Recognition: unknown
A Clinical Point Cloud Paradigm for In-Hospital Mortality Prediction from Multi-Level Incomplete Multimodal EHRs
Pith reviewed 2026-05-10 19:41 UTC · model grok-4.3
The pith
Representing clinical events as points in 4D space enables accurate mortality prediction from incomplete multimodal EHRs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
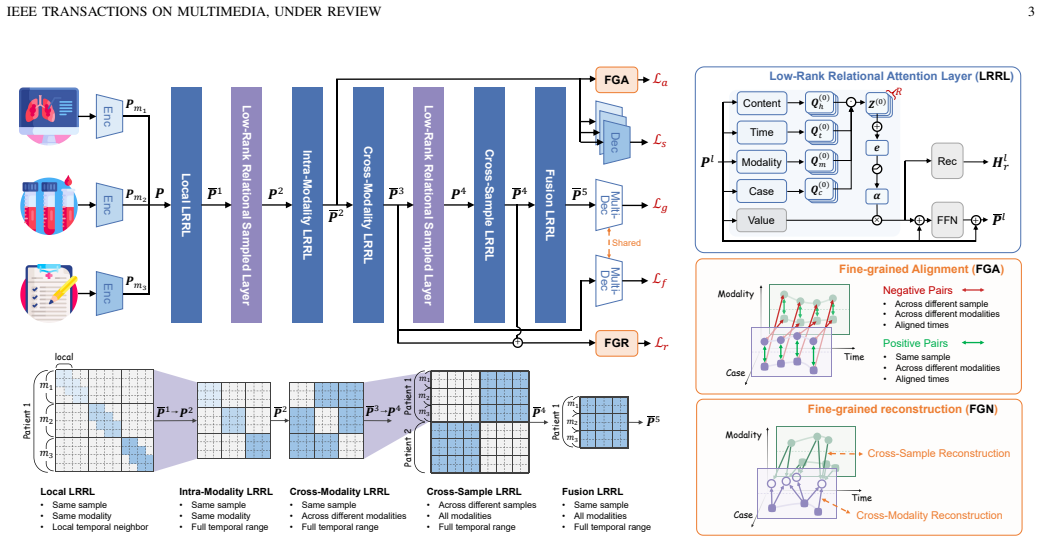
HealthPoint (HP) is a unified paradigm that represents heterogeneous clinical events as points in a continuous 4D space defined by content, time, modality, and case. Low-Rank Relational Attention efficiently captures high-order dependencies across arbitrary point pairs in these dimensions. A hierarchical interaction and sampling strategy balances fine-grained modeling with computational cost. The resulting framework supports flexible event-level interaction, fine-grained self-supervision, robust modality recovery, and effective use of unlabeled data for in-hospital mortality prediction.
What carries the argument
The 4D clinical point cloud (content, time, modality, case) together with Low-Rank Relational Attention that models interactions between any pair of points while remaining computationally tractable.
If this is right
- HP reaches state-of-the-art performance on large-scale EHR datasets for in-hospital mortality prediction.
- The model maintains strong robustness when incompleteness varies across irregular sampling, missing modalities, and sparse labels.
- Fine-grained self-supervision allows effective use of unlabeled records without requiring complete outcome data.
- Low-rank attention enables modality recovery while avoiding rigid temporal or modal alignment steps.
Where Pith is reading between the lines
- The same point-cloud construction could be tested on other clinical time-series tasks such as length-of-stay or readmission prediction where incompleteness is also common.
- If the 4D representation generalizes, it may reduce reliance on separate imputation pipelines that currently dominate healthcare ML preprocessing.
- Hospitals could experiment with deploying the model on streaming records that arrive with variable completeness rather than waiting for batch completion.
Load-bearing premise
Representing clinical events as points in a continuous 4D space and modeling their interactions with low-rank attention preserves raw clinical semantics without distortion under irregular sampling, missing modalities, and sparse labels.
What would settle it
Run HP and standard imputation or alignment baselines on the same large EHR dataset with artificially increased missingness rates; if HP's mortality prediction AUC falls below the baselines at high incompleteness levels, the claim that the 4D point representation avoids semantic distortion would be refuted.
