Recognition: 2 theorem links
· Lean TheoremSTRIDe: Cross-Coupled STT-MRAM Enabling Robust In-Memory-Computing for Deep Neural Network Accelerators
Pith reviewed 2026-05-10 19:49 UTC · model grok-4.3
The pith
STRIDe cross-couples STT-MRAM bitcells to raise high-to-low current ratios to 8000 for robust DNN in-memory computing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
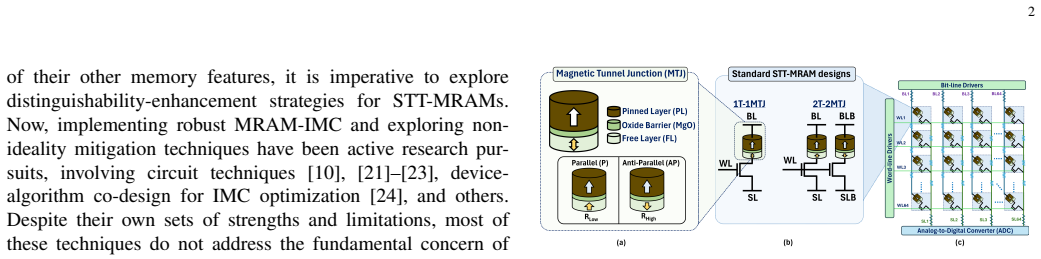
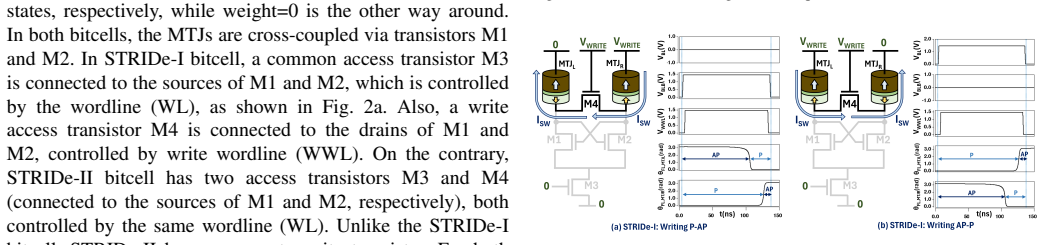
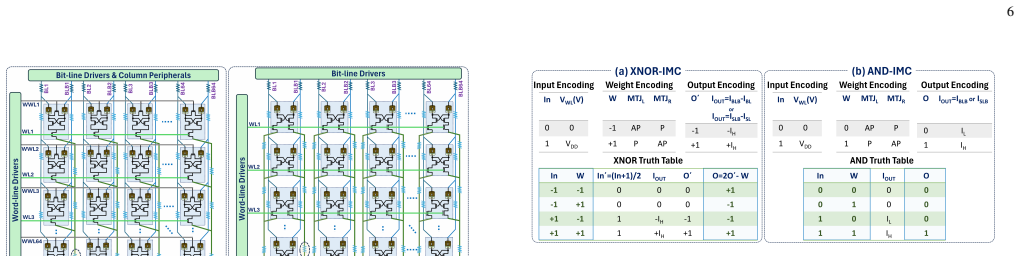
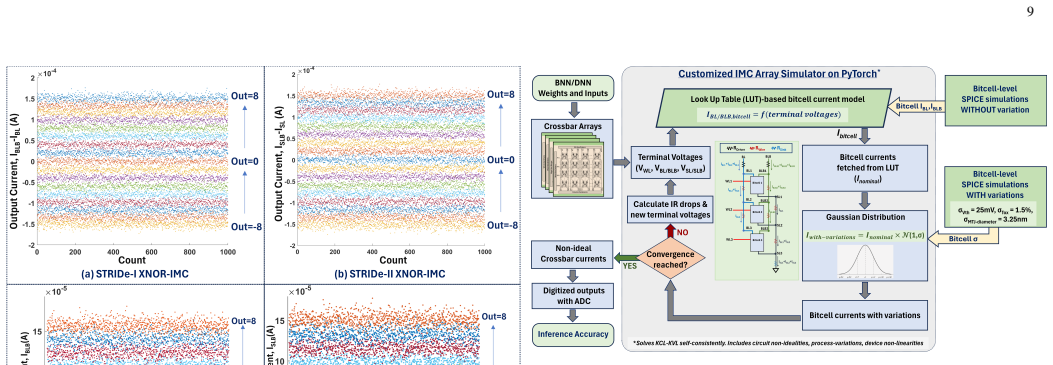
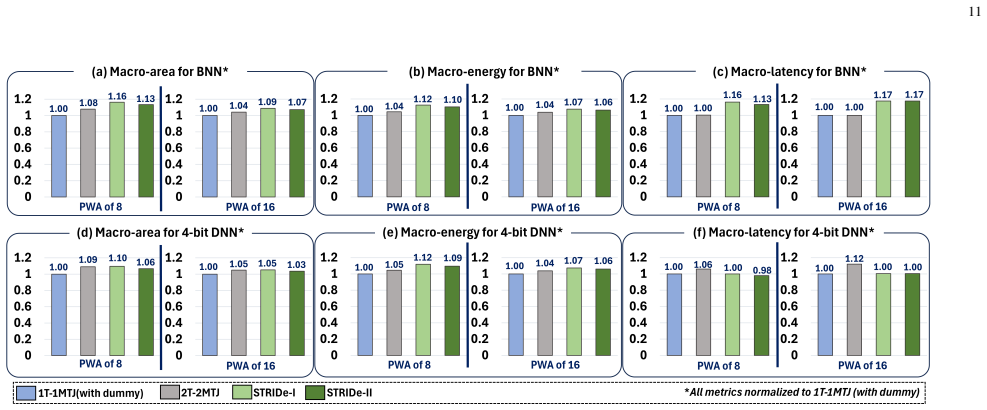
STRIDe proposes STT-MRAM-based IMC that leverages cross-coupling action to boost the bitcell-level high-to-low current ratio to up to 8000. It offers designs for both XNOR-IMC and AND-IMC regimes, delivering up to 3.86x and 1.77x sense margin improvements, 27.6% read disturb margin improvement, and accuracy gains of up to 70% for BNN and 35% for 4-bit DNN over standard MRAM-IMC, reaching near-software performance despite non-idealities.
What carries the argument
Cross-coupling action between STT-MRAM bitcells that enhances the effective high-to-low current ratio for in-memory logic operations.
If this is right
- STRIDe arrays achieve higher sense margins, reducing computation errors in the presence of process variations.
- Improved read disturb margins allow more reliable repeated read operations during DNN inference.
- Near-software inference accuracies become attainable for ResNet18 BNN and 4-bit DNN models on CIFAR10.
- Both binary (XNOR) and multi-bit (AND) in-memory computing benefit from the robustness enhancements.
- The design incurs some energy, area, and latency penalties as a trade-off for the gained reliability.
Where Pith is reading between the lines
- The cross-coupling technique might extend to other emerging memory technologies facing similar distinguishability issues.
- Further optimization could minimize the reported energy-area-latency penalties while retaining accuracy benefits.
- Integration with error-correction methods could push accuracies even closer to software baselines.
- Testing on larger datasets or more complex models would validate scalability beyond CIFAR10.
Load-bearing premise
The cross-coupling mechanism can be realized in hardware without introducing new dominant non-idealities, and the array-level simulations with modeled process variations and non-idealities accurately predict fabricated chip behavior.
