Recognition: no theorem link
GAIN: Multiplicative Modulation for Domain Adaptation
Pith reviewed 2026-05-10 20:24 UTC · model grok-4.3
The pith
Multiplicative modulation preserves the column span of pretrained weights to control forgetting in domain adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
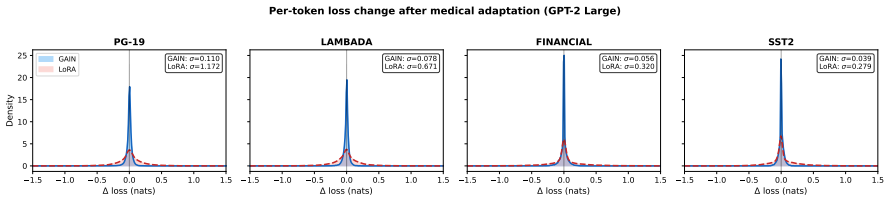
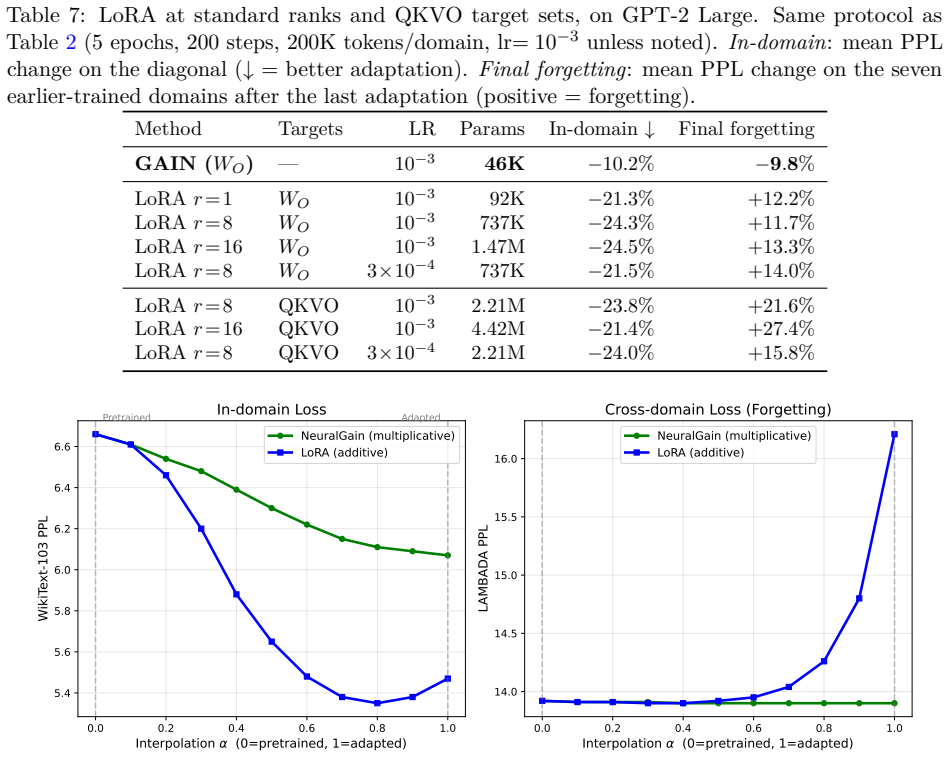
Adapting LLMs to new domains causes forgetting because standard methods inject new directions into the weight space. Forgetting is governed by whether the update preserves the column span of the pretrained weight matrix. GAIN proposes the simplest multiplicative alternative W_new = S * W that satisfies this by construction and can be absorbed into existing weights for zero inference cost. Across five models adapted sequentially over eight domains, GAIN improves earlier-domain perplexity by 7-13% while LoRA degrades it by 18-36%.
What carries the argument
The multiplicative scaling matrix S such that W_new = S * W, which preserves the column span of W by construction.
If this is right
- GAIN improves earlier-domain perplexity by 7-13% across models from 774M to 70B over eight domains.
- It matches the performance of replay-augmented LoRA without needing to store prior data.
- GAIN dominates EWC on the forgetting-adaptation trade-off.
- LoRA can only reduce forgetting by sacrificing in-domain adaptation, whereas GAIN achieves both.
- The principle generalises to independent multiplicative methods such as (IA)^3.
Where Pith is reading between the lines
- If column span preservation is the key, additive updates like LoRA could be modified to project onto the original span for better retention.
- This algebraic perspective might apply to other continual learning scenarios beyond language models.
- Since GAIN has zero inference cost, it could support permanent model updates after each adaptation phase.
Load-bearing premise
That preserving the column span of the pretrained weights is both necessary and sufficient to control forgetting in practice, and that a learned multiplicative matrix S can achieve strong in-domain adaptation without additional mechanisms or post-hoc adjustments.
What would settle it
An experiment where a model update that mathematically preserves the column span nevertheless exhibits substantial forgetting on previous domains, or where GAIN fails to adapt effectively to the new domain.