Figures




read the original abstract
Deep learning-based modeling of multimodal Electronic Health Records (EHRs) has become an important approach for clinical diagnosis and risk prediction. However, due to diverse clinical workflows and privacy constraints, raw EHRs are inherently multi-level incomplete, including irregular sampling, missing modalities, and sparse labels. These issues cause temporal misalignment, modality imbalance, and limited supervision. Most existing multimodal methods assume relatively complete data, and even methods designed for incompleteness usually address only one or two of these issues in isolation. As a result, they often rely on rigid temporal/modal alignment or discard incomplete data, which may distort raw clinical semantics. To address this problem, we propose HealthPoint (HP), a unified clinical point cloud paradigm for multi-level incomplete EHRs. HP represents heterogeneous clinical events as points in a continuous 4D space defined by content, time, modality, and case. To model interactions between arbitrary point pairs, we introduce a Low-Rank Relational Attention mechanism that efficiently captures high-order dependencies across these four dimensions. We further develop a hierarchical interaction and sampling strategy to balance fine-grained modeling and computational efficiency. Built on this framework, HP enables flexible event-level interaction and fine-grained self-supervision, supporting robust modality recovery and effective use of unlabeled data. Experiments on large-scale EHR datasets for risk prediction show that HP consistently achieves state-of-the-art performance and strong robustness under varying degrees of incompleteness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HealthPoint (HP), a unified clinical point cloud paradigm for in-hospital mortality prediction from multi-level incomplete multimodal EHRs. It represents heterogeneous clinical events as points in a continuous 4D space (content, time, modality, case), models pairwise interactions with a Low-Rank Relational Attention mechanism, and employs a hierarchical interaction and sampling strategy to support event-level modeling, modality recovery, and self-supervision on unlabeled data. Experiments on large-scale EHR datasets are reported to show state-of-the-art performance and robustness under varying degrees of incompleteness (irregular sampling, missing modalities, sparse labels).
Significance. If the empirical claims hold, the work would be significant for clinical machine learning by providing a single framework that simultaneously addresses multiple incompleteness issues common in real-world EHRs, avoiding the distortions from rigid alignments or data discarding seen in prior methods. The adaptation of point-cloud and low-rank attention ideas to clinical events, plus the emphasis on flexible self-supervision, represents a substantive modeling advance with potential for broader applicability in risk prediction tasks.
major comments (2)
- [§3.2] §3.2 (Low-Rank Relational Attention): The central robustness claim under high incompleteness rests on the low-rank factorization recovering high-order 4D dependencies even when many points are absent or irregularly spaced. No approximation-error bound or ablation isolating the rank choice versus full attention is provided, leaving open the possibility that the mechanism systematically loses sparse but clinically informative interactions precisely in the regimes the method targets.
- [§4.3] §4.3 (Ablation and incompleteness experiments): The hierarchical sampling strategy is asserted to balance fine-grained modeling with efficiency without discarding informative events, yet the reported ablations do not quantify information loss (e.g., via event-type retention rates or downstream performance drop when sampling is disabled) across the full range of incompleteness levels. This directly affects whether the 4D embedding preserves raw clinical semantics.
minor comments (2)
- [Abstract] The abstract and §4.1 refer to 'large-scale EHR datasets' without naming them or reporting cohort sizes and missingness statistics; adding these would strengthen reproducibility and allow readers to judge the severity of the incompleteness regimes tested.
- [§3.1] Notation for the 4D point coordinates (content, time, modality, case) is introduced descriptively but lacks an explicit embedding equation; a single displayed equation would clarify how discrete heterogeneous events are mapped into the continuous space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of the Low-Rank Relational Attention mechanism and the evaluation of the hierarchical sampling strategy. We address each point below and will revise the manuscript to incorporate additional analyses where feasible.
read point-by-point responses
-
Referee: §3.2 (Low-Rank Relational Attention): The central robustness claim under high incompleteness rests on the low-rank factorization recovering high-order 4D dependencies even when many points are absent or irregularly spaced. No approximation-error bound or ablation isolating the rank choice versus full attention is provided, leaving open the possibility that the mechanism systematically loses sparse but clinically informative interactions precisely in the regimes the method targets.