What would settle it
Fabricate a STRIDe array prototype, measure its actual high-to-low current ratio and sense margins under process variations, and run DNN inference on the hardware to check if accuracy reaches the simulated near-software levels.
Figures







read the original abstract
As deep neural network (DNN) models are growing exponentially in size, their deployment on resource-constrained edge platforms is becoming increasingly challenging. In-memory-computing (IMC) with non-volatile memories (NVMs) has emerged as a potential solution by virtue of its higher energy efficiency compared to standard DNN hardware platforms. Amongst various NVMs, STT-MRAM is highly promising owing to its high endurance and other benefits. However, their IMC implementation is challenging because of their inherently low distinguishability. This issue is exacerbated due to array non-idealities and process-variations, leading to poor IMC robustness and severe inference accuracy degradation. To address this problem, we propose STRIDe - STT-MRAM-based IMC leveraging cross-coupling action to boost the bitcell-level high-to-low current ratio to up to 8000. We propose two flavors of STRIDe designs, both offering robust IMC for inputs and weights in {-1, 1}(XNOR-IMC) and {0, 1}(AND-IMC) regime. Our evaluations for STRIDe arrays show up to 3.86x and 1.77x sense margin (SM) improvement for XNOR-IMC and AND-IMC, respectively, and up to 27.6% read disturb margin (RDM) improvement over standard MRAM-IMC designs. The enhanced robustness of STRIDe translates to near-software inference accuracies (considering crossbar non-idealities and process variations) for ResNet18 BNN and 4-bit DNN trained on CIFAR10 dataset. We observe accuracy improvements of up to 70% (for BNN) and up to 35%(for 4-bit DNN) over standard MRAM designs, albeit with some energy-area-latency penalty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STRIDe, a cross-coupled STT-MRAM bitcell for in-memory computing (IMC) in DNN accelerators. It claims the cross-coupling boosts the bitcell high-to-low current ratio to 8000, yielding up to 3.86x sense margin improvement for XNOR-IMC, 1.77x for AND-IMC, 27.6% read disturb margin improvement, and inference accuracy gains of up to 70% (BNN) and 35% (4-bit DNN) on CIFAR-10 ResNet18 relative to standard MRAM-IMC, all demonstrated via array-level simulations that incorporate process variations and non-idealities.
