer, a novel in-place completion paradigm. Specifically, 3D-Fixer extends 3D object generative priors to generate complete 3D assets conditioned on the partially visible point cloud at the original locations, which are cropped from the fragmented geometry obtained from the geometry estimation methods. Unlike prior works that require explicit pose alignment, 3D-Fixer uses fragmented geometry as a spatial anchor to preserve layout fidelity. At its core, we propose a coarse-to-fine generation scheme to resolve boundary ambiguity under occlusion, supported by a dual-branch conditioning network and an Occlusion-Robust Feature Alignment (ORFA) strategy for stable training. Furthermore, to address the data scarcity bottleneck, we present ARSG-110K, the largest scene-level dataset to date, comprising over 110K diverse scenes and 3M annotated images with high-fidelity 3D ground truth. Extensive experiments show that 3D-Fixer achieves state-of-the-art geometric accuracy, which significantly outperforms baselines such as MIDI and Gen3DSR, while maintaining the efficiency of the diffusion process. Code and data will be publicly available at https://zx-yin.github.io/3dfixer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 3D-Fixer, a coarse-to-fine in-place completion method for compositional 3D scene generation from a single image. It extends 3D object generative priors by conditioning on partially visible point clouds cropped from fragmented geometry obtained via existing estimators, using these fragments as a spatial anchor at original locations to preserve layout fidelity without explicit 6DoF pose optimization. The approach features a dual-branch conditioning network, an Occlusion-Robust Feature Alignment (ORFA) strategy, and a new ARSG-110K dataset comprising over 110K scenes and 3M images with high-fidelity 3D ground truth. The central claim is that this yields state-of-the-art geometric accuracy, significantly outperforming baselines such as MIDI and Gen3DSR, while retaining the efficiency of the diffusion process.
Significance. If the robustness and quantitative claims hold, the work offers a practical bridge between efficient feed-forward generation and generalizable per-instance methods, potentially improving scalability for complex scenes. The scale of the ARSG-110K dataset with annotated high-fidelity ground truth constitutes a concrete resource contribution that could support future benchmarking and training in scene-level 3D generation.
major comments (2)
- [Section 3.2] Section 3.2 and Figure 3: The method conditions the diffusion prior directly on the partial point cloud at original locations without pose alignment, relying on the fragmented geometry as a spatial anchor. No ablation quantifies sensitivity to realistic noise levels in these input fragments (e.g., depth estimation artifacts or incomplete surfaces). If anchor deviation exceeds the receptive field of the dual-branch conditioner, the generative prior may produce locally plausible geometry while violating global layout fidelity—the precise failure mode claimed to be avoided versus explicit pose baselines.
- [Abstract] Abstract and experimental sections: The assertion of state-of-the-art geometric accuracy with significant outperformance over MIDI and Gen3DSR is presented without any numerical metrics, error analysis, dataset splits, or evaluation protocol details. Standard quantitative comparisons (e.g., Chamfer distance, scene-level IoU, or layout consistency) with statistical reporting are required to substantiate the central claim.
minor comments (2)
- Clarify the exact input/output dimensions and training objectives for the dual-branch conditioner and ORFA module with pseudocode or an expanded equation set.
- Provide details on the construction, annotation pipeline, and train/val/test splits of the ARSG-110K dataset to enable reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important aspects of robustness and quantitative rigor that we will address to strengthen the manuscript. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 and Figure 3: The method conditions the diffusion prior directly on the partial point cloud at original locations without pose alignment, relying on the fragmented geometry as a spatial anchor. No ablation quantifies sensitivity to realistic noise levels in these input fragments (e.g., depth estimation artifacts or incomplete surfaces). If anchor deviation exceeds the receptive field of the dual-branch conditioner, the generative prior may produce locally plausible geometry while violating global layout fidelity—the precise failure mode claimed to be avoided versus explicit pose baselines.
Authors: We agree that quantifying sensitivity to realistic noise in the input fragments is important for validating the reliability of the in-place spatial anchoring approach. Although the ORFA strategy and dual-branch conditioner are designed to promote robustness under partial and occluded observations, an explicit ablation on noise levels (e.g., depth artifacts and surface incompleteness) was not included. In the revised manuscript we will add this ablation to Section 3.2, perturbing the cropped point clouds with controlled noise and incompleteness levels, and report effects on both local geometry and global layout fidelity using metrics such as Chamfer distance and layout consistency. revision: yes
-
Referee: [Abstract] Abstract and experimental sections: The assertion of state-of-the-art geometric accuracy with significant outperformance over MIDI and Gen3DSR is presented without any numerical metrics, error analysis, dataset splits, or evaluation protocol details. Standard quantitative comparisons (e.g., Chamfer distance, scene-level IoU, or layout consistency) with statistical reporting are required to substantiate the central claim.