Authors: We agree that a theoretical approximation-error bound would further strengthen the robustness claims. Deriving a tight bound for high-order 4D dependencies under irregular sampling and missing points is non-trivial and beyond the current scope; we note this limitation explicitly in the revision. Empirically, the manuscript already includes performance comparisons showing that the low-rank mechanism achieves state-of-the-art results with substantially lower computational cost than full attention, and maintains accuracy across high incompleteness regimes. To directly address the concern about sparse interactions, we will add a targeted ablation in the revised version that (i) varies the rank hyperparameter and (ii) evaluates retention of performance on subsets containing rare but clinically critical events. This will isolate the effect of the factorization on sparse signals. revision: partial
-
Referee: §4.3 (Ablation and incompleteness experiments): The hierarchical sampling strategy is asserted to balance fine-grained modeling with efficiency without discarding informative events, yet the reported ablations do not quantify information loss (e.g., via event-type retention rates or downstream performance drop when sampling is disabled) across the full range of incompleteness levels. This directly affects whether the 4D embedding preserves raw clinical semantics.
Authors: We appreciate this suggestion for more granular evaluation. The hierarchical sampling is designed to retain events according to temporal density and modality relevance, but the current ablations primarily report end-to-end predictive metrics. In the revision we will add explicit quantification of information preservation: event-type retention rates (broken down by modality and clinical category) and the performance delta when the sampling module is disabled, evaluated across the full spectrum of incompleteness levels already tested in the paper. These additions will provide direct evidence that the 4D point-cloud representation maintains raw clinical semantics under the proposed sampling strategy. revision: yes
Circularity Check
No significant circularity; framework is an explicit modeling choice validated empirically
full rationale
The paper introduces HealthPoint as a proposed paradigm that represents clinical events as 4D points and applies low-rank relational attention plus hierarchical sampling to handle multi-level incompleteness in EHRs. These elements are described as design decisions to enable flexible interactions and self-supervision, not as quantities derived from prior results or fitted parameters that are then relabeled as predictions. No equations or steps in the abstract reduce by construction to the inputs (e.g., no self-definitional mapping where the output is the fit itself, no uniqueness theorem imported from self-citation, and no renaming of known patterns as new unification). Performance claims rest on experimental results across datasets rather than tautological equivalence, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous clinical events can be represented as points in a continuous 4D space defined by content, time, modality, and case without loss of clinical semantics.
invented entities (2)
-
HealthPoint (HP) paradigm
no independent evidence
-
Low-Rank Relational Attention mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mimic-iii, a freely accessible critical care database,
A. E. Johnson, T. J. Pollard, L. Shen, L.-w. H. Lehman, M. Feng, M. Ghassemi, B. Moody, P. Szolovits, L. Anthony Celi, and R. G. Mark, “Mimic-iii, a freely accessible critical care database,”Scientific data, vol. 3, no. 1, pp. 1–9, 2016
2016
-
[2]
Artificial intelligence- based methods for fusion of electronic health records and imaging data,
F. Mohsen, H. Ali, N. El Hajj, and Z. Shah, “Artificial intelligence- based methods for fusion of electronic health records and imaging data,” Scientific Reports, vol. 12, no. 1, p. 17981, 2022
2022
-
[3]
Multimodal pretraining of medical time series and notes,
R. King, T. Yang, and B. J. Mortazavi, “Multimodal pretraining of medical time series and notes,” inMachine Learning for Health (ML4H). PMLR, 2023, pp. 244–255
2023
-
[4]
The future of multimodal artificial intelligence models for integrating imaging and clinical metadata: a narrative review,
