Recognition: 2 theorem links
· Lean TheoremSLSREC: Self-Supervised Contrastive Learning for Adaptive Fusion of Long- and Short-Term User Interests
Pith reviewed 2026-05-10 20:19 UTC · model grok-4.3
The pith
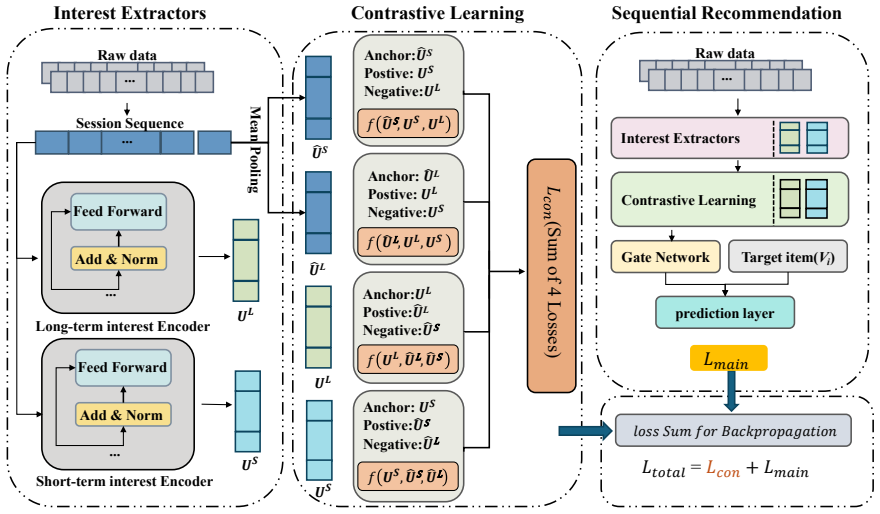
SLSRec disentangles long-term and short-term user interests using self-supervised contrastive learning before adaptively fusing them for recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
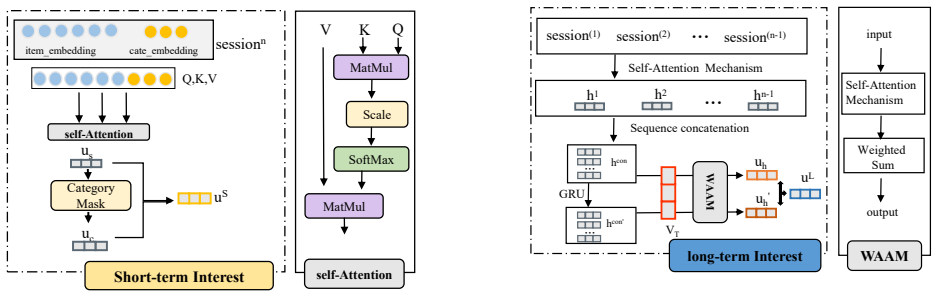
SLSRec segments historical user behaviors over time and applies a self-supervised contrastive learning framework to disentangle long- and short-term interest representations, which an attention-based fusion network then adaptively aggregates to improve recommendation performance over models that combine both into a single vector.
What carries the argument
The self-supervised contrastive learning strategy that calibrates separate long- and short-term interest representations, together with the attention-based fusion network that adaptively aggregates them.
If this is right
- SLSRec outperforms state-of-the-art models on three public benchmark datasets.
- The approach exhibits superior robustness across various recommendation scenarios.
- Accurate calibration of the two interest types avoids the accuracy losses of single-vector models.
- Adaptive aggregation optimizes how each interest type contributes to the final output.
Where Pith is reading between the lines
- The same segmentation-plus-contrastive pattern could be tested in other sequential settings where user signals evolve at different rates, such as content consumption logs.
- Explicit separation of interest types may make it easier to inspect which part of the history drove a given recommendation.
- If the method scales, it could simplify some recurrent or transformer layers by handling temporal scale differences more directly in the representation stage.
Load-bearing premise
Dividing user history into long and short time segments and training with contrastive self-supervision can isolate the two interest types without creating new representation losses that offset the gains.
What would settle it
On the three public benchmark datasets, SLSRec achieves recommendation accuracy equal to or lower than that of standard models that represent all user interests in a single combined vector.
