Recognition: no theorem link
BoxComm: Benchmarking Category-Aware Commentary Generation and Narration Rhythm in Boxing
Pith reviewed 2026-05-10 19:04 UTC · model grok-4.3
The pith
Multimodal models struggle with category-aware boxing commentary and narration rhythm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that existing multimodal large language models have difficulty generating commentary that matches a requested category or that follows professional rhythm patterns in boxing videos. Their experiments on the BoxComm dataset establish this gap, and they show that supplying the model with cues from automatically detected punches leads to better results on both the category and rhythm measures.
What carries the argument
The category taxonomy for commentary sentences and the rhythm assessment that tracks pacing and type balance across continuous video segments.
If this is right
- Models that receive punch event cues generate better commentary on the proposed tests.
- Prior benchmarks missed the category and rhythm dimensions that matter for combat sports.
- Professional commentary competence includes both type accuracy and appropriate temporal distribution.
- Perceiving subtle fleeting events is essential for effective combat sports commentary generation.
Where Pith is reading between the lines
- Similar benchmarks could be built for other individual or combat sports to test the same skills.
- The event cue idea might transfer to any video task where brief actions carry high meaning.
- Automated systems based on this could help create accessible descriptions for visually impaired viewers of boxing.
- Future work might combine this with live video streams for real-time commentary assistance.
Load-bearing premise
The taxonomy and rhythm measure correctly represent what professional boxing commentators do well.
What would settle it
An experiment showing no performance difference between the basic models and the punch-event version on the category generation or rhythm tasks.
Figures





read the original abstract
Recent multimodal large language models (MLLMs) have shown strong capabilities in general video understanding, driving growing interest in automatic sports commentary generation. However, existing benchmarks for this task focus exclusively on team sports such as soccer and basketball, leaving combat sports entirely unexplored. Notably, combat sports present distinct challenges: critical actions unfold within milliseconds with visually subtle yet semantically decisive differences, and professional commentary contains a substantially higher proportion of tactical analysis compared to team sports. In this paper, we present BoxComm, a large-scale dataset comprising 445 World Boxing Championship match videos with over 52K commentary sentences from professional broadcasts. We propose a structured commentary taxonomy that categorizes each sentence into play-by-play, tactical, or contextual, providing the first category-level annotation for sports commentary benchmarks. Building on this taxonomy, we introduce two novel and complementary evaluations tailored to sports commentary generation: (1) category-conditioned generation, which evaluates whether models can produce accurate commentary of a specified type given video context; and (2) commentary rhythm assessment, which measures whether freely generated commentary exhibits appropriate temporal pacing and type distribution over continuous video segments, capturing a dimension of commentary competence that prior benchmarks have not addressed. Experiments on multiple state-of-the-art MLLMs reveal that current models struggle on both evaluations. We further propose EIC-Gen, an improved baseline incorporating detected punch events to supply structured action cues, yielding consistent gains and highlighting the importance of perceiving fleeting and subtle events for combat sports commentary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BoxComm, a dataset of 445 World Boxing Championship videos containing over 52K professionally annotated commentary sentences. It defines a three-way taxonomy (play-by-play, tactical, contextual) and proposes two new evaluations: category-conditioned generation (testing type-specific output given video) and commentary rhythm assessment (measuring temporal pacing and type distribution over continuous segments). Experiments show that current MLLMs underperform on both tasks; the authors introduce EIC-Gen, an enhanced baseline that injects detected punch events as structured cues, reporting consistent gains and arguing that perception of fleeting actions is critical for combat-sports narration.
Significance. If the taxonomy and rhythm metrics prove to be faithful proxies for professional commentary quality, the work would fill a clear gap by extending sports-commentary benchmarks to combat sports and by emphasizing millisecond-scale event perception. The large-scale dataset and the EIC-Gen ablation supply concrete starting points for future MLLM research on fine-grained action narration. The paper earns credit for releasing a new annotated corpus and for designing evaluations that go beyond standard captioning metrics.
major comments (3)
- [§3] §3 (Taxonomy): No inter-annotator agreement, expert validation, or correlation with professional commentary quality is reported for the play-by-play/tactical/contextual partition. Because both the category-conditioned generation task and the rhythm assessment rest directly on these labels, the absence of such validation leaves open whether performance gaps reflect model limitations or artifacts of the chosen taxonomy.
