Recognition: no theorem link
Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse
Pith reviewed 2026-05-10 18:46 UTC · model grok-4.3
The pith
Chorus reuses features across similar video generation requests to speed up diffusion transformers by up to 45 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
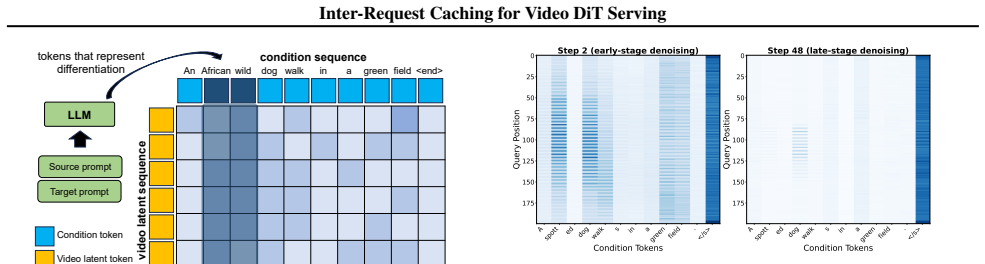
Chorus introduces a three-stage inter-request caching strategy for video DiT models. Stage 1 performs full reuse of latent features from similar prior requests. Stage 2 applies inter-request caching only in selected latent regions during intermediate denoising steps and pairs it with Token-Guided Attention Amplification to preserve semantic alignment with the conditioning prompt. This combination extends safe reuse into later denoising stages where prior intra-request methods stop working.
What carries the argument
Chorus's three-stage inter-request caching strategy, which reuses latent features from similar requests while using token-guided attention amplification to maintain prompt alignment.
If this is right
- Industrial 4-step distilled video models become practical for higher-throughput serving.
- Latency drops for clusters of users who submit prompts with overlapping content.
- Caching decisions can be made at the start of the denoising trajectory rather than only inside one request.
- The method scales the benefit of few-step distillation without requiring further model compression.
Where Pith is reading between the lines
- Prompt embedding similarity could be used to build a shared cache index that decides reuse on the fly.
- The same inter-request pattern may transfer to other iterative generative tasks such as image or 3D synthesis.
- Production deployments would need separate mechanisms to handle user data privacy when storing intermediate latents.
Load-bearing premise
Sufficient similarity exists across independent user requests to enable effective inter-request feature reuse without degrading video quality or semantic alignment with prompts.
What would settle it
Apply Chorus to a collection of video prompts that share little semantic similarity and check whether standard quality metrics such as CLIP prompt alignment or FID scores fall below the no-caching baseline.
Figures








read the original abstract
Video Diffusion Transformer (DiT) models are a dominant approach for high-quality video generation but suffer from high inference cost due to iterative denoising. Existing caching approaches primarily exploit similarity within the diffusion process of a single request to skip redundant denoising steps. In this paper, we introduce Chorus, a caching approach that leverages similarity across requests to accelerate video diffusion model serving. Chorus achieves up to 45\% speedup on industrial 4-step distilled models, where prior intra-request caching approaches are ineffective. Particularly, Chorus employs a three-stage caching strategy along the denoising process. Stage 1 performs full reuse of latent features from similar requests. Stage 2 exploits inter-request caching in specific latent regions during intermediate denoising steps. This stage is combined with Token-Guided Attention Amplification to improve semantic alignment between the generated video and the conditional prompts, thereby extending the applicability of full reuse to later denoising steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Chorus, a three-stage inter-request caching framework for accelerating Video Diffusion Transformer (DiT) serving. Stage 1 performs full latent feature reuse from similar prior requests; Stage 2 enables partial reuse in selected latent regions during intermediate denoising steps, augmented by Token-Guided Attention Amplification to maintain prompt alignment; the system targets industrial 4-step distilled models and reports up to 45% end-to-end speedup where intra-request caching methods become ineffective.
Significance. If the empirical speedups are shown to hold under realistic request traces without quality degradation, the work would represent a meaningful advance in generative-model serving systems. Extending caching from intra-request to inter-request reuse directly addresses the diminishing returns of few-step distillation and could influence production video-generation pipelines. The explicit three-stage design and attention-amplification mechanism are concrete contributions that merit consideration if supported by thorough workload characterization and quality ablations.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): The central 45% speedup claim on 4-step models is predicated on frequent triggering of Stage-1 full reuse, yet the manuscript supplies no quantitative measurement of prompt-embedding or early-latent similarity distributions drawn from production request traces. Without such data (e.g., histograms or CDFs of cosine similarity across independent user prompts), it is impossible to determine whether the reported gains are representative of real serving workloads or an artifact of the chosen evaluation prompts.