Authors: We acknowledge that the abstract and experimental presentation would benefit from greater specificity. We will revise the abstract to include key numerical results (e.g., Chamfer distance and IoU improvements over MIDI and Gen3DSR). In addition, we will expand the experimental sections to provide explicit details on dataset splits, evaluation protocols, error analysis, and statistical reporting for all quantitative comparisons, ensuring the state-of-the-art claims are fully supported by the presented evidence. revision: yes
Circularity Check
No significant circularity; method and claims are self-contained
full rationale
The paper introduces a new in-place completion paradigm (3D-Fixer) that conditions existing 3D object generative priors on cropped partial point clouds from upstream geometry estimators, augmented by a proposed coarse-to-fine scheme, dual-branch conditioner, and ORFA strategy. It also contributes a new dataset (ARSG-110K). No equations, fitted parameters, or central claims reduce by construction to self-defined quantities, self-citations, or renamed prior results. The derivation chain relies on external priors and empirical comparisons to independent baselines (MIDI, Gen3DSR), with no load-bearing self-referential steps or uniqueness theorems imported from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption 3D object generative priors can be extended to generate complete assets conditioned on partially visible point clouds at original locations
- domain assumption Fragmented geometry from estimation methods provides a sufficient spatial anchor to preserve layout fidelity
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear3D-Fixer extends 3D object generative priors to generate complete 3D assets conditioned on the partially visible point cloud at the original locations... dual-branch conditioning network and an Occlusion-Robust Feature Alignment (ORFA) strategy
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearcoarse-to-fine generation scheme... expanded bounding box B_exp... Fine Shape Refiner
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearJcost is never mentioned; geometry estimation priors are treated as black-box inputs
Reference graph
Works this paper leans on
-
[1]
Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view
Andreea Ardelean, Mert ¨Ozer, and Bernhard Egger. Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view. In2025 International Con- ference on 3D Vision (3DV), pages 616–626. IEEE, 2025. 2, 3, 6, 7, 8
2025
-
[2]
Scan2cad: Learning cad model alignment in rgb-d scans
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X Chang, and Matthias Nießner. Scan2cad: Learning cad model alignment in rgb-d scans. InProceed- ings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 2614–2623, 2019. 5
2019
-
[3]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama ˜AG ¸ l Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024. 2, 3, 1
work page internal anchor Pith review arXiv 2024
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015. 3, 5
work page internal anchor Pith review arXiv 2015
-
[5]
Single-view 3d scene reconstruc- tion with high-fidelity shape and texture
Yixin Chen, Junfeng Ni, Nan Jiang, Yaowei Zhang, Yixin Zhu, and Siyuan Huang. Single-view 3d scene reconstruc- tion with high-fidelity shape and texture. In2024 Interna- tional Conference on 3D Vision (3DV), pages 1456–1467. IEEE, 2024. 2, 3, 6
2024
-
[6]
Buol: A bottom-up framework with occupancy-aware lifting for panoptic 3d scene reconstruction from a single image
Tao Chu, Pan Zhang, Qiong Liu, and Jiaqi Wang. Buol: A bottom-up framework with occupancy-aware lifting for panoptic 3d scene reconstruction from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 4937–4946, 2023. 2
2023
-
[7]
Abo: Dataset and benchmarks for real-world 3d object un- derstanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object un- derstanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21126– 21136, 2022. 3, 5
2022
-
[8]
Blender Foundation, Stichting Blender Foundation, Amsterdam, 2025
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2025. 2
2025
-
[9]
Panoptic 3d scene reconstruction from a single rgb image
Manuel Dahnert, Ji Hou, Matthias Nießner, and Angela Dai. Panoptic 3d scene reconstruction from a single rgb image. Advances in Neural Information Processing Systems, 34: 8282–8293, 2021. 2, 3, 6
2021
-
[10]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 5, 6, 7, 2
2017
-
[11]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023. 3, 5
2023
-
[12]
Vggt- long: Chunk it, loop it, align it – pushing vggt’s limits on kilometer-scale long rgb sequences, 2025
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt- long: Chunk it, loop it, align it – pushing vggt’s limits on kilometer-scale long rgb sequences, 2025. 3