B. D. Simon, K. B. Ozyoruk, D. G. Gelikman, S. A. Harmon, and B. T ¨urkbey, “The future of multimodal artificial intelligence models for integrating imaging and clinical metadata: a narrative review,” Diagnostic and Interventional Radiology, vol. 31, no. 4, p. 303, 2025
2025
-
[5]
M3care: Learning with missing modalities in multimodal healthcare data,
C. Zhang, X. Chu, L. Ma, Y . Zhu, Y . Wang, J. Wang, and J. Zhao, “M3care: Learning with missing modalities in multimodal healthcare data,” inProceedings of the 28th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining, 2022, pp. 2418–2428
2022
-
[6]
Improving medical predictions by irregular multimodal electronic health records modeling,
X. Zhang, S. Li, Z. Chen, X. Yan, and L. R. Petzold, “Improving medical predictions by irregular multimodal electronic health records modeling,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 41 300–41 313
2023
-
[7]
Prime: Pretraining for patient condition representation with irregular multimodal electronic health records,
B. Li, B. Du, and J. Ye, “Prime: Pretraining for patient condition representation with irregular multimodal electronic health records,”ACM Transactions on Knowledge Discovery from Data, vol. 19, no. 7, pp. 1– 39, 2025
2025
-
[8]
Multimodal missing data in healthcare: A comprehensive review and future directions,
L. P. Le, T. Nguyen, M. A. Riegler, P. Halvorsen, and B. T. Nguyen, “Multimodal missing data in healthcare: A comprehensive review and future directions,”Computer Science Review, vol. 56, p. 100720, 2025
2025
-
[9]
Hierarchical pretraining on multimodal electronic health records,
X. Wang, J. Luo, J. Wang, Z. Yin, S. Cui, Y . Zhong, Y . Wang, and F. Ma, “Hierarchical pretraining on multimodal electronic health records,” inProceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, vol. 2023, 2023, p. 2839
2023
-
[10]
Recurrent neural networks for multivariate time series with missing values,
Z. Che, S. Purushotham, K. Cho, D. Sontag, and Y . Liu, “Recurrent neural networks for multivariate time series with missing values,” Scientific reports, vol. 8, no. 1, p. 6085, 2018
2018
-
[11]
Multimodal patient representation learning with missing modalities and labels,
Z. Wu, A. Dadu, N. Tustison, B. Avants, M. Nalls, J. Sun, and F. Faghri, “Multimodal patient representation learning with missing modalities and labels,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Redcore: Rela- tive advantage aware cross-modal representation learning for missing modalities with imbalanced missing rates,
J. Sun, X. Zhang, S. Han, Y .-P. Ruan, and T. Li, “Redcore: Rela- tive advantage aware cross-modal representation learning for missing modalities with imbalanced missing rates,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 13, 2024, pp. 15 173– 15 182
2024
-
[13]
Diffmv: A unified diffusion framework for healthcare predictions with random missing views and view laziness,
C. Zhao, H. Tang, H. Zhao, and X. Li, “Diffmv: A unified diffusion framework for healthcare predictions with random missing views and view laziness,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 3933–3944
2025
-
[14]
Drfuse: Learning disentangled representation for clinical multi-modal fusion with missing modality and modal inconsistency,
W. Yao, K. Yin, W. K. Cheung, J. Liu, and J. Qin, “Drfuse: Learning disentangled representation for clinical multi-modal fusion with missing modality and modal inconsistency,” inProceedings of the AAAI confer- ence on artificial intelligence, vol. 38, no. 15, 2024, pp. 16 416–16 424
2024
-
[15]
Flex- care: Leveraging cross-task synergy for flexible multimodal healthcare prediction,
M. Xu, Z. Zhu, Y . Li, S. Zheng, Y . Zhao, K. He, and Y . Zhao, “Flex- care: Leveraging cross-task synergy for flexible multimodal healthcare prediction,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 3610–3620
2024
-
[16]
Self-supervised multimodal learning: A survey,
Y . Zong, O. Mac Aodha, and T. M. Hospedales, “Self-supervised multimodal learning: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 7, pp. 5299–5318, 2024
2024
-
[17]
Vecocare: Visit sequences-clinical notes joint learning for diagnosis prediction in healthcare data
Y . Xu, K. Yang, C. Zhang, P. Zou, Z. Wang, H. Ding, J. Zhao, Y . Wang, and B. Xie, “Vecocare: Visit sequences-clinical notes joint learning for diagnosis prediction in healthcare data.” inIJCAI, vol. 23, 2023, pp. 4921–4929
2023