Figures


read the original abstract
User interests typically encompass both long-term preferences and short-term intentions, reflecting the dynamic nature of user behaviors across different timeframes. The uneven temporal distribution of user interactions highlights the evolving patterns of interests, making it challenging to accurately capture shifts in interests using comprehensive historical behaviors. To address this, we propose SLSRec, a novel Session-based model with the fusion of Long- and Short-term Recommendations that effectively captures the temporal dynamics of user interests by segmenting historical behaviors over time. Unlike conventional models that combine long- and short-term user interests into a single representation, compromising recommendation accuracy, SLSRec utilizes a self-supervised learning framework to disentangle these two types of interests. A contrastive learning strategy is introduced to ensure accurate calibration of long- and short-term interest representations. Additionally, an attention-based fusion network is designed to adaptively aggregate interest representations, optimizing their integration to enhance recommendation performance. Extensive experiments on three public benchmark datasets demonstrate that SLSRec consistently outperforms state-of-the-art models while exhibiting superior robustness across various scenarios.We will release all source code upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SLSRec, a session-based recommender that segments user historical behaviors into long-term and short-term sequences, applies a self-supervised contrastive learning framework to produce disentangled representations of these interests, and uses an attention-based fusion network to adaptively combine them for next-item prediction. It claims this avoids the accuracy compromise of single-vector models and demonstrates consistent outperformance over state-of-the-art baselines on three public benchmark datasets with superior robustness.
Significance. If the central mechanism of contrastive disentanglement is shown to produce statistically independent long- and short-term vectors whose adaptive fusion yields genuine gains, the work would address a recurring limitation in sequential recommendation models. The promise to release source code upon acceptance is a positive contribution to reproducibility. However, the absence of auxiliary diagnostics for disentanglement (e.g., mutual information or orthogonality measures) leaves open whether observed improvements stem from the claimed separation or from other modeling choices.
major comments (3)
- [§3.2] §3.2 (Contrastive Learning Module): The contrastive objective is defined via positive/negative pair construction on segmented sequences, yet no quantitative verification is supplied that the resulting long-term and short-term embeddings exhibit reduced statistical dependence (e.g., via mutual information, cosine similarity histograms, or an orthogonality regularizer). Without such evidence, the model may reduce to an attention-weighted sum of correlated vectors, undermining the central claim that disentanglement improves upon prior single-representation compromises.
- [§4.1–4.3] §4.1–4.3 (Experimental Setup and Results): While the abstract asserts outperformance and robustness, the main text provides no explicit statement of the train/validation/test split protocol, hyperparameter search procedure (including whether the contrastive temperature or attention fusion weights were tuned on the test distribution), or statistical significance tests across the three datasets. This makes it impossible to rule out circularity or overfitting as the source of the reported gains.
- [Table 3] Table 3 (Ablation Study): The ablation removing the contrastive loss reports only marginal degradation on one dataset; this result is load-bearing for the claim that self-supervised disentanglement is the key driver, yet no variance estimates or multiple-run statistics are given to establish that the difference is reliable rather than noise.
minor comments (2)
- [§3] Notation for the long-term and short-term encoders is introduced without an explicit diagram or pseudocode; a small figure clarifying the data flow from segmented sequences through contrastive pairs to the fusion attention would improve readability.
- [Abstract] The abstract states that code will be released upon acceptance, but the current manuscript does not include a link to a public repository or supplementary material containing the exact experimental configurations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions where they strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Contrastive Learning Module): The contrastive objective is defined via positive/negative pair construction on segmented sequences, yet no quantitative verification is supplied that the resulting long-term and short-term embeddings exhibit reduced statistical dependence (e.g., via mutual information, cosine similarity histograms, or an orthogonality regularizer). Without such evidence, the model may reduce to an attention-weighted sum of correlated vectors, undermining the central claim that disentanglement improves upon prior single-representation compromises.
Authors: We thank the referee for this observation. The contrastive loss is explicitly constructed to push long-term and short-term representations apart by using cross-segment pairs as negatives, which is intended to reduce their statistical dependence beyond what a simple attention fusion would achieve. Nevertheless, we agree that direct quantitative diagnostics would make the disentanglement effect more transparent. In the revised manuscript we will add cosine similarity histograms between the long- and short-term embeddings as well as mutual-information estimates computed on held-out data, thereby providing the requested verification. revision: yes
-
Referee: [§4.1–4.3] §4.1–4.3 (Experimental Setup and Results): While the abstract asserts outperformance and robustness, the main text provides no explicit statement of the train/validation/test split protocol, hyperparameter search procedure (including whether the contrastive temperature or attention fusion weights were tuned on the test distribution), or statistical significance tests across the three datasets. This makes it impossible to rule out circularity or overfitting as the source of the reported gains.