- [§4.2] §4.2 (Rhythm assessment): The rhythm metric is defined via temporal pacing and type-distribution statistics, yet no human correlation study or comparison against expert-rated commentary quality is provided. This is load-bearing for the central claim that current models “struggle on a dimension of commentary competence” and that EIC-Gen improves it.
- [§5] §5 (Experiments): The manuscript omits dataset splits, annotation guidelines, error bars, and statistical significance tests for the reported gains of EIC-Gen over baselines. Without these, the quantitative support for the claim that “detected punch events supply structured action cues” remains limited.
minor comments (2)
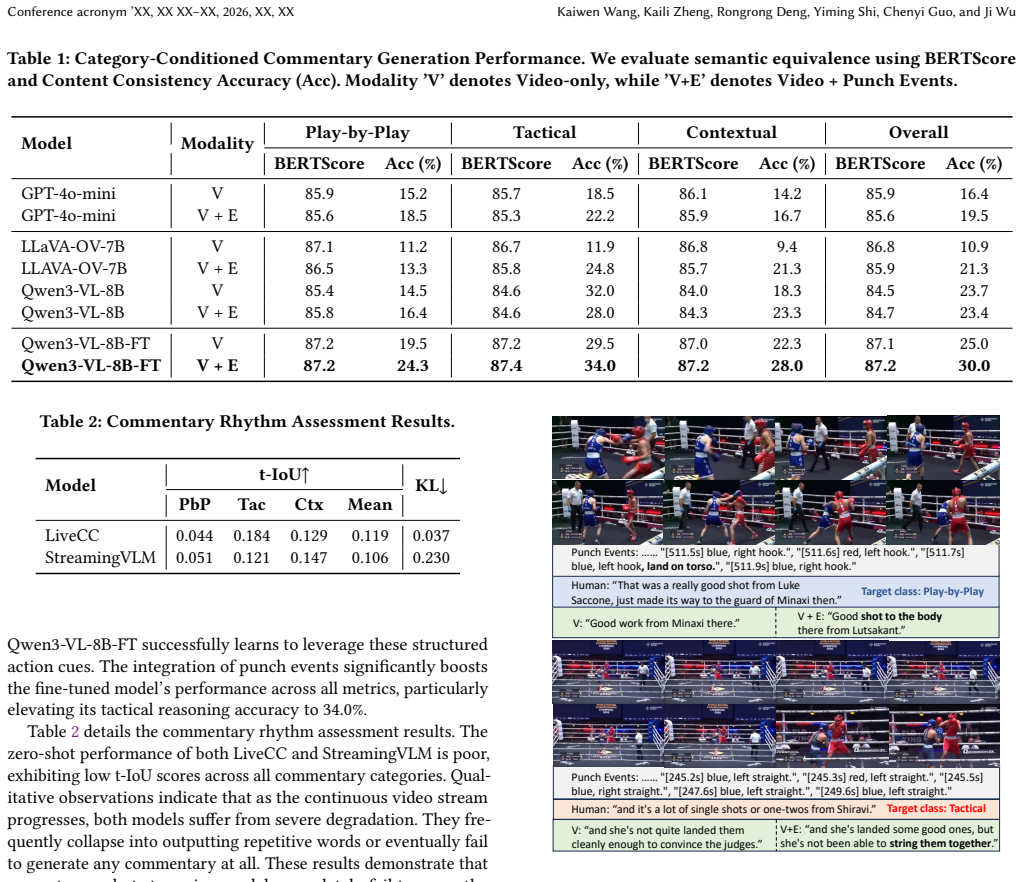
- [Table 1] Table 1 and §3.1: The breakdown of the 52K sentences across the three categories is not tabulated; adding these counts would clarify the class balance and support reproducibility.
- [Figure 2] Figure 2: The example video frames and corresponding commentary sentences would benefit from explicit category labels and timestamps to illustrate the rhythm metric.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of validation and experimental rigor that will strengthen the manuscript. We address each major comment below and will make the corresponding revisions.
read point-by-point responses
-
Referee: [§3] §3 (Taxonomy): No inter-annotator agreement, expert validation, or correlation with professional commentary quality is reported for the play-by-play/tactical/contextual partition. Because both the category-conditioned generation task and the rhythm assessment rest directly on these labels, the absence of such validation leaves open whether performance gaps reflect model limitations or artifacts of the chosen taxonomy.