-
[18]
Learn- ing missing modal electronic health records with unified multi-modal data embedding and modality-aware attention,
K. Lee, S. Lee, S. Hahn, H. Hyun, E. Choi, B. Ahn, and J. Lee, “Learn- ing missing modal electronic health records with unified multi-modal data embedding and modality-aware attention,” inMachine Learning for Healthcare Conference. PMLR, 2023, pp. 423–442
2023
-
[19]
The false hope of current approaches to explainable artificial intelligence in health care,
M. Ghassemi, L. Oakden-Rayner, and A. L. Beam, “The false hope of current approaches to explainable artificial intelligence in health care,” The lancet digital health, vol. 3, no. 11, pp. e745–e750, 2021
2021
-
[20]
Learning the natural history IEEE TRANSACTIONS ON MULTIMEDIA, UNDER REVIEW 10 of human disease with generative transformers,
A. Shmatko, A. W. Jung, K. Gaurav, S. Brunak, L. H. Mortensen, E. Birney, T. Fitzgerald, and M. Gerstung, “Learning the natural history IEEE TRANSACTIONS ON MULTIMEDIA, UNDER REVIEW 10 of human disease with generative transformers,”Nature, vol. 647, no. 8088, pp. 248–256, 2025
2025
-
[21]
Large language models forecast patient health trajectories enabling digital twins,
N. Makarov, M. Bordukova, P. Quengdaeng, D. Garger, R. Rodriguez- Esteban, F. Schmich, and M. P. Menden, “Large language models forecast patient health trajectories enabling digital twins,”npj Digital Medicine, vol. 8, no. 1, p. 588, 2025
2025
-
[22]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[23]
Point transformer,
H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V . Koltun, “Point transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16 259–16 268
2021
-
[24]
Multilayer feedforward networks are universal approximators,
K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators,”Neural networks, vol. 2, no. 5, pp. 359–366, 1989
1989
-
[25]
Y . Li, R. M. Wehbe, F. S. Ahmad, H. Wang, and Y . Luo, “Clinical- longformer and clinical-bigbird: Transformers for long clinical se- quences,”arXiv preprint arXiv:2201.11838, 2022
-
[26]
On the limits of cross-domain generalization in automated x-ray prediction,
J. P. Cohen, M. Hashir, R. Brooks, and H. Bertrand, “On the limits of cross-domain generalization in automated x-ray prediction,” inMedical Imaging with Deep Learning, 2020. [Online]. Available: https://arxiv.org/abs/2002.02497
-
[27]
Warpformer: A multi-scale modeling approach for irregular clinical time series,
J. Zhang, S. Zheng, W. Cao, J. Bian, and J. Li, “Warpformer: A multi-scale modeling approach for irregular clinical time series,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 3273–3285
2023
-
[28]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
K. Cho, B. Van Merri ¨enboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation,”arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review arXiv 2014
-
[29]
Tensor decompositions and applications,
T. G. Kolda and B. W. Bader, “Tensor decompositions and applications,” SIAM review, vol. 51, no. 3, pp. 455–500, 2009
2009
-
[30]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[31]
Multimodal machine learning: A survey and taxonomy,
T. Baltru ˇsaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,”IEEE transactions on pattern anal- ysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018
2018
-
[32]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning. PmLR, 2020, pp. 1597–1607
2020
-
[33]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,”The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948
1948
-
[34]
Learning Confidence for Out -of-Distribution Detection in Neural Networks,
T. DeVries and G. W. Taylor, “Learning confidence for out- of-distribution detection in neural networks,”arXiv preprint arXiv:1802.04865, 2018
-
[35]
Mimic- iv, a freely accessible electronic health record dataset,
A. E. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gowet al., “Mimic- iv, a freely accessible electronic health record dataset,”Scientific data, vol. 10, no. 1, p. 1, 2023
2023
-
[36]
Multitask learning and benchmarking with clinical time series data,
H. Harutyunyan, H. Khachatrian, D. C. Kale, G. Ver Steeg, and A. Galstyan, “Multitask learning and benchmarking with clinical time series data,”Scientific data, vol. 6, no. 1, p. 96, 2019
2019
-
[37]
Heart: Learning better representation of ehr data with a heterogeneous relation-aware transformer,