Authors: We acknowledge that the experimental protocol details were insufficiently explicit. The splits follow the standard leave-one-out protocol used in prior session-based recommendation work on the same datasets; hyperparameters (including contrastive temperature and attention fusion weights) were selected exclusively on the validation set via grid search. We will add a dedicated subsection in §4.1 that states the exact split ratios, the validation-based tuning procedure, and the fact that no test-set information was used for hyperparameter selection. We will also report paired statistical significance tests (t-tests) over five independent runs for all main results. revision: yes
-
Referee: [Table 3] Table 3 (Ablation Study): The ablation removing the contrastive loss reports only marginal degradation on one dataset; this result is load-bearing for the claim that self-supervised disentanglement is the key driver, yet no variance estimates or multiple-run statistics are given to establish that the difference is reliable rather than noise.
Authors: We agree that variance estimates are necessary to interpret the ablation results reliably. The marginal degradation observed on one dataset may reflect dataset-specific characteristics, but without standard deviations it is difficult to judge statistical reliability. In the revised manuscript we will rerun the full ablation study over five random seeds, report mean performance together with standard deviations, and include a brief discussion of whether the observed differences remain consistent across runs. revision: yes
Circularity Check
No circularity detected in architecture proposal or claims
full rationale
The paper introduces SLSRec as an architectural proposal that segments historical user behaviors temporally, applies a standard self-supervised contrastive objective to produce separate long- and short-term vectors, and then uses an attention network for adaptive fusion. No load-bearing equation or step reduces by construction to a fitted parameter renamed as a prediction, nor does any uniqueness claim rest on a self-citation chain. The contrastive loss and attention components are conventional; the novelty lies in their combination and the segmentation heuristic. Performance assertions rest on experiments against public benchmarks rather than any tautological reduction of the model definition to itself. This is a typical model paper whose central claims are empirically falsifiable outside the derivation.
Axiom & Free-Parameter Ledger
free parameters (2)
- contrastive temperature
- attention fusion weights
axioms (2)
- domain assumption Historical user interactions can be segmented by time to isolate long-term versus short-term interests
- domain assumption Self-supervised contrastive learning suffices to calibrate disentangled representations without labeled supervision
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A contrastive learning strategy is introduced to ensure accurate calibration of long- and short-term interest representations... Lu_con = f(uL,ÛL,ÛS) + ... (triplet loss on Euclidean distances)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a session-based partition strategy... long-term interests are modeled via session-level interest evolution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neural news recommendation with long-and short-term user representations
[An et al., 2019 ] Mingxiao An, Fangzhao Wu, Chuhan Wu, Kun Zhang, Zheng Liu, and Xing Xie. Neural news recommendation with long-and short-term user representations. In Proceedings of the 57th annual meeting of the association for computational linguis- tics, pages 336–345,
2019
-
[2]
Microsoft rec- ommenders: Best practices for production-ready recommendation systems
[Argyriou et al., 2020 ] Andreas Argyriou, Miguel González-Fierro, and Le Zhang. Microsoft rec- ommenders: Best practices for production-ready recommendation systems. In Companion Proceedings of the Web Conference 2020, pages 50–51,
2020
-
[3]
Lightgcl: Simple yet effective graph contrastive learning for recommendation
[Cai et al., 2023 ] Xuheng Cai, Chao Huang, Lianghao Xia, and Xubin Ren. Lightgcl: Simple yet effective graph contrastive learning for recommendation. arXiv preprint arXiv:2302.08191,
-
[4]
Control- lable multi-interest framework for recommendation
