Recognition: no theorem link
Beyond Standard Benchmarks: A Systematic Audit of Vision-Language Model's Robustness to Natural Semantic Variation Across Diverse Tasks
Pith reviewed 2026-05-10 20:23 UTC · model grok-4.3
The pith
Robust CLIP models can amplify natural adversarial vulnerabilities while standard CLIP models reduce performance on natural language-induced adversarial examples across multiple vision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
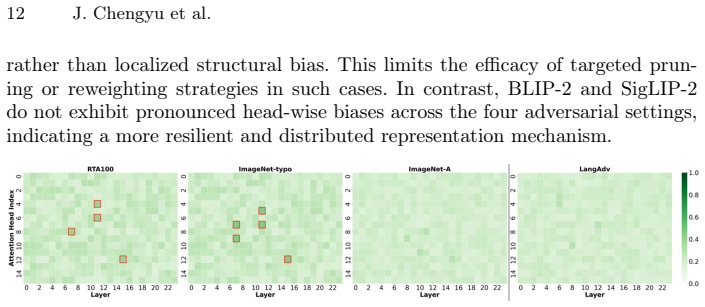
Through evaluation on curated adversarial datasets, the analysis shows that robust CLIP models amplify natural adversarial vulnerabilities, and CLIP models significantly reduce performance for natural language-induced adversarial examples, with interpretable analyses identifying failure modes in zero-shot settings for classification, segmentation, and VQA.
What carries the argument
The systematic evaluation framework assessing VLMs on natural adversarial scenarios for diverse downstream tasks, using metrics on typographic, ImageNet-A, and language-induced datasets.
If this is right
- Robust training of CLIP models may inadvertently heighten risks from certain natural variations.
- CLIP-based systems require additional safeguards against language-induced adversarial inputs.
- Evaluations must extend beyond standard benchmarks to include typographic and semantic attacks for real-world reliability.
- Interpretable failure mode analysis can inform targeted improvements in model robustness.
Where Pith is reading between the lines
- Deployments of these models in applications like autonomous systems or content moderation could face unexpected failures under common real-world perturbations.
- Trade-offs in robustness training suggest exploring hybrid approaches that balance standard and natural adversarial performance.
- Extending this audit to other VLMs or multimodal tasks could reveal broader patterns in vulnerability amplification.
- The findings imply a need for standardized natural adversarial benchmarks in VLM development.
Load-bearing premise
The specific curated datasets chosen accurately represent the kinds of natural semantic variations encountered in everyday use of these models.
What would settle it
Demonstrating through additional testing that robust CLIP models maintain or improve performance on a wider range of natural adversarial examples without amplifying vulnerabilities, or that CLIP does not show significant drops on language-induced cases.
Figures







read the original abstract
Recent advances in vision-language models (VLMs) trained on web-scale image-text pairs have enabled impressive zero-shot transfer across a diverse range of visual tasks. However, comprehensive and independent evaluation beyond standard benchmarks is essential to understand their robustness, limitations, and real-world applicability. This paper presents a systematic evaluation framework for VLMs under natural adversarial scenarios for diverse downstream tasks, which has been overlooked in previous evaluation works. We evaluate a wide range of VLMs (CLIP, robust CLIP, BLIP2, and SigLIP2) on curated adversarial datasets (typographic attacks, ImageNet-A, and natural language-induced adversarial examples). We measure the natural adversarial performance of selected VLMs for zero-shot image classification, semantic segmentation, and visual question answering. Our analysis reveals that robust CLIP models can amplify natural adversarial vulnerabilities, and CLIP models significantly reduce performance for natural language-induced adversarial examples. Additionally, we provide interpretable analyses to identify failure modes. We hope our findings inspire future research in robust and fair multimodal pattern recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic evaluation framework for vision-language models (CLIP, robust CLIP, BLIP2, SigLIP2) under natural adversarial scenarios across zero-shot image classification, semantic segmentation, and visual question answering. It evaluates these models on three curated adversarial datasets (typographic attacks, ImageNet-A, and natural language-induced adversarial examples), reports performance drops, and concludes that robust CLIP models amplify natural adversarial vulnerabilities while CLIP models significantly reduce performance on natural language-induced examples, supported by interpretable failure-mode analyses.
Significance. If the performance drops are shown to be robust and the curated sets are validated as representative of real-world natural semantic variation, the findings would be significant for identifying VLM limitations beyond standard benchmarks and could inform development of more robust multimodal systems. The provision of interpretable analyses is a strength that aids in understanding failure modes.
major comments (2)
- [Abstract] Abstract: The abstract states clear empirical observations on performance reductions but provides no details on dataset curation criteria, statistical testing, error bars, or controls for confounding factors. This is load-bearing for the central claims, as it prevents assessment of whether the reported drops are robust or artifactual.