2025
-
[13]
3d-front: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Bin- qiang Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 10933–10942,
-
[14]
3d-future: 3d fur- niture shape with texture.International Journal of Computer Vision, 129(12):3313–3337, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d fur- niture shape with texture.International Journal of Computer Vision, 129(12):3313–3337, 2021. 2, 5
2021
-
[15]
Diffcad: Weakly-supervised probabilistic cad model retrieval and alignment from an rgb image.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024
Daoyi Gao, D ´avid Rozenberszki, Stefan Leutenegger, and Angela Dai. Diffcad: Weakly-supervised probabilistic cad model retrieval and alignment from an rgb image.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024. 2, 3, 6
2024
-
[16]
Behavior vision suite: Customizable dataset generation via simulation
Yunhao Ge, Yihe Tang, Jiashu Xu, Cem Gokmen, Chengshu Li, Wensi Ai, Benjamin Jose Martinez, Arman Aydin, Mona Anvari, Ayush K Chakravarthy, et al. Behavior vision suite: Customizable dataset generation via simulation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22401–22412, 2024. 5
2024
-
[17]
Learn- ing 3d object shape and layout without 3d supervision
Georgia Gkioxari, Nikhila Ravi, and Justin Johnson. Learn- ing 3d object shape and layout without 3d supervision. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 1695–1704, 2022. 2
2022
-
[18]
Roca: Ro- bust cad model retrieval and alignment from a single image
Can G ¨umeli, Angela Dai, and Matthias Nießner. Roca: Ro- bust cad model retrieval and alignment from a single image. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4022–4031, 2022. 2
2022
-
[19]
Reparo: Compositional 3d assets generation with differen- tiable 3d layout alignment
Haonan Han, Rui Yang, Huan Liao, Jiankai Xing, Zunnan Xu, Xiaoming Yu, Junwei Zha, Xiu Li, and Wanhua Li. Reparo: Compositional 3d assets generation with differen- tiable 3d layout alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25367– 25377, 2025. 3, 6
2025
-
[20]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
2020
-
[21]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23646–23657, 2025. 2, 3, 6
2025
-
[22]
Hamid Izadinia, Qi Shan, and Steven M Seitz. Im2cad. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5134–5143, 2017. 2
2017
-
[23]
Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal naviga- tion
Mukul Khanna, Yongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, 9 Eric Undersander, Angel X Chang, and Manolis Savva. Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal naviga- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Patte...
-
[24]
Mask2cad: 3d shape prediction by learning to segment and retrieve
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. Mask2cad: 3d shape prediction by learning to segment and retrieve. InEuropean Conference on Computer Vision, pages 260–277. Springer, 2020. 2
2020
-
[25]
Patch2cad: Patchwise embedding learning for in-the- wild shape retrieval from a single image
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. Patch2cad: Patchwise embedding learning for in-the- wild shape retrieval from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12589–12599, 2021
2021
-
[26]
Florian Langer, Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. Sparc: Sparse render-and-compare for cad model alignment in a single rgb image.arXiv preprint arXiv:2210.01044, 2022. 2
-
[27]
Behavior-1k: A benchmark for embodied ai with 1,000 ev- eryday activities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart ´ın-Mart´ın, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 ev- eryday activities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023. 5
2023
-
[28]
Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets, 2025
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, et al. Step1x-3d: Towards high-fidelity and con- trollable generation of textured 3d assets.arXiv preprint arXiv:2505.07747, 2025. 3
-
[29]
Openrooms: An open framework for photorealistic indoor scene datasets
Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu-Ying Yeh, Rui Zhu, Nitesh Gun- davarapu, Jia Shi, et al. Openrooms: An open framework for photorealistic indoor scene datasets. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7190–7199, 2021. 5
2021
-
[30]
Objaverse++: Curated 3d object dataset with quality annotations
Chendi Lin, Heshan Liu, Qunshu Lin, Zachary Bright, Shi- tao Tang, Yihui He, Minghao Liu, Ling Zhu, and Cindy Le. Objaverse++: Curated 3d object dataset with quality annota- tions.arXiv preprint arXiv:2504.07334, 2025. 3, 5
-
[31]
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, and Katerina Fragkiadaki. Partcrafter: Structured 3d mesh generation via compo- sitional latent diffusion transformers.arXiv preprint arXiv:2506.05573, 2025. 2, 3