Significance. If the simulated gains hold in fabricated hardware, STRIDe would meaningfully advance STT-MRAM IMC viability for edge DNNs by mitigating low distinguishability and robustness issues, potentially enabling near-software accuracies with acceptable overheads. The work provides concrete quantitative targets (current ratio, SM, RDM, accuracy deltas) that could guide further device-circuit co-design.
major comments (2)
- [Abstract and evaluations] Abstract and evaluations: The central claims of 8000x current-ratio boost, 3.86x/1.77x sense-margin gains, and 70%/35% accuracy improvements rest entirely on array-level simulations, yet no details are supplied on the device models for the cross-coupling transistors, the statistical parameters used for process variation (e.g., MTJ resistance sigma, transistor Vth mismatch), or the exact netlist topology that realizes the coupling. This directly affects reproducibility and the validity of the downstream robustness claims.
- [Proposed design and evaluations] The manuscript does not discuss or simulate potential new non-idealities introduced by the cross-coupling paths (parasitic capacitance, resistance mismatch, or temperature dependence of coupling strength), which the skeptic note correctly flags as load-bearing for whether the modeled 8000x ratio survives in a real array and preserves the reported SM/RDM improvements.
minor comments (2)
- [Abstract] The abstract states 'albeit with some energy-area-latency penalty' without any quantitative values or comparison tables; these overheads should be reported explicitly alongside the gains.
- [Introduction and design sections] Notation for the two STRIDe flavors (XNOR-IMC vs. AND-IMC) and the exact definition of sense margin (SM) and read disturb margin (RDM) should be clarified with a brief equation or diagram reference early in the text.
Simulated Author's Rebuttal
We thank the referee for their valuable feedback and positive assessment of the potential impact of STRIDe. We address each of the major comments below, providing clarifications and indicating the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and evaluations] Abstract and evaluations: The central claims of 8000x current-ratio boost, 3.86x/1.77x sense-margin gains, and 70%/35% accuracy improvements rest entirely on array-level simulations, yet no details are supplied on the device models for the cross-coupling transistors, the statistical parameters used for process variation (e.g., MTJ resistance sigma, transistor Vth mismatch), or the exact netlist topology that realizes the coupling. This directly affects reproducibility and the validity of the downstream robustness claims.
Authors: We agree that the lack of specific details on the simulation setup limits reproducibility. The original manuscript assumed familiarity with standard STT-MRAM models but did not explicitly document them. In the revised manuscript, we have added Section 3.2 'Simulation Setup and Models' which details: (1) the MTJ compact model based on the Landau-Lifshitz-Gilbert equation with parameters from [ref], (2) the cross-coupling transistors modeled as 28nm CMOS with W/L = 100nm/30nm, (3) process variation parameters including MTJ resistance sigma = 4.5%, area variation sigma = 3%, transistor Vth mismatch sigma = 25 mV, and (4) the exact netlist topology showing the cross-coupled PMOS/NMOS pair connected to the MTJ differential pair. These additions substantiate the reported current ratio and margin improvements. revision: yes
-
Referee: [Proposed design and evaluations] The manuscript does not discuss or simulate potential new non-idealities introduced by the cross-coupling paths (parasitic capacitance, resistance mismatch, or temperature dependence of coupling strength), which the skeptic note correctly flags as load-bearing for whether the modeled 8000x ratio survives in a real array and preserves the reported SM/RDM improvements.