[Cen et al., 2020 ] Yukuo Cen, Jianwei Zhang, Xu Zou, Chang Zhou, Hongxia Yang, and Jie Tang. Control- lable multi-interest framework for recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2942–2951,
2020
-
[5]
Sequential recommenda- tion with graph neural networks
[Chang et al., 2021 ] Jianxin Chang, Chen Gao, Yu Zheng, Yiqun Hui, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. Sequential recommenda- tion with graph neural networks. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, pages 378–387,
2021
-
[6]
Intent con- trastive learning for sequential recommendation
[Chen et al., 2022 ] Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. Intent con- trastive learning for sequential recommendation. In Proceedings of the ACM Web Conference 2022, pages 2172–2182,
2022
-
[7]
Se- mantic retrieval augmented contrastive learning for sequential recommendation
[Cui et al., 2025 ] Ziqiang Cui, Yunpeng Weng, Xing Tang, Xiaokun Zhang, Shiwei Li, Peiyang Liu, Bowei He, Dugang Liu, Weihong Luo, Chen Ma, et al. Se- mantic retrieval augmented contrastive learning for sequential recommendation. In The Thirty-ninth An- nual Conference on Neural Information Processing Systems,
2025
-
[8]
Gate-variants of gated recurrent unit (gru) neural net- works
[Dey and Salem, 2017 ] Rahul Dey and Fathi M Salem. Gate-variants of gated recurrent unit (gru) neural net- works. In 2017 IEEE 60th international midwest sym- posium on circuits and systems (MWSCAS), pages 1597–1600. IEEE,
2017
-
[9]
Information-controllable graph con- trastive learning for recommendation
[Guo et al., 2024 ] Zirui Guo, Yanhua Yu, Yuling Wang, Kangkang Lu, Zixuan Yang, Liang Pang, and Tat- Seng Chua. Information-controllable graph con- trastive learning for recommendation. In Proceedings of the 18th ACM Conference on Recommender Sys- tems, pages 528–537,
2024
-
[10]
Neu- ral collaborative filtering
[He et al., 2017 ] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neu- ral collaborative filtering. In Proceedings of the 26th international conference on world wide web, pages 173–182,
2017
-
[11]
Recurrent neural networks with top-k gains for session-based recommendations
[Hidasi and Karatzoglou, 2018 ] Balázs Hidasi and Alexandros Karatzoglou. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM international con- ference on information and knowledge management, pages 843–852,
2018
-
[12]
Session-based Recommendations with Recurrent Neural Networks
[Hidasi, 2015 ] B Hidasi. Session-based recommenda- tions with recurrent neural networks. arXiv preprint arXiv:1511.06939,
work page internal anchor Pith review arXiv 2015
-
[13]
Cumulated gain-based evaluation of ir techniques
[Järvelin and Kekäläinen, 2002 ] Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of ir techniques. ACM Transactions on Information Systems (TOIS), 20(4):422–446,
2002
-
[14]
Self-attentive sequential recommenda- tion
[Kang and McAuley, 2018 ] Wang-Cheng Kang and Ju- lian McAuley. Self-attentive sequential recommenda- tion. In 2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE,
2018
-
[15]
Challenging common assumptions in the unsupervised learning of disentangled representations
[Locatello et al., 2019 ] Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. In international conference on machine learning, pages 4114–4124. PMLR,
2019
-
[16]
Sdm: Sequential deep matching model for online large-scale recommender system
[Lv et al., 2019 ] Fuyu Lv, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wilfred Ng. Sdm: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM international conference on information and knowl- edge management, pages 2635–2643,
2019
-
[17]
[Shih et al., 2025 ] Kowei Shih, Yi Han, and Li Tan. Rec- ommendation system in advertising and streaming media: Unsupervised data enhancement sequence sug- gestions. arXiv preprint arXiv:2504.08740,
-
[18]
Bert4rec: Sequential recommendation with bidirectional encoder represen- tations from transformer
[Sun et al., 2019 ] Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, and Wenwu Ou. Bert4rec: Sequential recommendation with bidirectional encoder represen- tations from transformer. In Proceedings of the 13th ACM Conference on Recommender Systems (RecSys), pages 297–306,
2019
-
[19]
Per- sonalized top-n sequential recommendation via con- volutional sequence embedding