-
[32]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling, 2023. 3
2023
-
[33]
Towards high-fidelity single-view holistic reconstruction of indoor scenes
Haolin Liu, Yujian Zheng, Guanying Chen, Shuguang Cui, and Xiaoguang Han. Towards high-fidelity single-view holistic reconstruction of indoor scenes. InEuropean Con- ference on Computer Vision, pages 429–446. Springer, 2022. 2, 3, 6
2022
-
[34]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Cad-estate: Large-scale cad model annota- tion in rgb videos
Kevis-Kokitsi Maninis, Stefan Popov, Matthias Nießner, and Vittorio Ferrari. Cad-estate: Large-scale cad model annota- tion in rgb videos. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 20189–20199,
-
[36]
arXiv preprint arXiv:2508.15769 (2025)
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Sce- negen: Single-image 3d scene generation in one feedforward pass.arXiv preprint arXiv:2508.15769, 2025. 2, 3
-
[37]
Total3dunderstanding: Joint lay- out, object pose and mesh reconstruction for indoor scenes from a single image
Yinyu Nie, Xiaoguang Han, Shihui Guo, Yujian Zheng, Jian Chang, and Jian Jun Zhang. Total3dunderstanding: Joint lay- out, object pose and mesh reconstruction for indoor scenes from a single image. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 55–64, 2020. 2, 3, 6
2020
-
[38]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3, 5, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Atiss: Autoregres- sive transformers for indoor scene synthesis.Advances in Neural Information Processing Systems, 34:12013–12026,
Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. Atiss: Autoregres- sive transformers for indoor scene synthesis.Advances in Neural Information Processing Systems, 34:12013–12026,
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[41]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
-
[43]
Wayfair’s 3d model api.https : //www.aboutwayfair.com/tech- innovation/ wayfairs- 3d- model- api, 2016
Shrenik Sadalgi. Wayfair’s 3d model api.https : //www.aboutwayfair.com/tech- innovation/ wayfairs- 3d- model- api, 2016. [Online; accessed 15-Nov-2023]. 5
2016
-
[44]
Stefan Stojanov, Anh Thai, and James M. Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias
-
[45]
Depth anything at any condition.arXiv preprint arXiv:2507.01634,
Boyuan Sun, Modi Jin, Bowen Yin, and Qibin Hou. Depth anything at any condition.arXiv preprint arXiv:2507.01634,
-
[46]
Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation, 2024
Tencent Hunyuan3D Team. Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation, 2024. 3
2024
-
[47]
Hunyuan3d 2.0: Scaling diffu- sion models for high resolution textured 3d assets generation, 2025
Tencent Hunyuan3D Team. Hunyuan3d 2.0: Scaling diffu- sion models for high resolution textured 3d assets generation, 2025
2025
-
[48]
Hunyuan3d 2.5: Towards high- fidelity 3d assets generation with ultimate details, 2025
Tencent Hunyuan3D Team. Hunyuan3d 2.5: Towards high- fidelity 3d assets generation with ultimate details, 2025. 3
2025
-
[49]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the 10 Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 3, 4, 1
2025
-
[50]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5261–5271, 2025
2025
-
[51]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546,
work page internal anchor Pith review arXiv
-
[52]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697– 20709, 2024
2024
-
[53]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chun- hua Shen, and Tong He. pi3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[54]
Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Jian Yang, et al. Representation entanglement for genera- tion: Training diffusion transformers is much easier than you think.arXiv preprint arXiv:2507.01467, 2025. 5
-
[55]
R3ds: Reality-linked 3d scenes for panoramic scene understanding
Qirui Wu, Sonia Raychaudhuri, Daniel Ritchie, Manolis Savva, and Angel X Chang. R3ds: Reality-linked 3d scenes for panoramic scene understanding. InEuropean Conference on Computer Vision, pages 452–468. Springer, 2024. 5
2024
-
[56]
Direct3d: Scal- able image-to-3d generation via 3d latent diffusion trans- former.Advances in Neural Information Processing Systems, 37:121859–121881, 2024
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3d: Scal- able image-to-3d generation via 3d latent diffusion trans- former.Advances in Neural Information Processing Systems, 37:121859–121881, 2024. 3
2024
-
[57]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21469–21480, 2025. 2, 3, 4, 5, 1
2025
-
[58]
Psdr-room: Single photo to scene using differentiable rendering
Kai Yan, Fujun Luan, Milo ˇs Ha ˇsan, Thibault Groueix, Valentin Deschaintre, and Shuang Zhao. Psdr-room: Single photo to scene using differentiable rendering. InSIGGRAPH Asia 2023 Conference Papers, pages 1–11, 2023. 2, 3
