Recognition: no theorem link
Beyond Fixed Tests: Repository-Level Issue Resolution as Coevolution of Code and Behavioral Constraints
Pith reviewed 2026-05-10 20:08 UTC · model grok-4.3
The pith
Repository-level issue resolution requires coevolving code and tests rather than optimizing against fixed tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
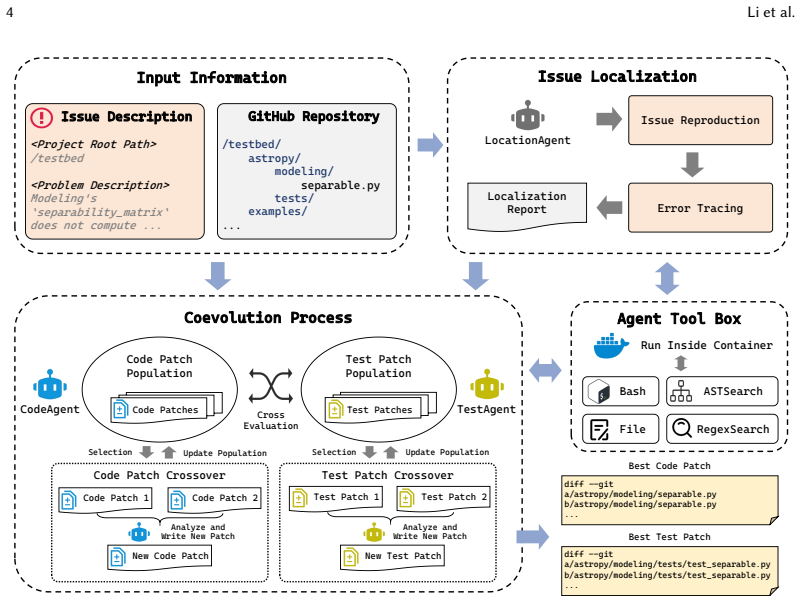
The authors claim that repository-level issue resolution is fundamentally not optimization under fixed tests, but search over evolving behavioral constraints. They operationalize this view with Agent-CoEvo, a coevolutionary multi-agent framework in which candidate code patches and test patches are jointly explored, iteratively refined through mutual evaluation, and recombined semantically to narrow the space of behavior consistent with the issue description. On SWE-bench Lite and SWT-bench Lite, the framework outperforms state-of-the-art agent-based and agentless baselines in both repair success and test reproduction quality.
What carries the argument
Agent-CoEvo, a coevolutionary multi-agent framework that treats tests as dynamic constraints which both guide and are revised by the code repair process.
If this is right
- Higher repair success rates on SWE-bench Lite and SWT-bench Lite than baselines that keep tests fixed.
- Improved quality of reproduced tests that better align with the original issue description.
- Fewer brittle or overfitted fixes because constraints evolve with the code.
- A shift in automated repair from code-only optimization to coevolution of implementation and specification.
Where Pith is reading between the lines
- Similar coevolution of implementation and specification could apply to other incomplete-specification settings such as API evolution or formal method assistance.
- Repair benchmarks may need new metrics that measure alignment with revised intent rather than only passage of the original tests.
- Interactive tools could let developers review and steer the evolved constraints to prevent unintended drift.
Load-bearing premise
Mutual evaluation and semantic recombination between code and test candidates will reliably narrow the space of behavior consistent with the issue description without introducing new inconsistencies or losing the original intent.
What would settle it
A concrete case on the evaluation benchmarks where the coevolved tests accept a patch that independent human review determines fails to address the reported issue or where the evolved tests diverge from the bug report in ways that mask the actual fault.
Figures





read the original abstract
Software engineers resolving repository-level issues do not treat existing tests as immutable correctness oracles. Instead, they iteratively refine both code and the tests used to characterize intended behavior, as new modifications expose missing assumptions or misinterpreted failure conditions. In contrast, most existing large language model (LLM)-based repair systems adopt a linear pipeline in which tests or other validation signals act mostly as post-hoc filters, treating behavioral constraints as fixed during repair. This formulation reduces repair to optimizing code under static and potentially misaligned constraints, leading to under-constrained search and brittle or overfitted fixes. We argue that repository-level issue resolution is fundamentally not optimization under fixed tests, but search over evolving behavioral constraints. To operationalize this view, we propose Agent-CoEvo, a coevolutionary multi-agent framework in which candidate code patches and test patches are jointly explored and iteratively refined. Rather than treating tests as immutable oracles, our framework models them as dynamic constraints that both guide and are revised by the repair process. Through mutual evaluation and semantic recombination, code and test candidates progressively narrow the space of behavior consistent with the issue description. Evaluated on SWE-bench Lite and SWT-bench Lite, Agent-CoEvo consistently outperforms state-of-the-art agent-based and agentless baselines in both repair success and test reproduction quality. Our findings suggest that enabling repair agents to revise behavioral constraints during search is critical for reliable issue resolution, pointing toward a shift from code-only optimization to coevolution of implementation and specification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that repository-level issue resolution is not optimization under fixed tests but search over evolving behavioral constraints. It proposes Agent-CoEvo, a multi-agent coevolutionary framework in which code patches and test patches are jointly explored and refined via mutual evaluation and semantic recombination to narrow the behavior space consistent with the issue description. On SWE-bench Lite and SWT-bench Lite, Agent-CoEvo outperforms state-of-the-art agent-based and agentless baselines in both repair success and test reproduction quality.