Figures


read the original abstract
Adapting LLMs to new domains causes forgetting because standard methods (e.g., full fine-tuning, LoRA) inject new directions into the weight space. We show that forgetting is governed by one algebraic property: whether the update preserves the column span of the pretrained weight matrix (Proposition 1). We propose GAIN, the simplest multiplicative alternative (W_new = S * W), which satisfies this by construction and can be absorbed into existing weights for zero inference cost. Across five models (774M to 70B) adapted sequentially over eight domains, GAIN improves earlier-domain perplexity by 7-13%, while LoRA degrades it by 18-36%. GAIN matches replay-augmented LoRA without storing prior data and dominates EWC on the forgetting-adaptation Pareto front. While LoRA can only reduce forgetting by sacrificing in-domain adaptation, GAIN achieves both with no domain boundaries and no regularization. The principle generalises: (IA)^3, an independent multiplicative method, also improves earlier domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that catastrophic forgetting in sequential domain adaptation of LLMs is governed by a single algebraic property: whether the weight update preserves the column span of the pretrained weight matrix (Proposition 1). It introduces GAIN as the simplest multiplicative alternative via W_new = S * W, which satisfies this property by construction, can be absorbed into the base weights for zero inference cost, and empirically yields 7-13% better earlier-domain perplexity than LoRA (which degrades it by 18-36%) across five models (774M-70B) and eight domains, while matching replay-augmented LoRA without data storage and dominating EWC on the adaptation-forgetting trade-off. The principle is said to generalize to other multiplicative methods such as (IA)^3.
Significance. If the algebraic characterization of forgetting holds and the empirical gains prove robust, the work would offer a principled, low-overhead alternative to additive adaptation methods for continual learning in LLMs, with the practical advantage of zero-cost inference via absorption of S. The broad evaluation across model scales and the generalization note to (IA)^3 are positive features. The central thesis challenges the dominance of additive updates like LoRA by tying forgetting directly to span expansion.
major comments (3)
- [Proposition 1] Proposition 1 (abstract and associated section): the claim that forgetting is governed by column-span preservation and that W_new = S * W satisfies it by construction requires a formal statement and proof sketch. Algebraically, col(S W) = S · col(W), which equals col(W) only if the original subspace is invariant under S; otherwise the new column space is the image of the old one under S. This distinction is load-bearing for the central claim that span preservation (rather than other multiplicative properties or regularization) controls forgetting.
- [Results] Empirical evaluation (results section reporting 7-13% and 18-36% figures): the performance claims lack error bars, baseline implementation details, domain sequencing protocol, and exclusion criteria. Without these, it is impossible to assess whether the reported Pareto dominance over LoRA and EWC is robust or sensitive to optimization dynamics specific to learning S.
- [Experiments] Experimental controls (comparison to LoRA and discussion of span preservation): the manuscript compares GAIN to LoRA (which can expand rank) but provides no control that enforces span preservation through a different mechanism, such as a rank-constrained additive update. This leaves open whether the observed gains stem from the claimed algebraic property or from implicit regularization and parameter tying in the multiplicative form.
minor comments (2)
- [Abstract] Abstract: the statement that GAIN achieves adaptation 'with no domain boundaries and no regularization' is strong; a brief clarification in the main text of how sequential adaptation proceeds without explicit boundaries would improve readability.
- [Method] Notation: the multiplication symbol in W_new = S * W should be explicitly defined as matrix multiplication (left multiplication) to avoid any ambiguity with element-wise operations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with clear indications of planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Proposition 1] Proposition 1 (abstract and associated section): the claim that forgetting is governed by column-span preservation and that W_new = S * W satisfies it by construction requires a formal statement and proof sketch. Algebraically, col(S W) = S · col(W), which equals col(W) only if the original subspace is invariant under S; otherwise the new column space is the image of the old one under S. This distinction is load-bearing for the central claim that span preservation (rather than other multiplicative properties or regularization) controls forgetting.
Authors: We agree that Proposition 1 requires a formal statement and proof sketch to clarify the algebraic details. In the revised manuscript we will add a dedicated subsection that (i) formally defines column span and span preservation, (ii) states Proposition 1 precisely, and (iii) provides a proof sketch showing that W_new = S W maps the original column space to its image under S. We will explicitly note the referee's distinction: col(SW) equals col(W) only when the subspace is invariant under S; otherwise it is the transformed image. The central claim we defend is that this construction prevents the introduction of directions outside the (transformed) original span, in contrast to additive updates that can expand the effective column space. We will revise the surrounding text to make this nuance load-bearing and transparent rather than claiming exact equality in all cases. revision: yes
-
Referee: [Results] Empirical evaluation (results section reporting 7-13% and 18-36% figures): the performance claims lack error bars, baseline implementation details, domain sequencing protocol, and exclusion criteria. Without these, it is impossible to assess whether the reported Pareto dominance over LoRA and EWC is robust or sensitive to optimization dynamics specific to learning S.