- [§3.2] §3.2 (Token-Guided Attention Amplification): The description of how attention amplification mitigates semantic drift in Stage 2 is high-level; the manuscript should provide the precise formulation (e.g., the scaling factor applied to cross-attention weights and its dependence on token similarity) together with an ablation isolating its contribution to both speedup and perceptual quality metrics.
minor comments (1)
- [Abstract] The abstract states concrete speedups but omits any mention of the quality metrics (FVD, CLIP score, human preference) or baseline implementations used; these details should appear in the abstract or a dedicated results table for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of workload characterization and technical clarity that we have addressed through revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): The central 45% speedup claim on 4-step models is predicated on frequent triggering of Stage-1 full reuse, yet the manuscript supplies no quantitative measurement of prompt-embedding or early-latent similarity distributions drawn from production request traces. Without such data (e.g., histograms or CDFs of cosine similarity across independent user prompts), it is impossible to determine whether the reported gains are representative of real serving workloads or an artifact of the chosen evaluation prompts.
Authors: We agree that a quantitative characterization of similarity distributions strengthens the claims. While we lack access to proprietary production traces, our evaluation uses a diverse collection of prompts drawn from public video generation benchmarks that reflect varied real-world usage. In the revised manuscript we have added histograms and CDF plots of cosine similarity for both prompt embeddings and early latents across the full evaluation set. These plots show that a non-trivial fraction of prompt pairs exceed similarity thresholds sufficient for Stage-1 reuse, supporting the reported end-to-end gains. We also include a sensitivity analysis showing how speedup varies with similarity rate, clarifying the conditions under which the 45% figure is achieved. revision: yes
-
Referee: [§3.2] §3.2 (Token-Guided Attention Amplification): The description of how attention amplification mitigates semantic drift in Stage 2 is high-level; the manuscript should provide the precise formulation (e.g., the scaling factor applied to cross-attention weights and its dependence on token similarity) together with an ablation isolating its contribution to both speedup and perceptual quality metrics.
Authors: We have expanded §3.2 with the exact formulation. Token-Guided Attention Amplification scales the cross-attention weights for each token by a factor (1 + γ · sim(token_i, token_j)), where sim is the cosine similarity between token embeddings and γ is a tunable coefficient. The revised section also contains a new ablation study that isolates this component: we report both latency reduction (additional reuse enabled in Stage 2) and quality metrics (CLIP similarity, FID, and human preference scores) with and without amplification. The ablation confirms that the mechanism preserves semantic alignment while contributing measurably to the overall speedup. revision: yes
Circularity Check
No circularity: empirical systems paper with no derivations or self-referential reductions
full rationale
The manuscript presents Chorus as a three-stage inter-request caching system for video DiT serving, with performance claims (e.g., up to 45% speedup on 4-step models) grounded in experimental measurements rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described design. The similarity assumption across requests is stated as an empirical precondition for the approach to apply, not derived from or equivalent to the method itself by construction. This is a standard empirical systems contribution whose central results do not reduce to their own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Feng, L., Zheng, S., Liu, J., Lin, Y ., Zhou, Q., Cai, P., Wang, X., Chen, J., Zou, C., Ma, Y ., et al. Hicache: Training-free acceleration of diffusion models via hermite polynomial- based feature caching.arXiv preprint arXiv:2508.16984,
-
[2]
Sliding window attention training for efficient large language models
URLhttps://arxiv.org/abs/2502.18845. Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 7514–7528,
-
[3]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Liu, F., Zhang, S., Wang, X., Wei, Y ., Qiu, H., Zhao, Y ., Zhang, Y ., Ye, Q., and Wan, F. Timestep embedding tells: It’s time to cache for video diffusion model. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pp. 7353–7363, 2025a. Liu, J., Zou, C., Lyu, Y ., Chen, J., and Zhang, L. From reusing to forecasting: Accelerating di...
-
[6]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
URL https://arxiv.org/abs/ 2401.14159. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pp. 10684–10695,
-
[7]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review arXiv
-
[8]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
URL https://arxiv.org/ abs/2511.22699. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. At- tention is all you need.Advances in neural information processing systems, 30,
work page internal anchor Pith review arXiv
-
[9]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Gonzalez, Jun Zhu, and Jianfei Chen
Zhang, J., Wang, H., Jiang, K., Yang, S., Zheng, K., Xi, H., Wang, Z., Zhu, H., Zhao, M., Stoica, I., Gonzalez, J. E., Zhu, J., and Chen, J. Sla: Beyond sparsity in diffusion transformers via fine-tunable sparse-linear at- tention, 2025a. URL https://arxiv.org/abs/ 2509.24006. Zhang, J., Zheng, K., Jiang, K., Wang, H., Stoica, I., Gon- zalez, J. E., Chen,...
-
[11]
10 Inter-Request Caching for Video DiT Serving A
URL https://arxiv.org/abs/2601.07832. 10 Inter-Request Caching for Video DiT Serving A. More Visual Results A brown bear grazing in a green field (target prompt) A brown horse grazing in a green field (source prompt) Pure Computation NIRV ANA Chorus Chorus with teacache 1.26x 1.46x 2.51x A cow jump on a snowy plain (target prompt) A deer run on a snowy pl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.