T. Huang, S. A. Rizvi, R. K. Thakur, V . Socrates, M. Gupta, D. van Dijk, R. A. Taylor, and R. Ying, “Heart: Learning better representation of ehr data with a heterogeneous relation-aware transformer,”Journal of Biomedical Informatics, vol. 159, p. 104741, 2024
2024
-
[38]
Multi-task heterogeneous graph learning on electronic health records,
T. H. Chan, G. Yin, K. Bae, and L. Yu, “Multi-task heterogeneous graph learning on electronic health records,”Neural Networks, vol. 180, p. 106644, 2024
2024
-
[39]
Towards robust multimodal representation: A unified approach with adaptive experts and alignment,
N. Moradinasab, S. Sengupta, J. Liu, S. Syed, and D. E. Brown, “Towards robust multimodal representation: A unified approach with adaptive experts and alignment,”arXiv preprint arXiv:2503.09498, 2025
-
[40]
Ehrcon: Dataset for checking consistency between unstructured notes and structured tables in electronic health records,
Y . Kwon, J. Kim, G. Lee, S. Bae, D. Kyung, W. Cha, T. Pollard, A. Johnson, and E. Choi, “Ehrcon: Dataset for checking consistency between unstructured notes and structured tables in electronic health records,”Advances in Neural Information Processing Systems, vol. 37, pp. 89 334–89 345, 2024
2024
-
[41]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019
2019
-
[42]
Multimodal transformer for unaligned multimodal language sequences,
Y .-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the 57th annual meeting of the association for computational linguistics, 2019, pp. 6558–6569
2019
-
[43]
Con- trastive learning of medical visual representations from paired images and text,
Y . Zhang, H. Jiang, Y . Miura, C. D. Manning, and C. P. Langlotz, “Con- trastive learning of medical visual representations from paired images and text,” inMachine learning for healthcare conference. PMLR, 2022, pp. 2–25
2022
-
[44]
Moe-health: A mixture of experts framework for robust multimodal healthcare prediction,
X. Wang and C. Yang, “Moe-health: A mixture of experts framework for robust multimodal healthcare prediction,” inProceedings of the 16th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, 2025, pp. 1–9
2025
-
[45]
Large language models encode clinical knowledge,
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohlet al., “Large language models encode clinical knowledge,”Nature, vol. 620, no. 7972, pp. 172– 180, 2023
2023
-
[46]
Towards generalist biomedical ai,
T. Tu, S. Azizi, D. Driess, M. Schaekermann, M. Amin, P.-C. Chang, A. Carroll, C. Lau, R. Tanno, I. Ktenaet al., “Towards generalist biomedical ai,”Nejm Ai, vol. 1, no. 3, p. AIoa2300138, 2024
2024
-
[47]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,”Advances in Neural Information Processing Systems, vol. 36, pp. 28 541–28 564, 2023
2023
-
[48]
Building a knowledge graph to enable precision medicine,
P. Chandak, K. Huang, and M. Zitnik, “Building a knowledge graph to enable precision medicine,”Scientific Data, vol. 10, no. 1, p. 67, 2023
2023
-
[49]
Kerprint: local-global knowledge graph enhanced diagnosis prediction for retrospective and prospective interpretations,
K. Yang, Y . Xu, P. Zou, H. Ding, J. Zhao, Y . Wang, and B. Xie, “Kerprint: local-global knowledge graph enhanced diagnosis prediction for retrospective and prospective interpretations,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 4, 2023, pp. 5357–5365
2023
-
[50]
From observation to concept: A flexible multi-view paradigm for medical report generation,
Z. Liu, Z. Zhu, S. Zheng, Y . Zhao, K. He, and Y . Zhao, “From observation to concept: A flexible multi-view paradigm for medical report generation,”IEEE Transactions on Multimedia, vol. 26, pp. 5987– 5995, 2023
2023
-
[51]
Contiformer: Continuous-time transformer for irregular time series modeling,
Y . Chen, K. Ren, Y . Wang, Y . Fang, W. Sun, and D. Li, “Contiformer: Continuous-time transformer for irregular time series modeling,”Ad- vances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[52]
Trajgpt: Irregular time-series representation learning of health trajectory,
Z. Song, Q. Lu, H. Zhu, D. Buckeridge, and Y . Li, “Trajgpt: Irregular time-series representation learning of health trajectory,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[53]
Tee4ehr: Transformer event encoder for better representation learning in electronic health records,