Authors: We thank the referee for highlighting these omissions in the results presentation. The revised manuscript will include: (a) error bars computed from three independent runs with distinct random seeds for all reported perplexity figures; (b) complete baseline implementation details, including LoRA ranks, learning rates, batch sizes, and optimizer settings; (c) an explicit description of the domain sequencing protocol (sequential adaptation in the fixed order of the eight domains listed in Section 4); and (d) confirmation that no domains were excluded—all eight were used in every sequential run. These additions will allow readers to evaluate robustness and sensitivity to optimization choices. revision: yes
-
Referee: [Experiments] Experimental controls (comparison to LoRA and discussion of span preservation): the manuscript compares GAIN to LoRA (which can expand rank) but provides no control that enforces span preservation through a different mechanism, such as a rank-constrained additive update. This leaves open whether the observed gains stem from the claimed algebraic property or from implicit regularization and parameter tying in the multiplicative form.
Authors: We acknowledge that an explicit control enforcing span preservation via an additive mechanism would further isolate the algebraic effect. However, constructing a rank-constrained additive baseline that strictly preserves the original column span requires repeated orthogonal projections onto the pretrained column space, which is computationally prohibitive at the scales considered (up to 70B parameters) and not representative of practical adaptation methods. Our existing comparisons already contrast unconstrained additive updates (LoRA), regularized additive updates (EWC), and the multiplicative form (GAIN). In the revision we will expand the discussion to explicitly address this limitation, explain why the multiplicative parameterization provides a natural and efficient enforcement of the property, and note the practical difficulties of an equivalent additive control. We believe the theoretical motivation combined with the empirical Pareto dominance remains supportive, but we will make the absence of such a control transparent. revision: partial
Circularity Check
No circularity detected; algebraic claim and construction are independent.
full rationale
The paper states that forgetting is governed by column-span preservation (Proposition 1) and introduces GAIN via the direct definition W_new = S * W, which is said to satisfy the property by construction. This is a design choice rather than a reduction of the proposition to the method itself. No fitted parameters are renamed as predictions, no self-citation chain bears the central load, and empirical gains are reported against external baselines without evidence that results are forced by construction to match inputs. The derivation remains self-contained against the provided abstract and skeptic analysis.
Axiom & Free-Parameter Ledger
free parameters (1)
- S matrix
axioms (1)
- domain assumption Forgetting during domain adaptation is governed by whether the weight update preserves the column span of the pretrained matrix.
Reference graph
Works this paper leans on
-
[1]
R. A. Andersen and V. B. Mountcastle. The influence of the angle of gaze upon the excitability of the light-sensitive neurons of the posterior parietal cortex. Journal of Neuroscience, 5 0 (5): 0 1218--1235, 1985
work page 1985
-
[2]
Lora vs full fine-tuning: An illusion of equivalence
S. Biderman, N. Prashanth, J. Portes, S. Pillai, B. Garrett, and A. Jermyn. LoRA vs full fine-tuning: An illusion of equivalence. arXiv preprint arXiv:2410.21228, 2024
- [3]
-
[4]
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer. QLoRA : Efficient finetuning of quantized LLMs . In NeurIPS, 2023
work page 2023
-
[5]
S. Gururangan, A. Marasovi \'c , S. Swayamdipta, K. Lo, I. Beltagy, D. Downey, and N. A. Smith. Don't stop pretraining: Adapt language models to domains and tasks. In ACL, 2020
work page 2020
-
[6]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA : Low-rank adaptation of large language models. In ICLR, 2022
work page 2022
-
[7]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114 0 (13): 0 3521--3526, 2017
work page 2017
- [8]
-
[9]
H. Liu, D. Tam, M. Muqeeth, J. Mohta, T. Huang, M. Bansal, and C. Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. In NeurIPS, 2022
work page 2022
-
[10]
DoRA: Weight-Decomposed Low-Rank Adaptation
S.-Y. Liu, C.-Y. Wang, H. Yin, P. Molchanov, Y.-C. F. Wang, K.-T. Cheng, and M.-H. Chen. DoRA : Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
A. Mallya and S. Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. In CVPR, 2018
work page 2018
-
[12]
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne. Experience replay for continual learning. In NeurIPS, 2019
work page 2019
-
[13]
E. Salinas and L. F. Abbott. Coordinate transformations in the visual system: How to generate gain fields and what to compute with them. Progress in Brain Research, 130: 0 175--190, 2001
work page 2001
-
[14]
E. Salinas and P. Thier. Gain modulation: A major computational principle of the central nervous system. Neuron, 27 0 (1): 0 15--21, 2000
work page 2000
-
[15]
S. Treue and J. C. Mart \' nez-Trujillo. Feature-based attention influences motion processing gain in macaque visual cortex. Nature, 399 0 (6736): 0 575--579, 1999
work page 1999
-
[16]
PiCa: Parameter-Efficient Fine-Tuning with Column Space Projection
Z. Wang et al. Pica: Column space projection for parameter-efficient fine-tuning. arXiv preprint arXiv:2505.20211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.