2023
-
[59]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024. 2
2024
-
[60]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 2, 3, 1
2024
-
[61]
Cast: Component-aligned 3d scene reconstruction from an rgb image.ACM Transactions on Graphics (TOG), 44(4): 1–19, 2025
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qix- uan Zhang, Lan Xu, Wei Yang, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruction from an rgb image.ACM Transactions on Graphics (TOG), 44(4): 1–19, 2025. 2, 3
2025
-
[62]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF international conference on computer vision, pages 9043–9053, 2023. 2
2023
-
[63]
Metascenes: Towards automated replica creation for real-world 3d scans
Huangyue Yu, Baoxiong Jia, Yixin Chen, Yandan Yang, Puhao Li, Rongpeng Su, Jiaxin Li, Qing Li, Wei Liang, Song-Chun Zhu, et al. Metascenes: Towards automated replica creation for real-world 3d scans. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1667–1679, 2025. 2, 5, 6, 8
2025
-
[64]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffu- sion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024. 5
work page internal anchor Pith review arXiv 2024
-
[65]
3dshape2vecset: A 3d shape representation for neu- ral fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neu- ral fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023. 3
2023
-
[66]
Holistic 3d scene un- derstanding from a single image with implicit representation
Cheng Zhang, Zhaopeng Cui, Yinda Zhang, Bing Zeng, Marc Pollefeys, and Shuaicheng Liu. Holistic 3d scene un- derstanding from a single image with implicit representation. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 8833–8842, 2021. 2
2021
-
[67]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2
2023
-
[68]
Uni-3d: A universal model for panoptic 3d scene reconstruc- tion
Xiang Zhang, Zeyuan Chen, Fangyin Wei, and Zhuowen Tu. Uni-3d: A universal model for panoptic 3d scene reconstruc- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 9256–9266, 2023. 2 11 3D-Fixer: Coarse-to-Fine In-place Completion for 3D Scenes from a Single Image Supplementary Material
2023
-
[69]
Implementation details Base model.Our method builds on the TRELLIS [57] framework, which is a two-stage rectified flow generation method, where the first stage is a DiT [40] model that gen- erates the sparse voxel structure in the latent space, and the second stage is a DiT-style model based on the sparse coor- dinates predicted in stage one to generate t...
-
[70]
Furthermore, we introduce three designs to improve the model’s ability
Robustness to input noise Tolerance to initial distortion.Although the initial geome- tries are distorted, our ARSG-110K contains massive high- quality 3D GT as supervision samples, therefore, 3D-Fixer can learn how to generate plausible 3D assets. Furthermore, we introduce three designs to improve the model’s ability. First, the ORFA strategy (Sec. 3.5 i...
-
[71]
Texture quality To access the quality of the synthesized texture, we sep- arately render three views for the visible (V) and unseen (U) region on our testset, and report FID and CLIP score in Tab. 4b. These metrics demonstrate the quality and seman- tic consistency of the generated textures
-
[72]
As in Fig
More results In this section and in our Supplementary Video, we present diverse visualizations across a variety of scenarios. As in Fig. 8, our approach produces high-quality 3D assets and accurately reconstructs the spatial layout of the scene. In contrast, Gen3DSR generates blurry geometric structures, while MIDI fails to recover an accurate spatial lay...
-
[73]
To improve rendering photorealism, we additionally collect over 1K HDR maps and 5K material textures from BlenderKit, a community platform for sharing 3D assets
Procedural scene generation To procedurally construct the ARSG-110K dataset, we use a subset of 180K high-quality 3D object assets from TRELLIS-500K [57]. To improve rendering photorealism, we additionally collect over 1K HDR maps and 5K material textures from BlenderKit, a community platform for sharing 3D assets. All scenes are rendered using the Blende...
-
[74]
We believe an important fu- ture direction is to explore unified frameworks to simulta- neously estimate the scene geometry and generate the com- plete 3D instances in the scene
Limitations and Future Works As our method performs in-place completion using geometry-based cues for scene generation, the accuracy of the recovered layout inherently depends on the quality of the initial estimated geometry. We believe an important fu- ture direction is to explore unified frameworks to simulta- neously estimate the scene geometry and gen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.