H. Karami, D. Atienza, and A. Ionescu, “Tee4ehr: Transformer event encoder for better representation learning in electronic health records,” Artificial Intelligence in Medicine, vol. 154, p. 102903, 2024
2024
-
[54]
Irregularity-informed time series analysis: Adaptive modelling of spatial and temporal dynamics,
L. N. Zheng, Z. Li, C. G. Dong, W. E. Zhang, L. Yue, M. Xu, O. Maennel, and W. Chen, “Irregularity-informed time series analysis: Adaptive modelling of spatial and temporal dynamics,” inProceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024, pp. 3405–3414
2024
-
[55]
X. Zhang, M. Zeman, T. Tsiligkaridis, and M. Zitnik, “Graph-guided network for irregularly sampled multivariate time series,”arXiv preprint arXiv:2110.05357, 2021
-
[56]
Ctpd: Cross-modal temporal pattern discovery for enhanced multimodal electronic health records analysis,
F. Wang, F. Wu, Y . Tang, and L. Yu, “Ctpd: Cross-modal temporal pattern discovery for enhanced multimodal electronic health records analysis,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 6783–6799
2025
-
[57]
Learning trimodal relation for audio-visual question answering with missing modality,
K. R. Park, H. J. Lee, and J. U. Kim, “Learning trimodal relation for audio-visual question answering with missing modality,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 42–59
2024
-
[58]
Borrowing treasures from neighbors: In-context learning for multimodal learning with missing modalities and data scarcity,
Z. Zhi, Z. Liu, M. Elbadawi, A. Daneshmend, M. Orlu, A. Basit, A. De- mosthenous, and M. Rodrigues, “Borrowing treasures from neighbors: In-context learning for multimodal learning with missing modalities and data scarcity,”Neurocomputing, p. 130502, 2025
2025
-
[59]
Redeem- ing modality information loss: Retrieval-guided conditional generation for severely modality missing learning,
J. Lang, R. Hong, Z. Cheng, T. Zhong, Y . Wang, and F. Zhou, “Redeem- ing modality information loss: Retrieval-guided conditional generation for severely modality missing learning,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 1241–1252
2025
-
[60]
Learning multimodal representations for in- complete ehrs with retrieval-augmented personalized modality recovery,
B. Li, B. Du, and J. Ye, “Learning multimodal representations for in- complete ehrs with retrieval-augmented personalized modality recovery,” Information Fusion, p. 104347, 2026
2026
-
[61]
Multi-task paired masking with alignment modeling for medical vision- language pre-training,
K. Zhang, Y . Yang, J. Yu, H. Jiang, J. Fan, Q. Huang, and W. Han, “Multi-task paired masking with alignment modeling for medical vision- language pre-training,”IEEE Transactions on Multimedia, vol. 26, pp. 4706–4721, 2023
2023
-
[62]
Mime: Multilevel medical embedding of electronic health records for predictive healthcare,
E. Choi, C. Xiao, W. Stewart, and J. Sun, “Mime: Multilevel medical embedding of electronic health records for predictive healthcare,”Ad- vances in neural information processing systems, vol. 31, 2018
2018
-
[63]
Using clini- cal notes with time series data for icu management,
S. Khadanga, K. Aggarwal, S. Joty, and J. Srivastava, “Using clini- cal notes with time series data for icu management,”arXiv preprint arXiv:1909.09702, 2019. IEEE TRANSACTIONS ON MULTIMEDIA, UNDER REVIEW 11 APPENDIXA THEORETICALJUSTIFICATION OFLOW-RANKCOUPLING In this section, we show that the proposedLow-Rank Coupling(Eq. 4) is a CP-based low-rank appro...
-
[64]
Based on the overall performance, we selectR= 8for both datasets
RankR.We varyR∈ {4,8,16}, and the results are shown in Table XVI. Based on the overall performance, we selectR= 8for both datasets
-
[65]
For MIMIC-III, we select1-4|4-12; for MIMIC- IV , we select1-4|-|12-12
Sampling Intervals.We evaluate different sampling interval settings for each dataset, and the results are reported in Table XVII. For MIMIC-III, we select1-4|4-12; for MIMIC- IV , we select1-4|-|12-12
-
[66]
The results are reported in Table XVIII and Table XIX
Loss Weights (λ a andλ r).We further study the effects of the loss weights for Fine-grained Alignment and Fine- grained Reconstruction. The results are reported in Table XVIII and Table XIX. According to the overall performance, we useλ a = 0.002andλ r = 10for MIMIC-III, and λa = 0.0001andλ r = 5for MIMIC-IV . TABLE XV ABLATION STUDY ON ENTROPY-BASED INFE...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.