Significance. If the central claims hold, this work would be significant for automated program repair and LLM-based software engineering agents by shifting from linear fixed-oracle pipelines to dynamic coevolution of code and tests, aligning better with developer practice. A clear strength is the use of external benchmarks (SWE-bench Lite, SWT-bench Lite) rather than self-referential quantities, avoiding circularity. The empirical outperformance, if robustly validated, would support the broader claim that revising behavioral constraints during search improves reliability.
major comments (3)
- [Abstract] Abstract: The claim that 'through mutual evaluation and semantic recombination, code and test candidates progressively narrow the space of behavior consistent with the issue description' is load-bearing for the central thesis but provides no concrete mechanism (e.g., entailment checks against the bug report, embedding similarity, or rejection sampling on original failure conditions) to prevent test drift or loss of original intent. Without this, reported gains in repair success and test reproduction quality could stem from expanded search rather than faithful coevolution.
- [Evaluation section] Evaluation on SWE-bench Lite and SWT-bench Lite: No details are given on experimental controls for how test revisions are validated against the original issue intent, whether post-hoc adjustments occurred, or how 'test reproduction quality' is measured to confirm fidelity. This directly weakens support for the outperformance claims and the assertion that coevolution is critical for reliable resolution.
- [Agent-CoEvo framework] Framework description: The mutual evaluation step is presented as reliably narrowing consistent behavior, yet the manuscript does not specify rejection criteria or grounding steps that would address the risk of introducing new inconsistencies while preserving the bug report semantics. This is load-bearing for the weakest assumption in the coevolution operationalization.
minor comments (2)
- [Abstract] The term 'test reproduction quality' is used in the abstract and results without an explicit definition or formula in the provided text; add a precise metric description early in the evaluation section.
- Figure or table captions (if present in the full manuscript) should explicitly state the number of runs, statistical significance tests, and baseline configurations to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies important areas for clarification in our presentation of the coevolution approach. We agree that greater specificity on mechanisms and controls will strengthen the manuscript and will make the requested revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'through mutual evaluation and semantic recombination, code and test candidates progressively narrow the space of behavior consistent with the issue description' is load-bearing for the central thesis but provides no concrete mechanism (e.g., entailment checks against the bug report, embedding similarity, or rejection sampling on original failure conditions) to prevent test drift or loss of original intent. Without this, reported gains in repair success and test reproduction quality could stem from expanded search rather than faithful coevolution.
Authors: We acknowledge that the abstract states the high-level claim without enumerating the concrete safeguards. The full framework section describes mutual evaluation via embedding-based semantic similarity to the issue description combined with rejection sampling on consistency with the original failing conditions. We will revise the abstract to include a concise reference to these steps (entailment-style consistency checks and rejection on drift from the reported failure) so the central thesis is better grounded. revision: yes
-
Referee: [Evaluation section] Evaluation on SWE-bench Lite and SWT-bench Lite: No details are given on experimental controls for how test revisions are validated against the original issue intent, whether post-hoc adjustments occurred, or how 'test reproduction quality' is measured to confirm fidelity. This directly weakens support for the outperformance claims and the assertion that coevolution is critical for reliable resolution.
Authors: We agree that the evaluation section would benefit from explicit controls. We will add a dedicated paragraph describing: (1) validation of revised tests against the original issue description and failure reproduction on the pre-patch codebase, (2) confirmation that no post-hoc test adjustments were performed after patch generation, and (3) the exact metric for test reproduction quality (semantic alignment plus reproduction of the original failing behavior). These additions will directly support the reported gains. revision: yes
-
Referee: [Agent-CoEvo framework] Framework description: The mutual evaluation step is presented as reliably narrowing consistent behavior, yet the manuscript does not specify rejection criteria or grounding steps that would address the risk of introducing new inconsistencies while preserving the bug report semantics. This is load-bearing for the weakest assumption in the coevolution operationalization.