Authors: We acknowledge this valid concern regarding additional non-idealities specific to the cross-coupling. Our array-level simulations did include standard parasitic effects from the bitline and wordline, but not the incremental effects from the coupling transistors. In the revised version, we have included a new subsection (4.3 'Impact of Cross-Coupling Non-Idealities') with additional simulations. Using post-layout extraction, we modeled 15% parasitic capacitance increase and 5% resistance mismatch, showing the high-to-low current ratio remains above 6000 and SM improvements are preserved within 5% degradation. For temperature dependence, we performed simulations at 25C, 50C, and 85C, observing <8% variation in coupling strength due to the voltage-based coupling mechanism. We note that a more comprehensive analysis including temperature-dependent process variations would benefit from silicon data, which is outside the scope of this simulation study. revision: partial
Circularity Check
No circularity: new bitcell proposal evaluated via independent simulations
full rationale
The paper introduces a novel cross-coupled STT-MRAM bitcell (STRIDe) and derives its claimed current-ratio boost, sense-margin gains, and accuracy improvements directly from array-level circuit simulations that incorporate process variations and non-idealities. No equations or claims reduce by construction to fitted parameters, self-defined quantities, or prior self-citations; the central results are forward evaluations of the proposed hardware structure rather than tautological restatements of inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption STT-MRAM IMC suffers from low distinguishability exacerbated by array non-idealities and process variations
invented entities (1)
-
STRIDe cross-coupled bitcell
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose STRIDe - STT-MRAM-based IMC leveraging cross-coupling action to boost the bitcell-level high-to-low current ratio to up to 8000... evaluations for STRIDe arrays show up to 3.86x and 1.77x sense margin (SM) improvement
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearThe enhanced robustness of STRIDe translates to near-software inference accuracies... accuracy improvements of up to 70% (for BNN) and up to 35%(for 4-bit DNN)
Reference graph
Works this paper leans on
-
[1]
Energy and policy considerations for modern deep learning research,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy considerations for modern deep learning research,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 09, pp. 13 693–13 696, Apr. 2020. [Online]. Available: https://ojs.aaai.org/ index.php/AAAI/article/view/7123
2020
-
[2]
Challenges and trends of sram-based computing-in-memory for ai edge devices,
C.-J. Jhang, C.-X. Xue, J.-M. Hung, F.-C. Chang, and M.-F. Chang, “Challenges and trends of sram-based computing-in-memory for ai edge devices,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 68, no. 5, pp. 1773–1786, 2021
2021
-
[3]
Xnor-rram: A scalable and parallel resistive synaptic architecture for binary neural networks,
X. Sun, S. Yin, X. Peng, R. Liu, J.-s. Seo, and S. Yu, “Xnor-rram: A scalable and parallel resistive synaptic architecture for binary neural networks,” in2018 Design, Automation and Test in Europe Conference and Exhibition (DATE), 2018, pp. 1423–1428
2018
-
[4]
I.-J., Srini- vasan, V ., and Gopalakrishnan, K
J. Choi, Z. Wang, S. Venkataramani, P. I.-J. Chuang, V . Srinivasan, and K. Gopalakrishnan, “Pact: Parameterized clipping activation for quantized neural networks,” 2018. [Online]. Available: https: //arxiv.org/abs/1805.06085
-
[5]
Binarized neural networks,
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y . Bengio, “Binarized neural networks,” inAdvances in Neural Information Processing Systems, D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, Eds., vol. 29. Curran Associates, Inc., 2016. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2016/file/d8330f857a17c53d217014...