- [Evaluation framework and results sections] Evaluation framework and results sections: The central claims rest on measurements from three deliberately constructed curated sets without quantitative distributional statistics, coverage metrics, or correlation analysis demonstrating that these sets represent or correlate with the empirical distribution of natural semantic shifts in uncontrolled deployment. If the amplification effect is an artifact of curation criteria, the conclusions about natural semantic variation do not follow.
minor comments (2)
- Add error bars, confidence intervals, and statistical significance tests to all reported performance metrics and comparisons across models and datasets.
- Clarify the exact number of examples per dataset and any filtering criteria applied during curation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped clarify the presentation of our evaluation framework. We address each major comment below and have made revisions to strengthen the manuscript's rigor where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states clear empirical observations on performance reductions but provides no details on dataset curation criteria, statistical testing, error bars, or controls for confounding factors. This is load-bearing for the central claims, as it prevents assessment of whether the reported drops are robust or artifactual.
Authors: We agree that the abstract would benefit from additional context on these aspects. In the revised manuscript, we have updated the abstract to briefly describe the curation criteria for the three adversarial datasets, note the use of multiple runs for error bars, and reference controls for confounding factors such as label consistency. Full details on statistical testing remain in the Methods and Results sections, where we have added error bars to figures and tables along with significance tests. revision: yes
-
Referee: [Evaluation framework and results sections] Evaluation framework and results sections: The central claims rest on measurements from three deliberately constructed curated sets without quantitative distributional statistics, coverage metrics, or correlation analysis demonstrating that these sets represent or correlate with the empirical distribution of natural semantic shifts in uncontrolled deployment. If the amplification effect is an artifact of curation criteria, the conclusions about natural semantic variation do not follow.
Authors: We acknowledge this concern regarding representativeness. The original manuscript described curation criteria in Section 3 based on real-world scenarios for typographic attacks, ImageNet-A, and natural language-induced examples. In revision, we have added quantitative distributional statistics (e.g., semantic embedding distances and coverage relative to ImageNet), coverage metrics, and correlation analyses with broader natural variation sources. We have also expanded the discussion to address potential curation artifacts and limitations in generalizing to all uncontrolled deployments, while maintaining that the observed effects hold for the studied natural adversarial scenarios. revision: partial
Circularity Check
No circularity: direct empirical measurements on held-out adversarial sets
full rationale
The paper conducts an empirical audit by evaluating multiple VLMs (CLIP variants, BLIP2, SigLIP2) on three fixed curated datasets for zero-shot classification, segmentation, and VQA tasks. All reported results consist of performance drops, failure-mode analyses, and comparisons of observed accuracies; no equations, parameter fitting, predictions derived from the same data, or self-citation chains are used to justify the central claims. The analysis is therefore self-contained against external benchmarks and contains no load-bearing steps that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.09837 (2025)
Anis, A.M., Ali, H., Sarfraz, S.: On the limitations of vision-language models in understanding image transforms. arXiv preprint arXiv:2503.09837 (2025)
-
[2]
In: Proceedings of the IEEE international confer- ence on computer vision
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: Vqa: Visual question answering. In: Proceedings of the IEEE international confer- ence on computer vision. pp. 2425–2433 (2015)
2015
-
[3]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Awadalla, A., Gao, I., Gardner, J., Hessel, J., Hanafy, Y., Zhu, W., Marathe, K., Bitton, Y., Gadre, S., Sagawa, S., et al.: Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390 (2023)
work page internal anchor Pith review arXiv 2023
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Azuma, H., Matsui, Y.: Defense-prefix for preventing typographic attacks on clip. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3644–3653 (2023)
2023
-
[5]
Advances in neural information processing systems 32(2019)
Barbu, A., Mayo, D., Alverio, J., Luo, W., Wang, C., Gutfreund, D., Tenenbaum, J., Katz, B.: Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. Advances in neural information processing systems 32(2019)
2019
-
[6]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chefer, H., Gur, S., Wolf, L.: Generic attention-model explainability for interpret- ing bi-modal and encoder-decoder transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 397–406 (2021)
2021
-
[8]
See https://vicuna
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023)2(3), 6 (2023) 14 J. Chengyu et al
2023
- [9]
-
[10]
Distill6(3), e30 (2021)
Goh, G., Cammarata, N., Voss, C., Carter, S., Petrov, M., Schubert, L., Radford, A., Olah, C.: Multimodal neurons in artificial neural networks. Distill6(3), e30 (2021)
2021
-