Authors: We accept that the current description leaves the rejection criteria implicit. We will expand the framework section with explicit rejection rules: a candidate test patch is rejected if its embedding similarity to the issue description falls below a threshold or if it fails to reproduce the original failure on the unmodified code. We will also include a short example illustrating preservation of bug-report semantics during recombination. revision: yes
Circularity Check
No significant circularity; central claim and framework are independent of evaluation metrics
full rationale
The paper reframes issue resolution as coevolution of code and tests, operationalized via the Agent-CoEvo multi-agent framework using mutual evaluation and semantic recombination. This is presented as a conceptual shift from fixed-test optimization, with no equations, fitted parameters, or self-referential definitions in the abstract or described structure. Evaluation relies on external benchmarks (SWE-bench Lite, SWT-bench Lite) and comparisons to independent baselines, not on quantities defined from the method itself. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via prior work are identifiable. The derivation chain remains self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Agent-CoEvo multi-agent coevolutionary framework
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
- [5]
-
[6]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Earl T Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. 2014. The oracle problem in software testing: A survey.IEEE transactions on software engineering41, 5 (2014), 507–525
2014
- [8]
- [9]
-
[10]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [11]
-
[12]
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2023. Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128(2023)
work page internal anchor Pith review arXiv 2023
- [13]
-
[14]
Yoav Freund and Robert E Schapire. 1997. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences55, 1 (1997), 119–139
1997
- [15]
-
[16]
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Quentin Carbonneaux, Taco Cohen, and Gabriel Synnaeve
- [17]
-
[18]
Lianghong Guo, Wei Tao, Runhan Jiang, Yanlin Wang, Jiachi Chen, Xilin Liu, Yuchi Ma, Mingzhi Mao, Hongyu Zhang, and Zibin Zheng. 2025. Omnigirl: A multilingual and multimodal benchmark for github issue resolution.Proceedings , Vol. 1, No. 1, Article . Publication date: April 2025. 20 Li et al. of the ACM on Software Engineering2, ISSTA (2025), 24–46
2025
-
[19]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[20]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Sungmin Kang, Juyeon Yoon, and Shin Yoo. 2023. Large language models are few-shot testers: Exploring llm-based general bug reproduction. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2312–2323
2023
- [22]
- [23]
-
[24]
Han Li, Yuling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin Wang, Yantao Jia, Tao Huang, and Qianxiang Wang
- [25]
-
[26]
Kefan Li, Yuan Yuan, Hongyue Yu, Tingyu Guo, and Shijie Cao. 2025. CoCoEvo: Co-Evolution of Programs and Test Cases to Enhance Code Generation.IEEE Transactions on Evolutionary Computation(2025)
2025
-
[27]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with alphacode.Science378, 6624 (2022), 1092–1097
2022
-
[28]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
- [30]
- [31]
-
[32]
Yingwei Ma, Qingping Yang, Rongyu Cao, Binhua Li, Fei Huang, and Yongbin Li. 2025. Alibaba lingmaagent: Improving automated issue resolution via comprehensive repository exploration. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 238–249
2025
-
[33]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2023. Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems36 (2023), 46534–46594
2023
-
[34]
Fangwen Mu, Junjie Wang, Lin Shi, Song Wang, Shoubin Li, and Qing Wang. 2025. EXPEREPAIR: Dual-Memory Enhanced LLM-based Repository-Level Program Repair.arXiv preprint arXiv:2506.10484(2025)
work page internal anchor Pith review arXiv 2025
-
[35]
Niels Mündler, Mark Müller, Jingxuan He, and Martin Vechev. 2024. SWT-bench: Testing and validating real-world bug-fixes with code agents.Advances in Neural Information Processing Systems37 (2024), 81857–81887
2024
- [36]
-
[37]
Ansong Ni, Srini Iyer, Dragomir Radev, Veselin Stoyanov, Wen-tau Yih, Sida Wang, and Xi Victoria Lin. 2023. Lever: Learning to verify language-to-code generation with execution. InInternational Conference on Machine Learning. PMLR, 26106–26128
2023
-
[38]
Pengyu Nie, Rahul Banerjee, Junyi Jessy Li, Raymond J Mooney, and Milos Gligoric. 2023. Learning deep semantics for test completion. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2111–2123
2023
- [39]
- [40]
-
[41]
Ravin Ravi, Dylan Bradshaw, Stefano Ruberto, Gunel Jahangirova, and Valerio Terragni. 2025. LLMLOOP: Improving LLM-Generated Code and Tests through Automated Iterative Feedback Loops.ICSME. IEEE(2025)
2025
- [42]
-
[43]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2023. An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering50, 1 (2023), 85–105. , Vol. 1, No. 1, Article . Publication date: April 2025. Beyond Fixed Tests: Repository-Level Issue Resolution as Coevolution of Code and Behav...
2023
-
[44]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems36 (2023), 8634–8652
2023
- [45]
- [46]
-
[47]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review arXiv 2024
-
[48]
You Wang, Michael Pradel, and Zhongxin Liu. 2025. Are" Solved Issues" in SWE-bench Really Solved Correctly? An Empirical Study.arXiv preprint arXiv:2503.15223(2025)
-
[49]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review arXiv 2024
-
[50]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
- [51]
-
[52]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[53]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604
2024
-
[54]
Albert Örwall. 2024. Moatless Tools. https://github.com/aorwall/moatless-tools. Accessed: 2024-11-13. , Vol. 1, No. 1, Article . Publication date: April 2025
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.