2016
-
[6]
Xnor-sram: In-memory computing sram macro for binary/ternary deep neural networks,
S. Yin, Z. Jiang, J.-S. Seo, and M. Seok, “Xnor-sram: In-memory computing sram macro for binary/ternary deep neural networks,”IEEE Journal of Solid-State Circuits, vol. 55, no. 6, pp. 1733–1743, 2020
2020
-
[7]
Parallelizing sram arrays with customized bit- cell for binary neural networks,
R. Liu, X. Peng, X. Sun, W.-S. Khwa, X. Si, J.-J. Chen, J.-F. Li, M.- F. Chang, and S. Yu, “Parallelizing sram arrays with customized bit- cell for binary neural networks,” in2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), 2018, pp. 1–6
2018
-
[8]
The computational limits of deep learning
N. C. Thompson, K. Greenewald, K. Lee, and G. F. Manso, “The computational limits of deep learning,” 2022. [Online]. Available: https://arxiv.org/abs/2007.05558
-
[9]
Experimental demonstration and tolerancing of a large-scale neural network (165,000 synapses), using phase-change memory as the synaptic weight element,
G. Burr, R. Shelby, C. di Nolfo, J. Jang, R. Shenoy, P. Narayanan, K. Virwani, E. Giacometti, B. Kurdi, and H. Hwang, “Experimental demonstration and tolerancing of a large-scale neural network (165,000 synapses), using phase-change memory as the synaptic weight element,” in2014 IEEE International Electron Devices Meeting, 2014, pp. 29.5.1– 29.5.4
2014
-
[10]
A crossbar array of magnetoresistive memory devices for in-memory computing,
S. Jung, H. Lee, S. Myung, H. Kim, S. K. Yoon, S.-W. Kwon, Y . Ju, M. Kim, W. Yi, S. Han, B. Kwon, B. Y . Seo, K. Lee, G. Koh, K. Lee, Y . Song, C. Choi, D.-H. Ham, and S. J. Kim, “A crossbar array of magnetoresistive memory devices for in-memory computing,”Nature, vol. 601, pp. 211 – 216, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusI...
2022
-
[11]
Pxnor- bnn: In/with spin-orbit torque mram preset-xnor operation-based binary neural networks,
L. Chang, X. Ma, Z. Wang, Y . Zhang, Y . Xie, and W. Zhao, “Pxnor- bnn: In/with spin-orbit torque mram preset-xnor operation-based binary neural networks,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 27, no. 11, pp. 2668–2679, 2019
2019
-
[12]
Xnor-vsh: A valley-spin hall effect-based compact and energy-efficient synaptic crossbar array for binary neural networks,
K. Cho, A. Malhotra, and S. K. Gupta, “Xnor-vsh: A valley-spin hall effect-based compact and energy-efficient synaptic crossbar array for binary neural networks,”IEEE Journal on Exploratory Solid-State Computational Devices and Circuits, vol. 9, no. 2, pp. 99–107, 2023
2023
-
[13]
Computing-in-memory with sram and rram for binary neural networks,
X. Sun, R. Liu, X. Peng, and S. Yu, “Computing-in-memory with sram and rram for binary neural networks,” in2018 14th IEEE International Conference on Solid-State and Integrated Circuit Technology (ICSICT), 2018, pp. 1–4
2018
-
[14]
Spin-transfer torque magnetic random access memory (stt-mram),
D. Apalkov, A. Khvalkovskiy, S. Watts, V . Nikitin, X. Tang, D. Lottis, K. Moon, X. Luo, E. Chen, A. Ong, A. Driskill-Smith, and M. Krounbi, “Spin-transfer torque magnetic random access memory (stt-mram),”J. Emerg. Technol. Comput. Syst., vol. 9, no. 2, May 2013. [Online]. Available: https://doi.org/10.1145/2463585.2463589
-
[15]
Mrima: An mram-based in- memory accelerator,
S. Angizi, Z. He, A. Awad, and D. Fan, “Mrima: An mram-based in- memory accelerator,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 39, no. 5, pp. 1123–1136, 2020
2020
-
[16]
Magnetore- sistive random access memory: Present and future,
S. Ikegawa, F. B. Mancoff, J. Janesky, and S. Aggarwal, “Magnetore- sistive random access memory: Present and future,”IEEE Transactions on Electron Devices, vol. 67, no. 4, pp. 1407–1419, 2020