Authors: We agree that validation of the taxonomy is critical given its foundational role. The initial submission omitted these details to prioritize the benchmark introduction and evaluations. We will revise §3 to report inter-annotator agreement computed during the annotation process, incorporate expert validation feedback from professional boxing commentators, and add a targeted correlation study linking the taxonomy to expert-rated commentary quality. These changes will be included in the revised manuscript. revision: yes
-
Referee: [§4.2] §4.2 (Rhythm assessment): The rhythm metric is defined via temporal pacing and type-distribution statistics, yet no human correlation study or comparison against expert-rated commentary quality is provided. This is load-bearing for the central claim that current models “struggle on a dimension of commentary competence” and that EIC-Gen improves it.
Authors: We acknowledge that a human correlation study is necessary to establish the rhythm metric as a reliable proxy for commentary quality. We will conduct such a study, in which domain experts rate generated commentaries on pacing and type appropriateness, and report the correlations with our metrics. The study design and results will be added to the revised §4.2. revision: yes
-
Referee: [§5] §5 (Experiments): The manuscript omits dataset splits, annotation guidelines, error bars, and statistical significance tests for the reported gains of EIC-Gen over baselines. Without these, the quantitative support for the claim that “detected punch events supply structured action cues” remains limited.
Authors: We appreciate the referee noting these omissions. We will update the manuscript to explicitly describe the dataset splits, include the full annotation guidelines in an appendix, add error bars to all reported metrics, and perform and report statistical significance tests (e.g., paired t-tests with p-values) for EIC-Gen improvements. These revisions will be made in the updated §5. revision: yes
Circularity Check
No circularity: new dataset, taxonomy, and evaluations are independent contributions.
full rationale
The paper collects a fresh dataset of 445 boxing videos with 52K professional commentary sentences, proposes a three-category taxonomy (play-by-play, tactical, contextual), and defines two new evaluation protocols (category-conditioned generation and rhythm assessment via temporal pacing and type distribution). These elements are introduced as original constructs without any equations, fitted parameters, or self-citations that reduce the central claims (MLLM struggles and EIC-Gen gains) to the inputs by construction. Experiments rely on external MLLMs and event detection rather than self-referential loops, making the derivation chain self-contained against newly gathered data and standard models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Professional broadcast commentary represents the desired output distribution for AI generation models
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. 2025. Llava-onevision- 1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661(2025)
work page internal anchor Pith review arXiv 2025
-
[2]
Peter Andrews, Oda Elise Nordberg, Njål Borch, Frode Guribye, and Morten Fjeld
-
[3]
InProceedings of the 2024 ACM International Conference on Interactive Media Experiences
Designing for automated sports commentary systems. InProceedings of the 2024 ACM International Conference on Interactive Media Experiences. 75–93
2024
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, and Mike Zheng Shou
-
[6]
In Proceedings of the Computer Vision and Pattern Recognition Conference
Livecc: Learning video llm with streaming speech transcription at scale. In Proceedings of the Computer Vision and Pattern Recognition Conference. 29083– 29095
-
[7]
Adrien Deliege, Anthony Cioppa, Silvio Giancola, Meisam J Seikavandi, Jacob V Dueholm, Kamal Nasrollahi, Bernard Ghanem, Thomas B Moeslund, and Marc Van Droogenbroeck. 2021. Soccernet-v2: A dataset and benchmarks for holis- tic understanding of broadcast soccer videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4508–4519
2021
-
[8]
Hayden Faulkner and Anthony Dick. 2017. Tenniset: A dataset for dense fine- grained event recognition, localisation and description. In2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA). IEEE, 1–8
2017
-
[9]
Charles A Ferguson. 1983. Sports announcer talk: Syntactic aspects of register variation.Language in society12, 2 (1983), 153–172
1983
-
[10]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24108–24118
2025
- [11]
-
[12]
Silvio Giancola, Mohieddine Amine, Tarek Dghaily, and Bernard Ghanem. 2018. Soccernet: A scalable dataset for action spotting in soccer videos. InProceedings of the IEEE conference on computer vision and pattern recognition workshops. 1711– 1721