[11]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., et al.: The many faces of robustness: A critical analysis of out-of-distribution generalization. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8340–8349 (2021)
2021
-
[12]
In: International Conference on Learning Represen- tations (2019)
Hendrycks,D.,Dietterich,T.:Benchmarkingneuralnetworkrobustnesstocommon corruptions and perturbations. In: International Conference on Learning Represen- tations (2019)
2019
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., Song, D.: Natural adversarial examples. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15262–15271 (2021)
2021
-
[14]
Advances in Neural Information Processing Systems35, 29262–29277 (2022)
Ilharco, G., Wortsman, M., Gadre, S.Y., Song, S., Hajishirzi, H., Kornblith, S., Farhadi, A., Schmidt, L.: Patching open-vocabulary models by interpolating weights. Advances in Neural Information Processing Systems35, 29262–29277 (2022)
2022
-
[15]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021)
2021
-
[16]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[17]
In: The Thirteenth International Conference on Learning Representations
Lim, H., Choi, J., Choo, J., Schneider, S.: Sparse autoencoders reveal selective remapping of visual concepts during adaptation. In: The Thirteenth International Conference on Learning Representations
-
[18]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lüddecke, T., Ecker, A.: Image segmentation using text and image prompts. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 7086–7096 (2022)
2022
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Materzyńska, J., Torralba, A., Bau, D.: Disentangling visual and written concepts in clip. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16410–16419 (2022)
2022
-
[21]
Clip- cap: Clip prefix for image captioning
Mokady, R., Hertz, A., Bermano, A.H.: Clipcap: Clip prefix for image captioning. arXiv preprint arXiv:2111.09734 (2021)
-
[22]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[23]
Recht, B., Roelofs, R., Schmidt, L., Shankar, V.: Do imagenet classifiers generalize to imagenet? In: International conference on machine learning. pp. 5389–5400. PMLR (2019)
2019
-
[24]
In: Forty-first International Conference on Machine Learning Vision-Language Model Evaluation 15
Schlarmann, C., Singh, N.D., Croce, F., Hein, M.: Robust clip: Unsupervised ad- versarial fine-tuning of vision embeddings for robust large vision-language models. In: Forty-first International Conference on Machine Learning Vision-Language Model Evaluation 15
-
[25]
In: International Conference on Machine Learning
Schlarmann, C., Singh, N.D., Croce, F., Hein, M.: Robust clip: Unsupervised ad- versarial fine-tuning of vision embeddings for robust large vision-language models. In: International Conference on Machine Learning. pp. 43685–43704. PMLR (2024)
2024
-
[26]
Shen, S., Li, L.H., Tan, H., Bansal, M., Rohrbach, A., Chang, K.W., Yao, Z., Keutzer, K.: How much can CLIP benefit vision-and-language tasks? In: Interna- tional Conference on Learning Representations (2022)
2022
-
[27]
DataBricks (May, 2023) www
Team, M.N., et al.: Introducing mpt-7b: A new standard for open-source, com- mercially usable llms. DataBricks (May, 2023) www. mosaicml. com/blog/mpt-7b (2023)
2023
-
[28]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Team, Z.I.: Z-image: An efficient image generation foundation model with single- stream diffusion transformer. arXiv preprint arXiv:2511.22699 (2025)
work page internal anchor Pith review arXiv 2025
-
[29]
arXiv preprint arXiv:2511.04247 (2025)
Tran, A., Rossetto, L.: On the brittleness of clip text encoders. arXiv preprint arXiv:2511.04247 (2025)
-
[30]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Tu, W., Deng, W., Gedeon, T.: Toward a holistic evaluation of robustness in clip models. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[32]
Advances in neural information processing systems32(2019)
Wang, H., Ge, S., Lipton, Z., Xing, E.P.: Learning robust global representations by penalizing local predictive power. Advances in neural information processing systems32(2019)
2019
-
[33]
Wightman, R.: Pytorch image models.https://github.com/rwightman/ pytorch-image-models(2019). https://doi.org/10.5281/zenodo.4414861
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, C., Lin, Z., Cohen, S., Bui, T., Maji, S.: Phrasecut: Language-based image seg- mentation in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10216–10225 (2020)
2020
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu, Z., Yu, J., Cui, Y., Tao, D., Tian, Q.: Deep modular co-attention networks for visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6281–6290 (2019)
2019
-
[36]
Advances in Neural Information Processing Systems36, 54111–54138 (2023)
Zhao, Y., Pang, T., Du, C., Yang, X., Li, C., Cheung, N.M.M., Lin, M.: On eval- uating adversarial robustness of large vision-language models. Advances in Neural Information Processing Systems36, 54111–54138 (2023)
2023
-
[37]
arXiv preprint arXiv:2501.02029 (2025)
Zheng, Z., Zhao, J., Yang, L., He, L., Li, F.: Spot risks before speaking! un- raveling safety attention heads in large vision-language models. arXiv preprint arXiv:2501.02029 (2025)
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, M., Patel, V.M.: Enhancing adversarial robustness for deep metric learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15325–15334 (2022)
2022
-
[39]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Zhu, X., Xu, P., Zeng, G., Dong, Y., Hu, X.: Natural language induced adversarial images. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 10872–10881 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.