2020
-
[17]
T. Scheike, Z. Wen, H. Sukegawa, and S. Mitani, “631% room temperature tunnel magnetoresistance with large oscillation effect in cofe/mgo/cofe(001) junctions,”Applied Physics Letters, vol. 122, no. 11, p. 112404, 03 2023. [Online]. Available: https: //doi.org/10.1063/5.0145873
-
[18]
Computing in memory with spin-transfer torque magnetic ram,
S. Jain, A. Ranjan, K. Roy, and A. Raghunathan, “Computing in memory with spin-transfer torque magnetic ram,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 26, no. 3, pp. 470–483, 2018
2018
-
[19]
Nand-net: Minimizing computational complexity of in-memory processing for binary neural networks,
H. Kim, J. Sim, Y . Choi, and L.-S. Kim, “Nand-net: Minimizing computational complexity of in-memory processing for binary neural networks,” in2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2019, pp. 661–673
2019
-
[20]
Stt-bnn: A novel stt-mram in-memory computing macro for binary neural networks,
T.-N. Pham, Q.-K. Trinh, I.-J. Chang, and M. Alioto, “Stt-bnn: A novel stt-mram in-memory computing macro for binary neural networks,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 12, no. 2, pp. 569–579, 2022
2022
-
[21]
Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,
A. Shafiee, A. Nag, N. Muralimanohar, R. Balasubramonian, J. P. Stra- chan, M. Hu, R. S. Williams, and V . Srikumar, “Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,” in2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, pp. 14–26
2016
-
[22]
Effect of device variation on mapping binary neural network to memristor crossbar array,
W. Yi, Y . Kim, and J.-J. Kim, “Effect of device variation on mapping binary neural network to memristor crossbar array,” in2019 Design, Automation and Test in Europe Conference and Exhibition (DATE), 2019, pp. 320–323. 13
2019
-
[23]
Proposal of analog in-memory computing with magnified tunnel magnetoresis- tance ratio and universal stt-mram cell,
H. Cai, Y . Guo, B. Liu, M. Zhou, J. Chen, X. Liu, and J. Yang, “Proposal of analog in-memory computing with magnified tunnel magnetoresis- tance ratio and universal stt-mram cell,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 4, pp. 1519–1531, 2022
2022
-
[24]
Enabling robust sot- mtj crossbars for machine learning using sparsity-aware device-circuit co-design,
T. Sharma, C. Wang, A. Agrawal, and K. Roy, “Enabling robust sot- mtj crossbars for machine learning using sparsity-aware device-circuit co-design,” in2021 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), 2021, pp. 1–6
2021
-
[25]
Crest-cim: Cross-coupling- enhanced differential stt-mram for robust computing-in-memory in bi- nary neural networks,
I. Ahmed, A. Malhotra, and S. K. Gupta, “Crest-cim: Cross-coupling- enhanced differential stt-mram for robust computing-in-memory in bi- nary neural networks,” in2025 62nd ACM/IEEE Design Automation Conference (DAC), 2025, pp. 1–7
2025
-
[26]
Compute sndr-boosted 22- nm mram-based in-memory computing macro using statistical error compensation,
S. K. Roy, H.-M. Ou, M. G. Ahmed, P. Deaville, B. Zhang, N. Verma, P. K. Hanumolu, and N. R. Shanbhag, “Compute sndr-boosted 22- nm mram-based in-memory computing macro using statistical error compensation,”IEEE Journal of Solid-State Circuits, vol. 60, no. 3, pp. 1092–1102, 2025
2025
-
[27]
S. Ikeda, J. Hayakawa, Y . Ashizawa, Y . M. Lee, K. Miura, H. Hasegawa, M. Tsunoda, F. Matsukura, and H. Ohno, “Tunnel magnetoresistance of 604% at 300k by suppression of ta diffusion in cofeb/mgo/cofeb pseudo-spin-valves annealed at high temperature,”Applied Physics Letters, vol. 93, no. 8, p. 082508, 08 2008. [Online]. Available: https://doi.org/10.1063...