[Tang and Wang, 2018 ] Jiaxi Tang and Ke Wang. Per- sonalized top-n sequential recommendation via con- volutional sequence embedding. In Proceedings of the eleventh ACM international conference on web search and data mining, pages 565–573,
2018
-
[20]
Attentive sequential models of latent intent for next item recommendation
[Tanjim et al., 2020 ] Md Mehrab Tanjim, Congzhe Su, Ethan Benjamin, Diane Hu, Liangjie Hong, and Julian McAuley. Attentive sequential models of latent intent for next item recommendation. In Proceedings of The Web Conference 2020, pages 2528–2534,
2020
-
[21]
Contrastive learning for cold-start recommendation
[Wei et al., 2021 ] Yinwei Wei, Xiang Wang, Qi Li, Liqiang Nie, Yan Li, Xuanping Li, and Tat-Seng Chua. Contrastive learning for cold-start recommendation. In Proceedings of the 29th ACM International Con- ference on Multimedia, pages 5382–5390,
2021
-
[22]
Multi-relational contrastive learning for rec- ommendation
[Wei et al., 2023 ] Wei Wei, Lianghao Xia, and Chao Huang. Multi-relational contrastive learning for rec- ommendation. In Proceedings of the 17th ACM conference on recommender systems, pages 338–349,
2023
-
[23]
Self-supervised graph co-training for session-based recommendation
[Xia et al., 2021 ] Xin Xia, Hongzhi Yin, Junliang Yu, Yingxia Shao, and Lizhen Cui. Self-supervised graph co-training for session-based recommendation. In Pro- ceedings of the 30th ACM international conference on information & knowledge management, pages 2180– 2190,
2021
-
[24]
Contrastive learning for sequential rec- ommendation
[Xie et al., 2022 ] Xu Xie, Fei Sun, Zhaoyang Liu, Shi- wen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. Contrastive learning for sequential rec- ommendation. In 2022 IEEE 38th international con- ference on data engineering (ICDE), pages 1259–1273. IEEE,
2022
-
[25]
Sequential recommender system based on hierarchical attention network
[Ying et al., 2018 ] Haochao Ying, Fuzhen Zhuang, Fuzheng Zhang, Yanchi Liu, Guandong Xu, Xing Xie, Hui Xiong, and Jian Wu. Sequential recommender system based on hierarchical attention network. In IJCAI international joint conference on artificial in- telligence,
2018
-
[26]
Adaptive user modeling with long and short-term preferences for per- sonalized recommendation
[Yu et al., 2019 ] Zeping Yu, Jianxun Lian, Ahmad Mah- moody, Gongshen Liu, and Xing Xie. Adaptive user modeling with long and short-term preferences for per- sonalized recommendation. In IJCAI, volume 7, pages 4213–4219,
2019
-
[27]
Denoising long-and short-term interests for sequential recommendation
[Zhang et al., 2024 ] Xinyu Zhang, Beibei Li, and Bei- hong Jin. Denoising long-and short-term interests for sequential recommendation. In Proceedings of the 2024 SIAM International Conference on Data Mining (SDM), pages 544–552. SIAM,
2024
-
[28]
Plas- tic: Prioritize long and short-term information in top- n recommendation using adversarial training
[Zhao et al., 2018 ] Wei Zhao, Benyou Wang, Jianbo Ye, Yongqiang Gao, Min Yang, and Xiaojun Chen. Plas- tic: Prioritize long and short-term information in top- n recommendation using adversarial training. In Ijcai, pages 3676–3682,
2018
-
[29]
Disentangling long and short-term interests for recommendation
[Zheng et al., 2022 ] Yu Zheng, Chen Gao, Jianxin Chang, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. Disentangling long and short-term interests for recommendation. In Proceedings of the ACM Web Conference 2022, pages 2256–2267,
2022
-
[30]
Deep interest network for click-through rate prediction
[Zhou et al., 2018 ] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. In Pro- ceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1059–1068,
2018
-
[31]
Deep interest evolution network for click- through rate prediction
[Zhou et al., 2019 ] Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep interest evolution network for click- through rate prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 5941–5948,
2019
-
[32]
Dynamic multi-objective optimization frame- work with interactive evolution for sequential recom- mendation
[Zhou et al., 2023b ] Wei Zhou, Yong Liu, Min Li, Yu Wang, Zhiqi Shen, Liang Feng, and Zexuan Zhu. Dynamic multi-objective optimization frame- work with interactive evolution for sequential recom- mendation. IEEE Transactions on Emerging Topics in Computational Intelligence, 7(4):1228–1241, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.