2018
-
[13]
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. 2023. Humans in 4D: Reconstructing and tracking humans with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14783–14794
2023
-
[14]
Xusheng He, Wei Liu, Shanshan Ma, Qian Liu, Chenghao Ma, and Jianlong Wu. 2025. Finebadminton: A multi-level dataset for fine-grained badminton video understanding. InProceedings of the 33rd ACM International Conference on Multimedia. 12776–12783
2025
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Colin Lea, Michael D Flynn, Rene Vidal, Austin Reiter, and Gregory D Hager
-
[18]
Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Temporal convolutional networks for action segmentation and detection. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 156–165
-
[19]
Xiang Li, Yangfan He, Shuaishuai Zu, Zhengyang Li, Tianyu Shi, Yiting Xie, and Kevin Zhang. 2025. Multi-modal large language model with rag strategies in soc- cer commentary generation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 6197–6206
2025
-
[20]
Licensed referees at the 2021 Boxing League, Szczyrk, Poland. 2021. Olympic boxing punch classification video dataset. https://www.kaggle.com/datasets/ piotrstefaskiue/olympic-boxing-punch-classification-video-dataset Dataset of real boxing fight recordings labeled by licensed referees for punch classification tasks
2021
-
[21]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing. 5971–5984
2024
- [22]
-
[23]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-chatgpt: Towards detailed video understanding via large vision and lan- guage models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 12585–12602
2024
-
[24]
Hassan Mkhallati, Anthony Cioppa, Silvio Giancola, Bernard Ghanem, and Marc Van Droogenbroeck. 2023. SoccerNet-caption: Dense video captioning for soccer broadcasts commentaries. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5074–5085
2023
-
[25]
Priyanka Patel and Michael J Black. 2025. Camerahmr: Aligning people with perspective. In2025 International Conference on 3D Vision (3DV). IEEE, 1562–1571
2025
-
[26]
Ji Qi, Jifan Yu, Teng Tu, Kunyu Gao, Yifan Xu, Xinyu Guan, Xiaozhi Wang, Bin Xu, Lei Hou, Juanzi Li, et al. 2023. GOAL: A challenging knowledge-grounded video captioning benchmark for real-time soccer commentary generation. InPro- ceedings of the 32nd ACM international conference on information and knowledge management. 5391–5395
2023
-
[27]
Jiayuan Rao, Haoning Wu, Hao Jiang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2025. Towards universal soccer video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference. 8384–8394
2025
-
[28]
Jiayuan Rao, Haoning Wu, Chang Liu, Yanfeng Wang, and Weidi Xie. 2024. Matchtime: Towards automatic soccer game commentary generation. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing. 1671–1685
2024
- [29]
-
[30]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [31]
-
[32]
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. 2023. Videomae v2: Scaling video masked autoencoders with dual masking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14549–14560
2023
-
[33]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3.5: Ad- vancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Dekun Wu, He Zhao, Xingce Bao, and Richard P Wildes. 2022. Sports video analysis on large-scale data. InEuropean conference on computer vision. Springer, 19–36
2022
-
[35]
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick
-
[36]
https://github.com/facebookresearch/detectron2
Detectron2. https://github.com/facebookresearch/detectron2
- [37]
- [38]
- [39]
- [40]
-
[41]
Fei Yan, Krystian Mikolajczyk, and Josef Kittler. 2016. Generating commentaries for tennis videos. In2016 23rd International Conference on Pattern Recognition (ICPR). IEEE, 2658–2663
2016
-
[42]
Ling You, Wenxuan Huang, Xinni Xie, Xiangyi Wei, Bangyan Li, Shaohui Lin, Yang Li, and Changbo Wang. 2025. Timesoccer: An end-to-end multimodal large language model for soccer commentary generation. InProceedings of the 33rd ACM International Conference on Multimedia. 3418–3427
2025
-
[43]
Benhui Zhang, Junyu Gao, and Yuan Yuan. 2024. A descriptive basketball high- light dataset for automatic commentary generation. InProceedings of the 32nd ACM international conference on multimedia. 10316–10325. Conference acronym ’XX, XX XX–XX, 2026, XX, XX Kaiwen Wang, Kaili Zheng, Rongrong Deng, Yiming Shi, Chenyi Guo, and Ji Wu
2024
-
[44]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demon- strations. 543–553
2023
-
[45]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2024. Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713(2024)
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.