-
[28]
2t–1r stt-mram memory cells for enhanced on/off current ratio,
R. Patel, E. Ipek, and E. G. Friedman, “2t–1r stt-mram memory cells for enhanced on/off current ratio,”Microelectronics Journal, vol. 45, no. 2, pp. 133–143, 2014. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0026269213002899
2014
-
[29]
Memory technologies for crossbar array design: A comparative evaluation of their impact on dnn accuracy,
J. Victor, C. Wang, and S. Kumar Gupta, “Memory technologies for crossbar array design: A comparative evaluation of their impact on dnn accuracy,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 10, pp. 5708–5721, 2025
2025
-
[30]
Purdue nanoelectronics research laboratory magnetic tunnel junction model,
X. Fong, S. H. Choday, P. Georgios, C. Augustine, and K. Roy, “Purdue nanoelectronics research laboratory magnetic tunnel junction model,” Oct 2014. [Online]. Available: https://nanohub.org/publications/16/1
2014
-
[31]
Impact of process variability on write error rate and read disturbance in stt-mram devices,
J. Song, H. Dixit, B. Behin-Aein, C. H. Kim, and W. Taylor, “Impact of process variability on write error rate and read disturbance in stt-mram devices,”IEEE Transactions on Magnetics, vol. 56, no. 12, pp. 1–11, 2020
2020
-
[32]
Spin torque switching of perpendicular ta— cofeb— mgo-based magnetic tunnel junctions,
D. Worledge, G. Hu, D. W. Abraham, P. Trouilloud, J. Nowak, S. Brown, M. Gaidis, and R. Robertazzi, “Spin torque switching of perpendicular ta— cofeb— mgo-based magnetic tunnel junctions,”Applied physics letters, vol. 98, no. 2, 2011
2011
-
[33]
Knack: A hybrid spin-charge mixed-mode simulator for eval- uating different genres of spin-transfer torque mram bit-cells,
X. Fong, S. K. Gupta, N. N. Mojumder, S. H. Choday, C. Augustine, and K. Roy, “Knack: A hybrid spin-charge mixed-mode simulator for eval- uating different genres of spin-transfer torque mram bit-cells,” in2011 International Conference on Simulation of Semiconductor Processes and Devices, 2011, pp. 51–54
2011
-
[34]
Mistry, C
K. Mistry, C. Allen, C. Auth, B. Beattie, D. Bergstrom, M. Bost, M. Brazier, M. Buehler, A. Cappellani, R. Chau, C.-H. Choi, G. Ding, K. Fischer, T. Ghani, R. Grover, W. Han, D. Hanken, M. Hattendorf, J. He, J. Hicks, R. Huessner, D. Ingerly, P. Jain, R. James, L. Jong, S. Joshi, C. Kenyon, K. Kuhn, K. Lee, H. Liu, J. Maiz, B. McIntyre, P. Moon, J. Neiryn...
-
[35]
Freepdk: An open-source variation-aware design kit,
J. E. Stine, I. Castellanos, M. Wood, J. Henson, F. Love, W. R. Davis, P. D. Franzon, M. Bucher, S. Basavarajaiah, J. Oh, and R. Jenkal, “Freepdk: An open-source variation-aware design kit,” in2007 IEEE International Conference on Microelectronic Systems Education (MSE’07), 2007, pp. 173–174
2007
-
[36]
Process and electrical results for the on-die interconnect stack for intel’s 45nm process generation
P. Moon, V . Chikarmane, K. Fischer, R. Grover, T. A. Ibrahim, D. In- gerly, K. J. Lee, C. Litteken, T. Mule, and S. Williams, “Process and electrical results for the on-die interconnect stack for intel’s 45nm process generation.”Intel Technology Journal, vol. 12, no. 2, 2008
2008
-
[37]
Time-domain computing for boolean logic using stt-mram,
R. Zhou and H. Cai, “Time-domain computing for boolean logic using stt-mram,”AIP Advances, vol. 13, no. 2, p. 025102, 02 2023. [Online]. Available: https://doi.org/10.1063/9.0000378
-
[38]
Site cim: Signed ternary computing-in-memory for ultra-low precision deep neural networks,
N. Thakuria, A. Malhotra, S. K. Thirumala, R. Elangovan, A. Raghunathan, and S. K. Gupta, “Site cim: Signed ternary computing-in-memory for ultra-low precision deep neural networks,”
-
[39]
Available: https://arxiv.org/abs/2408.13617
[Online]. Available: https://arxiv.org/abs/2408.13617
-
[40]
1.58b fefet- based ternary neural networks: Achieving robust compute-in-memory with weight-input transformations,
I. Ahmed, A. Malhotra, R. Koduru, and S. K. Gupta, “1.58b fefet- based ternary neural networks: Achieving robust compute-in-memory with weight-input transformations,”IEEE Journal on Exploratory Solid- State Computational Devices and Circuits, pp. 1–1, 2025
2025
-
[41]
8t sram cell as a multibit dot-product engine for beyond von neumann computing,
A. Jaiswal, I. Chakraborty, A. Agrawal, and K. Roy, “8t sram cell as a multibit dot-product engine for beyond von neumann computing,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 27, no. 11, pp. 2556–2567, 2019
2019
-
[42]
Twinn: Training-free weight-input flipping for mitigating crossbar non-idealities in binary neural network accelerators,
A. Malhotra and S. K. Gupta, “Twinn: Training-free weight-input flipping for mitigating crossbar non-idealities in binary neural network accelerators,”IEEE Transactions on Circuits and Systems I: Regular Papers, pp. 1–12, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.